Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NeurIPS 2022
Abstract
当前的端到端自动驾驶方法要么基于规划的轨迹运行控制器,要么直接执行控制预测,这已经跨越了两个单独研究的研究领域。鉴于它们彼此潜在的互利,本文主动探索这两个发达领域的结合。具体来说,我们的综合方法有两个分支,分别用于轨迹规划和直接控制。轨迹分支预测未来轨迹,而控制分支涉及一种新颖的多步预测方案,从而可以推断当前动作和未来状态之间的关系。这两个分支被连接,使得控制分支在每个时间步骤从轨迹分支接收相应的引导。然后将两个分支的输出融合以实现互补优势。使用CARLA模拟器在具有挑战性场景的闭环城市驾驶环境中评估我们的结果。即使使用单眼相机输入,所提出的方法在官方CARLA排行榜上排名第一,以大幅度超过其他具有多传感器或融合机制的复杂候选方法。源代码公开于https://github.com/OpenPerceptionX/TCP.

1 Introduction
端到端自动驾驶方法将原始传感器数据直接映射到规划的轨迹或低级控制动作,显示出简单的优点,在概念上避免了复杂的模块化设计和繁重的手工规则的级联错误。端到端自动驾驶模型的输出预测通常分为两种形式:轨迹/路线点[48, 4, 11, 46, 15, 29, 10]和直接控制动作[17, 39, 18, 42, 12, 60, 9]。然而,对于这两种形式中的哪一种更适合所有情况或某些场景,目前还没有明确的结论。
与可直接应用于车辆的控制预测不同,对于规划轨迹的方法,通常需要额外的控制器,例如PID控制器,作为将规划轨迹转换为控制信号的后续步骤。基于轨迹的预测的一个有吸引力和潜在优势在于,它实际上考虑了未来相对较长的时间范围,并且可以与其他模块(例如,多智能体轨迹预测[59, 10]、语义或占用预测模块[15, 8, 25])进一步组合,以减少可能的冲突。然而,将轨迹转化为控制动作,使车辆能够遵循计划的轨迹并非易事[57]。该行业通常采用复杂的控制算法,如模型预测控制,以实现可靠的轨迹跟踪性能[5, 21]。由于端到端模型的惯性问题,简单的PID控制器在大转弯或红灯时启动等情况下的性能可能会更差[29]。对于基于控制的方法,直接优化控制信号。然而,他们对当前步骤的关注可能会导致延迟反应,以避免与其他移动媒介发生潜在碰撞。不同步骤的控制预测之间的独立性也使得车辆的动作更加不稳定或不连续。图1显示了两种范式分别失败的两种典型情况。如何结合这两种形式的预测模型及其输出是一个有趣但相对较少研究的领域,这是这项工作的动力。
一个简单的想法(但实际上很少在文献中研究)是分别训练控制预测模型和轨迹规划模型,并直接组合它们的最终输出。它可以被视为两种不同模型的集合。然而,这种朴素的方法不仅使模型的大小加倍,而且忽略了这两种形式之间可能有用的相关性。为此,我们引入了TCP(轨迹引导控制预测)框架,将这两个分支打包成一个统一的框架。它可以被视为一个多任务学习(MTL)[7, 2]框架,其中共享主干提取计算复杂度降低的共同特征,以及由于两个任务之间的密切关系而提高的泛化能力[38, 34, 13]。此外,为了解决当前控制预测方法的缺点,我们精心设计了一种新的多步控制分支和轨迹引导控制预测方案。
虽然轨迹规划考虑了未来的几个步骤,但以行为克隆的方式直接学习控制[44, 41, 17, 18, 11]通常只关注当前的时间步骤,在每个状态动作对之前,作为独立和相同的分布式(IID)。这一假设并不准确,可能会妨碍长期性能,因为驾驶任务是一个序列决策问题。为了缓解这个问题,我们提出预测未来的多步控制动作。然而,多步骤控制过程需要与环境交互。因此,我们制定了一个时间模块来学习当前智能体和环境之间的前向过程和交互。GRU[16]实现的时间模块逐步处理每个时间步骤的特征表示,隐式地考虑了智能体的动态运动、它们之间的交互以及动态环境信息,如交通灯的变化。
此外,为了在多步预测方案中生成准确的控制信号,该模型应该从不同未来时间步骤的当前传感器输入中检索适当的位置信息。例如,智能体可能会在未来早期的几个时间步骤中更多地关注附近的区域,而在遥远的时间步骤中更关注远处的区域。考虑到知识已经部分编码在轨迹分支中,我们采用注意力机制来定位长期轨迹预测分支中的那些关键和有用区域,并引导控制预测分支以相应的方式在每个未来步骤中关注它们。因此,我们的模型能够推理如何优化当前控制预测,以便在应用预测的控制动作时,未来状态与专家状态相似。
利用来自两个分支的预测轨迹和控制信号,我们提出了一种基于情况的融合方案,根据实验结果和先验知识,以自集成的方式自适应地组合这两种形式,以形成最终输出。它结合了这两种形式中的最佳形式,从而进一步提高了不同场景下的性能。
当在CARLA驾驶模拟器中进行验证时,TCP显示出优异的性能[20]。我们的方法仅使用单眼摄像头,驾驶成绩达到75.137分,在公共CARLA排行榜[1]上排名第一,甚至超过了使用多个摄像头和激光雷达的现有最先进方法13.291分。本文的主要贡献包括:
- 我们研究了端到端自动驾驶的两种主要模式:轨迹规划和直接控制,并建议将它们结合在一个集成的学习流水线中。据我们所知,这是第一次联合学习和融合这两个分支进行预测。
- 设计了具有时间模块和轨迹引导注意力的多步控制预测分支,以实现时间推理。为了结合两个分支的优点,我们设计了一个基于情境的方案来融合两个输出。
- 作为一个简单但强大的基线,我们的方法仅使用单眼相机作为输入,在CARLA排行榜上实现了新的最先进水平,许多竞争对手使用了多个传感器。我们进行了彻底的消融研究,以验证我们方法的有效性。
2 Related Work
2.1 End-to-end Autonomous Driving
近年来,基于学习的端到端自动驾驶已成为一个活跃的研究课题。学习通常分为两类:强化学习(RL)和模仿学习。RL是解决对数据集分布变化更为鲁棒的问题的一种有前途的方法。Liang等人[39]使用DDPG来训练以监督方式预先训练的策略。Kendall等人[30]在车上训练他们的深度RL算法,以有效地学习驾驶真实世界的车辆。在[50, 9, 62]中,感知任务与在线RL过程分离。基于模型的方法WoR[12]假设世界处于轨道上,并使用策略蒸馏来实现强大的性能。
模仿学习(IL),特别是行为克隆,为模型收集记录的数据,以便以高数据效率进行模拟。专家数据通常有两种形式,轨迹和控制动作。Zeng等人[58]训练成本量以生成规划路线,而[49, 8, 25]基于语义占用图明确设计安全和舒适成本,以选择专家轨迹集中的最佳轨迹。Zhang等人[59]使用标记的BEV地图预测周围车辆的轨迹。LBC[11]和NEAT[15]从密集热图或偏移图解码航路点。上述这些方法都利用相对密集的表示来获得增加模型复杂性的结果。Transfus及其变体[46,29]采用简单的GRU来自动回归航路点。LAV[10]采用时间GRU模块来进一步细化轨迹。他们一致在CARLA排行榜上取得了令人印象深刻的成绩,激励我们在设计中调整自动回归方案。另一方面,所有基于轨迹的方法都使用PID控制器来获得最终动作,这可能会在复杂场景中产生较差的效果。
[44, 40, 3, 54]中提出了另一种直接预测控制动作的类型。CIL[17]使用图像编码器为不同的高级命令添加了测量编码器和多个分支。CILRS[18]随后被提出,并进一步引入了速度预测头。它们是CARLA驾驶模拟器中IL的经典基准。基于它们提出了多种优化方法,如多模态输入[22, 53]、多任务学习[56, 37, 24, 27, 31, 26, 63]、数据集聚合[45]和知识提取[61, 60]。然而,基于紧凑控制的方法通常具有较高的车辆碰撞率,这仍然是一个值得探索的有趣领域。类似的工作也存在于其他相关领域,如机器人导航。[43]在局部轨迹规划器之后学习控制器以改善整体导航行为。
2.2 Multi-task and Ensemble Learning for Autonomous Driving
多任务学习是一种流行的方法,可以同时训练多个相关任务,以相互帮助并提高泛化能力[7, 2]。各种自动驾驶任务的组合,如目标检测、车道检测、语义分割、深度估计等,已被证明能够实现令人难以置信的性能[38, 14, 47, 34, 52, 13]。MTL也适用于端到端问题,因为观察到从图像到控制信号的直接映射的性能是有限的。[56]添加了类似于CIL[17]的速度预测任务,[63]将横向和纵向控制分离为两个任务。LAV[10]训练了额外的场景映射网络,[24, 27, 29]还预测了光流或密集深度。我们同时训练轨迹和控制的想法与FASNet密切相关[31]。FASNet将当前智能体的未来位置预测作为辅助任务,并考虑到控制和位置之间的关系,增加了运动学损失。然而,该约束基于恒定速度模型,忽略了重要的油门和制动器,并且在推断时不起作用。另一方面,我们的TCP框架在早期阶段就具有交互功能,以充分发掘其潜在的共同利益。
长期以来,模型集合一直被用于提高计算机视觉性能[19, 33, 35, 51, 55, 45]。除了模型的正常组合之外,两种经典的集成学习方法在自动驾驶系统中尤其受欢迎。一个是测试时间增强(TTA),它对LiDAR的3D物体检测任务有很大帮助[6, 36]。另一种是专家融合[28],其中专家在输入空间的子集上进行训练,并训练门控网络以提供融合权重。LSD[42]和MoDE[32]将数据集划分为子场景,以获得端到端自动驾驶的不同子策略。这些传统的集成方法结合了相同结构的模型,而我们的方法试图结合两种不同的表示。此外,多专家设计增加了训练策略的复杂性,我们寻求一种更简单的基于情境的融合方案来提高性能。
3 Trajectory-guided Control Prediction
3.1 Problem Setting
Problem formulation. 给定由传感器信号i、车辆速度v和高级导航信息g组成的状态x,该高级导航信息包括由全局规划器提供的离散导航命令和导航目标坐标,端到端模型需要输出由纵向控制信号throttle∈[0, 1]、brake∈[0, 1]和横向控制信号steer∈[-1, 1]组成的控制信号。
传统方法通过轨迹输出或仅控制输出模型来解决这个问题。然而,TCP将这两者合并为两个分支:预测规划轨迹的轨迹分支和由轨迹分支引导并向未来输出当前和多步控制信号的控制分支。这两个分支机构都以监督的方式进行训练。考虑一个专家在每一步直接输出控制信号,用地面真实轨迹监控预测轨迹使其不严格满足模仿学习中行为克隆的设置。地面真相轨迹确实涉及未来专家动作和未来环境状态,因此我们将其制定为轨迹规划任务,地面真相轨迹作为轨迹分支的监督。对于控制分支,训练一个使专家控制监督的当前控制预测的控制模型只是模仿学习中的行为克隆,这可以公式化为:
![]()
其中D={(x, a*)}是由从专家收集的状态-动作对组成的数据集。πθ表示控制分支的策略,L是衡量专家的动作与我们的模型的动作有多接近的损失。专家通过控制车辆并与世界互动来收集数据集。每个收集到的路径都是一个轨迹![]() ,作为状态-动作对的序列
,作为状态-动作对的序列![]() ,然后将其添加到整个数据集D中。
,然后将其添加到整个数据集D中。
Expert demonstration. 这里我们选择Roach[60]作为专家。Roach是一个由RL使用特权信息训练的简单模型,包括道路、车道、路线、车辆、行人、交通灯和站点,所有这些都被渲染为2D BEV图像。与手工制定的规则相比,这种基于学习的专家可以传递除直接监督信号外更多的信息。具体来说,我们有一个特征损失,它迫使学生模型的最终输出头之前的潜在特征与专家的相似。价值损失也被添加为学生模型预测预期回报的辅助任务。
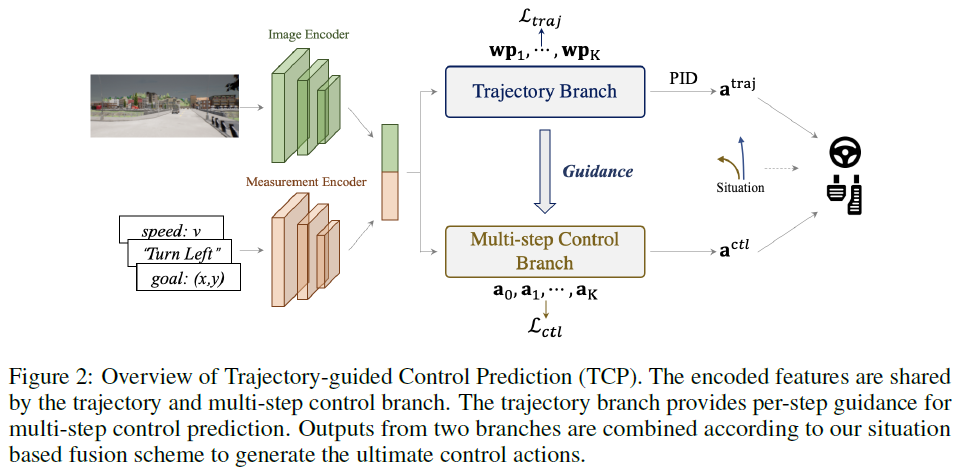
3.2 Architecture Design
Overview. 如图2所示,整个架构由输入编码级和两个后续分支组成。输入图像i经过基于CNN的图像编码器,例如ResNet[23],以生成特征图F。同时,导航信息g与当前速度v级联以形成测量输入m,然后基于MLP的测量编码器将m作为其输入并输出测量特征jm。编码的特征然后由两个分支共享,用于后续的轨迹和控制预测。具体而言,控制分支是一种新颖的多步预测设计,具有轨迹分支的指导,这将在以下章节中详细说明。最后,采用基于情境的融合方案来结合两种输出范式中的最优。我们将在下面详细介绍每个部分。
3.2.1 Trajectory planning branch
与直接预测控制动作的控制预测不同,轨迹规划分支首先生成由K步的航路点组成的规划轨迹,供智能体跟踪,然后由低级控制器处理该轨迹以获得最终控制动作。利用来自输入编码器的共享特征,图像特征图F被平均池化并与测量特征jm连接以形成jtraj。受[46]的启发,我们将jtraj输入GRU[16],以逐个自回归获得未来的航路点,从而形成规划的轨迹。
我们有两个PID控制器分别用于纵向和横向控制。使用规划的轨迹,我们首先计算连续航路点之间的矢量。这些矢量的大小表示所需的速度,并被发送到纵向控制器以产生throttle和brake控制动作,方向被发送到横向控制器以获得steer动作。
3.2.2 Multi-step control prediction branch
如第3.1节所述,对于仅基于当前输入预测当前控制动作的控制模型,受监督的训练只是行为克隆,其依赖于独立同分布(IID)假设。由于测试用例中的分布变化,这一假设显然不成立,因为闭环测试需要序列决策,其中历史动作将影响未来状态和动作。与其将其建模为马尔可夫决策过程(MDP)并诉诸强化学习,我们在这里设计了一种简单的方法,通过预测未来的多步控制来缓解问题。
给定当前状态xt,现在我们的多步控制预测分支输出多个动作:![]() 。然而,很难预测未来的控制动作,因为我们在当前时间步长只有传感器输入。针对这个问题,我们设计了一个时间模块来隐式地执行环境和我们的智能体的变化和交互过程。它应该主要提供关于环境和智能体自身状态的动态信息,例如其他对象的运动、交通灯的变化以及当前智能体的状态。同时,为了提高合并关键静态信息(例如,路缘和车道)的能力,并提高两个分支的空间一致性,我们提出使用轨迹分支来指导控制对象在每个未来时间步骤关注输入图像的适当区域。
。然而,很难预测未来的控制动作,因为我们在当前时间步长只有传感器输入。针对这个问题,我们设计了一个时间模块来隐式地执行环境和我们的智能体的变化和交互过程。它应该主要提供关于环境和智能体自身状态的动态信息,例如其他对象的运动、交通灯的变化以及当前智能体的状态。同时,为了提高合并关键静态信息(例如,路缘和车道)的能力,并提高两个分支的空间一致性,我们提出使用轨迹分支来指导控制对象在每个未来时间步骤关注输入图像的适当区域。
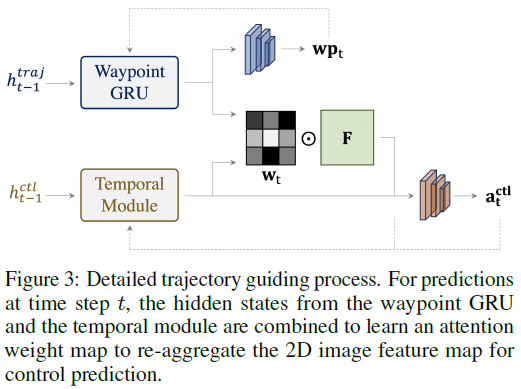
Temporal module. 我们的时间模块是用GRU实现的,以更好地与轨迹分支保持一致。在步骤 t (0 ≤ t ≤ K−1),时态模块的输入是当前特性![]() (下一节将详细介绍构造)和当前预测动作at的连接,这是关于环境和智能体自身当前状态的紧凑表示。时间模块假定基于当前特征向量和预测动作来推理动态变化过程。然后,更新的隐藏状态
(下一节将详细介绍构造)和当前预测动作at的连接,这是关于环境和智能体自身当前状态的紧凑表示。时间模块假定基于当前特征向量和预测动作来推理动态变化过程。然后,更新的隐藏状态![]() 将包含关于环境的动态信息以及在时间步骤t+1处智能体的更新状态。在某种程度上,时间模块充当粗略的模拟器,将整个环境和智能体抽象为特征向量。然后,它基于当前的动作预测来模拟环境和智能体之间的交互。
将包含关于环境的动态信息以及在时间步骤t+1处智能体的更新状态。在某种程度上,时间模块充当粗略的模拟器,将整个环境和智能体抽象为特征向量。然后,它基于当前的动作预测来模拟环境和智能体之间的交互。
Trajectory-guided attention. 由于传感器输入仅在当前步骤,很难找出模型在未来步骤应关注的理想区域。然而,当前智能体的位置包含了如何找到包含关键静态信息的区域的重要线索,以便在每个步骤中进行控制预测。
因此,我们寻求轨迹规划分支的帮助,以获取有关相应步骤中智能体的可能位置的信息。如图3所示,TCP通过学习注意力图从编码的特征图中提取重要信息来实现这一点。两个分支之间的互动增强了这两个密切相关的输出范式的一致性,并进一步阐述了多任务精神。具体地,利用图像编码器F在时间步骤 t (1 ≤ t ≤ K)提取的2D特征图,我们使用来自控制分支和轨迹分支的相应隐藏状态来计算注意力图![]() :
:
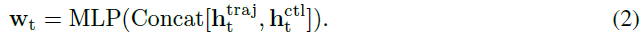
采用注意力图![]() 来聚合该步骤的特征图F。然后,我们将有人关注的特征图与
来聚合该步骤的特征图F。然后,我们将有人关注的特征图与![]() 相结合,以形成包含关于环境和当前智能体的静态和动态信息的信息表示特征
相结合,以形成包含关于环境和当前智能体的静态和动态信息的信息表示特征![]() 。该过程可描述如下:
。该过程可描述如下:
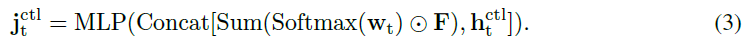
信息表示特征![]() 被馈送到策略头部,该头部在所有时间步骤之间共享,以预测相应的控制动作at。注意,对于初始步骤,我们仅使用测量特征来计算初始注意力图,并将关注的图像特征与测量特征相结合以形成初始特征向量
被馈送到策略头部,该头部在所有时间步骤之间共享,以预测相应的控制动作at。注意,对于初始步骤,我们仅使用测量特征来计算初始注意力图,并将关注的图像特征与测量特征相结合以形成初始特征向量![]() 。为了保证特征
。为了保证特征![]() 确实描述了该步骤的状态,并包含了控制预测的重要信息,我们在每个步骤中添加一个特征损失,以使
确实描述了该步骤的状态,并包含了控制预测的重要信息,我们在每个步骤中添加一个特征损失,以使![]() 也接近专家的特征。
也接近专家的特征。
为此,我们的TCP框架赋予了模型在短时间内的推理能力。它强调如何使当前控制预测接近专家的预测。此外,它还考虑了当前控制预测可以使在未来时间步骤中的环境状态和当前智能体的状态与专家预测类似。
3.3 Loss Design
我们的损失包括轨迹规划损失Ltraj、控制预测Lctl和辅助损失Laux。
对于轨迹规划分支,损失Ltraj可以表示为:
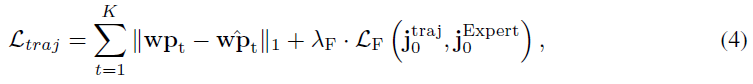
其中,![]() 分别是第t步的预测和地面真实航路点。LF指示测量
分别是第t步的预测和地面真实航路点。LF指示测量![]() 和来自专家的特征之间的L2距离的特征损失,作为额外监督信号[60]。λF是可调损失权重。
和来自专家的特征之间的L2距离的特征损失,作为额外监督信号[60]。λF是可调损失权重。
对于控制预测分支,我们将动作建模为Beta分布。损失Lctl为:
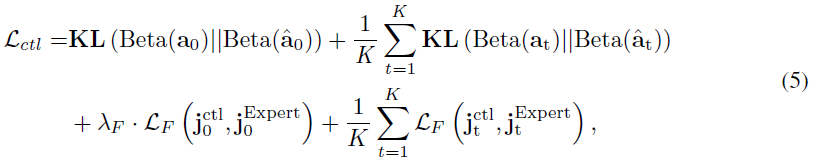
其中Beta(a)表示由相应的预测分布参数表示的Beta分布,KL散度用于测量预测控制分布与来自专家的分布(即![]() )之间的相似性。这里也应用了特征损失。请注意,由于立即执行的动作应该是我们要优化的关键目标,因此未来时间步长(t≥1)的所有损失都是平均值,然后加上当前时间步骤(t=0)的损失。
)之间的相似性。这里也应用了特征损失。请注意,由于立即执行的动作应该是我们要优化的关键目标,因此未来时间步长(t≥1)的所有损失都是平均值,然后加上当前时间步骤(t=0)的损失。
为了帮助智能体更好地估计其当前状态,我们添加了一个速度预测头来根据图像特征预测当前速度s,以及一个价值预测头来预测专家估计的期望回报,类似于[60]。我们将L1损失用于速度预测,L2损失用于价值预测,将它们的加权和表示为Laux。
总损失如下,按λtraj,λctl,λaux加权:
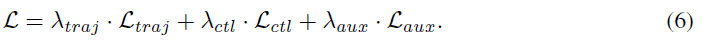
3.4 Output Fusion
我们的TCP框架有两种形式的输出表示:规划轨迹和预测控制。为了进一步结合它们的优点,我们设计了一种如算法1所示的基于情境的融合策略。具体地,将α表示为值在0到0.5之间的组合权重,在根据我们先前的信念一种表示更适合的特定情境中,我们将轨迹预测和控制预测的结果结合起来,将以权重为α的平均值相结合,从而使更合适的一个占据更多的权重(1−α)。注意,组合权重α确实不需要是常数或对称的,这意味着我们可以在不同的情况下将其设置为不同的值,或者对于特定的控制信号设置为不同。在我们的实验中,我们根据当前车辆是否在转弯来选择情况,这意味着如果它在转弯,情况是控制专用的,否则轨迹专用的。

4 Experiments
4.1 Experimental Setup
Task & Evaluation metrics. 我们的方法在CARLA驾驶模拟器中进行了验证和测试[20]。给定由一系列稀疏导航点以及高级命令(直行、左转/右转、变道和车道跟随)定义的路线,闭环驾驶任务要求自动驾驶者朝着目的地行驶。它旨在模拟现实的交通状况,包括不同的挑战场景,如避障、穿越无信号交叉口和突然失去控制。有三个主要指标:驾驶得分、路线完成和违规得分。路线完成是自主智能体完成路线的百分比。违规分数衡量道路沿线的违规次数,包括行人、车辆、道路布局、红灯等。驾驶分数是主要指标,是路线完成和违规分数的乘积。
Dataset. 我们使用随机天气条件下随机生成的路线,在CARLA模拟器提供的8个公共城镇中收集420K个数据。与[10]类似,我们在8个城镇(Town01、Town03、Town04和Town06)中的4个城镇中训练了189K数据的TCP,以进行消融,并使用所有420K数据进行训练,以提交在线排行榜。
4.2 State-of-the-art Comparison
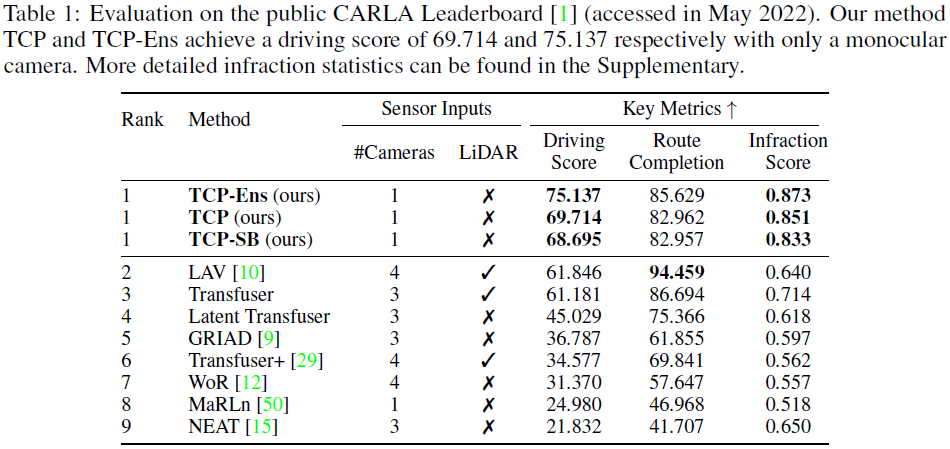
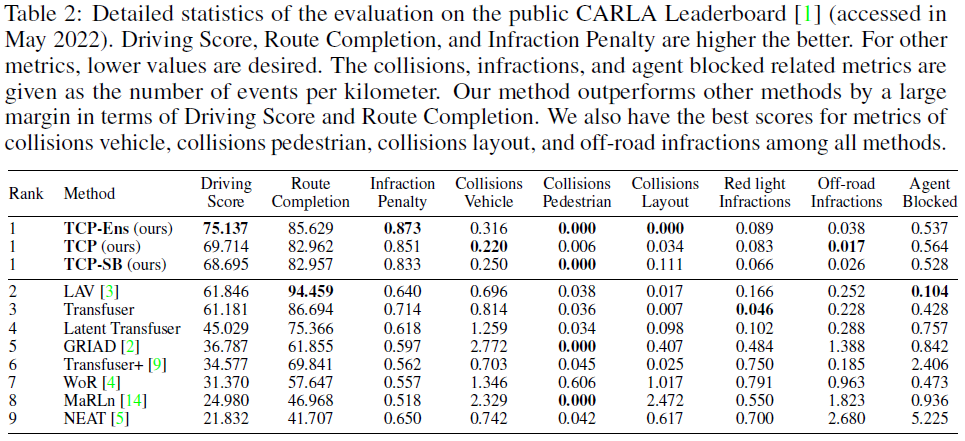
表1显示了我们的方法与公共CARLA排行榜上排名前8的项目之间的比较结果[1]。我们报告了TCP和两个变体的结果。TCP-SB将TCP的共享编码器替换为两个分支的两个独立编码器,TCP-Ens是TCP和TCP-SB的集成。我们的方法TCP Ens以75.137的驾驶分数和最高的违规分数在排行榜上排名第一,仅TCP一项也超过了现有方法。注意,我们的方法只使用单眼相机,而前2-4种方法都使用多个相机和激光雷达。我们的驾驶分数比第二好的单眼相机方法MaRLn[50]高50.157。我们的路线完成度略逊于LiDAR候选——一个原因是使用LiDAR的方法可能具有更好的目标检测能力。根据检测结果,他们通常采用爬行策略,表明车辆在长时间停止且前方没有障碍物时会缓慢移动。如[29]所述,这可以缓解当前车辆的阻塞问题,以提高路线完成性能。

4.3 Control vs. Trajectory
在本节中,我们进行了定量实验,以比较“仅控制”模型和“仅轨迹”模型,以证明它们的优缺点。对于两种模型,我们使用相同的设置,除了输出头及其相应的损失。我们使用ResNet-34对视觉输入进行编码,使用测量模块对导航信息进行编码。与[60]类似,我们添加了速度和价值头作为辅助任务,以帮助模型更好地编码环境。对于“仅控制”,我们基于来自两个编码器的级联潜在特征来预测控制分布。至于“仅轨迹”,我们将该特性提供给GRU解码器以生成路线点。如表2所示,虽然“仅轨迹”与车辆碰撞的频率低于“仅控制”,但它具有更多的布局碰撞、越野违规和智能体阻挡。我们还计算转弯过程中发生的每种违规行为的比例。可以观察到,对于“仅轨迹”,与“仅控制”相比,很大一部分这样的违规行为发生在当前智能体转向时。这验证了“仅轨迹”在智能体转弯时表现更差,这可能是由于第1节中讨论的简单PID控制器的轨迹跟踪性能不令人满意所致。至于“仅控制”具有较高的车辆碰撞率这一事实,这是因为该模型侧重于当前时间步骤,对潜在碰撞的反应往往较晚,如第1节所示。上述结果进一步验证了将两种输出范式相结合的必要性。
4.4 Ablative Study and Visualization
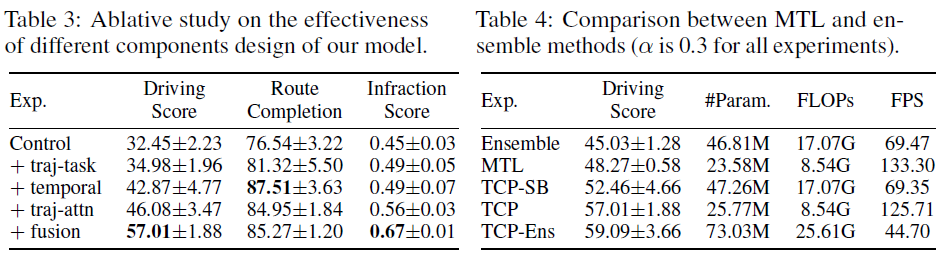
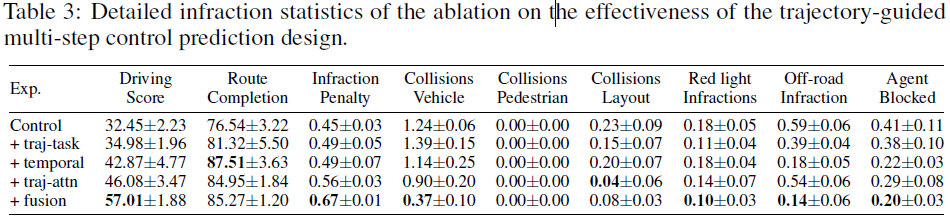
Component analysis. 我们首先验证了轨迹制导多步控制预测设计的有效性,如表3所示。当融合应用于这些消融时,我们只使用控制分支输出,除了最后一个完整的输出。添加轨迹分支作为辅助任务可将性能提高2.5点。使用我们的时间模块进行的多步预测大大有助于提高7.9分,添加轨迹引导注意力进一步提高3.2分。最后,应用我们的基于情境的融合方案(α设置为0.3)显著提高了违规分数,从而使总体驾驶分数达到57分。
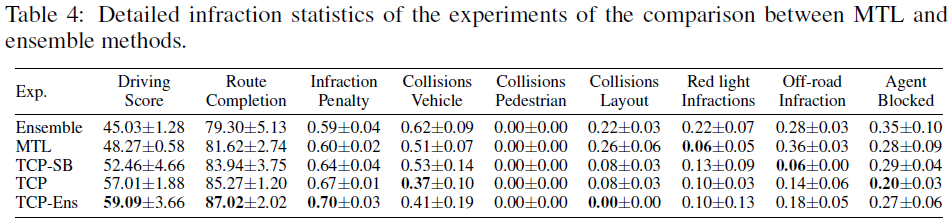
Multi-task vs. Ensemble. 表4中给出了它们的性能和计算复杂性的比较。集成(Ensemble)表示将"仅控制"和"仅轨迹"的输出与我们基于情况的融合方案直接结合。MTL表示具有共享CNN主干和测量编码器的模型,随后是轨迹分支和控制分支,但控制分支仅预测当前步骤预测,两个分支之间没有交互作用。我们得出的结论是,将两个模型与我们的融合方案直接结合可以大大提高性能,并且使用MTL方法比集成更好,但模型大小和GFLOP要小得多。将TCP和TCP-SB的结果组合为TCP-Ens的传统集成方法以计算复杂性为代价带来了进一步的性能增益。
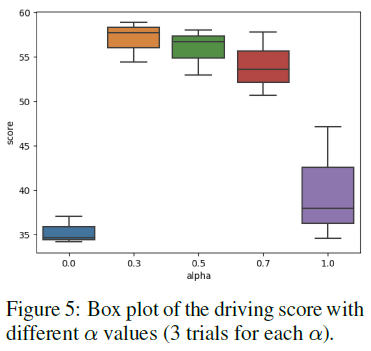
Situation based fusion weight. 我们研究了基于情境的融合方案中组合权重α的选择,并在右侧的图中显示了驾驶分数的方框图。除了α∈[0, 0.5],我们还测试了0.7和1,这意味着两个结果与我们的专用定义相反。我们看到,仅使用来自专用分支α=0的控制效果不佳,而直接取平均值或相反地融合仍然具有可比较的结果。一个原因是,这里使用的情况标准是车辆是否在转弯,这使得大多数情况下是轨迹专用的,如果α较小,则没有充分利用更强的控制分支。注意,基于情况的融合方案是通用的和灵活的,这里使用的标准或α值相对粗略。
Visualization. 图4显示了轨迹引导的注意力图。轨迹分支提供位置相关信息,以引导控制分支聚焦于对未来控制预测有用的重要区域。更多定性结果见附录。

5 Conclusion
在这项工作中,我们研究了两种分别基于轨迹和直接控制的端到端自动驾驶学习和预测范式。我们提出了一个统一的框架,该框架由一个轨迹分支和一个新的多步控制分支组成,其间有相互作用。我们设计了一种基于情境的融合方案,以结合来自两个分支的结果。我们只使用单眼相机的方法在CARLA排行榜上取得了最先进的性能。

在本补充文件中,我们首先在第A节中提供了数据集的详细描述。实现和训练详情见第B节。我们在第C节中显示了排行榜结果和消融研究的详细违规统计数据,以及定性结果。最后,我们在第D节中讨论了我们工作的局限性、常见故障案例、可能的未来方向和潜在社会影响。
A Dataset
A.1 Dataset Collection
我们使用CARLA 0.9.10.1进行数据收集和测试。我们使用Roach[16]作为收集数据的专家。为了提高专家的避障能力,我们额外增加了Transfus[12]采用的基于规则的车辆和行人检测器,以避免可能的碰撞。每条路线随机生成,长度从50米到300米不等。我们使用[12]中提供的场景配置。如果专家发生碰撞或闯红灯,我们会终止这条路线。这些路线的最后几帧被丢弃。数据样本以2HZ存储。
A.2 Dataset Statistics
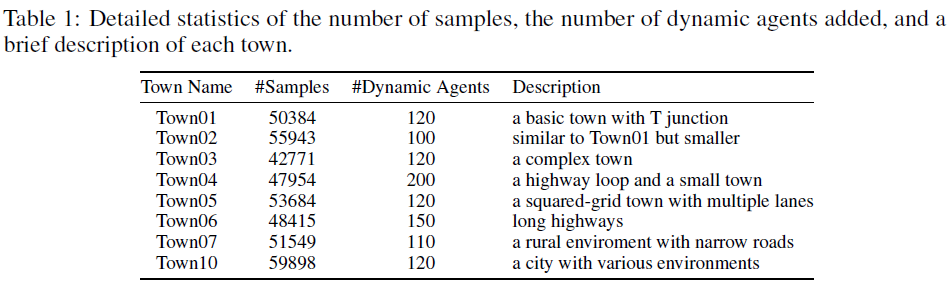
表1中提供了每个城镇的详细统计数据及其描述。正如主要论文中所述,我们对所有八个城镇进行了排行榜提交训练。对于我们的消融实验,我们在四个城镇(Town01、Town03、Town04和Town06)进行训练,并在Town02和Town05的四个不同天气下对设计的四条路线进行测试,如[3]所示。
B Implementation Details
我们使用在ImageNet[6]上预训练的ResNet-34[8]作为图像编码器。输入图像的大小为900×256,相机的FOV设置为100°。我们选择K为4,这意味着预测轨迹分支和控制分支在2HZ的四个未来步骤。详细的网络结构如表5所示。我们采用与[5]相同的PID设置,其中PID参数经过精细调整,即纵向PID控制器的Kp=5.0,Ki=0.5,Kd=1.0,横向PID控制器的Kp=0.75,Ki=0.75,Kd=0.3。不同损失项的权重如下:λF=0.05,λtraj=1,λctl=1,λaux=0.05(速度回归)或0.001(价值回归)。对于所有实验,我们在4个GeForce RTX 3090 GPU上训练TCP。我们的所有实验均使用学习率为1×10−4,权重衰减为1×10-7的的Adam优化器[10]。我们在60个回合内训练批大小为128的所有模型,在30个回合后,学习率降低了2倍。
在基于情况的融合方案中,我们选择车辆是否转弯作为情况的标准。具体来说,我们计算过去1秒内转向动作的绝对值。如果其中一半大于0.1,我们假设车辆正在转弯,因此情况是控制专用的,否则是轨迹专用的。对于在线CARLA排行榜[1]提交,我们使用了不对称融合方案。如果情况是轨迹专用的,我们设置α=0.5,当它是控制专用的时设置α=0。我们采用brake控制的最大值,而不是平均值。对于整体提交的TCP-Ens,我们还从不同模型中获取brake值的最大值,并获取steer和throttle的平均值。
C Experiments
C.1 Validation Protocol Details
我们使用与LAV[3]相同的验证路线。这包括总共4条路线,从Town02和Town05出发的均为2条。每一条路线都在4种不同的天气条件下进行测试(晴空、多云、晴雨、晴雨),并重复3次,总共48条路线。从官方CARLA排行榜报告(all_towns_traffic_scenarios_public.json)中添加了随机场景。智能体阻塞的时间限制从300秒减少到60秒,以节省时间。
C.2 Detailed Infractions Statistics
在本部分中,我们在表2中报告了CARLA排行榜上方法的详细违规统计数据,并在表3和表4中报告了消融实验的统计数据。
C.3 Qualitative Results
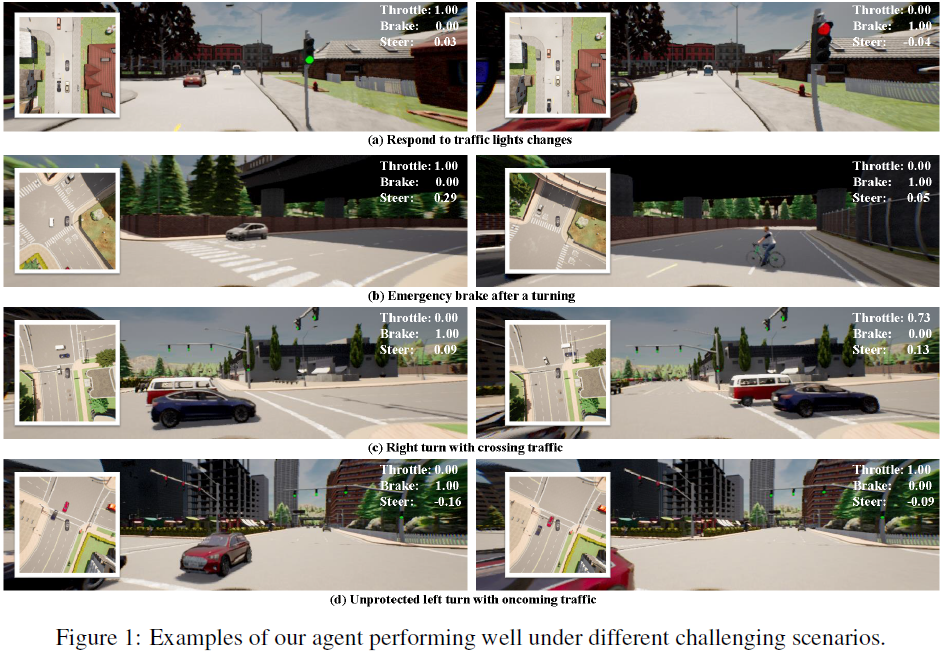
我们在图1中展示了我们的方法在不同挑战场景中表现良好的案例。在第一种情况下,自主智能体成功地对十字路口交通灯的及时变化做出反应。在第二种情况下,一名骑车人在当前智能体右转后突然横穿马路,我们的智能体及时紧急刹车,避免了碰撞。在第三种情况下,当有其他车辆通过时,当前车辆正在右转。它停下来,等待路过车辆通过,然后继续转弯。在最后一种情况下,我们的智能体正在对迎面驶来的车辆进行无保护左转,并成功地通过迎面驶来车辆。
图2提供了轨迹引导注意力图的更多可视化示例。我们还显示了图3中带有多步预测方案的"仅控制"模型的两个示例的GradCam[13]和EigenCam[11]可视化。对于GradCam可视化,我们将目标(需要在GradCam计算期间最大化)设置为当前和未来动作预测的负动作损失。请注意,GradCam通过计算梯度以最大化目标来可视化输入图像中对预测很重要的区域。它并不表示模型确实聚焦或很好地捕捉了GradCam突出显示的区域。如图3所示,用于当前动作预测的GradCam热图(a0)聚焦于接近自当前车辆位置的区域,而用于未来预测的热图(a1)则进一步聚焦于区域。这表明,预测未来行动确实需要关注更多地区。
然而,具有多步动作预测的仅控制模型仅按全局平均值聚集图像特征图一次。然后使用合并的特征来预测所有时间步骤的动作。因此,为每个步骤突出显示相应的重要区域是不现实的。我们使用EigenCam来可视化2D图像特征图。通过将特征图投影到特征向量来直接计算热图是一种无梯度可视化方法。如图3的最后一列所示,2D图像特征图的突出显示区域仅跨越单个区域,这对于多步预测来说信息不足。它验证了为每个未来步骤重新聚集具有不同突出显示区域的图像信息的必要性,如图2所示。



D Discussion
D.1 Limitations and Future Work
D.1.1 Failure Cases and Future Work Directions
我们的工作主要集中在结合端到端自动驾驶的两种输出形式,即轨迹规划和直接控制。基于情境的融合方案基于可能需要大量实验和特定先验知识的规则。更一般的或基于学习的自适应融合方案可能是未来的方向。
我们还在图4中讨论了TCP的两种典型故障情况。第一种情况发生在最初超出当前智能体前视图的其他车辆以高速冲入路径时。当紧急制动失效时,它会导致延迟碰撞。这是因为我们的单摄像头视野有限,因此未来的一个直接方向是向我们的智能体添加多视角摄像头或激光雷达输入。另一种失败是当前智能体无法预测其他车辆的可能轨迹,导致阻塞或碰撞。因此,明确做出其他车辆的轨迹预测,并将其与我们的轨迹分支相结合,也是进一步提高泛化能力的一个有趣方向,如LAV[3]和LBW[15]所示。
D.2 Broader Impact
我们探讨了端到端自动驾驶的两种传统输出范式的局限性和优势,提出了TCP,它在公共闭环基准上实现了最先进的性能,以推动问题的边界。我们的目标是将这一领域的两个研究分支结合起来,并提供一个统一的框架来结合它们可能的优势。我们的工作提供了一个简单而有效的框架,在此基础上,可以方便地集成和透明地比较新的模型和技术。尽管有这样的改进,但我们完全理解,我们的工作绝非完美,在实际应用中仍面临许多挑战。我们的模型是在模拟器中训练和测试的,直接在现实世界中部署它将导致可能的交通事故,这可能会造成负面的社会影响。
E License of Assets
CARLA[7]是一个开源模拟器,它获得麻省理工学院许可证,其资产获得CC-BY许可证。我们将Roach[16]的部分官方代码(根据CC-BY-NC 4.0许可证)集成到我们的代码库中。预训练的ResNet模型是麻省理工学院许可的。
我们工作的源代码和训练数据一旦被接受,就可以公开获得,并且它们是CC-BY-NC 4.0许可证。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号