Offline Reinforcement Learning as One Big Sequence Modeling Problem
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NeurIPS 2021
代码可以从此处获取
Abstract
强化学习(RL)通常与估计静态策略或单步模型有关,利用马尔可夫属性及时分解问题。然而,我们也可以将RL视为一个通用的序列建模问题,其目标是产生一系列动作,从而导致一系列高回报。从这个角度来看,很容易考虑在其他领域(例如自然语言处理)中运行良好的大容量序列预测模型是否也可以为RL问题提供有效的解决方案。为此,我们探索了如何使用序列建模工具来处理RL,使用Transformer架构对轨迹上的分布进行建模,并将波束搜索重新用作规划算法。将RL框架化为序列建模问题简化了一系列设计决策,使我们能够省去离线RL算法中常见的许多组件。我们展示了这种方法在长期动态预测、模仿学习、目标条件强化学习和离线强化学习方面的灵活性。此外,我们表明,这种方法可以与现有的无模型算法相结合,在稀疏奖励、长期任务中产生最先进的规划器。
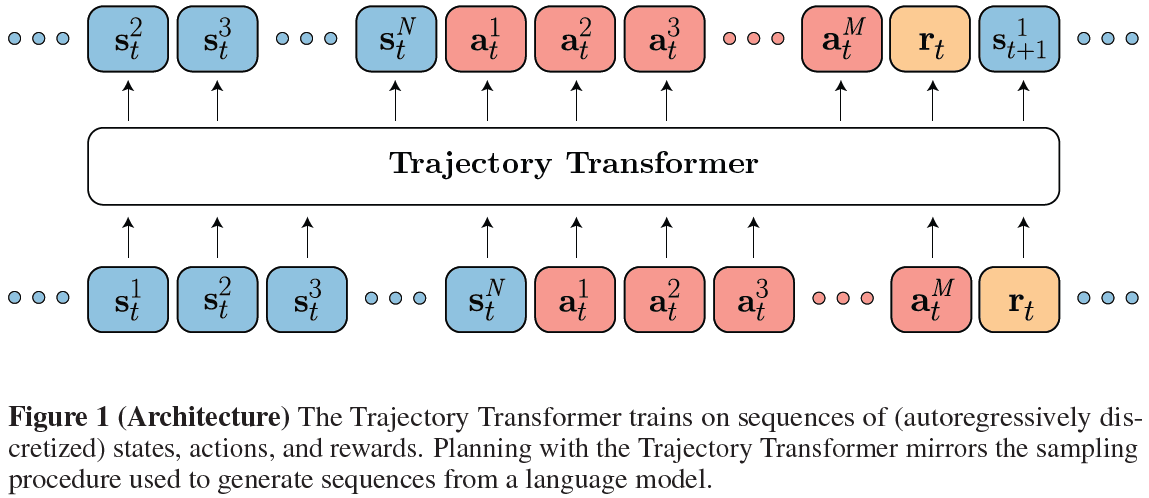
1 Introduction
强化学习的标准处理依赖于将长期问题分解为更小、更局部的子问题。在无模型算法中,这采用最优性原则(Bellman, 1957)的形式,一种自然地导致动态规划方法类的递归,如Q学习。在基于模型的算法中,这种分解采用单步预测模型的形式,它将预测高维、依赖于策略的状态轨迹的问题简化为估计相对简单的、与策略无关的转换分布的问题。
但是,我们也可以将强化学习视为类似于序列生成问题,其目标是产生一系列动作,当在环境中实现时,将产生一系列高回报。在本文中,我们考虑了这个类比的逻辑极端:当代序列建模工具箱本身是否提供了可行的强化学习算法?我们通过将轨迹视为状态、动作和奖励的非结构化序列来研究这个问题。我们使用Transformer架构(Vaswani et al., 2017)对这些轨迹的分布进行建模,这是当前捕获长视界依赖关系的首选工具。代替基于模型的控制中常见的轨迹优化器,我们使用波束搜索(Reddy, 1977),一种在自然语言处理中普遍存在的启发式解码方案,作为规划算法。
将强化学习和更广泛的数据驱动控制作为序列建模问题处理许多通常需要不同解决方案的考虑因素:actor-critic算法需要单独的actor和critic,基于模型的算法需要预测动态模型,以及离线RL方法通常需要估计行为策略(Fujimoto et al., 2019)。这些组件估计不同的密度或分布,例如在actor和行为策略的情况下对动作的估计,或者在动态模型的情况下对状态的估计。甚至价值函数也可以被视为在具有辅助最优性变量的图形模型中执行推理,相当于估计未来奖励的分布(Levine, 2018)。所有这些问题都可以统一在一个单一的序列模型下,该模型将状态、动作和奖励视为简单的数据流。这种观点的优势在于,可以采用大容量序列模型架构来解决该问题,从而产生一种更精简的方法,该方法可以受益于大规模无监督学习结果的相同可扩展性(Brown et al., 2020)。
我们将我们的模型称为Trajectory Transformer(图1)并在离线状态下对其进行评估,以便能够利用大量先前的交互数据。Trajectory Transformer是比传统动力学模型更可靠的长视界预测器,即使在标准模型参数化原则上足够的马尔可夫环境中也是如此。当使用修改后的波束搜索程序解码时,该程序会根据累积奖励对轨迹样本进行偏置,Trajectory Transformer在离线RL基准上获得结果,与专门为该设置设计的最佳先前方法相媲美。此外,我们描述了相同解码过程的变化如何产生基于模型的模仿学习方法、达到目标的方法,以及与动态规划相结合时,用于稀疏奖励、长视界任务。我们的结果表明,广泛应用于无监督学习的算法和架构主题在RL中具有类似的好处。
2 Related Work
从LSTM和序列到序列模型(Hochreiter & Schmidhuber, 1997; Sutskever et al., 2014)到具有自注意力的Transformer架构(Vaswani et al., 2017),深度网络序列建模的最新进展导致此类模型的有效性迅速提高。有鉴于此,人们很容易考虑这种序列模型如何提高强化学习的性能,这也与序列过程有关(Sutton, 1988)。事实上,许多先前的工作已经研究了应用各种类型的序列模型来表示标准RL算法中的组件,例如策略、价值函数和模型(Bakker, 2002; Heess et al., 2015a; Chiappa et al., 2017; Parisotto et al., 2020; Parisotto & Salakhutdinov, 2021; Kumar et al., 2020b)。尽管此类工作证明了此类模型在表示内存方面的重要性(Oh et al., 2016),但它们仍然依赖于标准RL算法的进步来提高性能。我们工作的目标是不同的:我们的目标是用序列建模尽可能多地替换RL流水线,以便产生一种更简单的方法,其有效性取决于序列模型的表示能力而不是算法的复杂性。
在基于学习的控制中,许多地方都出现了概率分布和密度的估计。这在基于模型的RL中最为明显,它用于训练预测模型,然后可用于规划或策略学习(Sutton, 1990; Silver et al., 2008; Fairbank, 2008; Deisenroth & Rasmussen, 2011; Lampe & Riedmiller, 2014; Heess et al., 2015b; Janner et al., 2020; Amos et al., 2021)。然而,它也在离线RL中占有重要地位,它用于估计用于约束学习策略的动作的条件分布,以避免数据集不支持的分布外行为(Fujimoto et al., 2019; Kumar et al., 2019a;Ghasemipour et al., 2021);模仿学习,用于拟合专家的行为以获得策略(Ross & Bagnell, 2010; Ross et al., 2011);以及其他领域,例如分层RL (Peng et al., 2017; Co-Reyes et al., 2018; Jiang et al., 2019)。在我们的方法中,我们训练一个单一的高容量序列模型来表示状态、动作和奖励序列的联合分布。这既可以作为预测模型,也可以作为行为策略(用于模仿)或行为约束(用于离线RL)。
我们的RL方法与先前使用学习模型进行规划的基于模型的方法最密切相关(Chua et al., 2018; Wang & Ba, 2020)。然而,虽然这些先前的方法通常需要额外的机制才能正常工作,例如在线环境中的集成(Kurutach et al., 2018; Buckman et al., 2018; Malik et al., 2019)或离线环境中的保守主义机制(Yu et al., 2020; Kidambi et al., 2020; Argenson & Dulac-Arnold, 2021),我们的方法不需要显式处理这些组件。对状态和动作进行联合建模已经提供了产生分布内动作的偏差,这避免了明确悲观的需要(Fujimoto et al., 2019; Kumar et al., 2019a; Ghasemipour et al., 2021; Nair et al., 2020; Jin et al., 2021; Yin et al., 2021; Dadashi et al., 2021)。我们的方法也不同于使用的动态模型架构中大多数基于模型的算法,全连接网络参数化对角协方差高斯分布是一种常见的选择(Chua et al., 2018),尽管最近的工作强调了自回归状态的有效性预测(Zhang et al., 2021)类似于Trajectory Transformer使用的预测。在最近提出的离线RL算法的背景下,我们的方法可以解释为基于模型的RL和策略约束的组合(Kumar et al., 2019a; Wu et al., 2019),尽管我们的方法不需要引入这样的明确的约束。在无模型强化学习的背景下,我们的方法也类似于最近提出的关于目标重新标记的工作(Andrychowicz et al., 2017; Rauber et al., 2019; Ghosh et al., 2021; Paster et al., 2021)和奖励条件反射(Schmidhuber, 2019; Srivastava et al., 2019; Kumar et al., 2019b)将所有过去的经验重新解释为具有适当语境化的有用演示。
在我们工作的同时,Chen et al. (2021)还提出了一种以序列预测为中心的RL方法,侧重于奖励条件,而不是Trajectory Transformer使用的基于波束搜索的规划。他们的工作进一步支持了一种可能性,即大容量序列模型可以应用于强化学习问题,而不需要通常与RL算法相关的组件。
3 Reinforcement Learning and Control as Sequence Modeling
在本节中,我们将描述序列模型的训练过程,并讨论如何将其用于控制。为简洁起见,我们将模型称为Trajectory Transformer,但强调在实现级别,我们的模型和搜索策略几乎与自然语言处理中常见的相同。因此,建模考虑较少关注架构设计,而更多关注如何表示轨迹数据——可能由连续状态和动作组成——以供离散token架构处理(Radford et al., 2018)。
3.1 Trajectory Transformer
我们方法的核心是将轨迹数据视为非结构化序列,以便通过Transformer架构进行建模。一条轨迹 τ 由 T 个状态、动作和标量奖励组成:
![]()
在连续状态和动作的情况下,我们独立离散每个维度。假设 N 维状态和 M 维动作,这将 τ 变成了长度为T(N+M+1)的序列:
![]()
所有token上的下标表示时间步骤,状态和动作上的上标表示维度(即,![]() 是状态在时间 t 的第 i 个维度)。虽然这种选择可能看起来效率低下,但它允许我们以更具表现力的方式对轨迹上的分布进行建模,而无需简化高斯转换等假设。
是状态在时间 t 的第 i 个维度)。虽然这种选择可能看起来效率低下,但它允许我们以更具表现力的方式对轨迹上的分布进行建模,而无需简化高斯转换等假设。
我们研究了两种简单的离散化方法:
- 均匀:给定维度的所有token对应于原始连续空间的固定宽度。假设每个维度的词汇量为V,状态维度 i 的标记覆盖宽度(max si - min si) / V的均匀间隔。
- 分位数:给定维度的所有token在经验数据分布下占等量的概率质量;每个token占训练集中每V个数据点中的1个。
均匀离散化的优点是它在原始连续空间中保留了欧氏距离的信息,这可能比训练数据分布更能反映问题的结构。然而,数据中的异常值可能会对离散化大小产生巨大影响,留下许多对应于零训练点的标记。分位数离散化方案确保所有标记都在数据中表示。我们在第4.2节对两者进行了实证比较。
我们的模型是一个镜像GPT架构的Transformer解码器(Radford et al., 2018)。我们使用的架构比大规模语言建模中通常使用的架构更小,由四层和四个自注意力头组成。(附录A中提供了完整的架构描述。) 使用用于训练序列模型的标准教师强制(teacher-forcing)程序(Williams & Zipser, 1989)进行训练。将Trajectory Transformer的参数表示为θ并将诱导条件概率表示为Pθ,训练期间最大化的目标是:
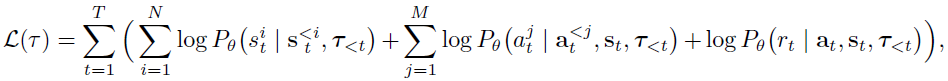
其中,我们使用τ<t表示从时间步骤 0 到 t-1 的轨迹,![]() 表示时间步骤 t 的状态的维度 0 到 i-1,类似地用于
表示时间步骤 t 的状态的维度 0 到 i-1,类似地用于![]() 。我们使用学习率为2.5 x 10-4的Adam优化器(Kingma & Ba, 2015)来训练参数θ。
。我们使用学习率为2.5 x 10-4的Adam优化器(Kingma & Ba, 2015)来训练参数θ。
3.2 Planning with Beam Search
我们现在描述如何将使用Trajectory Transformer的序列生成重新用于控制,重点关注三个设置:模仿学习、目标条件强化学习和离线强化学习。在自然语言处理中常规使用的序列模型解码方法之上,这些设置以越来越多的需要修改的方式列出。
为我们的规划技术提供基础的核心算法,即波束搜索,在通用序列的算法1中进行了描述。在Meister et al. (2020)的介绍之后,我们重载了log Pθ(· | x)来定义除了单个序列之外的一组序列的可能性:![]() 。我们使用( )表示空序列并表示连接。
。我们使用( )表示空序列并表示连接。
Imitation learning. 当目标是重现训练数据中的轨迹分布时,我们可以直接优化轨迹的概率。这种情况完全符合序列建模的目标,因此我们可以通过将条件输入 x 设置为当前状态 st (以及可选的先前历史τ<t)来使用算法1而无需修改。
这个过程的结果是一个标记化的轨迹 τ,从当前状态 st 开始,在数据分布下具有很高的概率。如果执行序列中的第一个动作 at 并重复波束搜索,我们就有一个后退的水平控制器。这种方法类似于基于长期模型的行为克隆变体,其中优化了整个轨迹以匹配参考行为的轨迹,而不仅仅是立即的状态条件动作。如果我们将预测序列长度设置为动作维度,我们的方法完全对应于具有自回归策略的最简单的行为克隆形式。
Goal-conditioned reinforcement learning. Transformer架构具有"因果"注意掩码,以确保预测仅依赖于序列中的先前标记。在自然语言的上下文中,这种设计对应于按照它们所说的线性顺序生成句子,而不是反映它们的层次句法结构的顺序(然而,参见Gu et al. 2019对使用自回归模型生成non-left-to-right的句子)。在轨迹预测的背景下,这种选择反而反映了物理因果关系,不允许未来事件影响过去。然而,给定未来的过去的条件概率仍然是明确定义的,这使我们不仅可以根据已经观察到的先前状态、动作和奖励,还可以根据我们希望发生的任何未来上下文来条件化样本。如果未来上下文是轨迹末端的状态,我们将轨迹解码为以下形式的概率:
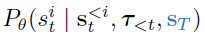
我们可以通过调节期望的最终状态 sT 直接将其用作达到目标的方法。如果我们总是以最终目标状态为条件的序列,我们可以保持下对角注意力掩码不变,并简单地将输入轨迹置换为{sT, s1, s2, ... , sT-1}。通过将目标状态添加到序列的开头,我们确保所有其他预测都可以在不修改标准注意力实现的情况下参与它。这种调节过程类似于使用监督学习来训练目标条件策略的先前方法(Ghosh et al., 2021),并且还与无模型RL中的重新标记技术有关(Andrychowicz et al., 2017)。在我们的框架中,它与序列建模中的标准子程序相同:根据可用证据推断最可能的序列。
Offline reinforcement learning.
4 Experiments
4.1 Model Analysis
4.2 Reinforcement Learning and Control
5 Discussion and Limitations
Appendix A Model and Training Specification
Appendix B Discrete Oracle
Appendix C Baseline performance sources
Appendix D Datasets
Appendix E Beam Search Hyperparameters


 浙公网安备 33010602011771号
浙公网安备 33010602011771号