
Decision Transformer: Reinforcement Learning via Sequence Modeling
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NeurIPS 2021
Abstract
我们引入了一个将强化学习(RL)抽象为序列建模问题的框架。这使我们能够利用Transformer架构的简单性和可扩展性,以及GPT-x和BERT等语言建模的相关进步。特别是,我们提出了Decision Transformer,一种将RL问题转换为条件序列建模的架构。与先前拟合价值函数或计算策略梯度的RL方法不同,Decision Transformer通过利用因果掩码的Transformer简单地输出最优动作。通过对期望回报(奖励)、过去状态和动作的自回归模型进行调节,我们的Decision Transformer模型可以生成实现期望回报的未来动作。尽管它很简单,但Decision Transformer在Atari、OpenAI Gym和Key-to-Door任务上的性能匹配或超过了最先进的model-free offline RL基准。
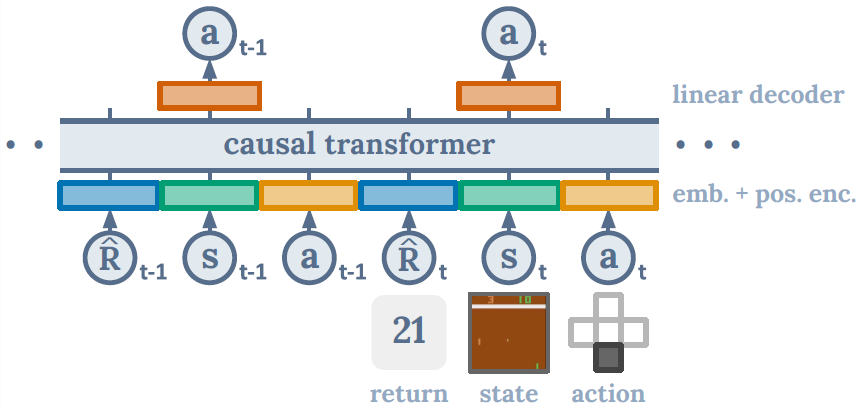
图1:Decision Transformer架构1。状态、动作和回报被馈送到特定于模态的线性嵌入中,并添加了位置回合时间步骤编码。Token被输入到GPT架构中,该架构使用因果自注意掩码自回归地预测动作。
1 我们的代码可以在以下网址获取:https://sites.google.com/berkeley.edu/decision-transformer

1 Introduction
最近的工作表明,Transformer [1]可以对语义概念的高维分布进行大规模建模,包括语言中的有效零样本泛化[2]和分布外图像生成[3]。鉴于此类模型成功应用的多样性,我们试图检查它们在形式化为强化学习(RL)的序列决策问题中的应用。与使用Transformer作为传统RL算法中组件的架构选择的先前工作[4, 5]相比,我们寻求研究是否生成轨迹建模——即对状态、动作和奖励序列的联合分布进行建模——可以替代传统的RL算法。
我们考虑了以下范式转变:我们将使用序列建模目标根据收集到的经验训练Transformer模型,而不是通过传统的RL算法(如时序差分(TD)学习[6])来训练策略。这将使我们能够绕过长期信度分配的bootstrap需求——从而避免已知会破坏RL稳定的“致命三元组”[6]之一。它还避免了像TD学习中通常所做的那样对未来奖励进行折扣的需要,这可能会导致不良的短视行为。此外,我们可以利用现有的广泛用于语言和视觉的、易于扩展的Transformer框架,利用大量研究稳定训练Transformer模型的工作。
除了展示出对长序列进行建模的能力外,Transformer还有其他优势。Transformer可以通过自注意力直接执行信度分配,而Bellman备份则缓慢传播奖励并且容易产生“干扰”信号[7]。这可以使Transformer在存在稀疏或分散注意力的奖励时仍然有效地工作。最后,经验证据表明,Transformer建模方法可以对广泛分布的行为进行建模,从而实现更好的泛化和迁移[3]。
我们通过考虑offline RL来探索我们的假设,我们将从次优数据中为智能体分配学习策略——从固定且有限的经验中产生最大有效的行为。由于误差传播和价值高估[8],这项任务传统上具有挑战性。但是,在使用序列建模目标进行训练时,这是一项自然的任务。通过在状态、动作和回报序列上训练自回归模型,我们将策略采样简化为自回归生成建模。我们可以通过选择所需的回报token来指定策略的专业知识——查询哪些“技能”,作为生成的提示。
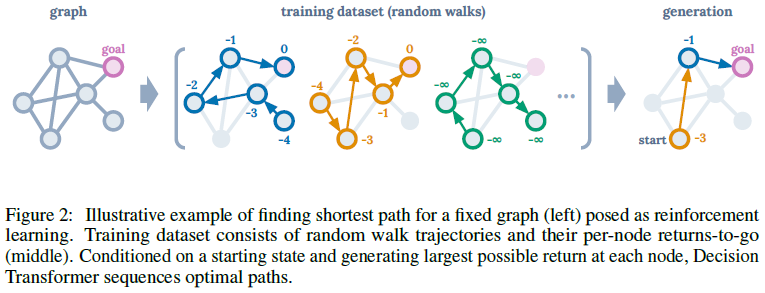
Illustrative example. 为了对我们的提议有一个直觉,考虑在有向图上找到最短路径的任务,这可以作为RL问题提出。当智能体在目标节点时奖励为0,否则为-1。我们训练了一个GPT [9]模型来预测一系列回报结果(未来奖励的总和)、状态和动作中的下一个token。仅在随机游走数据上进行训练——没有专家演示——我们可以在测试时通过添加一个先验来生成最优轨迹以产生最高可能的回报(参见附录中的更多细节和经验结果),然后通过条件生成相应的动作序列。因此,通过将序列建模工具与事后(hindsight)回报信息相结合,我们无需动态规划即可实现策略改进。
受此观察的启发,我们提出了Decision Transformer,我们使用GPT架构对轨迹进行自回归建模(如图1所示)。我们通过在Atari [10]、OpenAI Gym [11]和Key-to-Door [12]环境中的offline RL基准上评估Decision Transformer来研究序列建模是否可以执行策略优化。我们表明,在不使用动态编程的情况下,Decision Transformer可以匹配或超过最先进的model-free offline RL算法的性能[13, 14]。此外,在需要长期信度分配的任务中,Decision Transformer的性能优于RL基线。通过这项工作,我们旨在将序列建模和Transformer与RL联系起来,并希望序列建模成为RL的强大算法范式。
2 Preliminaries
2.1 Offline reinforcement learning

2.2 Transformers
Transformer是由Vaswani等人[1]提出的一种有效建模序列数据的架构。这些模型由带有残差连接的堆叠自注意力层组成。每个自注意力层接收与唯一输入token对应的n个嵌入![]() ,并输出n个嵌入
,并输出n个嵌入![]() ,保留输入维度。第 i 个token通过线性变换映射到键ki、查询qi和值vi。自注意力层的第 i 个输出是通过查询qi和其他键kj之间的归一化点积对值vj加权来给出的:
,保留输入维度。第 i 个token通过线性变换映射到键ki、查询qi和值vi。自注意力层的第 i 个输出是通过查询qi和其他键kj之间的归一化点积对值vj加权来给出的:
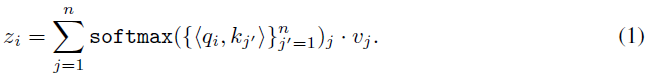
正如我们稍后将看到的,这允许层通过查询和关键向量的相似性(最大化点积)隐式形成状态-回报关联来分配"信度"。在这项工作中,我们使用GPT架构[9],它使用因果自注意掩码修改了Transformer架构以启用自回归生成,仅用序列中的前一个token替换n个token上的总和/softmax (![]() )。我们将其他架构细节推迟到原始论文中。
)。我们将其他架构细节推迟到原始论文中。

3 Method
在本节中,我们介绍了Decision Transformer,它在对Transformer架构进行最小修改的情况下对轨迹进行自回归建模,如图1和算法1所示。
Trajectory representation. 我们选择轨迹表示的关键要求是它应该使Transformer能够学习有意义的模式,并且我们应该能够在测试时有条件地生成动作。对奖励进行建模并非易事,因为我们希望模型根据未来期望的回报而不是过去的奖励来生成动作。因此,我们不是直接提供奖励,而是为模型提供回报![]() 。这导致以下轨迹表示可以进行自回归训练和生成:
。这导致以下轨迹表示可以进行自回归训练和生成:
![]()
在测试时,我们可以指定所需的性能(例如,1表示成功或0表示失败)以及环境起始状态,作为启动生成的条件信息。在为当前状态执行生成的动作后,我们将目标回报减少获得的奖励并重复直到回合终止。
Architecture. 我们将最后的K个时间步骤输入到Decision Transformer中,总共有3K个token(每种模式一个:return-to-go、状态或动作)。为了获得token嵌入,我们为每种模态学习了一个线性层,它将原始输入投影到嵌入维度,然后进行层归一化[15]。对于具有视觉输入的环境,状态被输入卷积编码器而不是线性层。此外,每个时间步骤的嵌入都会被学习并添加到每个token中——注意这与Transformer使用的标准位置嵌入不同,因为一个时间步骤对应于三个token。然后这些token由GPT [9]模型处理,该模型通过自回归建模预测未来的动作token。
Training. 我们得到了一个offline轨迹数据集。我们从数据集中抽取序列长度为K的小批量。对应于输入token st的预测头被训练以预测at——离散动作的交叉熵损失或连续动作的均方误差——并且每个时间步骤的损失被平均。尽管在我们的框架内很容易允许(如第5.4节所示)并且对于未来的工作来说这将是一项有趣的研究,但我们并没有发现预测状态或收益来提高性能。
4 Evaluations on Offline RL Benchmarks
在本节中,我们研究了Decision Transformer相对于专用offline RL和模仿学习算法的性能。特别是,我们的主要比较点是基于TD学习的model-free offline RL算法,因为我们的Decision Transformer架构本质上也是model-free。此外,TD学习是RL中用于提高样本效率的主要范例,并且在许多model-based RL算法中作为子程序的突出特点[16, 17]。我们还与行为克隆和变体进行了比较,因为它还涉及类似于我们的基于可能性的策略学习公式。确切的算法取决于环境,但我们的动机如下:
- TD学习:这些方法中的大多数使用动作空间约束或价值悲观主义,将是与Decision Transformer最忠实的比较,代表标准RL方法。一种最先进的model-free方法是Conservative Q-Learning (CQL) [14],作为我们的主要比较。此外,我们还与其他先前的model-free RL算法(如BEAR [18]和BRAC [19])进行了比较。
- 模仿学习:该机制类似地使用监督损失进行训练,而不是Bellman备份。我们在这里使用行为克隆,并在第5.1节中包含更详细的讨论。
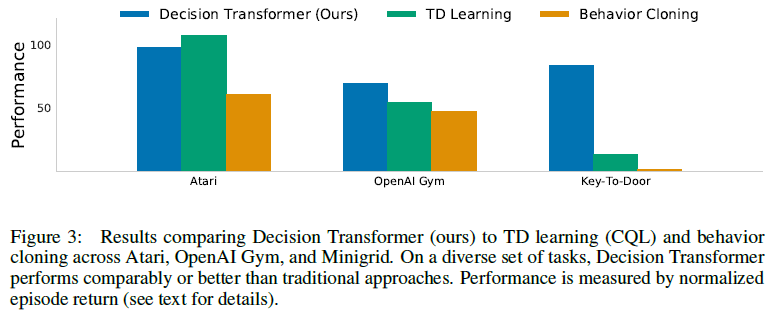
我们评估离散(Atari [10])和连续(OpenAI Gym [11])控制任务。前者涉及高维观察空间,需要长期的信度分配,而后者需要细粒度的连续控制,代表着多样化的任务集。我们的主要结果总结在图3中,其中我们显示了每个域的平均归一化性能。
4.1 Atari
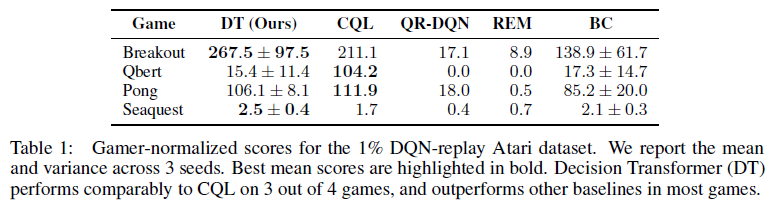
Atari基准测试[10]具有挑战性,因为它的高维视觉输入以及由于动作和结果奖励之间的延迟而导致的信度分配困难。根据Agarwal et al. [13],我们在DQN-replay数据集中所有样本的1%上评估我们的方法,代表在线DQN智能体[20]在训练期间观察到的5000万次转换中的50万次;我们报告了3颗种子的均值和标准差。我们遵循Hafner et al. [21]的协议,基于专业玩家对分数进行标准化,其中100代表职业玩家得分,0代表随机策略。
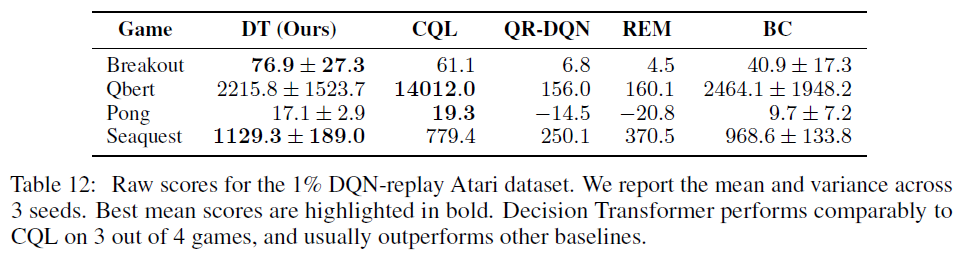
我们在Agarwal et al. [13]评估的四个Atari任务(Breakout, Qbert, Pong和Seaquest)上与CQL [14]、REM [13]和QR-DQN [22]进行比较。我们对Decision Transformer使用K = 30的上下文长度(Pong的K = 50除外)。我们还报告了行为克隆(BC)的性能,它使用与Decision Transformer相同的网络架构和超参数,但没有return-to-go条件2。对于CQL、REM和QR-DQN基准,我们直接从CQL和REM论文中报告数字。我们在表1中显示了结果。我们的方法在4个游戏中有3个与CQL具有竞争力,并且在所有4个游戏中都优于或匹配REM、QR-DQN和BC。
2 我们还尝试像之前的工作一样使用K = 1的MLP,但发现这比Transformer更差。
4.2 OpenAI Gym
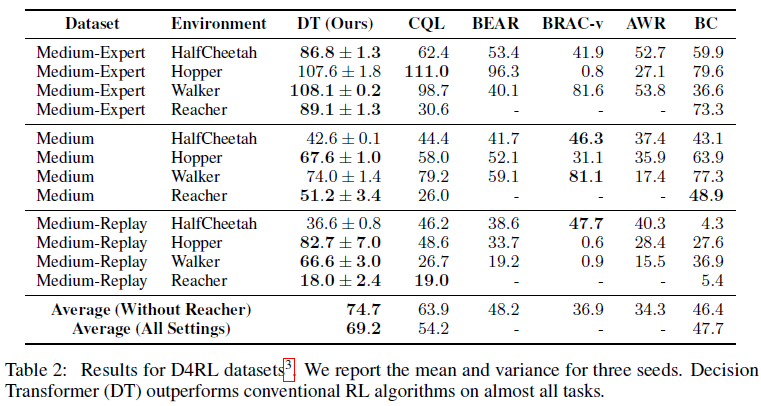
在本节中,我们考虑D4RL基准[23]中的连续控制任务。我们还考虑了一个不属于基准测试的2D reacher环境,并使用与D4RL基准测试类似的方法生成数据集。Reacher是一个以目标为条件的任务,奖励稀少,因此它代表了与标准运动环境(HalfCheetah、Hopper和Walker)不同的设置。不同的数据集设置如下所述。
1. Medium:由"中等"策略生成的100万个时间步骤,达到专家策略分数的大约三分之一。
2. Medium-Replay:被训练以执行中等策略的智能体的回放缓存(在我们的环境中大约25k-400k个时间步骤)。
3. Medium-Expert:中等策略生成的100万个时间步骤与专家策略生成的100万个时间步骤相连接。
我们与CQL [14]、BEAR [18]、BRAC [19]和AWR [24]进行比较。CQL代表了model-free offline RL中的最先进水平,这是价值悲观主义的TD学习的实例。根据Fu et al. [23]的说法,分数被归一化,因此100代表专家策略。CQL数字是从原始论文中报告的;BC数字由我们管理;其他方法是从D4RL论文中报道的。我们的结果如表2所示。Decision Transformer在大多数任务中取得了最高分,并且在其余任务中与最先进的技术相媲美。
3 鉴于CQL通常是最强的TD学习方法,对于Reacher,我们只运行CQL基准。
5 Discussion
5.1 Does Decision Transformer perform behavior cloning on a subset of the data?
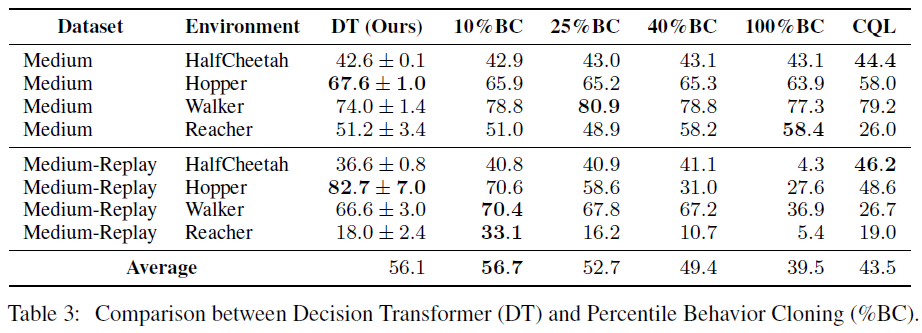
在本节中,我们试图深入了解Decision Transformer是否可以被认为是对具有一定回报的数据子集执行模仿学习。为了研究这一点,我们提出了一种新方法,百分位行为克隆(%BC),我们仅在数据集中前X%的时间步骤上运行行为克隆,按回合回报排序。百分位数X%在对整个数据集进行训练的标准BC (X = 100%)与仅克隆最优观察轨迹(X → 0%)之间进行插值,在通过训练更多数据和训练专门模型来更好地泛化之间进行权衡专注于数据的理想子集。
我们在表3中展示了将%BC与Decision Transformer和CQL进行比较的完整结果,覆盖X ∈ [10%, 25%, 40%, 100%]。请注意,选择用于克隆的最优子集的唯一方法是使用环境中的rollout进行评估,因此%BC不是一种现实的方法;相反,它有助于深入了解Decision Transformer的行为。当数据丰富时(如在D4RL机制中),我们发现%BC可以匹配或击败其他offline RL方法。在大多数环境中,Decision Transformer与最优%BC的性能相媲美,这表明它可以在对整个数据集分布进行训练后磨练特定子集。
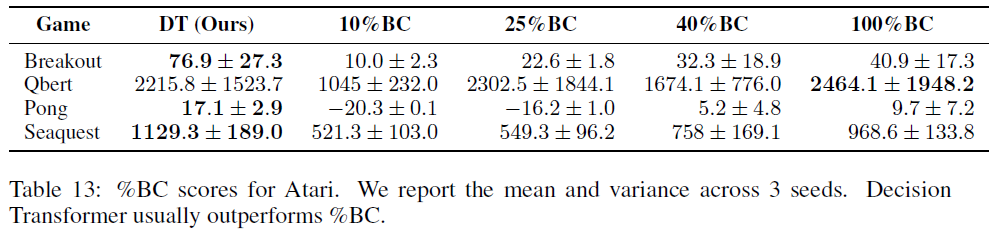
相比之下,当我们研究低数据机制时——例如Atari,我们使用1%的回放缓存作为数据集——%BC很弱(如表4所示)。这表明在数据量相对较少的场景中,Decision Transformer可以通过使用数据集中的所有轨迹来提高泛化能力,从而优于%BC,即使这些轨迹与回报条件目标不同。我们的结果表明,Decision Transformer比简单地对数据集的子集执行模仿学习更有效。在我们考虑的任务中,Decision Transformer要么优于%BC,要么与%BC竞争,而无需选择最优子集。

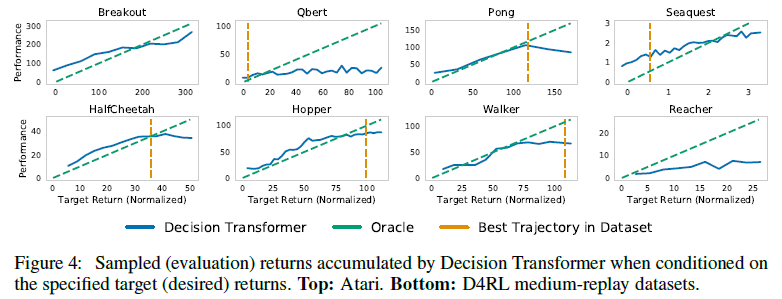
5.2 How well does Decision Transformer model the distribution of returns?
我们通过在大范围内改变期望的目标回报来评估Decision Transformer理解return-to-go token的能力——评估Transformer的多任务分布建模能力。图4显示了智能体在评估过程中针对不同的目标回报值累积的平均采样回报。在每项任务中,期望的目标回报和真实观察到的回报是高度相关的。在Pong、HalfCheetah和Walker等任务中,Decision Transformer生成的轨迹几乎完全符合期望的回报(如与oracle线的重叠所示)。此外,在Seaquest等一些Atari任务中,我们可以提示Decision Transformer的回报高于数据集中可用的最大回合回报,这表明Decision Transformer有时能够进行外推。
5.3 What is the benefit of using a longer context length?
为了评估访问先前状态、动作和回报的重要性,我们消融了上下文长度K。这很有趣,因为通常认为先前的状态(即K = 1)对于帧堆叠时的强化学习算法来说已经足够了像我们一样被使用。表5显示,当K = 1时,Decision Transformer的性能明显更差,表明过去的信息对Atari游戏有用。一个假设是,当我们表示策略分布时——比如序列建模——上下文允许Transformer识别哪个策略产生了动作,从而实现更好的学习和/或改进训练动态。

5.4 Does Decision Transformer perform effective long-term credit assignment?
为了评估我们模型的长期信度分配能力,我们考虑了Mesnard et al. [12]提出的Key-to-Door环境的变体。这是一个基于网格的环境,具有三个阶段的序列:(1) 在第一阶段,智能体被放置在一个带钥匙的房间中;(2) 然后,智能体被放置在一个空房间里;(3) 最后,智能体被放置在一个有门的房间里。智能体在第三阶段到达门口时会收到二值奖励,但前提是它在第一阶段拿起钥匙。这个问题很难分配信度,因为信度必须从回合的开头传播到结尾,跳过中间采取的动作。
我们在通过应用随机动作生成的轨迹数据集上进行训练,并在表6中报告成功率。此外,对于Key-to-Door环境,我们使用整个回合长度作为上下文,而不是像另一个一样具有固定的内容窗口环境。使用后见(highsight)回报信息的方法:我们的Decision Transformer模型和%BC(仅在成功的回合上训练)能够学习有效的策略——产生接近最优的路径,尽管只对随机游走进行训练。TD学习(CQL)无法在所涉及的长期范围内有效地传播Q值并且性能不佳。

5.5 Can transformers be accurate critics in sparse reward settings?
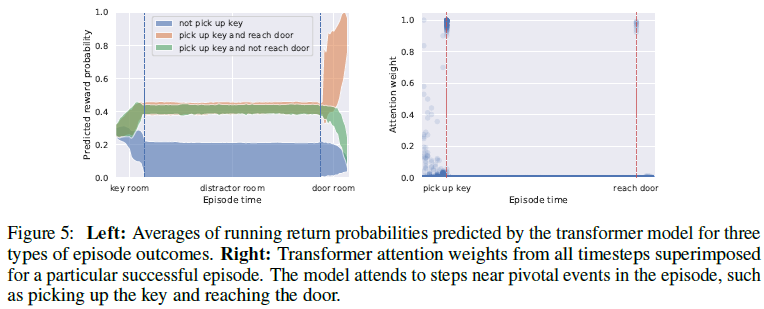
在前面的部分中,我们确定了Decision Transformer可以产生有效的策略(actor)。我们现在评估Transformer模型是否也可以成为有效的critic。我们将Decision Transformer修改为在Key-to-Door环境中输出除了动作token之外的回报token。此外,没有给出第一个回报token,而是对其进行预测(即模型学习初始分布![]() ),类似于标准的自回归生成模型。我们发现,Transformer会根据回合期间的事件不断更新奖励概率,如图5(左)所示。此外,我们发现Transformer参与了这一回合中的关键事件(拿起钥匙或到达门),如图5(右)所示,表明形成了Raposo et al. [25]所讨论的状态奖励关联并实现准确的价值预测。
),类似于标准的自回归生成模型。我们发现,Transformer会根据回合期间的事件不断更新奖励概率,如图5(左)所示。此外,我们发现Transformer参与了这一回合中的关键事件(拿起钥匙或到达门),如图5(右)所示,表明形成了Raposo et al. [25]所讨论的状态奖励关联并实现准确的价值预测。
5.6 Does Decision Transformer perform well in sparse reward settings?
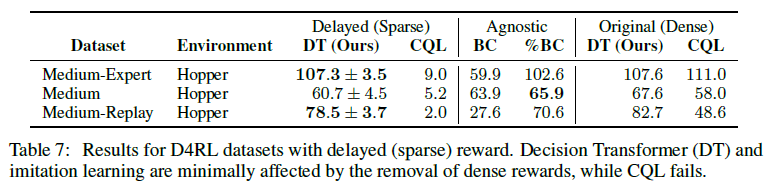
TD学习算法的一个已知弱点是它们需要密集的奖励才能表现良好,这可能是不切实际的和/或昂贵的。相比之下,Decision Transformer可以提高这些设置中的鲁棒性,因为它对奖励的密度做出了最小的假设。为了评估这一点,我们考虑了D4RL基准测试的延迟回报版本,其中智能体在轨迹上没有收到任何奖励,而是在最后的时间步骤中收到轨迹的累积奖励。我们的延迟回报结果如表7所示。延迟回报对Decision Transformer的影响最小;并且由于训练过程的性质,而模仿学习方法与奖励无关。虽然TD学习崩溃了,但Decision Transformer和%BC仍然表现良好,这表明Decision Transformer对延迟奖励的鲁棒性更强。
5.7 Why does Decision Transformer avoid the need for value pessimism or behavior regularization?
Decision Transformer和之前的offline RL算法之间的一个关键区别是,我们不需要策略正则化或保守主义来实现良好的性能。我们的猜想是基于TD学习的算法学习了一个近似价值函数,并通过优化这个价值函数来改进策略。这种优化学习函数的行为可能会加剧和利用价值函数逼近中的任何不准确性,从而导致策略改进失败。由于Decision Transformer不需要使用学习函数作为目标进行显式优化,因此它避免了正则化或保守主义的需要。
5.8 How can Decision Transformer benefit online RL regimes?
offline RL和行为建模能力有可能为下游任务启用样本高效的online RL。研究从offline到online过渡的工作通常发现基于可能性的方法,如我们的序列建模目标,更成功[26, 27]。因此,尽管我们在这项工作中研究了offline RL,但我们相信Decision Transformer可以通过作为行为生成的强大模型来有意义地改进online RL方法。例如,Decision Transformer可以用作强大的"记忆引擎",并与强大的探索算法(如Go-Explore [28])结合使用,具有同时建模和生成多种行为的潜力。
6 Related Work
6.1 Offline reinforcement learning
为了减轻offline RL中分布变化的影响,先前的算法要么 (a) 限制策略动作空间[29, 30, 31],要么 (b) 将价值悲观主义[29, 14]合并,或 (c) 将悲观主义合并到学习中动力学模型[32, 33]。由于我们不使用Decision Transformer来显式学习动态模型,因此我们主要在工作中与model-free算法进行比较;特别是,添加动态模型往往会提高model-free算法的性能。另一项工作探索通过学习一组与任务无关的技能,使用基于可能性的方法[34, 35, 36, 37]或通过最大化互信息[38, 39, 40],从offline数据集中学习广泛的行为分布。我们的工作类似于基于可能性的方法,它不使用迭代Bellman更新——尽管我们使用更简单的序列建模目标而不是变分方法,并使用奖励来条件生成行为。
6.2 Supervised learning in reinforcement learning settings
一些先前的强化学习方法与静态监督学习更相似,例如Q学习[41, 42],它仍然使用迭代备份,或者基于可能性的方法,例如行为克隆,它们不使用(在上一节中讨论)。最近的工作[43, 44, 45]研究了"倒置"强化学习(UDRL),这类似于我们在寻求以目标回报为条件的监督损失建模行为的方法。我们工作的一个关键区别是动机转向序列建模而不是监督学习:虽然实际方法主要在上下文长度和架构上有所不同,但序列建模即使没有获得奖励也能实现行为建模,其风格与语言相似[9]或图像[46],并且已知可以很好地缩放[2]。Kumar et al. [44]提出的方法与我们的K = 1的方法最相似,我们发现序列建模/长上下文的表现优于(参见第5.3节)。Ghosh et al. [47]扩展了先前的UDRL方法以使用状态目标条件,而不是奖励,以及Paster et al. [48]进一步使用具有状态目标条件的LSTM进行目标条件online RL设置。
在我们工作的同时,Janner et al. [49]提出了Trajectory Transformer,它类似于Decision Transformer,但另外使用状态和回报预测,以及离散化,其中包含model-based的组件。我们相信,除了我们的结果之外,他们的实验突出了序列建模成为强化学习普遍适用的想法的潜力。
6.3 Credit assignment
许多工作通过状态关联研究了更好的信度分配,学习了一种分解奖励函数的架构,使得某些"重要"状态构成了大部分信度[50, 51, 12]。他们使用学习到的奖励函数来改变actor-critic算法的奖励,以帮助在长范围内传播信号。特别是,与我们的长期设置类似,一些工作特别表明这种状态关联架构可以在延迟奖励设置中表现更好[52, 7, 53, 25]。相比之下,我们允许这些属性自然地出现在Transformer架构中,而无需明确学习奖励函数或critic。
6.4 Conditional language generation
各种工作已经研究了图像[54]和语言[55, 56]的引导生成。几项工作[57, 58, 59, 60, 61, 62]已经探索了用于可控文本生成的模型的训练或微调。类条件语言模型也可用于学习判别器以指导生成[63, 55, 64, 65]。然而,这些方法大多假设恒定的"类",而在强化学习中,奖励信号是随时间变化的。此外,更自然地提示模型期望的目标回报并随着时间的推移通过观察到的回报不断减少它,因为Transformer模型和环境共同生成轨迹。
6.5 Attention and transformer models
Transformer [1]已成功应用于自然语言处理[66, 9]和计算机视觉[67, 68]中的许多任务。然而,在RL中,Transformer的研究相对较少,主要是由于问题的不同性质,例如训练中的更高方差。Zambaldi et al. [5]表明,使用关系推理增强Transfomer可以提高组合环境和Ritter et al. [69]的性能表明迭代自注意力允许RL智能体更好地利用回合式记忆。Parisotto et al. [4]讨论了在高方差RL设置中更稳定地训练Transfomer的设计决策。与我们的工作不同,这些仍然使用actor-critic算法进行优化,专注于架构的新颖性。此外,在模仿学习中,一些工作研究了将Transfomer作为LSTM的替代品:Dasari和Gupta [70]研究oneshot模仿学习,而Abramson et al. [71]结合语言和图像模式来生成文本条件行为。
7 Conclusion
我们提出了Decision Transformer,旨在统一语言/序列建模和强化学习中的思想。在标准的offline RL基准测试中,我们展示了Decision Transformer可以匹配或优于专门为offline RL设计的强大算法,而只需对标准语言建模架构进行最少的修改。
我们希望这项工作能够激发更多关于将大型Transformer模型用于RL的研究。我们使用了在我们的实验中有效的简单监督损失,但大规模数据集的应用可以从自监督的预训练任务中受益。此外,可以考虑对回报、状态和动作进行更复杂的嵌入——例如,以回报分布为条件来模拟随机设置而不是确定性回报。Transformer模型也可用于对轨迹的状态演化进行建模,有可能作为,model-based RL的替代品,我们希望在未来的工作中对此进行探索。
对于实际应用,重要的是要了解Transformer在MDP设置中所犯的错误类型以及可能的负面后果,这些都是未充分探索的。考虑我们训练模型的数据集也很重要,这可能会增加破坏性偏差,特别是当我们考虑使用更多可能来自可疑来源的数据来研究增强RL智能体时。例如,恶意actor的奖励设计可能会产生意想不到的行为,因为我们的模型通过以期望的回报为条件来产生行为。
A Experimental Details
实验代码可以在补充材料中找到。
A.1 Atari
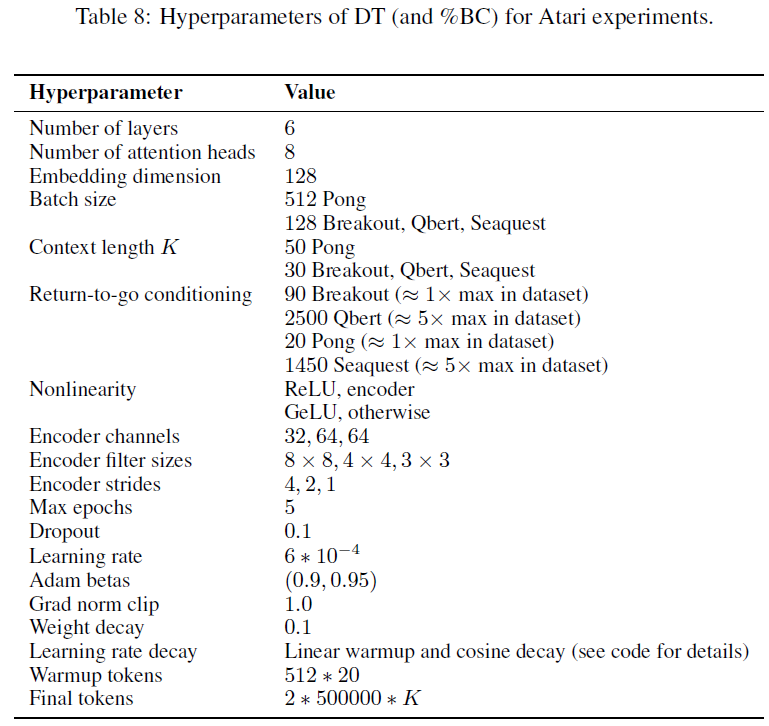
我们基于minGPT (https://github.com/karpathy/minGPT)为Atari游戏构建了我们的Decision Transformer实现,这是GPT的公开重新实现。我们使用其字符级GPT示例(https://github.com/karpathy/minGPT/blob/master/play_char.ipynb)中的大多数默认超参数。我们减少了批大小(Pong除外)、块大小、层数、注意力头和嵌入维度,以加快训练速度。为了处理观察结果,我们使用了Mnih et al. [20]的DQN编码器带有一个额外的线性层来投影到嵌入维度。
对于return-to-go调节,我们使用1或5倍的数据集最大回报,但原则性的return-to-go调节存在更多可能性。在Atari实验中,我们在嵌入每种模态后使用Tanh而不是LayerNorm(如第3节所述),但这并没有对性能产生显著影响。超参数的完整列表可以在表8中找到。、
A.2 OpenAI Gym
A.2.1 Decision Transformer
A.2.2 Behavior Cloning
A.3 Graph Shortest Path
B Atari Task Scores
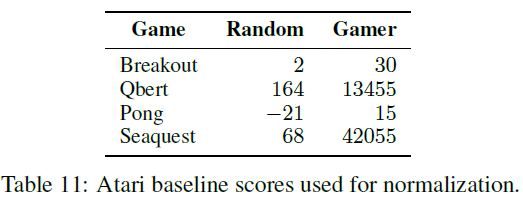
表11显示了Hafner et al. [21]用于标准化的标准化分数。表12和表13分别显示了对应于表1和表4的原始分数。对于%BC分数,我们使用与Decision Transformer相同的超参数进行公平比较。对于REM和QR-DQN,Agarwal et al. [13]和Kumar et al. [14]之间存在细微差异;我们报告REM作者提供给我们的原始数据。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人