Generative Adversarial Imitation Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain.
Abstract
考虑从示例专家行为中学习策略,而不与专家交互或访问强化信号。一种方法是通过逆强化学习恢复专家的成本函数,然后通过强化学习从该成本函数中提取策略。这种方法是间接的并且可能很慢。我们提出了一个新的通用框架,用于直接从数据中提取策略,就好像它是通过逆强化学习之后的强化学习获得的一样。我们表明,我们框架的某个实例在模仿学习和生成对抗网络之间进行了类比,从中我们得出了一种无模型模仿学习算法,该算法在模仿大型、高维环境中的复杂行为。
1 Introduction
我们对模仿学习的特定设置感兴趣——从专家演示中学习执行任务的问题——其中学习者只获得专家的轨迹样本,不允许在训练时向专家查询更多数据, 并且不提供任何类型的强化信号。有两种主要的方法适合这种设置:行为克隆[18],它将策略学习为来自专家轨迹的状态-动作对的监督学习问题;和逆强化学习[23, 16],它找到了专家唯一最优的成本函数。
行为克隆虽然非常简单,但由于协变量偏移引起的复合误差,只有在处理大量数据时才会成功[21, 22]。另一方面,逆强化学习(IRL)学习了一个成本函数,该函数将整个轨迹优先于其他轨迹,因此对于适合单时间步骤决策的方法来说,复合误差不是问题。因此,IRL在广泛的问题上取得了成功,从预测出租车司机的行为[29]到规划四足机器人的脚步[20]。
不幸的是,许多IRL算法运行起来非常昂贵,需要在内部循环中进行强化学习。因此,将IRL方法扩展到大型环境一直是近期工作的重点[6, 13]。然而,从根本上说,IRL学习了一个成本函数,它解释了专家的行为,但并不直接告诉学习者如何行动。鉴于学习者的真正目标通常是模仿专家采取行动——事实上,许多IRL算法都是根据他们学习的成本的最优动作的质量来评估的——那么,如果这样做可能会产生大量的计算开销,但不能直接产生动作,为什么我们必须学习成本函数?
我们需要一种算法,它可以通过直接学习策略来明确地告诉我们如何采取行动。为了开发这样的算法,我们从第3节开始,我们在其中描述了通过在最大因果熵IRL [29, 30]学习的成本函数上运行强化学习给出的策略。我们的表征引入了一个框架,用于直接从数据中学习策略,绕过任何中间IRL步骤。
然后,我们使用新的无模型模仿学习算法在第4节和第5节中实例化我们的框架。我们表明,我们得到的算法与生成对抗网络密切相关[8],这是一种来自深度学习社区的技术,最近在自然图像分布建模方面取得了成功:我们的算法利用生成对抗训练来拟合状态和动作的分布定义专家行为。我们在第6节中测试了我们的算法,我们发现它在针对不同数量的专家数据的复杂、高维基于物理的控制任务的训练策略方面远远优于竞争方法。
2 Background

3 Characterizing the induced optimal policy




让我们总结一下我们的结论。首先,IRL是占用度量匹配问题的对偶,并且恢复的成本函数是对偶最优的。经典的IRL算法在内循环中反复解决强化学习,例如Ziebart et al. [29]的算法在内部循环中运行值迭代的变体,可以解释为双上升的形式,其中一个重复解决具有固定对偶值(成本)的原始问题(强化学习)。如果解决无约束的原始问题是有效的,那么双上升是有效的,但在IRL的情况下,它相当于强化学习!其次,诱导最优策略是原始最优策略。诱导最优策略是通过在IRL之后运行RL获得的,这正是从对偶最优中恢复原始最优的行为;即,优化拉格朗日,对偶变量固定在对偶最优值。强对偶性意味着这种诱导的最优策略确实是原始最优策略,因此与专家相匹配。IRL传统上被定义为寻找成本函数的行为,使得专家策略是唯一最优的,但我们也可以将IRL视为一个试图诱导与专家的占用度量相匹配的策略的过程。
4 Practical occupancy measure matching
我们在命题3.2中看到,如果Ψ是常数,则最终的原始问题(7)只需将占用度量与所有状态和动作的专家相匹配。这样的算法实际上没有用。实际上,专家轨迹分布将仅作为有限的样本集提供,因此在大型环境中,大多数专家的占用度量值会很小,精确的占用度量匹配将迫使学习的策略很少访问这些看不见的状态-动作对仅仅是因为缺乏数据。此外,在我们想使用函数逼近来学习参数化策略πθ的情况下,当环境很大时,寻找合适的θ的优化问题将具有难以解决的大量约束:与S×A中的点一样多的约束。



该算法主要依赖于TRPO策略步骤,这是一个自然梯度步骤,受约束以确保![]() 不会偏离
不会偏离![]() 太远,这是通过在采样中的状态上平均的两个策略之间的KL散度来衡量的轨迹。这种精心构建的步进方案确保算法不会因估计梯度(12)中的高噪声而发散。我们将读者推荐给Schulman et al. [24]以了解有关TRPO的更多详细信息。
太远,这是通过在采样中的状态上平均的两个策略之间的KL散度来衡量的轨迹。这种精心构建的步进方案确保算法不会因估计梯度(12)中的高噪声而发散。我们将读者推荐给Schulman et al. [24]以了解有关TRPO的更多详细信息。
使用TRPO步进方案,Ho et al.能够在具有数百个观察维度的环境中训练具有线性成本函数类(10)的学徒学习的大型神经网络策略。然而,他们对这些线性成本函数类的使用将他们的方法限制在这些类可以很好地描述专家行为的设置中。我们将利用他们的算法开发一种模仿学习方法,该方法既可以扩展到大型环境,又可以模仿任意复杂的专家行为。为此,我们首先转向提出一种新的正则化器ψ,它比对应于Clinear和Cconvex (10)的正则化器具有更多的表达能力。
5 Generative adversarial imitation learning
如第4节所述,常数正则化器导致模仿学习算法与占用度量完全匹配,但在大型环境中难以处理。另一方面,线性成本函数类(10)的指标正则化器会导致算法在没有仔细调整的情况下无法精确匹配占用度量,但在大型环境中是易于处理的。我们提出了以下新的成本正则化器,它结合了了两者的优势,我们将在接下来的部分中展示:
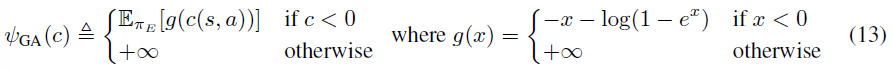
这个正则化器对成本函数 c 施加了较低的惩罚,将一定数量的负成本分配给专家状态-动作对;然而,如果 c 将较大的成本(接近于零,这是ΨGA可行的成本上限)分配给专家,那么ΨGA将严重惩罚 c。ΨGA的一个有趣特性是它是专家数据的平均值,因此可以适应任意专家数据集。第4节中描述的线性学徒学习算法使用的指标正则化器δC始终是固定的,不能像ΨGA那样适应数据。然而,也许ΨGA和δC之间最重要的区别是δC迫使成本位于由有限多个基函数跨越的小子空间中,而ΨGA允许任何成本函数,只要它在所有地方都是负的。
我们选择ΨGA的动机是以下事实,如附录所示(推论A.1.1):
![]()
其中上确界范围超过判别分类器D : S×A → (0, 1)。公式(14)与区分状态-动作对 π 和πE的二值分类问题的最佳负对数损失成正比。事实证明,这种最优损失是,直到恒定的移位和缩放,Jensen-Shannon散度![]() ,这是归一化占用分布之间的平方度量。将因果熵 H 视为由λ ≥ 0控制的策略正则化器,并为清楚起见放弃1 - γ占用测量归一化,我们获得了一种新的模仿学习算法:
,这是归一化占用分布之间的平方度量。将因果熵 H 视为由λ ≥ 0控制的策略正则化器,并为清楚起见放弃1 - γ占用测量归一化,我们获得了一种新的模仿学习算法:
![]()
这找到了一个策略,其占用度量最小化与专家的Jensen-Shannon散度。公式(15)最小化了占用测量之间的真实度量,因此,与线性学徒学习算法不同,它可以准确地模仿专家策略。
Algorithm 公式(15)在模仿学习和生成对抗网络[8]之间建立了联系,后者通过混淆判别分类器 D 来训练生成模型 G。D 的工作是区分 G 生成的数据分布和真实的数据分布。当 D 无法区分 G 生成的数据与真实数据时,则 G 已成功匹配真实数据。在我们的设置中,学习者的占用度量ρπ类似于 G 生成的数据分布,而专家的占用度量![]() 类似于真实的数据分布。
类似于真实的数据分布。
我们现在提出一种实用的模仿学习算法,称为生成对抗模仿学习或GAIL(算法1),旨在在大型环境中工作。GAIL解决公式(15)通过找到表达式的鞍点(π, D):
![]()
其中 π 和 D 都使用函数逼近器表示:GAIL适合参数化策略πθ、权重 θ 和鉴别器网络Dw:S×A → (0, 1),权重为 w。GAIL在 w 上的Adam [11]梯度步骤之间交替以增加关于 D 的公式(16)和在 θ 上的TRPO步骤以减少关于 π 的公式(16) (我们在附录A.2中推导出因果熵梯度的估计量![]() )。TRPO步骤与Ho et al. [10]的学徒学习算法具有相同的目的:它可以防止由于策略梯度中的噪声而导致策略发生太大变化。判别器网络可以被解释为为策略提供学习信号的局部成本函数——具体而言,采取降低成本函数c(s,a) = log D(s,a)的期望成本的策略步骤将朝着由判别器分类的状态-动作空间的类似专家的区域。
)。TRPO步骤与Ho et al. [10]的学徒学习算法具有相同的目的:它可以防止由于策略梯度中的噪声而导致策略发生太大变化。判别器网络可以被解释为为策略提供学习信号的局部成本函数——具体而言,采取降低成本函数c(s,a) = log D(s,a)的期望成本的策略步骤将朝着由判别器分类的状态-动作空间的类似专家的区域。

6 Experiments
我们针对9个基于物理的控制任务的基线评估了GAIL,范围从经典RL文献中的低维控制任务——cartpole [2]、acrobot [7]和mountain car [15]——到困难的高维任务(例如3D人形运动),最近才通过无模型强化学习解决[25, 24]。除经典控制任务外,所有环境均使用MuJoCo [28]进行模拟。有关所有任务的完整描述,请参见附录B。
每个任务都有一个真正的成本函数,在OpenAI Gym [5]中定义。我们首先通过在这些真实成本函数上运行TRPO [24]来为这些任务生成专家行为以创建专家策略。然后,为了评估关于专家数据样本复杂性的模仿性能,我们从专家策略中采样了不同轨迹计数的数据集。构成每个数据集的轨迹每个都由大约50个状态-动作对组成。我们针对三个基线测试了GAIL:
- 行为克隆:给定的状态-动作对数据集分为70%的训练数据和30%的验证数据。该策略通过监督学习进行训练,使用带有128个示例的小批量Adam [11],直到验证误差停止减少。
- 特征期望匹配(FEM):Ho et al. [10]的算法使用Abbeel and Ng [1]的成本函数类Clinear (10)
- 博弈论学徒学习(GTAL):Ho et al. [10]的算法使用Syed and Schapire [26]的成本函数类Cconvex (10)
我们使用所有算法为所有任务训练相同神经网络架构的策略:两个隐藏层,每个隐藏层100个单元,中间有tanh非线性。GAIL的鉴别器网络也使用了相同的架构。所有网络总是在每次试验开始时随机初始化。对于每项任务,我们为FEM、GTAL和GAIL提供完全相同数量的环境交互进行训练。由于时间限制,我们在除Humanoid之外的所有环境中对不同的随机种子运行了所有算法5-7次。
图1描述了结果,附录B提供了我们实验流水线的准确性能数据和详细信息,包括专家数据采样和算法超参数。我们发现,在经典控制任务(cartpole、acrobot和mountain car)上,与FEM和GTAL相比,行为克隆通常在专家数据效率方面受到影响,后者在很大程度上在数据集大小的广泛范围中能够生成具有近乎专家性能的策略,尽管在策略的不同随机初始化上有很大的差异。在这些任务上,GAIL始终制定出比行为克隆、FEM和GTAL表现更好的策略。然而,行为克隆在Reacher任务中表现出色,在该任务上它比GAIL更有效。我们能够使用因果熵正则化稍微提高GAIL在Reacher上的性能——在4轨迹设置中,根据单边Wilcoxon秩和检验(p = 0.05),从λ = 0到λ = 10-3的改进在训练重新运行时具有统计学意义。对于所有其他任务,我们没有使用因果熵正则化。
在其他MuJoCo环境中,对于我们测试的所有数据集大小,GAIL几乎总是达到专家性能的至少70%,并且在更大的数据集上完全达到了这一水平,随机种子之间的差异很小。即使使用最大的数据集,基线算法通常也无法达到专家级性能。对于Ant,FEM和GTAL表现不佳,产生的策略始终比随机选择动作的策略差。行为克隆能够在HalfCheetah、Hopper、Walker和Ant的足够数据上达到令人满意的性能,但在Humanoid上却无法达到60%以上,而GAIL在所有测试数据集大小上都达到了精确的专家性能。

7 Discussion and outlook
正如我们所展示的,GAIL在专家数据方面的样本效率通常很高。然而,就训练期间的环境交互而言,它并不是特别有效的样本。估计模仿目标梯度(18)所需的样本数量与TRPO从强化信号训练专家策略所需的数量相当。我们相信,我们可以通过使用行为克隆初始化策略参数来显著提高GAIL的学习速度,这根本不需要环境交互。
从根本上说,我们的方法是无模型的,因此它通常比基于模型的方法需要更多的环境交互。例如,引导成本学习[6]建立在引导策略搜索[12]的基础上,并继承了其样本效率,但也继承了其要求,即模型通过迭代拟合的时变线性动力学很好地近似。有趣的是,GAIL和引导成本学习在策略优化步骤和成本拟合(我们称为判别器拟合)之间交替,尽管这两种算法的派生方式完全不同。
我们的方法建立在IRL [29, 1, 27, 26]的大量工作之上,因此,就像IRL一样,我们的方法在训练期间不会与专家互动。我们的方法随机探索以确定哪些操作使策略的占用测量更接近专家的,而与专家交互的方法,如DAgger [22],可以简单地询问专家此类操作。最终,我们相信将精心挑选的环境模型与专家交互相结合的方法将在专家数据和环境交互的样本复杂度方面获胜。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号