
Human-Level Control through Directly-Trained Deep Spiking Q-Networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
 IEEE Transactions on Cybernetics 2022
IEEE Transactions on Cybernetics 2022
PS:本文翻译版不是最终提交版本
Abstract
作为第三代神经网络,脉冲神经网络(SNN)由于其高能效,在神经形态硬件上具有巨大的潜力。然而,深度脉冲强化学习(DSRL),即基于SNN的强化学习(RL),由于脉冲函数的二值输出和不可微分的特性,仍处于初级阶段。为了解决这些问题,我们在本文中提出了深度脉冲Q网络(DSQN)。具体来说,我们提出了一种基于Leaky Integrate-and-Fire (LIF)神经元和Deep Q-Network (DQN)的直接训练的深度脉冲强化学习架构。然后,我们为深度脉冲Q网络采用直接脉冲学习算法。我们从理论上进一步证明了在DSQN中使用LIF神经元的优势。已经对17款表现最好的Atari游戏进行了综合实验,以将我们的方法与最先进的转换方法进行比较。实验结果证明了我们的方法在性能、稳定性、鲁棒性和能源效率方面的优越性。据我们所知,我们的工作是第一个使用直接训练的SNN在多个Atari游戏上实现最先进性能的工作。
Index Terms——Deep Reinforcement Learning, Spiking Neural Networks, Directly-Training, Atari Games.
I. INTRODUCTION
近年来,脉冲神经网络(SNN)因其在神经形态硬件上的低功耗[1]而引起了广泛关注。与使用连续值来表示信息的人工神经网络(ANN)不同,SNN使用离散脉冲来表示信息,这是受到时空动力学和通信方法中生物神经元行为的启发。这使得SNN已经在专用的神经形态硬件上成功实现,例如英国曼彻斯特的SpiNNaker[2]、IBM的TrueNorth[3]和英特尔的Loihi[4],据报道,这些芯片的能效比传统芯片高1000倍。此外,最近的研究表明,与人工神经网络相比,SNN在图像分类[5]、对象识别[6][7]、语音识别[8]和其他领域[9]–[13]具有竞争力。
目前的工作重点是将SNN与深度强化学习(DRL)相结合,即Atari游戏上的深度脉冲强化学习(DSRL),与图像分类相比,这涉及额外的复杂性。DSRL的发展落后于DRL,而DRL在许多强化学习(RL)任务中取得了巨大的成功,甚至超过了人类水平的表现[14]–[19]。主要原因是训练SNN是一项挑战,因为事件驱动的脉冲活动是离散且不可微的。此外,脉冲神经元的活动不仅在空间域逐层传播,而且也沿时间域传播[20]。这使得强化学习中SNN的训练更加困难。
为了避免训练SNN的困难,[21]提出了一种将ANN转换为SNN的替代方法。[22]将现有的转换方法[23]–[25]扩展到深度Q学习领域,提高了SNN在输入图像遮挡中的鲁棒性。在此之后,[26]提出了一种更稳健且更有效的转换方法,将预先训练好的深度Q网络(DQN)转换为SNN,并在多个Atari游戏中实现了一流的性能。然而,现有的转换方法严重依赖于预训练的人工神经网络。此外,它们需要很长的仿真时间窗口(至少数百个时间步骤)才能收敛,这在计算方面要求很高。
为了保持SNN的能效优势,最近广泛研究了直接训练方法[27]–[30]。例如,[31]提出了一种依赖于阈值的批归一化方法来直接训练深层SNN。首次在ImageNet上探索了直接训练的高性能深层SNN。此外,通过设计一个近似脉冲反向传播行为的替代梯度函数,替代梯度学习(SGL)被提出来解决脉冲函数中的不可微问题[32]。与现有的转换方法相比,它的灵活性和效率使得它在克服SNN的训练挑战方面更有希望。然而,现有的大多数直接训练方法只关注图像分类,而不关注RL任务。
除了训练方法外,深度脉冲强化学习还有另一个挑战,即如何从高度相似的Q值中区分最佳动作[26]。事实证明,在优化用于图像分类的人工神经网络的过程中,正确分类的值总是显著高于错误分类的值。与图像分类相比,即使对于强化学习方面训练有素的网络,不同动作的Q值也往往非常相似[26]。实际上,令人困惑的Q值问题在强化学习中并不是一个真正的问题,因为传统人工神经网络的连续信息表征。但在深度脉冲强化学习中,如何使SNN输出的离散脉冲很好地代表这些高度相似的Q值是一个具有挑战性的问题。
为了解决这些问题,我们在本文中提出了一个深度脉冲Q网络(DSQN)。具体来说,我们在DSQN中使用LIF神经元,使用发放率编码和适当但极短的仿真时间窗口(64个时间步骤)来解决令人困惑的Q值问题。此外,我们采用了一种脉冲替代梯度学习算法来实现对DSQN的直接训练。此后,我们从理论上证明了在DSQN中使用LIF神经元的优势。
最后,对17款表现最好的Atari游戏进行了综合实验。实验结果表明,DSQN在性能、稳定性、鲁棒性和能效方面完全超越了基于转换的SNN [26]。同时,DSQN达到了与朴素DQN [15]相同的性能水平。我们的方法提供了另一种在使用SNN的Atari游戏上实现高性能的方法,同时避免了转换方法的限制。据我们所知,我们的工作是第一个使用直接训练的SNN在多个Atari游戏上实现最先进性能的工作。它为进一步研究使用直接训练的SNN解决强化学习问题铺平了道路。
II. RELATED WORKS
[15]将深度神经网络引入到传统强化学习算法Q学习中,形成了DQN算法,开创了DRL领域。他们使用卷积神经网络来逼近Q学习的Q函数,结果,DQN在49款Atari游戏中达到甚至超过了人类水平。之后,[22]是第一个将脉冲转换方法引入深度Q学习领域的工作。他们证明,浅层和深层ReLU网络都可以转换为SNN,而不会降低Atari游戏Breakout的性能。然后,他们表明,转换后的SNN比原始神经网络更能抵抗输入扰动。然而,它只专注于提高SNN在Atari游戏上的鲁棒性而不是性能。为了进一步提高性能,[26]提出了一种更有效的转换方法,该方法基于对脉冲发放率的更准确近似。它基于预先训练的DQN减少了转换误差,并在多个Atari游戏上实现了最先进的性能。尽管这些基于转换的研究导致了DSRL的进一步发展,但仍有一些限制尚未解决,例如,对预训练的ANN的严重依赖和对非常长的仿真时间窗口的需求。其他相关工作是[33][34]。
与现有方法相比,我们的方法是通过对LIF神经元进行脉冲替代梯度学习直接训练的。这使得它更加灵活并降低了训练成本,因为它不依赖于预训练的人工神经网络,并且只需要极短的仿真时间窗口。
III. METHODS
在本节中,我们将详细描述深度脉冲Q网络(DSQN),包括直接训练的深度脉冲强化学习架构、直接学习方法以及在DSQN中使用LIF神经元的理论演示。

A. Architecture of DSQN
深度脉冲Q网络由3个卷积层和2个全连接层组成。我们使用DSQN中的LIF神经元来构建直接训练的深度脉冲强化学习架构。通过发放率编码和适当的仿真时间窗口长度,该架构可以达到足够的精度来处理第1节中提到的令人困惑的Q值问题,同时保持SNN的直接学习方法的能效优势。图1具体展示了DSQN的架构和环境交互。
对于具有L层的网络,令Vl,t表示在仿真时间 t 第 l 层中的神经元膜电位。LIF神经元整合输入,直到膜电位超过阈值Vth ∈ R+,并相应地产生一个脉冲。一旦产生脉冲,膜电位将通过硬复位或软复位来复位。请注意,硬复位意味着将膜电位重置回基准,通常为0。软复位意味着当膜电位超过阈值时,从膜电位中减去阈值Vth。
第 l ∈ {1, ... , L - 1} 层中LIF神经元的神经元动力学在仿真时间 t 可以被描述如下:
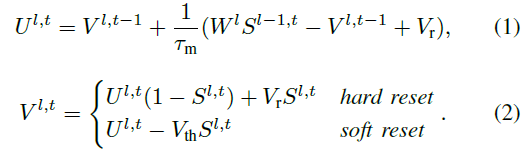
公式(1)描述了神经元的亚阈值膜电位,即当膜电位不超过阈值电位Vth时,其中τm表示膜时间常数,Wl表示第 l 层中神经元的可学习权重 , Vr表示初始膜电位。公式(2)描述了达到Vth时神经元的膜电位。
第 l ∈ {1, ... , L - 1} 层中LIF神经元的输出在仿真时间 t 可以被表示如下:
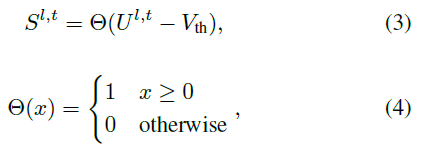
其中Θ(x)是神经元的脉冲函数。
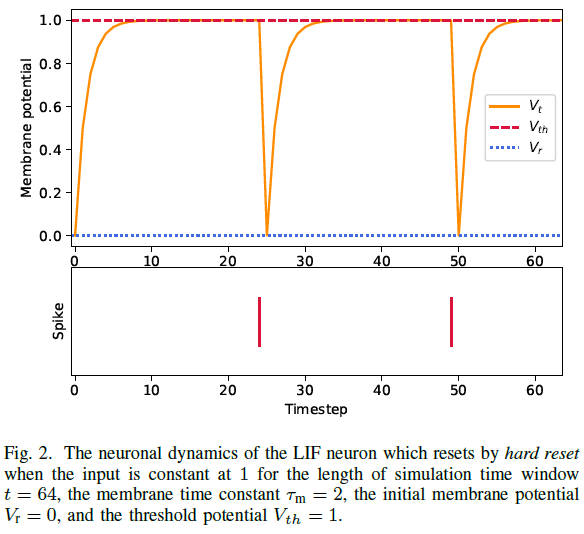
通过硬复位复位的LIF神经元的神经元动力学如图2所示。随着仿真时间的流逝,LIF神经元对输入电流进行积分,其膜电位根据公式(1)继续上升。直到膜电位达到膜电位阈值Vth,LIF神经元根据公式(3)和(4)发出脉冲。然后根据公式(2)重置膜电位。
对于最后一层 L 中的神经元,它们的输出OL可以描述为:
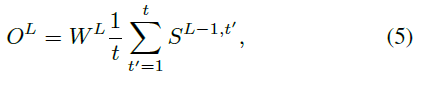
其中WL是最后一层神经元的可学习权重。同时,OL表示DSQN的输出Q值。
作为RL智能体,在与环境交互期间,DSQN通过深度Q学习算法[15]进行训练。因此,深度脉冲Q学习算法使用以下损失函数:
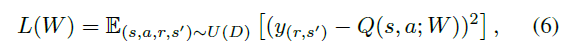
其中:

其中Q(s, a; W)表示由DSQN参数化的近似Q值函数,W和W-分别表示DSQN在当前和历史上的权重。(s, a, r, s') ~ U(D)表示从经验回放内存D中均匀随机抽取的minibatch,γ是奖励折扣因子。
根据公式(5),损失函数也可以简单地被表示为:
![]()
B. Direct learning method for DSQN
在本节中,我们只考虑通过硬复位重置的LIF神经元的情况。
根据公式(5)(8)和链式法则,对于最后一层L,我们有:
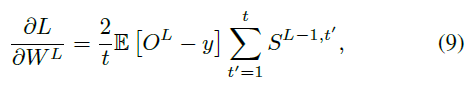
对于隐藏层 l ∈ {1, ... , L-1},根据公式(1)、(3)和(8),我们有:
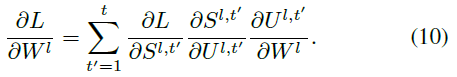
公式(10)中的第一个因素可以被导出为:
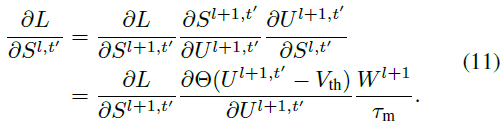
特别地,当 l = L-1 时,公式(11)不同:
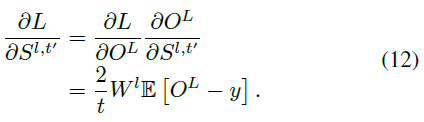
脉冲函数Θ(x)是不可微的,这导致公式(10)也是不可微的。为了解决这个问题,我们使用一个可微的替代梯度函数[32]σ(x)来近似Θ(x)。相应地,公式(11)可被改写为:
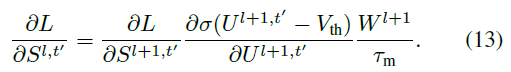
公式(10)中的第三个因素可以被推导为:
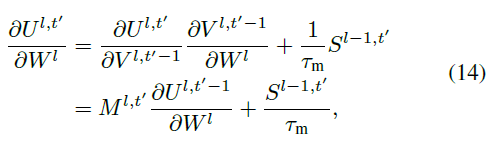
其中:
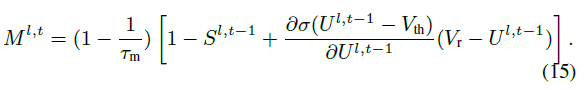
然后,我们在时间维度上连续导出梯度。当 t = 1 时,我们有:
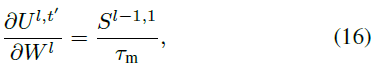
当 t > 1 时,我们得到:
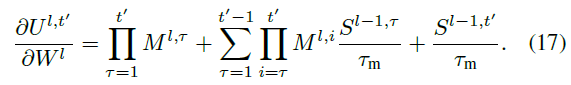
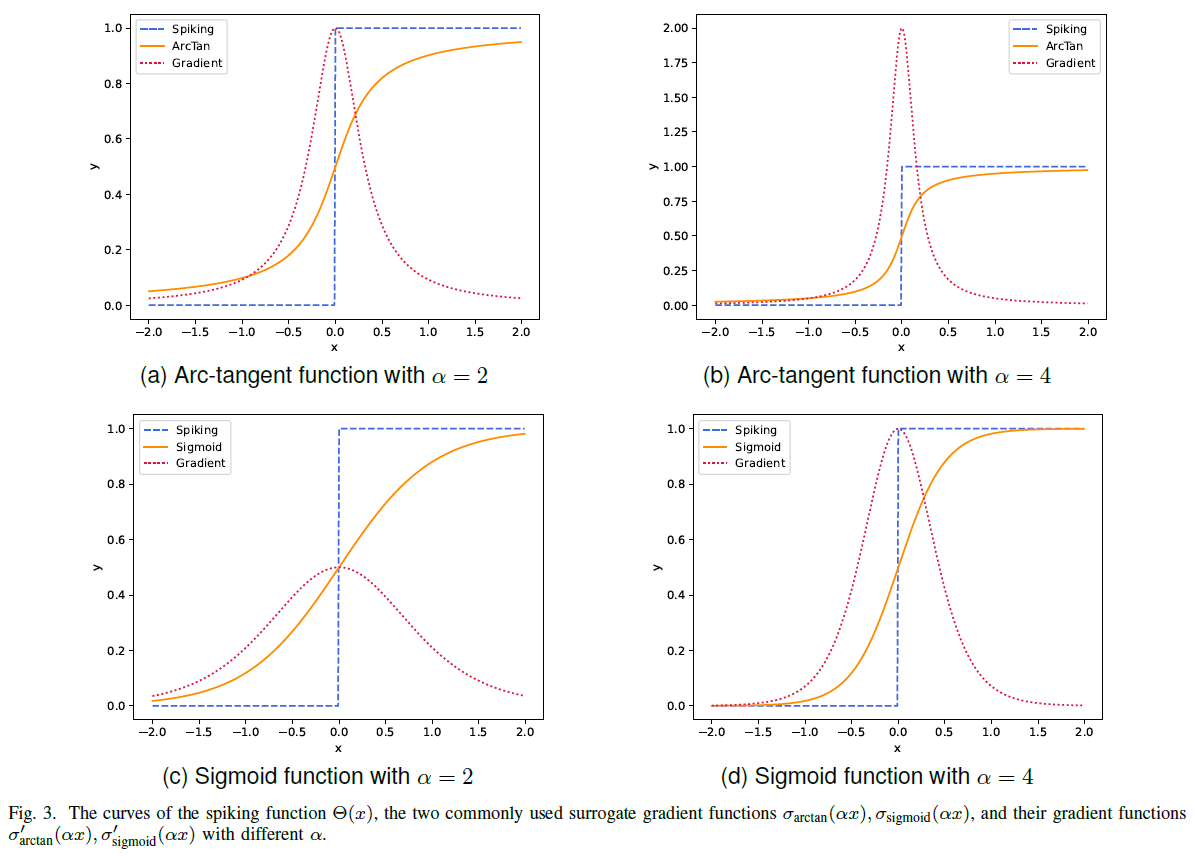
常用的替代梯度函数有反正切函数和sigmoid函数,它们都与Θ(x)非常相似。在本文中,考虑到替代梯度函数的复杂性会影响计算效率,因此我们在DSQN中使用反正切函数,其定义为:
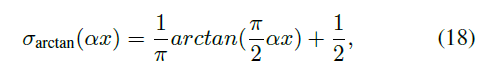
其中α是控制函数平滑度的因素。反正切函数的梯度可以被表示为:
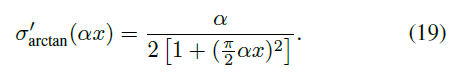
图3是脉冲函数Θ(x)的曲线,两个常用的替代梯度函数σarctan(αx), σsigmoid(αx),以及它们的梯度函数σ'arctan(αx), σ'sigmoid(αx)(不同的α取值)。值得注意的是,α越大,σarctan(αx)和Θ(x)将越接近。同时,当 x 接近 0 时,梯度更容易爆炸,而当 x 远离 0 时,梯度更容易消失。
使用替代梯度函数可以让DSQN直接通过深度脉冲Q学习算法得到很好的训练。
C. Demonstration of using LIF neurons in DSQN
在本节中,我们从理论上展示了在直接训练的深度脉冲Q网络中使用LIF神经元的优势。我们首先解释了深度脉冲强化学习中现有的转换方法为什么使用Integrate-and-Fire (IF)神经元,然后提供直接训练的DSQN中使用LIF神经元的理论。
1) Limitation of conversion methods in DSRL: [24]证明了通过软复位重置的IF神经元是ReLU激活函数随时间的无偏估计量。IF神经元的神经元动力学可以被描述为:
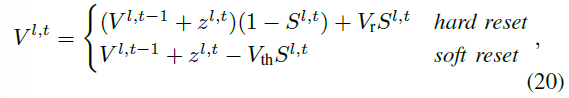
在Vr = 0且第一层的输入z1 = Vtha1不变的情况下,[24]提供了第一层中IF神经元的发放率r1,t与ReLU激活函数a1的输出之间的关系,当接收与以下相同的输入时:
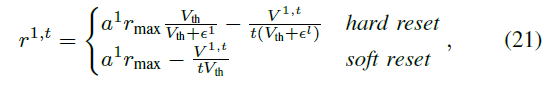
其中rmax表示最大发放率,并且 ε 表示在复位时丢弃的剩余电荷。
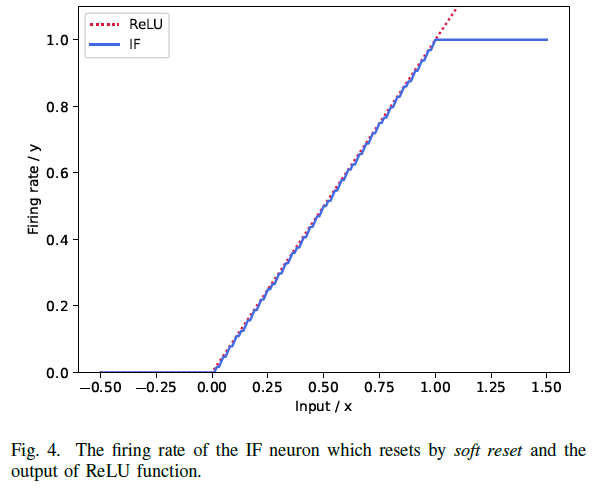
根据公式(21),当仿真时间窗口 t 的长度趋于无穷大且输入在[0, 1]之间,通过软复位重置的IF神经元是ReLU激活函数随时间的无偏估计。
图4显示了在接收相同输入时,通过软复位复位的IF神经元的发放率与ReLU激活函数的输出之间的关系。当x ∈ [0, 1]时,IF神经元的发放率与ReLU激活函数的输出高度相似。但是当输入x ≥ 1时,IF神经元的发放率不再增加,因为rmax = 1。
因此,DSRL中现有的转换方法必须引入归一化技术,将超过 1 的输入归一化为[0, 1],然后ANN可以成功地转换为SNN。这导致DSRL中现有的转换方法需要非常长的仿真时间窗口,通常为数百个时间步骤,才能达到足够的精度,从而最大限度地减少转换过程中产生的误差。此外,转换方法的固有问题,即严重依赖预训练的人工神经网络,仍未解决。
2) Advantages of using LIF neurons in DSQN: 类似于推导公式(21)的过程,我们可以从公式(1)和(2)导出一个描述第一层LIF神经元发放率的公式。为了简化符号,我们删除了层和神经元索引,让 z 表示输入,Vr = 0。
对于硬复位,从公式(2)开始,可以通过对仿真时间 t 求和来简单地计算平均发放率:

在第一层输入 z 不变的假设下,使用![]() ,我们得到:
,我们得到:
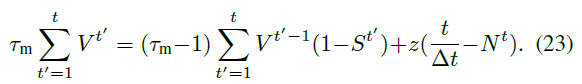
当在常数上评估时间和时,时间分辨率Δt进入公式(23): ![]() 。下面将由最大发放率
。下面将由最大发放率![]() 的定义代替。
的定义代替。
在重新排列公式(23)以产生仿真时间 t 的脉冲总数Nt,除以仿真时间 t,设置V0 = 0,并重新引入下降的索引后,我们获得第一层中LIF神经元的平均发放率 r:
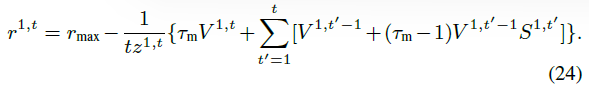
对于软复位,在仿真时间 t 上对公式(2)求均值:
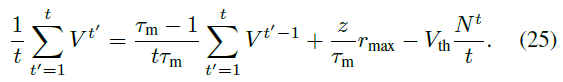
使用z1 = Vtha1,求解r = N/t,设置V0 = 0并重新引入索引得到:
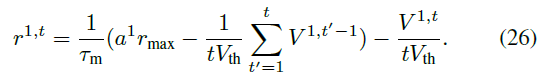
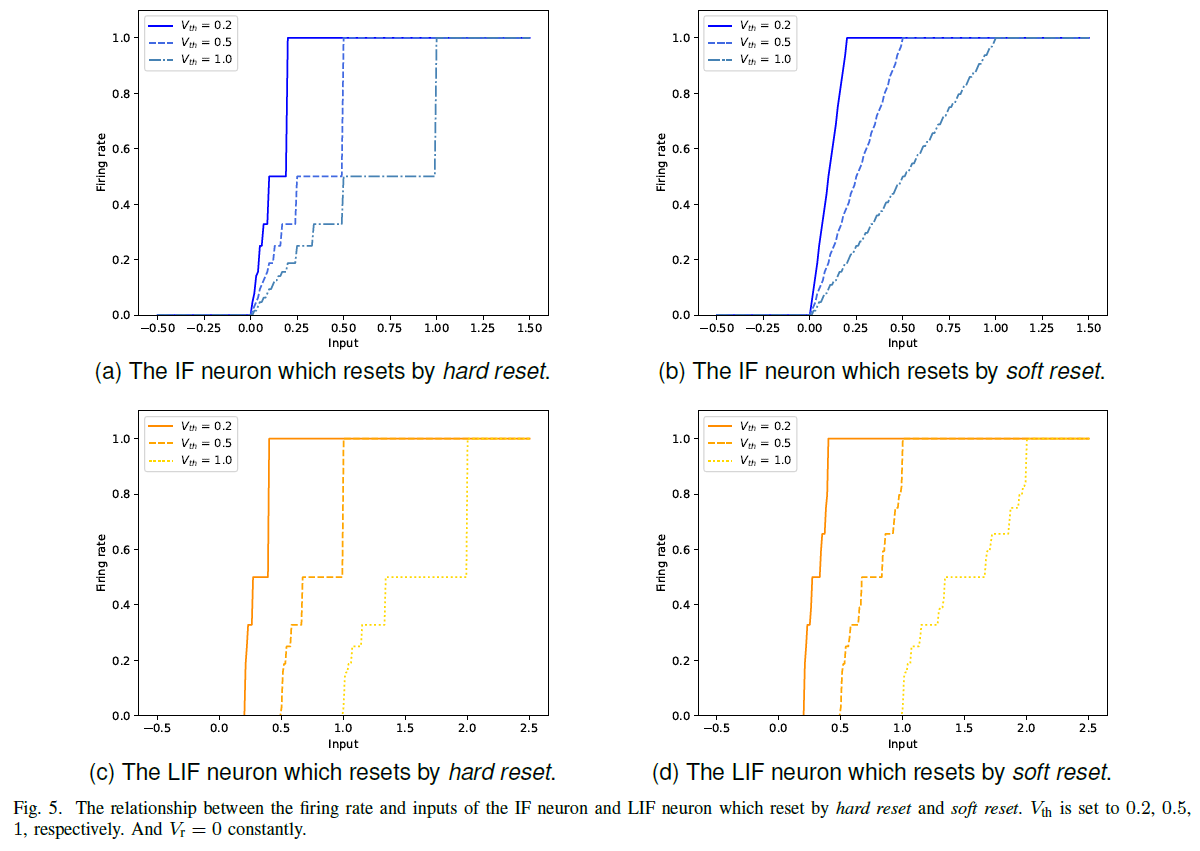
图5显示了通过不同Vth下硬复位和软复位复位的IF和LIF神经元的发放率和输入之间的关系。
与IF神经元相比,LIF神经元能够通过硬复位和软复位处理更广泛的输入(≥1)。因此,LIF神经元比IF神经元具有更强的泛化能力,可以直接训练而不依赖转换方法中的归一化技术。
IV. EXPERIMENTAL RESULTS
在本节中,我们在17款表现最好的Atari游戏上评估了深度脉冲Q网络。然后,我们以朴素DQN [15]为基准比较了DSQN和基于转换的SNN [26]的实验结果,并从几个方面分析了实验结果。
A. Experimental setup
1) Environments: 我们基于OpenAI Gym1进行了实验。每个实验都在单个GPU上运行。具体实验硬件环境如表 I 所示。

1 OpenAI Gym的开源代码可以在https://github.com/openai/gym上找到。
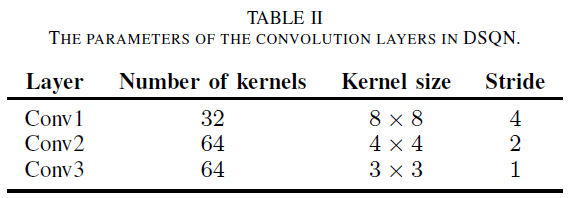
2) Parameters: 所提出的DSQN由三个卷积层和两个全连接层组成。三个卷积层的具体参数如表 II 所示,而两个全连接层使用不同的参数。第一个全连接层FC1有512个神经元,最后一层FC2在不同的Atari游戏中有不同的神经元,从4到18个,具体取决于游戏中验证动作的数量。
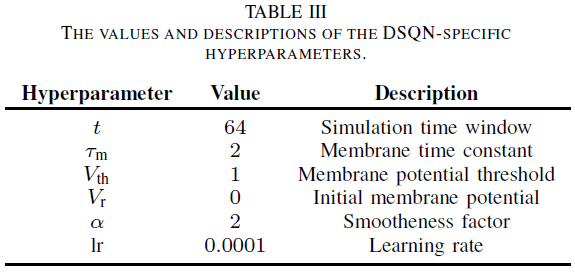
DSQN和朴素DQN都经过了50M时间步骤的训练,具有相同的架构和超参数[15]。基于转换的SNN和DSQN的仿真时间窗口长度分别设置为500和64个时间步骤。其他DSQN特定的超参数如表 III 所示。
需要指出的是,与[26]中报告的结果不同,后者是在[99.9, 99.99]中以最佳百分位数进行的,我们在复现基于转换的SNN时一直将百分位数设置为99.9。

3) Preprocessing: 在[15]之后,为了减少训练所需的计算量和内存量,我们预处理单个原始Atari游戏帧并堆叠 m 个最近的帧以产生DSQN的输入,其中m = 4。图6显示了原始的Atari图像和预处理堆叠为状态的图像。
4) Testing: 为了展示DSQN的优越性,我们选择了与[26]相同的17款性能最佳的Atari游戏,这些游戏也是朴素DQN取得了非常高的性能的游戏[15]。为了公平地将DSQN与基于转换的SNN和朴素DQN进行比较,我们复现了这两种方法。
我们通过在每场比赛中使用ε-贪婪策略(ε = 0.05)进行30轮比赛来评估这三个RL智能体。对于每一轮,智能体从不同的初始随机条件开始,采取随机次数(最多30次)无操作动作,最多玩5分钟(18000个时间步骤)。将30轮获得的分数的均值和标准差作为这三个RL智能体的最终分数和标准差。
5) Metrics: 我们分别通过他们获得的分数和标准差来评估三个RL智能体在多个Atari游戏中的性能和稳定性。我们通过朴素DQN的分数对DSQN和基于转换的SNN的分数进行了归一化。三个RL智能体的标准差首先通过它们对应的分数进行归一化,然后DSQN的归一化标准差和基于转换的SNN再次通过朴素DQN的标准差进行归一化。
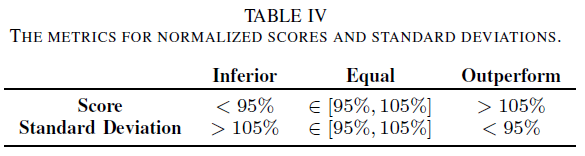
这样,我们可以通过归一化分数和标准差轻松比较DSQN与基于转换的SNN的性能和稳定性。由于DRL算法的稳定性普遍较差,我们开发了表 IV 来比较DSQN和基于转换的SNN与基于归一化分数和标准差的朴素DQN。
6) Code: 我们基于SpikingJelly [35]实现了DSQN,这是一个基于PyTorch的SNN的开源2深度学习框架。将训练好的朴素DQN通过[26]提出的方法基于其开源代码3转换为SNN。
可以在我们的Github存储库中访问源代码4。
2 SpikingJelly的开源代码可以在https://github.com/fangwei123456/spikingjelly获取。
3 [26]的开源代码可以在https://github.com/WeihaoTan/bindsnet-1访问。
4 https://github.com/AptX395/Deep-Spiking-Q-Networks
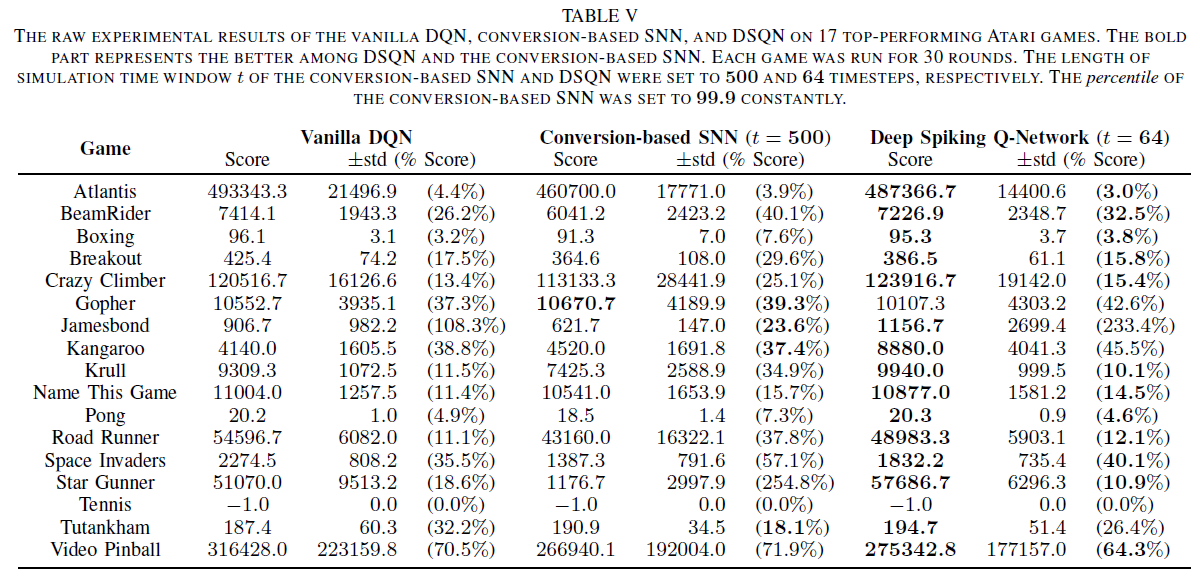
B. Comparison results
表 V 报告了三个RL智能体在17款表现最好的Atari游戏中的原始实验结果,包括分数、标准差。通过使用上一节中说明的指标,我们从表 V 中获得了表 VI,它通过使用朴素DQN的分数和标准差对表 V 中的原始实验结果进行归一化,显示了DSQN和基于转换的SNN之间的性能和稳定性差异。
1) Performance: 根据表 VI 所示分数的差异,DSQN在17款Atari游戏中的15款中取得了高于基于转换的SNN的分数。这说明了我们的DSQN直接学习方法与转换方法相比的优越性。
同时,根据表 VI 所示的分数和表 IV 的判断标准,DSQN在4个游戏中优于朴素DQN,在9个游戏中与它相同,在4个游戏中低于它。这说明我们直接训练的深度脉冲强化学习架构在解决DRL问题方面具有与朴素DQN相同水平的性能。
此外,DSQN表现出比基于转换的SNN更高的能效,因为DSQN的性能优于基于转换的SNN,而其仿真时间窗口长度仅为64个时间步骤,比基于转换的SNN低一个数量级。基于转换的SNN (500个时间步骤)。

2) Stability: 根据表六所示标准差的差异,DSQN在17款Atari游戏中有12款游戏的标准差低于基于转换的SNN。这说明DSQN在稳定性方面比基于转换的SNN更强。
同时,根据表 VI 所示的标准差和表 IV 所示的评判标准,DSQN在6个游戏中优于朴素DQN,在2个游戏中与之相当,在9个游戏中低于它。这说明DSQN具有与朴素DQN相同水平的稳定性。
此外,DSQN比基于转换的SNN表现出更强的鲁棒性,因为当在17款Atari游戏中的每款游戏上测试DSQN和基于转换的SNN时,它们各自的超参数在测试期间是恒定的。
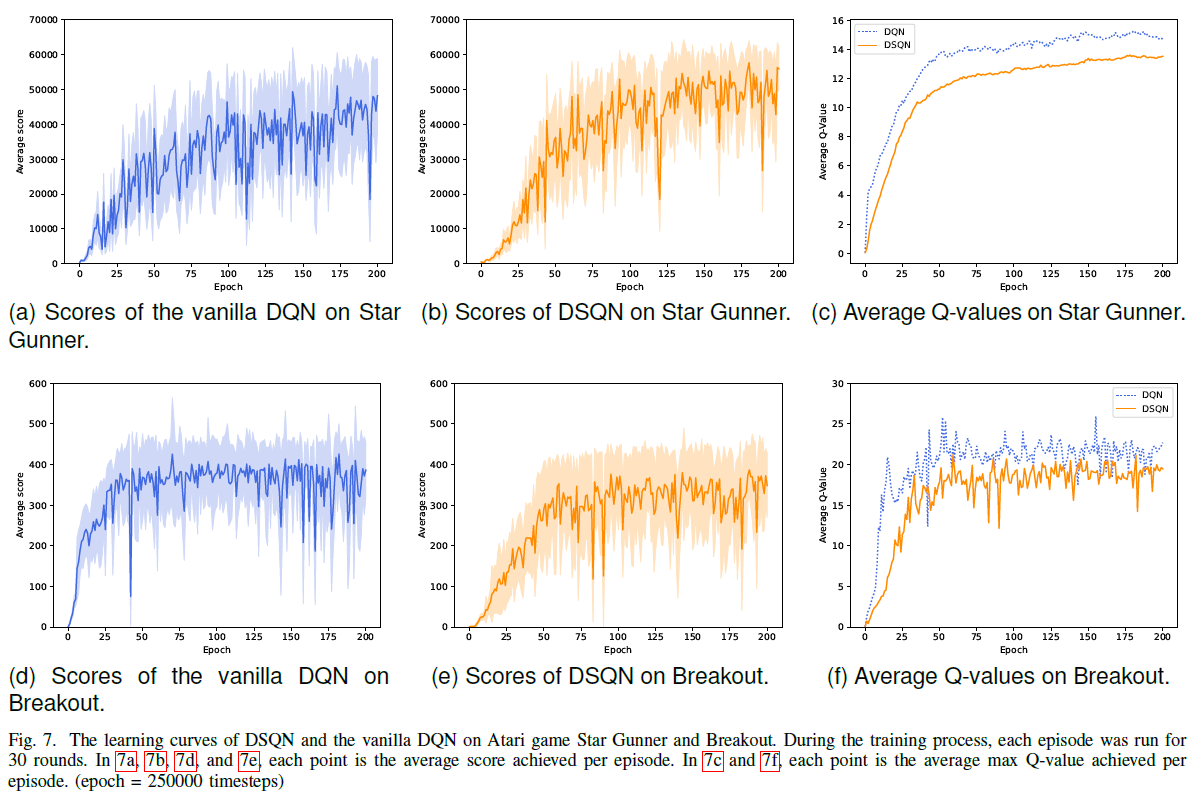
3) Learning capability: 除了比较DSQN和基于转换的SNN之外,我们还分析了DSQN和朴素DQN之间的差距。
图7显示了训练过程中DSQN和朴素DQN在Atari游戏Star Gunner和Breakout上的学习曲线。
如图7a和7b所示,DSQN的得分总体上高于朴素DQN。如图7d和7e所示,虽然DSQN的得分总体上略低于朴素DQN,但DSQN的标准差总体上低于朴素DQN。这表明,DSQN具有与朴素DQN相同水平的学习能力,可以达到与朴素DQN相同水平的性能,同时具有更高的稳定性。图7c和7f所示的平均Q值曲线也可以证实,DSQN比普通DQN更稳定。
综上所述,结合DSQN和基于转换的SNN在分数和标准差方面的实验结果,DSQN不仅在绝大多数Atari游戏上取得了比基于转换的SNN更高的分数,而且同时达到了更低的标准差。这表明DSQN在性能和稳定性方面都优于基于转换的SNN。此外,根据DSQN和朴素DQN的比较,DSQN虽然是SNN,但其学习能力并不逊于朴素DQN。
这些实验结果证明了DSQN在性能、稳定性、鲁棒性和能效方面优于基于转换的SNN。同时,DSQN在性能上达到了与DQN相同的水平,在稳定性上超过了DQN。
V. CONCLUSIONS AND FUTURE WORKS
在本文中,我们提出了一种直接训练的深度脉冲强化学习架构,称为深度脉冲Q网络(DSQN),以解决使用SNN解决深度强化学习(DRL)任务的问题。据我们所知,我们的方法是第一个使用直接训练的SNN在多个Atari游戏上实现最先进性能的方法。我们的工作作为直接训练的SNN玩Atari游戏的基准,并为未来研究使用SNN解决DRL问题铺平了道路。LIF神经元性质的理论分析不是特别深入,我们可以在以后的工作中继续改进。此外,基于目前的工作,为了更好地激发SNN的潜力,我们计划在未来对实际的神经形态硬件进行深入的研究。


