Evolving-to-Learn Reinforcement Learning Tasks with Spiking Neural Networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

ArXiv 2022
Abstract
受自然神经系统的启发,突触可塑性规则用于训练具有局部信息的脉冲神经网络,使其适用于神经形态硬件的在线学习。然而,当实现这些规则来学习不同的新任务时,它们通常需要大量的任务相关微调工作。本文旨在通过采用一种进化算法来简化这一过程,该算法为手头的任务进化出合适的突触可塑性规则。更具体地说,我们提供了一组各种局部信号、一组数学算子和一个全局奖励信号,然后笛卡尔遗传编程过程从这些组件中找到最佳学习规则。使用这种方法,我们找到了成功解决XOR和cart-pole任务的学习规则,并发现了优于文献中基准规则的新学习规则。
1 Introduction
1990年代,生物神经系统中神经动力学领域的研究进展促进了脉冲神经网络(SNN)的发展[Maas, 1997]。SNN是一种特殊类型的人工神经网络(ANN),由生物学上更真实的计算单元组成。与生物神经元之间的通信类似,SNN中的信息传输是通过脉冲执行的。脉冲是当神经元的膜电位超过阈值时发生的离散事件[Gerstner et al., 2014]。结果,SNN中的神经元被稀疏激活,与传统的ANN相比,这些网络有可能更高效地执行计算,后者与密集的连续值进行通信[Maas, 1997; Stone, 2016]。出于这个原因,SNN有望用于功率受限的应用。此外,神经形态芯片的最新发展为SNN的硬件实现铺平了道路[Davies et al., 2018; DeBole et al., 2019],并且他们已经成功地使用进化[Howard and Elfes, 2014; Hagenaars et al., 2020]或替代梯度的反向传播[Shrestha and Orchard, 2018; Neftci et al., 2019]等方法进行了训练。然而,这些利用大量非局部信息的算法并不特别适合神经形态硬件中的片上学习。
SNN的高效片上学习可以通过像Hebb规则[Hebb, 1949]或脉冲时序依赖可塑性(STDP)[Markram et al., 1997]等突触可塑性规则或Oja规则[Oja, 1982]和三元组STDP[Pfister and Gerstner, 2006]等改进变体来实现。其中一些学习规则来自实验数据[Artola et al., 1990],而另一些则是为了优化某些指标,如信息传输效率[Toyoizumi et al., 2005]。大多数研究在学习规则的推导过程中都考虑了这两个因素,但很少具体说明每个方面的依赖程度。此外,发现替代学习规则通常是一个反复试验的过程,这可能是一项耗时的任务。为了解决这些问题,Jordan et al. [2021]提出了一种进化算法来发现突触可塑性规则的数学表达式。应用遗传编程来发展规则,以在不同任务上训练SNN。进化搜索成功地(重新)发现了具有高性能的现有解决方案,并确定了训练的基本术语。在某些任务中,该算法还进化出具有竞争性能的新学习规则。然而,由于这项工作是为SNN进化符号突触可塑性规则的首次尝试,因此为训练选择的任务相对简单,并且搜索空间仅限于现有解决方案中存在的组件。
作为[Jordan et al., 2021]的扩展,我们将实现相同的算法来进化用于训练SNN的突触可塑性规则,针对具有更高任务复杂性和扩展进化搜索空间的强化学习任务。目标是发展用于解决强化任务的突触可塑性规则,确定成功学习的关键术语,并发现具有可比或更好性能的新学习规则。
本文将分别在第2节和第3节中概述相关工作和方法。接下来,第4节将介绍实验结果。我们将在第5节中讨论实验和结果。
2 Related Work
进化突触可塑性规则的想法首先应用于ANN。为了提高具有生物学合理模型的ANN的学习能力,Bengio et al. [1991]使用梯度下降和遗传算法优化了突触可塑性规则的参数。后来,这种方法的通用性通过将其应用于学习简单但多样化的任务来证明:生物回路、布尔函数和各种分类任务[Bengio et al., 2007]。遵循类似的方法,Niv et al. [2002]和Stanley et al. [2003]进化了学习规则来训练ANN分别在自适应环境下执行强化学习任务和自动控制任务。在所有这些工作中,学习规则的优化都是基于一个参数函数,它通常是一个现有的突触可塑性规则,例如Hebb规则。优化器只学习函数的系数。这种方法的主要优点是固定学习规则的格式限制了搜索空间并减少了计算量。然而,由于参数函数之外的变量都被排除在外,这种方法的鲁棒性和通用性受到了损害。
更通用的方法是用ANN代替符号学习规则并对其进行优化以获得更好的学习性能。自适应HyperNeat算法是一种元学习方法,它进化了对学习规则进行编码的ANN的连接模式和权重[Risi and Stanley, 2010]。这种方法使用神经元状态(如神经元迹和脉冲活动)作为ANN的输入,输出相关突触的权重更新。最近,在神经形态硬件中实现了一种类似的方法,以优化SNN在基本强化学习任务中的训练[Bohnstingl et al., 2019]。这种方法简化了自适应HyperNeat算法,只进化了ANN的连接权重。两项工作都将他们的方法与在相同任务上优化参数学习规则的方法进行了比较,发现优化由ANN编码的学习规则对环境变化的任务更稳健。这种方法的缺点也很明显。由于学习规则是由ANN表达的,很难解释,因此很难分析学习行为并概括进化的学习规则来学习其他任务。
随着计算神经科学和SNN的发展,已经衍生出各种突触可塑性规则来学习不同的任务[Markram et al., 1997; Florian, 2017]。为了提出可应用于更广泛问题的更通用规则,研究人员提出了进化和评估突触可塑性规则的符号表达的元学习方法。不同于以往的方法具有固定的函数,学习规则的系数、算子和操作数都是要在这种方法中进化的基因组。Jordan et al. [2021]实现笛卡尔遗传编程(CGP)以进化用于学习奖励驱动、误差驱动和相关任务的突触可塑性规则。Confavreux et al. [2020]成功应用协方差矩阵适应进化策略重新发现Oja规则和anti-Hebbian规则。与前面段落中讨论的优化算法相比,这些方法进化了学习规则的整个表达式。与仅进化系数的方法相比,它们具有更大的搜索空间。因此,它们也更加健壮和灵活。此外,进化的结果是学习规则的数学表达,这使得学习行为的解释更容易。由于这些原因,我们将在本文中采用类似的方法。
3 Methodology
3.1 Neuron Model
有许多神经元模型具有不同程度的复杂性和准确度[Hodgkin and Huxley, 1952; Brunel and van Rossum, 1907]。由于用于训练SNN的学习规则的进化在计算上非常昂贵,因此具有低复杂度的神经元模型是有利的。此外,关于生物神经系统的高准确度并不是成功进化的必要因素。由于这些原因,LIF模型足以用于此处的脉冲神经元模拟。类似于RC电路,神经元膜可以看作是一个电容器,膜电位U随流入其中的电流 I 而变化,这是求和过程。当膜电位达到脉冲阈值时,神经元释放一个脉冲S,膜电位下降到平衡或静息值。泄漏行为描述了由于离子扩散引起的电位衰减。LIF模型可以用数学方法表示如下:

其中 i, j 分别表示突触后和突触前神经元,k 表示仿真时间步骤。常数α是膜衰减,w是突触权重。
3.2 Reward Modulated Spike Timing Dependent Plasticity (R-STDP)
STDP是一种适合生物神经元实验数据的学习规则[Markram et al., 1997],STDP的变体已广泛应用于训练SNN。生物学基础是Hebb理论,该理论被概括为"一起发放的细胞连接在一起"[Hebb, 1949]。后来随着在兔海马中发现的长期增强和长期抑制现象[Lømo, 1966]进行了扩展。长期增强(LTP)现象表明,当突触后神经元在突触前脉冲后的某个时间窗口内发放时,突触强度会出现长期增加。相反,当突触后神经元在突触前脉冲之前的某个时间窗口内发放时,会发生长期抑制。因此,在基本的STDP学习规则中,突触强度变化是突触前和突触后脉冲之间的时间差的函数。在基本STDP的一些变体中,使用突触前和突触后神经元或突触的资格迹来表示脉冲的时间差。为了进一步模仿自然界中奖励驱动的学习行为,奖励调节的STDP (R-STDP)在学习规则中引入了奖励信号,使其适合训练SNN执行强化学习任务。一个例子是Florian [2017]提出的MSTDPET规则:
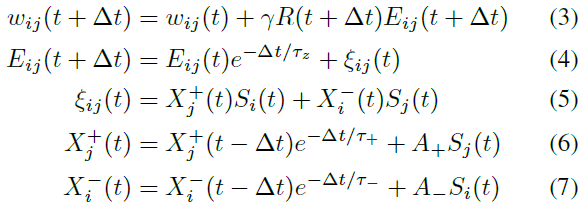
其中 γ 是学习率,Δt 是仿真时间步骤。奖励 R 在每个时间步骤更新。每个突触Eij的资格迹是对突触活动ξij的低通滤波器,它有一个pre-before-post (+)和一个post-before-pre (-)项。所有 τ 代表衰减时间常数。常数A±衡量脉冲 S 对神经元活动迹X±的贡献。
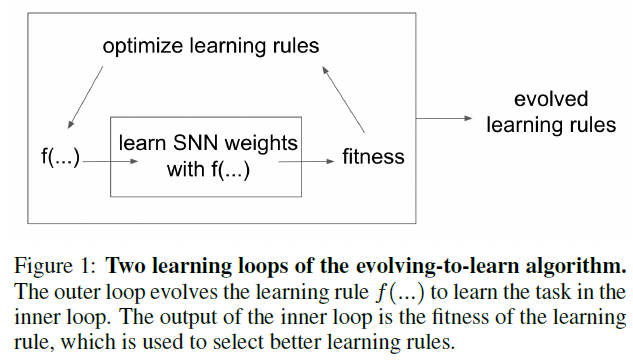
3.3 Evolving-to-learn
Jordan et al. [2021]提出的进化学习算法可以被视为具有两个循环的基于优化的元学习算法,如图1所示。外循环是对学习规则的数学表达式的进化搜索,将使用CGP [Miller, 2007]执行。学习规则由索引的二维笛卡尔图表示。该图具有固定数量的输入、输出和内部节点。每个内部节点都有一个由三个整数组成的字符串:第一个整数表示运算符,另外两个整数表示要连接的节点的索引。内部节点的输出也可以用作其他内部节点的输入。
在进化开始时,索引图是随机初始化的。在每一代之后,将选择最佳解决方案作为父母,并通过突变从父母那里产生一个大小的后代。突变可以发生在算子和节点的连接中。图2显示了具有三列和三行的CGP示例。
然后,CGP生成的学习规则将用于训练SNN在内循环中执行特定任务。内循环的性能反过来又是外循环对进化的适应度。概括起来,该算法可以通过以下步骤来描述:1
- 为内循环和适应度函数定义要学习的任务。
- 设计SNN架构并确定编码解码方法。
- 指定进化搜索的输入信号。
- 执行进化以发现具有高适应度的学习规则。
在我们的实验中将实现相同的程序。然而,与Jordan et al. [2021]的工作不同,仅使用基准学习规则的输入信号,我们还包括了神经元状态,例如脉冲和神经元迹,以赋予进化更大的自由度。进化过程中不包含膜衰减和脉冲阈值等超参数;它们使用基准学习规则进行了预先调整并保持固定。
1 代码将在发布后开源。

4 Experiments
4.1 XOR Classification
我们首先在基本XOR分类任务上测试所提出的方法。每个XOR输入都被编码为500个时间步骤的脉冲序列。50个脉冲随机分布在区间内,分别生成两个不同的模式0和1。在每个学习epoch开始时,会生成不同的输入模式集作为训练和测试样本。SNN具有三层LIF神经元:2个输入神经元、20个隐藏神经元和一个输出神经元。分类取决于输出脉冲的总数。如果输出神经元的脉冲超过一个学习周期的平均输出脉冲,则输出将为1;否则,输出将为0。
作为基准学习规则,我们使用MSTDPET规则[Florian, 2017],如公式3-7所示。与[Jordan et al., 2021]中使用的Urbanczik和Senn规则不同,MSTDPET会在仿真的每个时间步骤更新连接权重。因此,奖励也应该在每个时间步骤分配给网络。如果正确的输出为1,则为每个释放的输出脉冲分配1的奖励给突触。如果正确的输出为0,则每释放一个输出脉冲,奖励为-1。在没有输出脉冲的情况下,两种情况的奖励都是0。
如前所述,可用于基准学习规则的信号将包含在进化中,在本例中为Eij和 R。为了扩展搜索空间并赋予进化搜索更多的自由度,在生物突触可塑性中起作用的神经元状态也可用于进化:突触前和突触后脉冲Si和Sj,以及具有两种不同衰减ei1、ei2、ej1和ej2的突触前和突触后神经元迹。学习规则的一般形式表示如下:
![]()
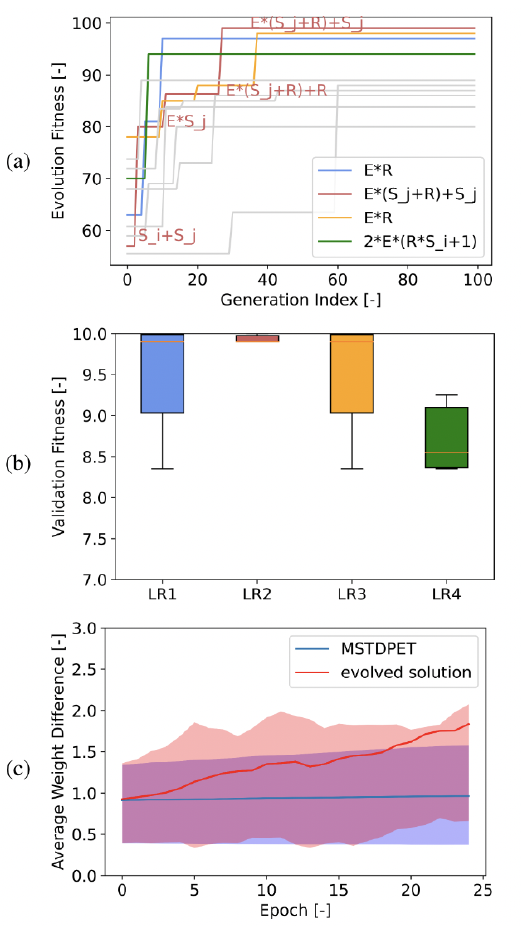
由于权重初始化是随机执行的,因此可能存在初始化已经接近最优解的情况,从而产生良好的性能,也可能存在初始化不利于学习的情况。因此,每个人在进化搜索中进行三个实验试验。适应度函数定义为三个试验的最终测试精度的平均值。
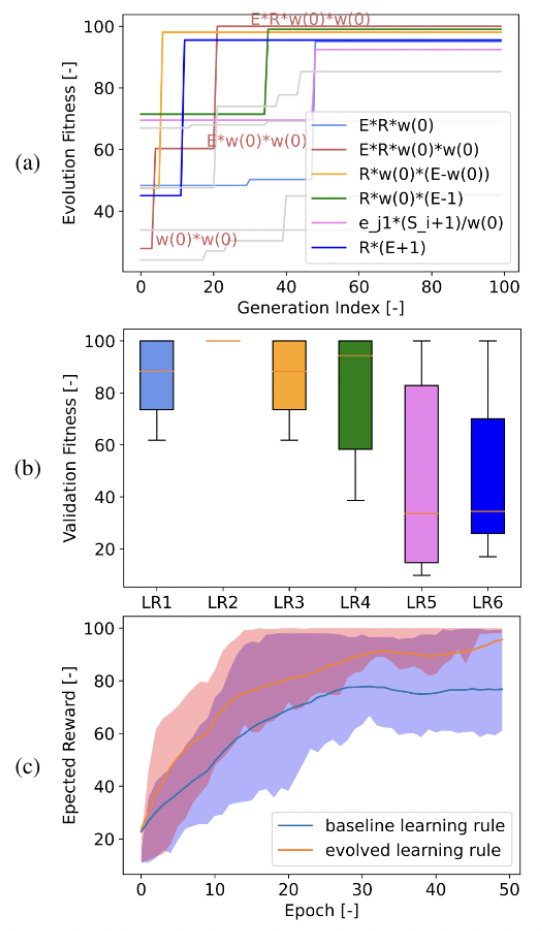
10次进化运行的结果如图3(a-b)所示。 它表明有两个学习周期在100代内成功地进化了MSTDPET学习规则。此外,可以注意到ER一词出现在所有具有高适应度的进化学习规则中,表明它对于学习XOR任务至关重要。这可以解释如下。使用时间编码,两个输入神经元将同时出现模式0。突触后神经元和两个输入神经元之间的突触在每个时间步骤将具有相同的 E。每释放一个输出脉冲都会获得负奖励,突触权重也将减少相同的量。但是,当输入的标签为1时,两个输入脉冲序列将不同。如果突触连接很强,则突触后神经元更有可能在突触前脉冲之后立即发放脉冲,从而导致更大的突触迹。相反,权重较小的连接往往具有较小的突触迹。因此,经过多次学习循环后,强连接会变强,弱连接会变弱,这是一种有利于解决XOR任务的模式。
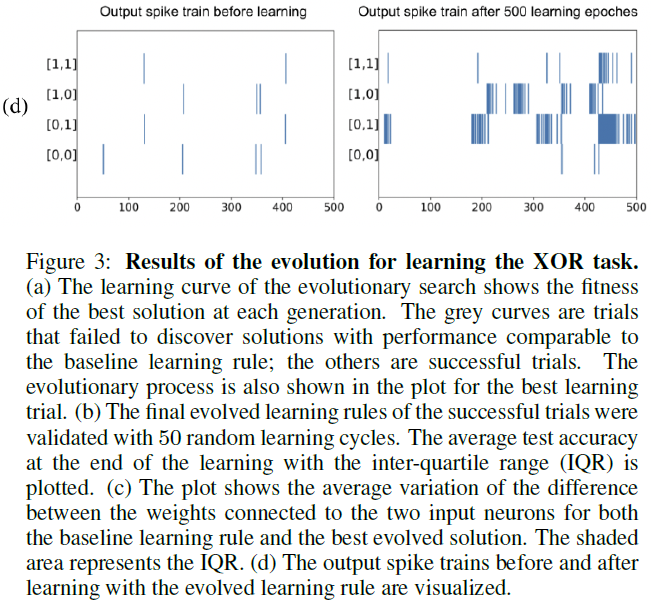
除了重新发现基准学习规则外,还发现了一个性能更好的学习规则,其表达式为E(Sj + R) + Sj。除了突触迹和奖励之外,突触前脉冲也包含在学习规则中。与MSTDPET规则类似,进化规则通过增加连接到两个输入神经元的突触之间的强度差异来学习XOR任务。使用基准学习规则,权重只会在突触后神经元脉冲时更新。当突触前神经元脉冲时,进化规则也会更新权重。对于模式0,连接到两个输入神经元的突触的权重将在只有突触前脉冲时相同地增加,而在只有输出脉冲时减少。对于模式1,突触前脉冲和输出脉冲都会增加连接到两个输入神经元的突触之间的强度差异,从而加快学习速度,如图3(c)所示。图3(d)表明,在使用进化的学习规则进行500个学习epoch之后,输入[0, 1]和[1, 0]明显更大。
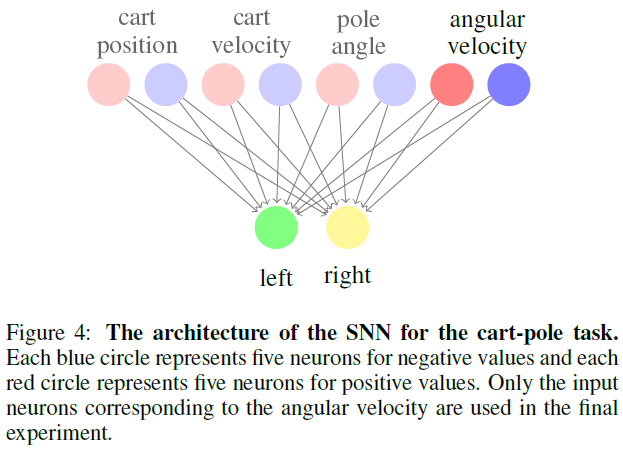
4.2 Cart-pole Task
接下来,实现了相同的从进化到学习的方法来学习可塑性规则,以训练SNN以执行cart-pole任务。使用OpenAI Gym2的CartPole环境,其中有四种观察状态可用:小车位置、小车速度、极角和极角速度。系统的动作是离散的:向左或向右施加在推车上的力。SNN有两层:Poisson编码器对的输入层和2个输出神经元。每对Poisson编码器有5个正值神经元和5个负值神经元。Poisson编码器将输入状态的绝对值转换为具有50个网络仿真时间步骤的脉冲序列。二值编码器之一将根据状态的符号被激活。一个回合是具有多个环境时间步骤的cart-pole的仿真循环。对于每个环境时间步骤,模型将接收一组观察状态。在被编码成脉冲序列后,SNN将通过网络模拟。在网络仿真结束时,系统将根据模型的输出采取动作。2个输出神经元控制小车的动作。如果对应于左侧动作的输出神经元比其他神经元脉冲更多,则向左的力将施加到小车。否则,将施加向右的力。SNN的架构如图4所示。
系统采取动作后,模型将从环境中获得奖励。如果动作向左并导致极点移动到中心,则连接到左侧输出神经元的突触将获得正奖励,而其他突触将获得相反的奖励。如果向左的动作导致极点下降,则与左侧对应的输出神经元的连接将获得负奖励,其他连接将获得正奖励。
学习cart-pole任务的基准学习规则是[Shim and Li, 2017]中用于学习机器人控制任务的乘法R-STDP规则:
![]()
与MSTDPET不同,此学习规则涉及在学习窗口wij(0)开始时的初始权重以提高性能。然而,应用此学习规则的问题在于,奖励必须在每个网络仿真时间步骤都可用,而SNN模型仅在网络仿真结束时采取动作后才会收到反馈。为了解决这个问题,在仿真过程中存储了每个网络时间步骤的神经元状态。采取动作后,权重将使用奖励和存储状态进行更新。接下来,注意到基准学习规则未能稳定地执行cart-pole任务。这是因为在杆子掉落并推动小车快速移动的情况下,输出会受到大幅度状态的支配,从而导致非常高发放率的输入脉冲序列。出于这个原因,我们修改了实验:1)网络不接收所有四种状态(小车位置、小车速度、杆角度和杆角速度),而是只接收杆角速度(最重要的信息);2)网络权重仅在每个episode开始时的一定时间步骤内更新。
与XOR任务类似,突触前和突触后神经元的活动和迹也与基准学习规则的输入变量一起包含在进化中。突触可塑性规则可被表示为:
![]()
在进化过程中,每个候选学习规则有3个任务的随机试验,每个试验有50个回合。最大寿命为100个环境时间步骤,当极角超过15时,回合将终止。候选学习规则的适应度通过最后5个回合的平均时间平衡时间来衡量。
10次进化运行的结果如图5(a-b)所示。可以注意到,其中一次进化运行精确地导致了基准学习规则,而另一次运行进化出具有相似适应度的类似表达式:Rw(0)(E - 1)。对于具有大突触迹的强连接,额外的常数项可以忽略不计,因此对学习性能的影响很小。还有两次进化运行在进化过程中获得了高适应度。然而,他们的学习性能不稳定,并且在验证中获得了较低的适应度。更重要的是,进化还发现了一个学习规则,它比其他规则获得了更高的适应度和更稳定的学习性能:Δwij(t) = γtR(t)Eij(t)wij(0)2。与基准学习规则相比,它包括来自乘法R-STDP(公式9)的所有输入,但初始权重的幂为2。与图5(c)所示的基准学习规则相比,它提高了学习性能。当强连接导致正确的动作并获得正奖励时,学习规则将进一步加强连接模式。然而,当强连接导致错误动作并获得负奖励时,学习规则会降低强连接权重并增加弱连接权重。wij(0)2项将更快地引出所需的模式。图5(d)表明,在50个学习epoch后,极点在整个episode中保持平衡,并具有进化的学习规则。
2 https://gym.openai.com/envs/CartPole-v1/

5 Discussion
在本文中,我们应用了一种进化学习算法来使用局部输入信号进化突触可塑性学习规则的数学表达式。该算法成功地学习了在XOR和cart-pole任务上训练SNN的学习规则。正如实验结果所证明的,XOR和cart-pole实验(重新)发现了基准学习规则并确定了解决任务的基本术语。这种方法允许将突触可塑性规则更好地推广到其他类似任务,因为可以根据这些基本术语自定义学习规则。同时,与以前的工作相比[Jordan et al., 2021; Confavreux et al., 2020],我们扩展了搜索空间并以cart-pole任务的形式解决了一个更复杂的问题,进一步证明了算法的通用性和进化方法的灵活性。此外,对于这两个实验,我们发现了一个新的学习规则,它比基准解决方案具有更高的性能和稳定性。
在实验过程中,揭示了现有突触可塑性规则中先验知识的重要性。不仅因为基准学习规则提供了一部分输入信号,还因为初步学习对于调整网络模型的超参数是必要的,以确保模型对于解决任务是活跃的。然而,由于超参数在进化过程中是固定的,它可能会阻止发现与其他超参数集一起工作的新学习规则。
此外,该实验的一部分通常被其他工作和其他关于SNN的突触可塑性学习的研究所忽略。在这项工作中,发现实验的设计对学习规则的进化有很大的影响。例如,编码和解码、奖励的定义都是训练SNN模型的重要元素。如果这些元素之一没有正确定义,它可能导致进化以及学习规则本身的低性能。这些设计决策通常是在实验过程中通过反复试验和迭代做出的。因此,虽然进化学习算法减少了手动推导和比较不同突触可塑性规则的工作量,但要正确设计实验仍有大量工作。
总之,进化学习算法是帮助理解现有突触可塑性规则的学习过程和辅助学习规则的手动泛化的有效工具。它还能够通过预定义的实验设置发现和优化学习规则。然而,由于对先验知识的依赖和对设计决策的敏感性,该算法还不能完全自动地为随机新任务发现新的学习规则。 迈向更高水平的突触可塑性规则元学习的下一步可以包括在进化中自动调整超参数,这可能允许发现更多具有相应超参数的新学习规则。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号