Combining STDP and binary networks for reinforcement learning from images and sparse rewards
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Neural Networks 2021
Abstract
脉冲神经网络(SNN)旨在复制生物大脑的能源效率、学习速度和时间处理。然而,此类网络的准确性和学习速度仍落后于基于传统神经模型的强化学习(RL)模型。这项工作将预训练的二值卷积神经网络与通过奖励调节的STDP在线训练的SNN相结合,以利用两种模型的优势。脉冲网络是其先前版本的扩展,在架构和动态方面进行了改进,以应对更具挑战性的任务。我们专注于对所提出的模型进行广泛的实验评估,这些模型具有优化的最先进基准,即近端策略优化(PPO)和深度Q网络(DQN)。这些模型在具有高维观察的网格世界环境中进行比较,该环境由高达256×256像素的RGB图像组成。实验结果表明,所提出的架构可以成为评估环境中深度强化学习(DRL)的竞争替代品,并为脉冲网络的更复杂的未来应用奠定基础。
Keywords: spiking neural networks, binary neural networks, STDP, reinforcement learning.
1. Introduction
机器学习的许多最新进展都受到大自然的启发。目前的工作旨在拉近两个植根于神经科学和生物学见解的领域:强化学习(RL)和脉冲神经网络(SNN)。强化学习是一种旨在重现动物学习方式的范式(Sutton & Barto, 2018)。与监督学习场景相比,可以训练RL智能体来执行任务,而无需专家教师或有关如何实现目标的清晰、分步知识。通常,智能体能够重复试验并在成功执行一系列动作后获得奖励就足够了。请注意,例如,通过食物奖励训练实验室老鼠在迷宫中导航的方式的相似性。虽然RL的基础已经在三年前奠定(Sutton, 1988),但过去十年深度学习(DL)的进步使训练RL智能体能够处理越来越复杂的任务。最近一些深度强化学习(DRL)应用的例子包括玩Atari游戏(Mnih et al., 2015)、学习腿式机器人的敏捷和动态运动技能(Hwangbo et al., 2019)以及从头开始训练机器人操纵器(O. M. Andrychowicz et al., 2020; Gu et al., 2017)。然而,工程系统在快速学习新的复杂任务的能力方面仍然远远落后于动物系统。虽然DRL能够在大量计算预算下掌握特定技能,但大自然已经进化出能够快速适应和学习新技能的有机体(Cully et al., 2015)。
这种限制部分是由于人工神经网络(ANN)的训练过程,它构成了DRL智能体的大脑。此类网络的训练通常涉及存储在单独存储器中的大量示例。此外,经过训练的网络通常也需要比生物大脑更多的功率,从而限制了在具有嵌入式电子设备或其他有限电源的设备上的应用(Bing et al., 2018)。
传统的人工神经网络使用连续信号来逼近未知函数。相比之下,SNN使用离散脉冲并随时间处理信息。单线突触的使用允许在低功耗神经形态芯片中实现SNN,能够实时模拟多达108个脉冲神经元(Frady et al., 2020; Thakur et al., 2018)。当使用适当的传感器(例如动态视觉传感器(DVS))(Gallego et al., 2019)时,此类神经形态硬件还能够提供低延迟的感官响应。基于光学硬件的实现已被证明可以进一步减少延迟并提高较小脉冲网络的模拟速度(Feldmann et al., 2019)。
SNN可以使用受生物学启发的算法进行训练,称为脉冲时序相关可塑性(STDP)。这种方法的一个优点是每个突触只需要知道突触前和突触后神经元产生的脉冲。通过将STDP与全局强化信号相结合(R-STDP),脉冲智能体可以在不计算全局误差梯度的情况下解决RL任务。这个过程如图1所示。
目前的工作通过提供以下贡献来推进该领域:
1. 一种新颖的脉冲架构被提出并演示,以从RGB图像作为输入的稀疏和延迟奖励中学习。
2. 优化了网络输入层和隐含层之间突触的稀疏性,并显示出对学习速度和准确性有显著影响。
3. 在评估环境中,所提出的网络在学习速度和学习策略的最终延迟方面均显示出与最先进的DRL算法的竞争力。
此篇文章的结构如下。第2节提供了相关文献的回顾和与当前工作的比较。第3节描述了所提出的模型,并在第4节中与基准模型进行了实验比较。总结性评论和对未来可能的努力的讨论可以在第5节中找到。额外的实验和演示代码作为补充材料提供。

2. Related works
Izhikevich (2007)、Florian (2007)和Legenstein et al. (2008)独立地为R-STDP调节脉冲网络奠定了基础。为了证明这种方法的计算能力和时间能力,Florian (2007)展示了一个由脉冲神经元组成的完全连接的多层网络,以解决具有延迟奖励的时间编码XOR问题。虽然理论模型已经使用奖励调节的STDP超过十年,但最近的研究提供了资格迹在强化学习中作用的实验证据(Gerstner et al., 2018)。本工作中使用的R-STDP规则是Florian (2007)工作中发现的RMSTDPET的简化版本。
Potjans et al. (2011)和后来的Frémaux et al. (2013)提出了具有时序差分(TD)的actor-critic模型。Frémaux and Gerstner (2016)随后引入了一个更一般的三因素学习规则。这些早期模型的一个缺点是,实现的网络在输入层对观察到的状态进行完全编码,功能上类似于经典的表格RL算法。换句话说,输入层中的每个神经元用于编码环境的特定状态。我们在上一篇论文(Chevtchenko & Ludermir, 2020)中通过一个带有隐含位置单元的四层网络解决了可伸缩性方面的限制。目前的工作重点是修改该结构,以展示与具有图像观测的最先进DRL算法相当的性能。
Nakano et al. (2015)先前通过基于自由能的RL模型的脉冲版本(Otsuka et al., 2010)解决了从具有延迟奖励的图像中训练SNN的问题。使用T-迷宫环境验证了所提出的模型,该模型包含来自MNIST数据集的28×28二值图像的视觉线索。目前的工作是在这个任务的一个更具挑战性的版本上进行评估的,使用高达256×256像素的RGB图像。受Nakano et al. (2015)的启发,我们还评估了预先训练的二值CNN作为特征提取器。然而,该网络在不同于测试环境中显示的图像集上进行训练。
Wunderlich et al. (2019)使用R-STDP制作一个小型脉冲网络,学习在BrainScaleS 2神经形态系统上玩简化版的Atari游戏pong。这项工作的主要目的是证明神经形态硬件的功耗优势,并且所提出的架构具有与以前工作类似的可扩展性限制。
Kaiser et al. (2019)提出了一个与机器人模型交互的神经模拟框架。先前提出的突触可塑性规则SPORE (Kappel et al., 2018)通过少量视觉神经元(分别为16×16和16×4)提供的观察结果,对球平衡和线跟踪任务进行评估。作者指出,随着时间的推移,逐渐降低学习率可以提高算法的性能。这项工作为加入机器人技术和脉冲网络领域做出了重要贡献。然而,该框架旨在模拟生物真实的神经元和突触,与深度学习方法相比,没有表现出竞争性的性能。虽然生物学合理性并不是最先进性能的明显障碍,但在目前的工作中,我们选择将所提出的模型与现代DRL算法进行比较(Mnih et al., 2015; Schulman et al., 2017)。
Tang et al. (2020)最近探索了一种训练SNN的混合方法。在这项工作中,使用DDPG算法(Lillicrap et al., 2015),深度学习critic协助训练脉冲actor。因此,当critic网络成功地逼近环境的奖励函数时,脉冲actor可以有效地部署在机器人上。对联合训练进行了优化,结果表明,与单独使用DDPG和DDPG到脉冲的转换方法相比,联合训练在测试环境中更有效。另一方面,Bing et al. (2020)最近的另一项工作将通过R-STDP训练的脉冲网络与DQN到脉冲的转换进行了比较。在评估的车道跟驰任务中,训练后R-STDP比DQN转换为脉冲网络更有效。类似地,在目前的工作中,我们将预先训练的二值CNN与通过R-STDP训练的脉冲模型相结合,并表明它与PPO和DQN算法具有竞争力。
Bellec et al. (2020)提出了一种称为e-prop的学习规则,并将其应用于循环脉冲网络。该规则被证明近似于在两个离散Atari游戏上通过时间反向传播训练的LSTM网络的性能。这是一种很有前途的方法,值得注意的是,脉冲循环网络是在线训练的,每一步只接收当前帧。然而,结果没有直接与DRL方案进行比较,学习速度也没有得到解决。与目前的工作类似,在模拟过程中,与资格迹相关的时间参数逐渐增加。当前的工作重点是展示学习速度和质量方面的竞争力,将我们的方法与优化的最新RL算法进行比较。在未来,我们打算探索循环连接以及卷积脉冲网络的在线训练,这两种情况均出现在Bellec et al. (2020)中。
Chung and Kozma (2020)独立于Bellec et al. (2020),提出了一种基于STDP的反馈调节脉冲网络学习规则。学习规则是基于发放率而不是单个脉冲。虽然该网络被证明能够解决两个经典控制问题,但其性能与Sutton and Barto (2018)的在线actor-critic智能体相当。在之前的工作(Chevtchenko & Ludermir, 2020)中,我们已经证明,在类似于Chung and Kozma (2020)中发现的控制任务上,所提出的脉冲模型可以优于DQN算法。
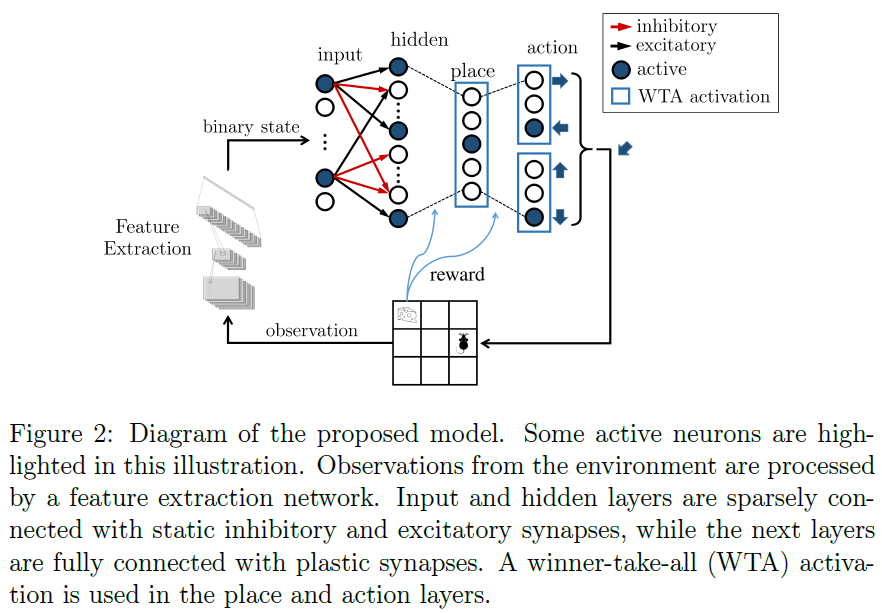
3. The proposed network
所提出的模型基于先前引入的脉冲结构(Chevtchenko & Ludermir, 2020)。网络的主要组件及其与环境的交互如图2所示。智能体与环境的交互是以循环的方式完成的。在每一步中,环境都会被智能体的动作修改,并提供新的观察结果,以及适当时的标量奖励信号。以下各节更详细地描述了模型的结构和动力学。
3.1. Neural model
这项工作中使用的脉冲模型类似于IF模型,没有泄漏和不应期。神经元的内部电位是带有附加噪声的突触前脉冲的加权和。如果内部电位达到某个阈值,神经元会发出一个脉冲并重置其电位。我们的模型是使用自定义代码而不是现有的用于刺激神经元的软件来模拟的。因此,通过优先考虑硬件模拟和实现的简易性,我们不使用生物学合理的参数。因此,尽管可以分配物理维度,但这项工作中提出的参数是无单位的。
当内部电位达到阈值时,神经元从突触前脉冲累积电荷并向突触后神经元发出脉冲。在整篇论文中,j 和 i 分别用于指代突触前和突触后神经元。神经元 i 的离散时间更新规则如下:

其中vi(t)是神经元 i 的电位,ξi(t)是高斯噪声。噪声以零为中心,具有标准差σn,仅适用于place和output层中的神经元。突触前神经元的激活是一个二值变量sj。wj,isj(t - 1)是神经元 j 从突触前脉冲诱导的神经元 i 中的电位,由神经元 i 和 j 之间的突触效能加权。其他特定于层的参数将在下一节中描述。
3.2. Feature extraction network
在之前的工作中,脉冲网络被证明可以通过one-hot离散化方法(Chevtchenko & Ludermir, 2020)从具有多达六个传感器的稀疏输入中学习RL任务。虽然这种编码对少量模拟传感器有效,但在处理更高维度的输入(例如图像)时,它会导致输入层大得不切实际。例如,具有10位one-hot编码的128×128 RBG图像将需要491520个输入神经元。为了克服这个限制,卷积神经网络被用作特征提取器。在目前的工作中评估了二值CNN (Courbariaux et al., 2016)。请注意,通过适当的二值化方法,可以在此步骤中使用任何特征提取器。然而,当与SNN结合时,二值网络提供了两个吸引人的优势。首先,预训练的二值CNN至少可以像脉冲网络一样高效。其次,二值网络的任何层都可以简单地成为SNN的输入层,其中"1"表示脉冲。在当前实现中,"-1"激活被认为在相应的输入神经元中不存在脉冲。因此,不需要像标准CNN那样进行模数转换,从而产生更大的输入层或基于时间的编码。值得注意的是,需要定制硬件来同时利用脉冲网络和二值网络的优势。本文提出的混合模型可以更紧凑地实现无状态特征提取和输入隐藏神经元,其中不使用突触迹。
图3提供了本工作中使用的二值卷积架构的说明。与传统的监督学习场景不同,该网络是在少量随机选择的图像上进行训练的。这加快了训练速度,因为网络不必学习如何将不同的图像分类。相反,卷积滤波器被训练来区分一组随机的100个图像。 具有128个神经元的隐藏全连接层用作脉冲网络的输入。请注意,特征提取网络是在与RL环境中用作观察的不同图像类别上进行训练的。第4.1节提供了有关数据集划分的更多详细信息。

二值网络作为特征提取器的训练可以概括为以下步骤:
1. 选择100张图像的随机子集进行训练。
2. 创建一个有100个输出神经元的二值网络。
3. 将网络训练为具有100个类别的分类问题,直到收敛。
4. 保存训练好的模型,丢弃最后一层。
该网络的实现主要基于快速机器学习实验室存储库Kreis et al., 2020中提供的网络,并包含在示例代码中(有关补充材料,请参见附录A)。Adam优化器与默认参数一起使用。该模型在1000个回合中进行训练,学习率从训练开始时的10-3线性衰减到结束时的10-4。
经过训练的特征提取器有128个输出神经元,每个二值神经元产生+1或-1激活。在目前的工作中,-1被认为是SNN的输入层中没有脉冲。也可以在输入层使用一对抑制性和兴奋性神经元。在这种情况下,-1或+1激活会在相应的抑制性或兴奋性神经元中产生一个脉冲。然而,这种方法没有在实验中进行评估,因为它会使输入层中的神经元数量增加一倍。
3.3. Input and hidden layers
3.4. Place neurons
3.5. Output layer
4. Experimental evaluation
4.1. Environment
4.2. Baseline models
在此,我们简要描述了两种用作基准的DRL算法。两者都是众所周知的,并且已经被广泛地进行了基准测试。我们的实现基于Stable Baselines3 (SB3)库,它是PyTorch中强化学习算法的一组可靠实现(Raffin et al., 2019)。没有对算法进行任何修改,除了允许超参数调整,如第4.3节所述。
4.2.1. Deep Q network
4.2.2. Proximal policy optimization
4.3. Hyperparameter optimization
4.3.1. Baseline algorithms
4.3.2. The proposed network
所提出的网络的优化分为两部分。受Frémaux et al. (2013)描述的类似实验的启发,输入层和隐藏层之间的连接在线性轨道环境中得到优化。线性轨道是第4.1节中描述的网格世界的简化。由于其低模拟成本,它允许在一个小的超参数空间中进行完整的搜索。
(未完待续)
4.4. Results
4.4.1. Connectivity optimization
4.4.2. Comparison with baseline models
在本节中,我们将提出的SNN与基准算法进行比较。每个算法的优化超参数集在表1, 2和4中突出显示。
SNN、PPO和DQN在大小为10×10的网格世界和由来自Linnaeus 5数据集的64×64 RGB图像组成的观察值上进行评估。结果如图10所示。还提供了随机智能体的性能以供参考。PPO和SNN都显著优于DQN算法。PPO和SNN的性能相似,但SNN的最终延迟稍好一些。
图11提供了更大的20×20网格世界的结果。相对性能类似于10×10配置,SNN和PPO明显优于DQN。请注意,优化的PPO在前200个回合中实现了较低的延迟。然而,可以通过调整单个时间参数来调整SNN的性能以改善延迟,如第4.4.3节所示。
4.4.3. Impact of hyperparameters
4.5. Discussion and summary
与DRL算法相比,上一节中提供的结果证明了所提出的网络的竞争力。本节包含结果摘要,以及与相关工作的重要比较。
所提出方法的一个方面是脉冲网络能够通过使用预先训练的二值CNN (Courbariaux et al. (2016)的BinaryNet)从图像观察中学习。BinaryNet每次试验只在一小组图像上训练一次。此外,该训练集是从Linnaeus 5数据集中的一类图像中随机抽取的,而网格世界环境呈现的观察结果是从同一数据集中的其他四类图像中随机抽取的。这类似于众所周知的迁移学习方法,其中从一项任务中获得的知识用于解决另一个相关问题。如果在附录A.6节中提供,则根据输入图像大小评估特征提取网络的可扩展性的补充实验。
分离特征提取和策略学习的最明显优势是降低了计算成本,因为卷积网络仅用于推理。可塑突触的数量也显著减少,并且仅限于脉冲网络的三层。应该注意的是,预训练的特征提取网络不太适合处理不断变化的环境,因为学习的滤波器可能无法提取有意义的信息。可以探索一种混合方法来解决这个限制,如果脉冲智能体长时间未能改进,则重新训练特征提取网络。
可塑突触数量的减少允许在线训练脉冲智能体,而无需使用大型内存库或通过梯度下降进行多次权重调整。值得注意的是,第2节中介绍的大多数相关脉冲模型也是在线训练的。然而,与Bellec et al. (2020)、Chung and Kozma (2020)以及Frémaux et al. (2013)提出的actor-critic架构不同。我们的网络不执行连续的权重调整。相反,突触仅在离散奖励信号时才使用资格迹进行更新。在当前的实现中,这个更新规则也施加了一些限制:期望奖励信号是稀疏的,并且观察是离散且有限的。在未来的工作中将探索所提出模型的actor-critic版本,旨在实现在更广泛的应用程序上的快速学习。
5. Conclusion and final remarks
本文提出的结果旨在为脉冲网络在强化学习中的更广泛应用提供基础和开放前景。据我们所知,这是第一篇在学习速度和准确性方面直接将提议的脉冲网络与最先进的DRL算法进行比较的论文。此外,我们将二值CNN与脉冲模型相结合,以利用两种架构的优势。所提出的网络以及基准DRL模型使用了自动超参数优化策略。优化后,可以调整单个时间参数以加快学习速度,尽管有一些稳定性成本。
5.1. Future work
Appendix A. Supplementary material
Appendix A.1. Input-hidden connectivity
Appendix A.2. Place neurons
Appendix A.3. Connectivity optimization
Appendix A.4. PPO with BinaryNet
Appendix A.5. Grid-world with positional observations
Appendix A.6. Scalability in terms of image size


 浙公网安备 33010602011771号
浙公网安备 33010602011771号