Deep Reinforcement Learning with Double Q-learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

AAAI 2016
Abstract
众所周知,流行的Q学习算法会在某些条件下高估动作价值。以前不知道在实践中这种高估是否普遍,它们是否会损害性能,以及它们是否通常可以避免。在本文中,我们肯定地回答了所有这些问题。特别是,我们首先表明,最近的DQN算法将Q学习与深度神经网络相结合,在Atari 2600领域的某些游戏中存在严重高估的问题。然后,我们展示了在表格设置中引入的双重Q学习算法背后的思想,可以推广到大规模函数近似。我们提出了对DQN算法的特定适应,并表明所得到的算法不仅减少了观察到的高估,正如假设的那样,而且这也导致了在几场游戏中更好的性能。
强化学习的目标(Sutton and Barto, 1998)是通过优化累积的未来奖励信号来学习针对序列决策问题的良好策略。Q学习(Watkins, 1989)是最流行的强化学习算法之一,但众所周知,它有时会学习到不切实际的高动作价值,因为它包括一个高估动作价值的最大化步骤,这往往更喜欢被高估而不是被低估的价值。
在以前的工作中,高估被归因于不够灵活的函数近似(Thrun and Schwartz, 1993)和噪声(van Hasselt, 2010, 2011)。在本文中,我们统一了这些观点,并表明当动作价值不准确时,无论近似误差的来源如何,都会发生高估。当然,不精确的价值估计是学习过程中的常态,这表明高估可能比以前认识到的要普遍得多。
如果确实发生高估,这是否会对实践中的性能产生负面影响,这是一个悬而未决的问题。过度乐观的价值估计本身并不一定是一个问题。如果所有值都一致地更高,那么相对的动作偏好就会被保留,我们不会期望得到的策略会更糟。此外,众所周知,有时乐观是好事:面对不确定性时保持乐观是一种众所周知的探索技术(Kaelbling et al., 1996)。然而,如果高估不是均匀的,也不是集中在我们希望了解更多的状态,那么它们可能会对最终策略的质量产生负面影响。Thrun and Schwartz (1993)给出了具体的例子,在这些例子中,这会导致次优策略,甚至是渐近的。
为了测试在实践中和规模上是否发生高估,我们研究了最近的DQN算法的性能(Mnih et al., 2015)。DQN将Q学习与灵活的深度神经网络相结合,并在各种大型确定性Atari 2600游戏上进行了测试,在许多游戏中达到了人类水平的性能。在某些方面,此设置是Q学习的最佳情况,因为深度神经网络提供了灵活的函数近似,具有低渐近近似误差的潜力,并且环境的确定性防止了噪声的有害影响。也许令人惊讶的是,我们表明即使在这种相对有利的环境中,DQN有时也会大大高估动作的价值。
我们展示了在表格设置中首次提出的双重Q学习算法(van Hasselt, 2010)背后的思想可以推广到与任意函数近似一起工作,包括深度神经网络。我们使用它来构建一个新的算法,我们称之为双重DQN。然后,我们展示了该算法不仅可以产生更准确的价值估计,而且可以在几个游戏中获得更高的分数。这表明,对DQN的高估确实导致了更糟糕的策略,减少它们是有益的。此外,通过改进DQN,我们在Atari领域获得了最先进的结果。
Background
为了解决序列决策问题,我们可以学习对每个动作的最优价值的估计,定义为采取该动作并随后遵循最优策略时未来奖励的期望总和。在给定策略 π 下,状态 s 中动作 a 的真实价值是:
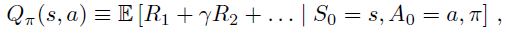
其中 γ ∈ [0, 1] 是一个折扣因子,它权衡了即时稍晚奖励的重要性。那么最优价值是Q*(s, a) = maxπQπ(s, a)。通过在每个状态中选择最高价值的动作,可以很容易地从最优价值推导出最优策略。
可以使用Q学习(Watkins, 1989)来学习最佳动作价值的估计,这是一种时序差分学习(Sutton, 1988)。大多数有趣的问题太大而无法分别学习所有状态下的所有动作价值。相反,我们可以学习一个参数化的价值函数Q(s,a; θt)。在状态St中采取动作At并观察即时奖励Rt+1和结果状态St+1之后,参数的标准Q学习更新为:
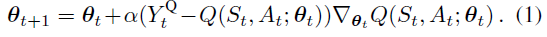
其中 α 是标量步长,目标![]() 定义为:
定义为:
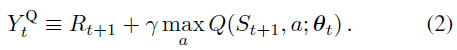
此更新类似于随机梯度下降,将当前价值Q(St,At; θt)向目标价值![]() 更新。
更新。
Deep Q Networks
深度Q网络(DQN)是一个多层神经网络,对于给定的状态 s 输出一个动作价值向量Q(s,· ; θ),其中 θ 是网络的参数。对于一个 n 维状态空间和一个包含 m 个动作的动作空间,神经网络是一个从Rn到Rm的函数。Mnih et al. (2015)提出的DQN算法的两个重要组成部分是目标网络的使用,以及经验回放的使用。目标网络参数为θ-,与在线网络相同,只是它的参数从在线网络的每一步复制,因此![]() ,并在所有其他步骤上保持固定。那么DQN使用的目标是:
,并在所有其他步骤上保持固定。那么DQN使用的目标是:
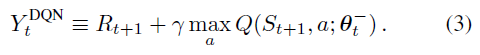
对于经验回放(Lin, 1992),观察到的转换被存储一段时间,并从这个记忆库中均匀采样以更新网络。目标网络和经验回放都显著提高了算法的性能(Mnih et al., 2015)。
Double Q-learning
(2)和(3)中的标准Q学习和DQN中的最大运算符使用相同的价值来选择和评估动作。这使得它更有可能选择高估的价值,从而导致过度乐观的价值估计。为了防止这种情况,我们可以将选择与评估分离。这就是双重Q学习背后的理念(van Hasselt, 2010)。
在原来的双重Q学习算法中,通过随机分配每个经验来学习两个价值函数来更新两个价值函数中的一个,这样就有两组权重,θ和θ'。对于每次更新,一组权重用于确定贪心策略,另一组用于确定其价值。为了清楚比较,我们可以先解开Q学习中的选择和评估,将其目标(2)重写为:
![]()
双重Q学习误差可以被写为:
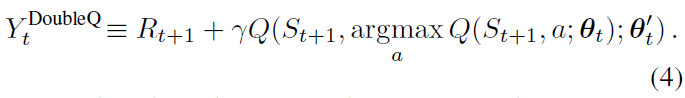
请注意,在argmax中,动作的选择仍然取决于在线权重θt。这意味着,就像在Q学习中一样,我们仍然根据θt定义的当前价值来估计贪婪策略的价值。但是,我们使用第二组权重![]() 来公平地评估该策略的价值。这第二组权重可以通过切换 θ 和 θ' 的角色来对称更新。
来公平地评估该策略的价值。这第二组权重可以通过切换 θ 和 θ' 的角色来对称更新。
Overoptimism due to estimation errors
Q学习的高估首先由Thrun and Schwartz (1993)进行研究,他们表明如果动作价值包含均匀分布在区间内的随机误差[-ε, ε]。那么每个目标被高估到![]() ,其中 m 是动作的数量。此外,Thrun and Schwartz给出了一个具体的例子,这些高估甚至会渐近地导致次优策略,并表明当使用函数近似时,高估会在一个小简单问题中表现出来。后来van Hasselt (2010)认为,即使使用表格表征,环境中的噪声也会导致高估,并提出双重Q学习作为解决方案。
,其中 m 是动作的数量。此外,Thrun and Schwartz给出了一个具体的例子,这些高估甚至会渐近地导致次优策略,并表明当使用函数近似时,高估会在一个小简单问题中表现出来。后来van Hasselt (2010)认为,即使使用表格表征,环境中的噪声也会导致高估,并提出双重Q学习作为解决方案。
在本节中,我们更一般地证明,任何类型的估计误差都可能导致向上偏差,无论这些误差是由于环境噪声、函数近似、非平稳性还是任何其他来源造成的。这很重要,因为在实践中,任何方法都会在学习过程中产生一些不准确性,这仅仅是因为真实价值最初是未知的。
上面引用的Thrun and Schwartz (1993)的结果给出了对特定设置的高估的上限,但也有可能,并且可能更有趣的是,推导出一个下限。
Theorem 1. 考虑一个状态 s,其中所有真正的最优动作价值在Q*(s, a) = V*(s)处对于一些V*(s)是相等的。令Qt是在![]() 的意义上总体上无偏的任意价值估计,但并非全部正确,例如对于某些C > 0,
的意义上总体上无偏的任意价值估计,但并非全部正确,例如对于某些C > 0,![]() ,其中m ≥ 2是 s 中的动作数。在这些条件下,
,其中m ≥ 2是 s 中的动作数。在这些条件下,![]() 。这个下限很紧。在相同条件下,双重Q学习估计的绝对误差下限为零。(证明在附录中。)
。这个下限很紧。在相同条件下,双重Q学习估计的绝对误差下限为零。(证明在附录中。)
请注意,我们不需要假设不同动作的估计误差是独立的。该定理表明,即使价值估计平均而言是正确的,任何来源的估计误差都会使估计上升并远离真正的最优价值。
定理1的下限随着动作的数量而减小。这是考虑下限的人工产物,需要获得非常具体的值。更典型的是,过度乐观会随着动作的数量而增加,如图1所示。Q学习的高估确实随着动作的数量而增加,而双重Q学习是无偏的。另一个例子,如果对于所有动作Q*(s, a) = V*(s)并且估计误差Qt(s, a) - V*(s)在[-1, 1],则过度乐观为![]() 。(证明在附录中。)
。(证明在附录中。)

我们现在转向函数近似,并考虑一个实值连续状态空间,每个状态有10个离散动作。为简单起见,此示例中的真正最优动作价值仅取决于状态,因此在每个状态中所有动作都具有相同的真实价值。这些真实价值显示在图2的左列(紫色线)中,定义为Q*(s, a) = sin(s) (顶行)或Q*(s, a) = 2 exp(-s2) (中间行和底行)。左图还显示了作为状态函数的单个动作(绿线)的近似价值以及估计所基于的样本(绿点)。估计是一个d次多项式,它适合采样状态下的真实价值,其中d = 6 (顶部和中间行)或d = 9 (底部行)。样本与真实函数完全匹配:没有噪声,我们假设我们对这些采样状态的动作价值具有基本事实。即使在前两行的采样状态上,近似也是不精确的,因为函数近似不够灵活。在底行中,该函数足够灵活以适合绿点,但这会降低未采样状态下的准确度。请注意,采样状态在左图左侧附近间隔更远,导致更大的估计误差。在许多方面,这是一个典型的学习环境,在每个时间点我们只有有限的数据。
图2中的中间列显示了所有10个动作(绿线)的估计动作价值函数,作为状态函数,以及每个状态中的最大动作价值(黑色虚线)。尽管所有动作的真实价值函数都相同,但近似值不同,因为我们提供了不同的采样状态集。1 最大值通常高于左侧紫色显示的基本事实。这在右图中得到了证实,它以橙色显示了黑色和紫色曲线之间的差异。橙色线几乎总是积极的,表明向上的偏见。右图还显示了蓝色中双重Q学习的估计值2,平均而言更接近于零。这表明双重Q学习确实可以成功地减少Q学习的过度乐观。
图2中的不同行显示了同一实验的变体。顶行和中间行之间的差异是真实价值函数,表明高估不是特定真实价值函数的产物。中间行和底行之间的区别在于函数近似的灵活性。在左中图中,某些采样状态的估计甚至不正确,因为该函数不够灵活。左下图中的函数更灵活,但这会导致对未见状态的估计误差更高,从而导致更高的高估。这很重要,因为在强化学习中经常使用灵活的参数函数近似器(例如,参见Tesauro, 1995; Sallans and Hinton, 2004; Riedmiller, 2005; Mnih et al., 2015)。
与van Hasselt (2010)相比,我们没有使用统计参数来发现高估,获得图2的过程是完全确定的。与Thrun and Schwartz (1993)相比,我们不依赖具有不可约渐近误差的不灵活函数近似;最下面一行显示,一个足够灵活以覆盖所有样本的函数会导致高估。这表明高估可能相当普遍。
在上面的示例中,即使假设我们在某些状态下拥有真实动作价值的样本,也会发生高估。如果我们从已经过于乐观的动作价值中引导出来,价值估计可能会进一步恶化,因为这会导致高估在我们的估计中传播。尽管一致地高估价值可能不会损害最终的策略,但在实践中,不同的状态和动作的高估误差会有所不同。高估与自举相结合会产生有害的影响,即传播错误的相关信息,即哪些状态比其他状态更有价值,直接影响学习策略的质量。
高估不应与面对不确定性时的乐观主义相混淆(Sutton, 1990; Agrawal, 1995; Kaelbling et al., 1996; Auer et al., 2002; Brafman and Tennenholtz, 2003; Szita and Lórincz, 2008; Strehl et al., 2009),其中探索奖励被给予具有不确定价值的状态或动作。相反,这里讨论的高估只发生在更新之后,导致面对明显的确定性时过于乐观。Thrun and Schwartz (1993)已经观察到这一点,他们指出,与面对不确定性时的乐观态度相比,这些高估实际上会阻碍学习最优策略。我们将在后面的实验中看到这种对策略质量的负面影响。同样:当我们使用双重Q学习减少高估时,策略会得到改善。
1 每个动作价值函数都适合不同的整数状态子集。状态 -6 和 6 总是被包括在内以避免外推,并且对于每个动作,两个相邻的整数缺失:对于动作a1,状态 -5 和 -4 没有被采样,对于a2状态 -4 和 -3 没有被采样,依此类推 . 这会导致估计值不同。
2 我们任意使用动作ai+5 (对于i ≤ 5)或ai-5 (对于i > 5)的样本作为动作 ai 的双重估计量的第二组样本。
Double DQN
双重Q学习的思想是通过将目标中的最大操作分解为动作选择和动作评估来减少高估。虽然没有完全解耦,但DQN架构中的目标网络提供了第二个价值函数的自然候选者,而无需引入额外的网络。因此,我们建议根据在线网络评估贪心策略,但使用目标网络来估计其价值。关于双重Q学习和DQN,我们将生成的算法称为双重DQN。它的更新与DQN相同,但将目标![]() 替换为:
替换为:
![]()
与双重Q学习(4)相比,第二个网络的权重![]() 被替换为目标网络的权重
被替换为目标网络的权重![]() ,用于评估当前的贪心策略。对目标网络的更新与DQN保持不变,并且仍然是在线网络的定期副本。
,用于评估当前的贪心策略。对目标网络的更新与DQN保持不变,并且仍然是在线网络的定期副本。
这个版本的双重DQN可能是DQN对双重Q学习的最小可能变化。目标是以最小的计算开销获得双重Q学习的大部分好处,同时保持DQN算法的其余部分完好无损以进行公平比较。
Empirical results
在本节中,我们分析了DQN的高估,并表明双重DQN在价值准确性和策略质量方面都优于DQN。为了进一步测试该方法的稳健性,我们还评估了由专家人类轨迹生成的随机开始算法,如Nair et al. (2015)提出的那样。
我们的测试平台包含Atari 2600游戏,使用Arcade学习环境(Bellemare et al., 2013)。目标是使用具有一组固定超参数的单个算法来学习在仅给定屏幕像素作为输入的情况下与交互分开玩每个游戏。这是一个要求很高的测试平台:不仅输入是高维的,游戏的视觉效果和游戏机制也因游戏而异。因此,好的解决方案必须在很大程度上依赖于学习算法——仅仅依靠调整来过拟合域实际上是不可行的。
我们密切遵循Mnih et al. (2015)概述的实验设置和网络架构。简而言之,网络架构是一个卷积神经网络(Fukushima, 1988; LeCun et al., 1998),具有3个卷积层和一个全连接隐藏层(总共大约150万个参数)。网络将最后四帧作为输入,输出每个动作的动作价值。在每个游戏中,网络都在单个GPU上训练200M帧,或大约1周。
Results on overoptimism
图3显示了DQN在六款Atari游戏中高估的示例。DQN和双重DQN都在Mnih et al. (2015)描述的确切条件下进行了训练。DQN始终对当前贪婪策略的价值过于乐观,有时甚至过度乐观,这可以通过将图表顶行中的橙色学习曲线与橙色直线进行比较来看出,后者代表最佳学习策略的实际贴现价值。更准确地说,(平均)价值估计在训练期间定期计算,长度为T = 125000步的完整评估阶段为:
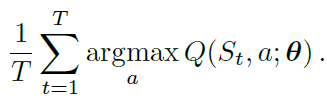
通过运行几个回合的最佳学习策略并计算实际累积奖励来获得基本事实平均价值。如果没有高估,我们会期望这些数量匹配(即曲线匹配每个图右侧的直线)。相反,DQN的学习曲线始终比真实价值高得多。双重DQN的学习曲线(以蓝色显示)更接近代表最终策略真实价值的蓝色直线。请注意,蓝色直线通常高于橙色直线。这表明双重DQN不仅产生更准确的价值估计,而且产生更好的策略。
中间两幅图显示了更极端的高估,其中DQN在Asterix和Wizard of Wor游戏中非常不稳定。请注意 y 轴上值的对数刻度。底部的两个图显示了这两个游戏的相应分数。请注意,中间图中DQN价值估计的增加与底部图中分数的降低一致。同样,这表明高估正在损害最终策略的质量。如果孤立地看待,人们可能会认为观察到的不稳定性与使用函数近似的异策学习的固有不稳定性问题有关(Baird, 1995; Tsitsiklis and Van Roy, 1997; Sutton et al., 2008; Maei, 2011; Sutton et al., 2015)。然而,我们看到使用双重DQN的学习更加稳定,这表明这些不稳定性的原因实际上是Q学习的过度乐观。图3仅显示了几个示例,但在所有49个测试的Atari游戏中都观察到DQN的高估,尽管数量不同。
Quality of the learned policies
过度乐观并不总是对学习策略的质量产生不利影响。例如,尽管略微高估了策略价值,但DQN在Pong中实现了最佳行为。然而,减少高估可以显著有利于学习的稳定性;我们在图3中看到了明显的例子。我们现在通过评估所有49款DQN测试的游戏,更普遍地评估双重DQN在策略质量方面的帮助程度。
正如Mnih et al. (2015)所述,每个评估回合首先执行一个不影响环境的特殊无操作动作多达30次,为智能体提供不同的起点。评估期间的一些探索提供了额外的随机化。对于双重DQN,我们使用了与DQN完全相同的超参数,以允许进行仅专注于减少高估的受控实验。学到的策略在5分钟的模拟器时间(18000帧)内进行评估,其中ε-贪婪策略ε = 0.05。分数在100个回合中取均值。双重DQN和DQN之间的唯一区别是目标,使用![]() 而不是YDQN。这种评估有点对抗,因为使用的超参数针对DQN而不是针对双重DQN进行了调整。
而不是YDQN。这种评估有点对抗,因为使用的超参数针对DQN而不是针对双重DQN进行了调整。
为了获得跨游戏的汇总统计数据,我们将每个游戏的得分归一化如下:

"随机"和"人类"分数与Mnih et al. (2015)使用的相同,并在附录中给出。
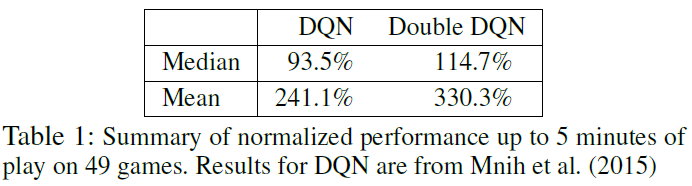
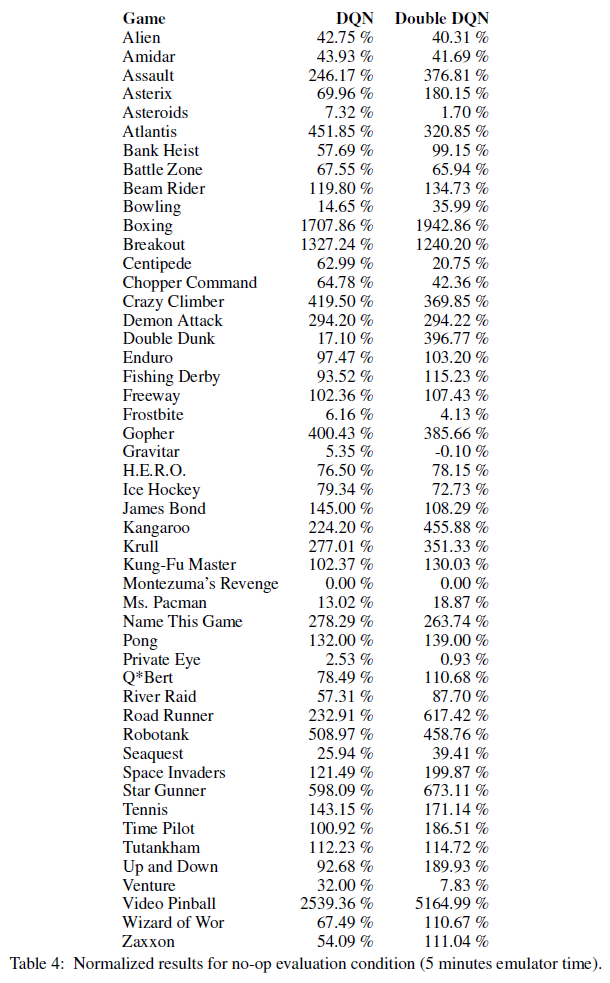
表1,在没有操作的情况下,表明整体上双重DQN明显优于DQN。详细的比较(在附录中)表明,有几款游戏的双重DQN大大改进了DQN。值得注意的例子包括Road Runner (从233%到617%)、Asterix (从70%到180%)、Zaxxon (从54%到111%)和Double Dunk (从17%到397%)。
Gorila算法(Nair et al., 2015)是DQN的大规模分布式版本,由于架构和基础设施差异很大,因此直接比较不清楚。为了完整起见,我们注意到Gorila分别获得了96%和495%的中值和平均归一化分数。

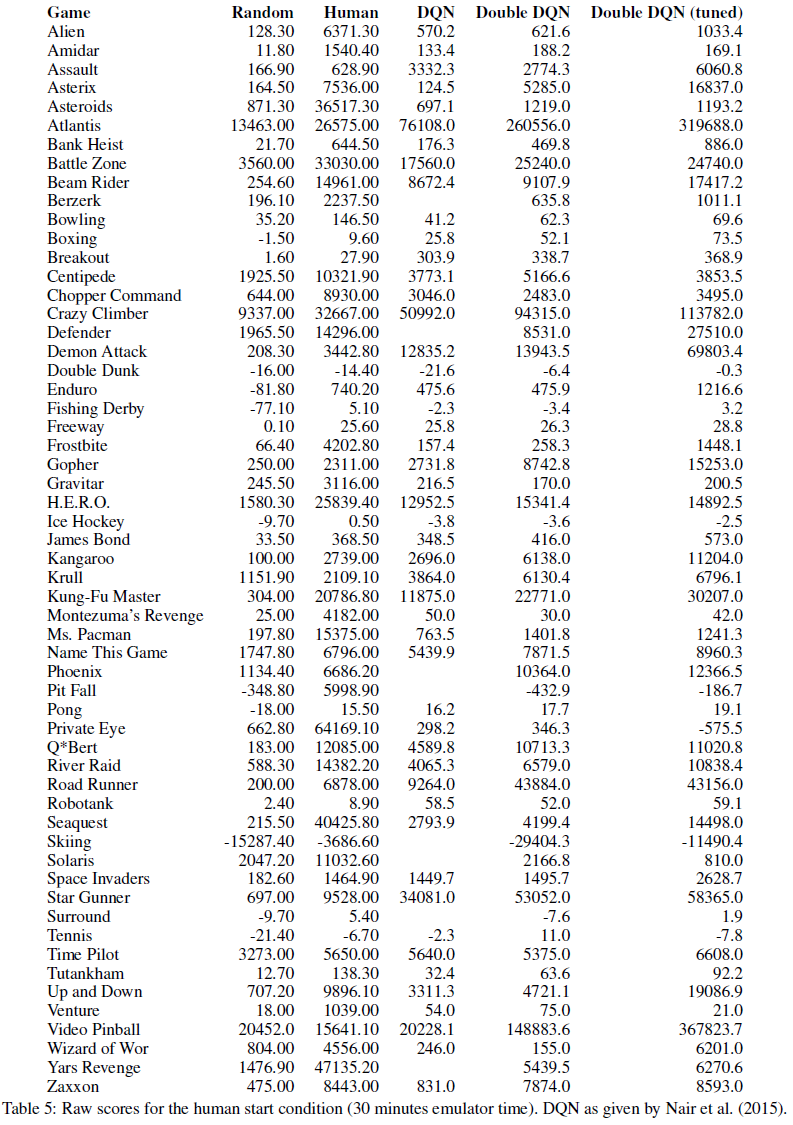
Robustness to Human starts
对先前评估的一个担忧是,在具有独特起点的确定性游戏中,学习者可以潜在地学会记住动作序列,而无需太多泛化。虽然成功,但该解决方案不会特别强大。通过从不同的起点测试智能体,我们可以测试找到的解决方案是否泛化良好,从而为学习策略提供了一个具有挑战性的测试平台(Nair et al., 2015)。
正如Nair et al. (2015)提出的,我们从人类专家的轨迹中为每个游戏采样了100个起点。我们从这些起点中的每一个开始评估回合,并运行模拟器最多108000帧(60Hz下30分钟,包括起点之前的轨迹)。每个智能体仅根据起点后累积的奖励进行评估。
在本次评估中,我们包含了双重DQN的调整版本。一些调整是合适的,因为超参数是针对DQN调整的,这是一种不同的算法。对于双重DQN的调整版本,我们将目标网络的每两个副本之间的帧数从10000增加到30000,以进一步减少高估,因为在每次切换后DQN和双重DQN都立即恢复为Q学习。此外,我们将学习期间的探索从ε = 0.1减少到ε = 0.01,然后在评估期间使用ε = 0.001。最后,调整后的版本对网络顶层的所有动作价值使用单个共享偏差。这些变化中的每一个都提高了性能,并且它们共同产生了明显更好的结果。3
表2报告了Mnih et al. (2015)对49个游戏的评估的汇总统计数据。双重DQN获得明显更高的中位数和平均分数。同样Gorila DQN (Nair et al., 2015)未包含在表中,但为了完整性,它获得了78%的中位数和259%的平均值。图4和附录中提供了详细结果以及另外8个游戏的结果。在几个游戏中,从DQN到双重DQN的改进是惊人的,在某些情况下使分数更接近人类,甚至超过了这些。
对于这种更具挑战性的评估,双重DQN似乎更加稳健,这表明发生了适当的泛化,并且找到的解决方案没有利用环境的确定性。这很有吸引力,因为它表明在寻找通用解决方案而不是确定性的步骤序列方面取得了进展,这些步骤将不太健壮。
3 除了Tennis,在训练期间,低 ε 似乎是伤害而不是帮助。
Discussion
这篇论文有五个贡献。首先,我们展示了为什么Q学习在大规模问题中可能过于乐观,即使这些问题是确定性的,因为学习的固有估计误差。其次,通过分析Atari游戏的价值估计,我们发现这些高估在实践中比之前承认的更为普遍和严重。第三,我们已经证明可以大规模使用双重Q学习来成功地减少这种过度乐观,从而使学习更加稳定和可靠。第四,我们提出了一种称为双重DQN的具体实现,它使用DQN算法的现有架构和深度神经网络,无需额外的网络或参数。最后,我们展示了双重DQN找到了更好的策略,在Atari 2600域上获得了新的最先进的结果。
Appendix




Experimental Details for the Atari 2600 Domain
我们选择了49款游戏来匹配Mnih et al. (2015)使用的列表,完整列表见下表。每个智能体步骤由四个帧组成(在这些帧中重复最后选择的动作),奖励值(从Arcade学习环境(Bellemare et al., 2013)获得)被限制在-1和1之间。
Network Architecture
实验中使用的卷积网络正是Mnih et al. (2015)提出的卷积网络,为了完整起见,我们仅在此处提供详细信息。网络的输入是一个84x84x4的张量,其中包含最后四帧的重新缩放和灰度版本。第一个卷积层用32个大小为8(步幅为4)的滤波器对输入进行卷积,第二层有64个大小为4的层(步幅为2),最后一个卷积层有64个大小为3的滤波器(步幅为1)。接下来是512个单元的全连接隐藏层。所有这些层都由整流器线性单元(ReLu)分隔。最后,一个全连接的线性层投影到网络的输出,即Q值。用于训练网络的优化是RMSProp(动量参数为0.95)。
Hyper-parameters
在所有实验中,折扣设置为γ = 0.99,学习率设置为α = 0.00025。目标网络更新之间的步数τ = 10000。训练超过50M步(即200M帧)。每1M步对智能体进行一次评估,并将这些评估中的最佳策略保留为学习过程的输出。经验回放内存的大小为1M元组。内存被采样以每4步更新网络,小批量大小为32。使用的简单探索策略是ε-贪婪策略,在1M步内从1线性下降到0.1。
Supplementary Results in the Atari 2600 Domain
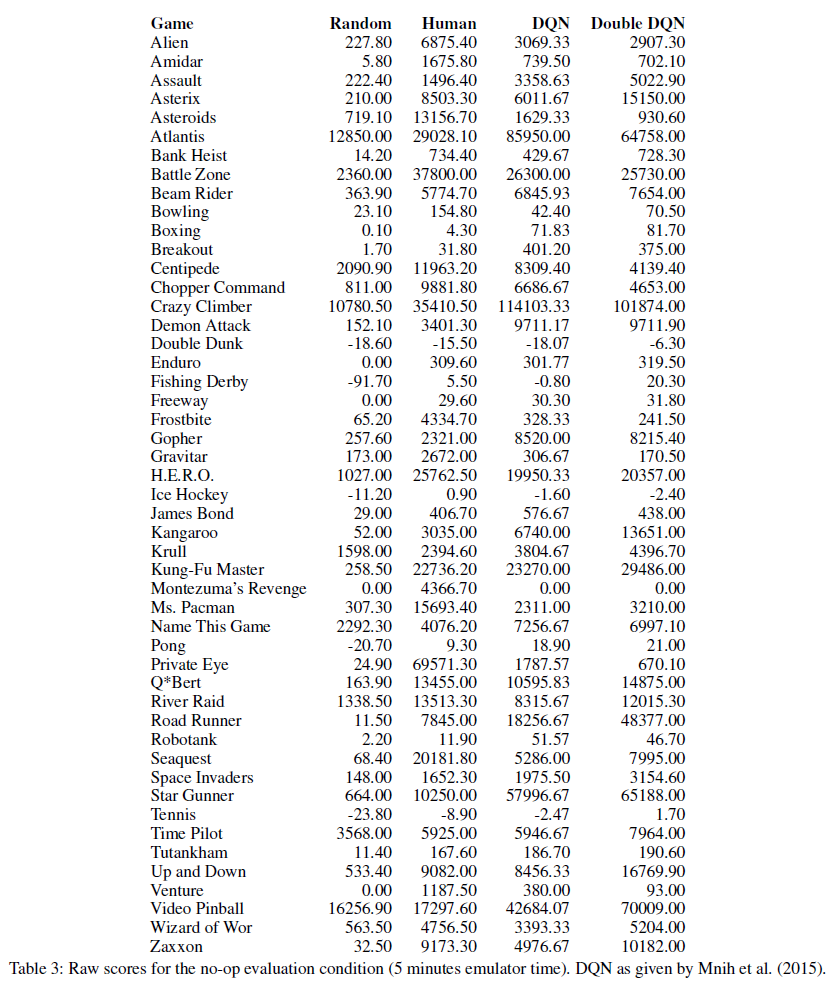
下表为我们在Atari领域的实验提供了更详细的结果。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号