Reinforcement Learning with Long Short-Term Memory
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS 14, VOLS 1 AND 2, (2002): 1475.0-1482.0
Abstract
本文介绍了使用长短期记忆循环神经网络的强化学习:RL-LSTM。使用Advantage(λ)学习和定向探索的无模型RL-LSTM可以解决相关事件之间存在长期依赖关系的非马尔可夫任务。这在T型迷宫任务以及杆平衡任务的困难变化中得到了证明。
1 Introduction
强化学习(RL)是一种基于延迟奖励信号学习如何行为的方法[12]。强化学习面临的更重要挑战之一是环境状态的一部分对智能体隐藏的任务。此类任务称为非马尔可夫任务或部分可观察马尔可夫决策过程。许多现实世界的任务都有这个隐藏状态的问题。例如,在导航任务中,环境中的不同位置可能看起来相同,但一个相同的动作可能会导致不同的下一个状态或奖励。因此,隐藏状态使RL更加真实。然而,这也让它变得更加困难,因为现在智能体不仅需要学习从环境状态到动作的映射,为了获得最佳性能,它通常还需要确定它处于哪种环境状态。
Long-term dependencies. 如果相关事件之间存在长期依赖关系,则大多数解决非马尔可夫RL任务的方法都会出现问题。长期依赖问题的一个示例是迷宫导航任务,其中区分两个看起来相同的T型路口的唯一方法是在任一T型路口之前很长时间记住观察或动作。这种情况为固定大小的历史窗口方法[6]带来了明显的问题,该方法试图通过使选择的动作不仅取决于当前观察,还取决于固定数量的最近观察和动作来解决隐藏状态。如果要记住的相关信息落在历史窗口之外,智能体就不能使用它。McCallum的变量历史窗口[8]原则上具有表示长期依赖关系的能力。但是,系统从零历史开始,逐步增加历史窗口的深度。这使得学习长期依赖变得困难,特别是当没有短期依赖可以构建时。
非马尔可夫任务的其他方法基于学习有限状态自动机[2]、循环神经网络(RNN)[10, 11, 6],或学习设置记忆位[9]。与历史窗口方法不同,它们不必表示(可能很长)整个历史,但原则上可以在任意时间内提取和表示相关信息。然而,事实证明,学习这样做很困难。考虑到它们之间分散注意力的观察和行动,困难在于发现一条信息与该信息在以后变得相关的时刻之间的相关性。这种困难可以看作是学习时间序列数据中长期依赖关系的一般问题的一个例子。本文针对这个问题使用了一种特殊的解决方案,该解决方案在有监督的时间序列学习任务中运行良好:长短期记忆(LSTM)[5, 3]。在本文中,LSTM循环神经网络与无模型RL结合使用,其精神与[10, 6]的无模型RNN方法相同。下一节将介绍 LSTM。第3节介绍了LSTM在称为RL-LSTM的系统中与强化学习的结合。第4节包含对具有长期依赖性的非马尔可夫RL任务的模拟结果。最后,第5节给出了一般性结论。
2 LSTM
LSTM是最近提出的循环神经网络架构,最初是为监督时间序列学习而设计的[5, 3]。它基于对传统循环神经网络学习算法的问题的分析,例如时序反向传播(BPTT)和实时循环学习(RTRL)在学习具有长期依赖关系的时间序列时具有。这些问题归结为一个问题,即及时传播的误差往往会消失或爆炸(参见[5])。
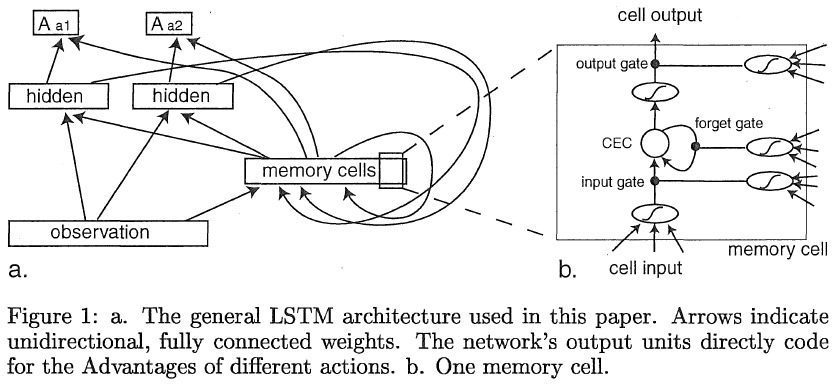
Memory cells. LSTM对这个问题的解决方案是在许多专门的单元中强制执行恒定的误差流,称为恒定误差转盘(CEC)。这实际上对应于这些具有不随时间衰减的线性激活函数的CEC。为了防止CEC填充来自时间序列的无用信息,使用其他专门的乘法单元(称为输入门)来调节对它们的访问。像CEC一样,输入门接收来自时间序列和网络中其他单元的输入,它们学会在适当的时刻打开和关闭对CEC的访问。从CEC的激活到网络的输出单元(可能还有其他单元)的访问是使用乘法输出门来调节的。与输入门类似,输出门学习何时将存储在CEC中的信息发送到网络的输出端。最近添加的是忘记门[3],当存储在CEC中的信息不再有用时,它会学习重置CEC的激活。CEC与其相关的输入、输出和遗忘门的组合称为记忆单元。有关存储单元的示意图,请参见图1b。也可以将多个CEC与一个输入、输出和遗忘门组合在一个所谓的内存块中。
Activation updates. 更正式地说,网络在每个时间步骤 t 的激活计算如下。标准隐藏单元的激活yh、输出单元激活yk、输入门激活yin、输出门激活yout和遗忘门激活yφ以下列标准方式计算:
![]()
其中Wim是从单元 m 到单元 i 的连接的权重。在本文中,fi是除输出单元外的所有单元的标准逻辑sigmoid函数,它是恒等函数。CEC激活![]() ,或存储块 j 中存储单元 v 的"状态",被计算如下:
,或存储块 j 中存储单元 v 的"状态",被计算如下:
![]()
其中 g 是一个逻辑sigmoid函数,缩放到范围[-2, 2]和![]() 。存储单元的输出
。存储单元的输出![]() 由下式计算:
由下式计算:
![]()
其中 h 是一个逻辑sigmoid函数,缩放到范围[-1, 1]。
Learning. 在时间序列的某些或所有时间步骤上,网络的输出单元可能会出现预测误差。误差通过除CEC之外的所有单元(包括门)在时间上倒退一步传播。然而,使用RTRL的高效变体[5, 3],误差会通过CEC无限期地反向传播。每个时间步骤都会进行权重更新,这与在线RL的理念非常吻合。学习算法略微适用于RL,如下一节所述。
3 RL-LSTM
RNN,例如LSTM,可以以多种方式应用于RL任务。一种方法是让RNN学习环境模型,该模型学习预测观察和奖励,并以此方式学习推断每个点的环境状态[6, 11]。LSTM的架构将允许预测依赖于很久以前的信息。然后,基于模型的系统可以学习从(推断的)环境状态到动作的映射,就像在马尔可夫案例中一样,使用标准技术,如Q-learning [6, 2],或通过冻结模型反向传播到控制器[11]。另一种无模型方法,也就是这里使用的方法,是使用RNN直接近似强化学习算法的价值函数[10, 6]。环境的状态由当前观察值(网络的输入)和网络中的循环激活(代表智能体的历史)来近似。与基于模型的方法相比,这种无模型方法的一个可能优势是,系统可以学习仅在对获得更高奖励有用的情况下解决隐藏状态,而不是浪费时间和资源来尝试预测与获得奖励无关的环境特征[6, 8]。
Advantage learning. 在本文中,RL-LSTM网络近似于优势学习[4]的价值函数,它被设计为对连续时间RL的Q-Iearning的改进。在连续时间RL中,相邻状态的价值以及给定状态下不同动作的最佳Q值通常只有很小的差异,这很容易在噪声中丢失。优势学习通过人为地降低每个状态中次优动作的价值来解决这个问题。在此,优势学习用于连续时间和离散时间RL。请注意,相邻状态价值之间的微小差异的相同问题适用于任何具有长奖励路径的RL问题。为了展示RL-LSTM弥合长时间滞后的潜力,我们需要考虑此类RL问题。一般来说,优势学习可能比Q-Iearning更适合非马尔可夫任务,因为它似乎对准确地获得价值估计不太敏感。
LSTM网络的输出单元直接编码不同动作的优势价值。图1a显示了本文中使用的一般网络架构。与使用函数近似器的Q-learning一样,时序差分误差ETD(t)源自优势学习[4]的贝尔曼方程的等价,被视为函数近似器在时间步骤 t 处的预测误差:
![]()
其中A(s, a)是状态 s 中动作 a 的优势价值,r 是即时奖励,V(s) = maxa A(s, a)是状态 s 的价值。γ 是[0,1]范围内的折扣因子,κ是最佳和次优动作价值之间差异的常数缩放。与执行的动作以外的其他动作相关的输出单元不接收误差信号。
Eligibility traces. 在这项工作中,优势学习通过资格迹进行了扩展,这通常被发现可以改善RL中的学习,尤其是在非马尔可夫领域[7]。这产生了Advantage(λ)学习,并且必要的计算结果与Q(λ)学习[1]中的结果几乎相同。它要求每个权重Wim存储一个资格迹eim。权重更新对应于:
![]()
K 表示与执行的动作相关的输出单元,a 是学习率参数,A 是确定资格迹衰减速度的参数。eim(0) = 0,如果采取探索性动作,则eim(t - 1)设置为0。
Exploration. 非马尔可夫强化学习需要特别注意探索问题[2, 8]。无向探索尝试在每种环境状态下以相同的方式尝试动作。 然而,在非马尔可夫任务中,智能体最初并不知道它处于哪种环境状态。部分探索必须旨在发现环境状态结构。此外,在许多情况下,非马尔可夫环境将提供明确的观察结果,指示某些部分的状态,而在其他部分提供模糊的观察结果(隐藏状态)。一般来说,我们希望在模棱两可的部分进行更多的探索。
本文采用基于这些想法的定向探索技术。一个单独的多层前馈神经网络,具有与LSTM网络相同的输入(代表当前观察)和一个输出单元yv,与LSTM网络同时训练。它使用标准反向传播进行训练,以预测由公式4定义的当前时序差分误差ETD(t)的绝对值,加上它自己在下一个时间步骤的折扣预测:
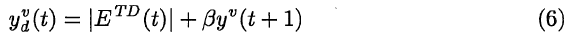
其中![]() 是输出yv(t)的期望值,并且 β 是[0, 1]范围内的折扣参数。从某种意义上说,这相当于尝试识别哪些观察结果是"有问题的",它们与当前价值估计中的大误差(第一项)相关联,或者先于具有大此类误差的情况(第二项)。yv(t)被线性缩放并用作玻尔兹曼动作选择规则的温度[12]。对于当前观察,估计的优势价值之间的差异很小(玻尔兹曼探索的标准效果),或者当前优势价值或不久之后的优势价值存在很多"不确定性"(这种定向探索方案的效果)时,最终结果是进行了很多探索。这种探索技术与统计上更严格的区间估计技术(参见[12])以及某些基于模型的方法有明显的相似之处,当存在模型预测中的更多不确定性时探索会更大[11]。
是输出yv(t)的期望值,并且 β 是[0, 1]范围内的折扣参数。从某种意义上说,这相当于尝试识别哪些观察结果是"有问题的",它们与当前价值估计中的大误差(第一项)相关联,或者先于具有大此类误差的情况(第二项)。yv(t)被线性缩放并用作玻尔兹曼动作选择规则的温度[12]。对于当前观察,估计的优势价值之间的差异很小(玻尔兹曼探索的标准效果),或者当前优势价值或不久之后的优势价值存在很多"不确定性"(这种定向探索方案的效果)时,最终结果是进行了很多探索。这种探索技术与统计上更严格的区间估计技术(参见[12])以及某些基于模型的方法有明显的相似之处,当存在模型预测中的更多不确定性时探索会更大[11]。
4 Test problems
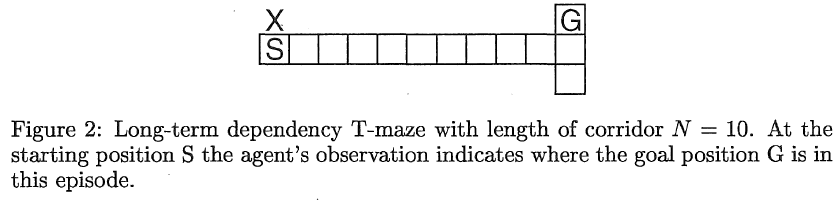
Long-term dependency T-maze. 第一个测试问题是基于非马尔可夫网格的T型迷宫(见图 2)。它旨在测试RL-LSTM弥合长时间滞后的能力,而不会因以其他方式使控制任务变得困难而混淆结果。智能体有四种可能的动作:向北、向东、向南或向西移动。智能体必须学会从走廊起点的起始位置移动到T型路口。在那里,它必须向北或向南移动到一个它看不到的不断变化的目标位置。但是,目标的位置取决于智能体在起始位置看到的"路标"。如果智能体在T型路口采取了正确的动作,它会收到4的奖励。如果采取错误的动作,它会收到-0.1的奖励。在这两种情况下,回合都会结束并开始新的回合,新的目标位置随机设置为北或南。在这一个回合中,智能体在静止不动时会收到-0.1的奖励。在起始位置,观测值是011或110,在走廊中观测值是101,在T型路口观测值是010。走廊N的长度系统地从5到70变化。在每种情况下, 进行了10次运行。
如果智能体只对T型路口采取最佳动作,它必须记住从起始位置观察N个时间步骤来确定T型路口的最佳动作。请注意,在时间滞后依赖性较短的情况下,智能体不会得到经验的帮助。其实反之亦然。一开始会采取更多的动作,直到到达T型路口,而且经历的历史在每一回合之间变化很大。智能体必须首先学会可靠地移动到T型路口。一旦完成,智能体将开始体验或多或少一致且可能最短的观察和动作历史,从中它可以学习提取相关信息。定向探索机制在这方面至关重要:它学会将探索设置在走廊的低处和T型路口的高处。
LSTM网络有3个输入单元、12个标准隐藏单元、3个记忆单元和α = 0.0002。在所有条件下都使用以下参数值:γ = 0.98, λ = 0.8, κ = 0.1。与已在非马尔可夫任务中使用的两个替代系统进行了实证比较。任务的长期依赖性质实际上排除了历史窗口方法。相反,使用了两个替代系统,如LSTM,原则上能够表示任意长时间滞后的信息。在第一个替代方案中,LSTM网络被使用BPTT [6]训练的Elman风格的简单循环网络取代。请注意,BPTT所需的RNN展开意味着这不再是真正的在线RL。Elman网络有16个隐藏单元和16个上下文单元,α = 0.001。第二种选择是基于表的系统,扩展了作为观察的一部分的内存位,并且控制器可以打开和关闭[9]。因为该任务要求智能体只记住一点信息,所以这个系统有一个记忆位,α = 0.01。为了确定LSTM对性能的具体贡献,在这两种备选方案中,除了LSTM(即Advantage(λ)学习、定向探索)之外,整个系统的所有元素都保持不变。
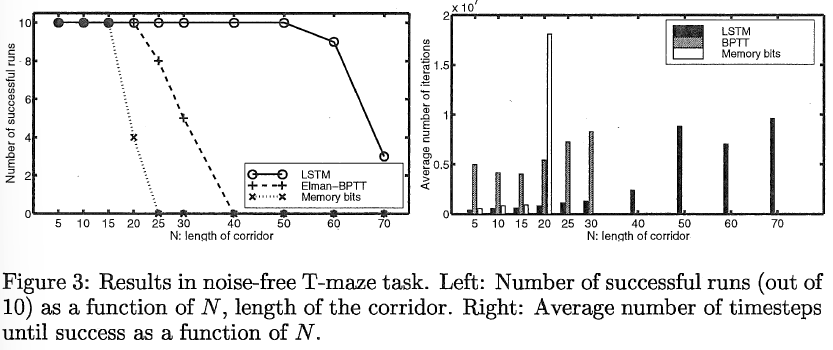
如果智能体使用其随机动作选择机制在超过80%的情况下学会在T型路口采取正确的动作,则认为运行成功。在实践中,这对应于在T型路口使用贪婪动作选择的100%正确的动作选择,以及导致T型路口的最优或接近最优的动作选择。图3显示了三种方法中每种方法的成功运行次数(共10次)作为走廊长度N的函数。它还显示了达到成功所需的平均时间步数。很明显,RL-LSTM能够处理比这两个替代方案更长的时间滞后。RL-LSTM在N = 50时具有完美的性能,之后性能逐渐下降。在替代方案也取得成功的情况下,RL-LSTM也学得更快。内存位系统性能最差的原因可能是,与其他两个相比,它没有明确计算相对于过去事件的性能梯度。这应该会降低信度分配的直接性,从而降低效率。Elman-BPTT系统确实计算了这样的梯度,但与LSTM相比,梯度信息往往会随着较长的时间滞后而迅速消失(如第2节所述)。
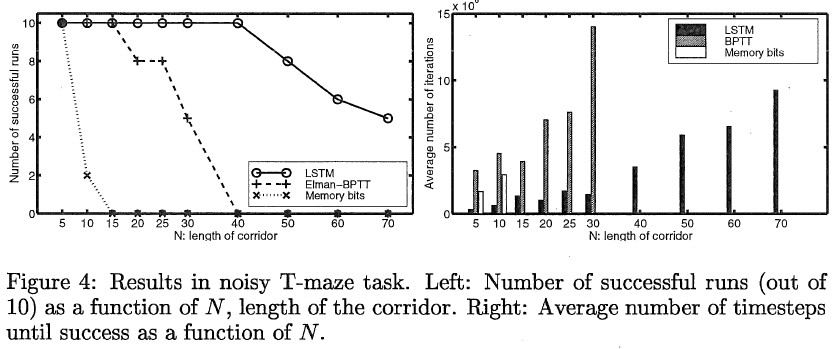
T-maze with noise. 在无噪声任务中学习长期依赖是一回事,在存在严重噪声的情况下这样做是另一回事。为了对此进行调查,设计了上述T型迷宫任务的一个非常嘈杂的变体。现在走廊中的观察是a0b,其中a和b是独立的,在[0, 1]范围内均匀分布的随机值,在线生成。该任务的所有其他方面与上述相同。LSTM和Elman-BPTT系统也保持不变。为了进行公平比较,基于表的内存位系统的观察是使用Michie和Chambers的BOXES状态聚合机制(参见[12])计算的,将每个输入维度划分为三个相等的区域。
图4显示了结果。内存位系统受噪声影响最大这并不奇怪,因为基于表的系统,即使增加了BOXES状态聚合,也不会提供非常复杂的泛化。这两种RNN方法几乎不受观测中严重噪声的影响。最重要的是,RL-LSTM再次显著优于其他方法,无论是在它可以处理的最大时间延迟方面,还是在学习任务所需的时间步数方面。
Multi-mode pole balancing. 第三个测试问题不像T型迷宫那样人为,并且具有更复杂的动态。它由经典极点平衡任务的一个困难变体组成。在杆平衡任务中,智能体必须通过向推车施加左右力来平衡一个固有不稳定的杆,该杆铰接在沿轨道行驶的轮式推车的顶部。即使在马尔可夫版本中,该任务也需要相当精确的控制来解决它。
本实验中使用的版本因隐藏状态的两个来源而变得更加困难。首先,如在[6]中,智能体无法观察到与小车速度和杆角速度相对应的状态信息。为了解决任务,它必须学会使用其循环连接来近似这个(连续的)信息。其次,智能体必须学会以两种不同的模式操作。在模式A中,动作1为左推,动作2为右推。在模式B中,这是相反的:动作1是右推,动作2是左推。模式在每个回合开始时随机设置。智能体在哪种模式下运行的信息仅在回合的第一秒提供给智能体。之后,相应的输入单元设置为零,智能体必须记住它处于哪种模式。显然,不记得模式会导致性能很差。如果杆下降超过±12°或小车撞到轨道的任一端,则唯一的奖励信号是 -1。请注意,如果要学习无限期地平衡极点,则智能体必须学习无限期地记住(离散)模式信息。这完全排除了历史窗口方法。然而,与T型迷宫相比,该系统现在具有启动时间相对较短的优势。
LSTM网络有2个输出单元、14个标准隐藏单元和6个记忆单元。它有3个输入单元:小车位置和极角各一个;一个用于操作模式,在一秒的模拟时间(50个时间步骤)后设置为零。γ = 0.95, λ = 0.6, κ = 0.2, α = 0.002。在这个问题中,没有必要进行定向探索,因为与T型迷宫相比,不完善的策略会导致许多不同的奖励信号体验,并且环境中到处都有隐藏状态。对于这样的连续问题,基于表的内存位系统不太适合,因此仅与Elman-BPTT系统进行了比较,该系统具有16个隐藏和上下文单元,a = 0.002。
Elman-BPTT系统在10次运行中从未达到令人满意的解决方案。当模式信息可用时,它只学习了前50个时间步骤的极点平衡,因此无法学习长期依赖性。然而,RL-LSTM在10次运行中有2次学习到了最佳性能(在平均学习6250000个时间步骤之后)。经过学习,这两个智能体能够在两种操作模式下无限期地平衡极点。在另外8次运行中,智能体仍然在数百甚至数千个时间步骤(平均学习8095000个时间步骤之后)学会了在两种模式下平衡极点,从而表明模式信息被记住了很长时间。在大多数情况下,这样的智能体学习一种模式的最佳性能,同时在另一种模式下获得良好但次优的性能。
5 Conclusions
本文提出的结果表明,使用Long Short-Term Memory (RL-LSTM)的强化学习是解决具有长期依赖关系的非马尔可夫RL任务的一种很有前途的方法。这在具有最多70个时间步骤的最小时滞依赖性的T型迷宫任务中得到了证明,并且在极点平衡的非马尔可夫版本中得到了证明,其中最佳性能需要无限期地记住信息。RL-LSTM的主要力量来源于LSTM的恒定误差流特性,但是为了在RL任务中获得良好的性能,与Advantage(λ)学习和定向探索的结合是至关重要的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号