
A solution to the learning dilemma for recurrent networks of spiking neurons
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NATURE COMMUNICATIONS, no. 1 (2020): 3625-21
Abstract
循环连接的脉冲神经元网络是大脑惊人的信息处理能力的基础。然而,尽管进行了广泛的研究,但它们如何通过突触可塑性学习以执行复杂的网络计算仍不清楚。我们认为这个难题的两个部分是由神经科学的实验数据提供的。数学结果告诉我们需要如何组合这些部分,以通过梯度下降实现生物学合理的在线网络学习,尤其是深度强化学习。这种称为e-prop的学习方法接近时间反向传播(BPTT)的性能,这是机器学习中训练循环神经网络的最著名方法。此外,它还提出了一种在用于人工智能的节能脉冲硬件中进行强大片上学习的方法。
大脑中的神经元网络与机器学习中的深度神经网络在至少两个基本方面有所不同:它们循环连接,形成大量循环,并且它们通过异步发放的定型电脉冲(称为脉冲)进行通信,而不是由深度前馈网络的每一层以同步方式产生的比特或数值。我们考虑了大脑中突触神经元可以说是最突出的模型:LIF神经元,其中通过突触连接从其他神经元到达的脉冲与相应的突触权重相乘,并通过泄漏膜电位进行线性积分。当膜电位达到发放阈值时,神经元发放——即发出脉冲信号。
但是,脉冲神经元(RSNN)的循环网络如何学习是一个悬而未决的问题,即如何通过突触可塑性的局部规则修改突触权重,从而提高网络的计算性能。在深度学习中,前馈网络通过梯度下降的损失函数E来解决这个问题,该函数测量当前网络性能的缺陷1。E的梯度通过前馈网络的所有层通过称为反向传播的过程向后传播到每个突触。循环连接网络可以更有效地计算,因为每个神经元可以多次参与网络计算,并且它们能够根据任务需求解决需要随着时间的推移集成信息或网络输出的非平凡定时的任务。因此,突触权重对损失函数的影响(见图1a)更加间接,通过梯度下降学习变得更加困难。如果神经元模型中存在缓慢变化的隐藏变量,例如具有脉冲频率自适应(SFA)的神经元,则该问题会更加严重。带有SFA的神经元在新皮质2中很常见,事实证明,将它们包含在RSNN中显著增加了网络的计算能力3。事实上,通过梯度下降训练的RSNN获得了与LSTM(长短期记忆)单元网络类似的计算能力,这是机器学习中循环神经网络的最新技术。由于与LSTM网络的这种功能关系,这些RSNN模型被称为LSNN3。
在机器学习中,通过将网络展开为虚拟前馈网络1来训练循环神经网络,参见图1b,并对其应用反向传播算法(图1c)。这种方法称为时间反向传播(BPTT),因为它需要梯度向后传播。
通过仔细选择伪导数来处理脉冲神经元的不连续动态,人们也可以将BPTT应用于RSNN,并且RSNN能够以这种方式学习以解决真正要求高的计算任务3,4。但困境在于,BPTT需要在网络计算期间存储所有神经元的中间状态,并在随后的离线过程中将这些状态与向后计算的梯度合并(见图1c)。这使得大脑不太可能使用BPTT。
之前缺乏强大的RSNN在线学习方法也影响了神经形态计算硬件的使用,该硬件旨在大幅降低AI实现的能耗。这种神经形态硬件的很大一部分,例如SpiNNaker6或英特尔的Loihi芯片7,都实现了RSNN。尽管学习算法在生物学上是否合理并不重要,但BPTT的过多存储和离线处理需求使该选项没有吸引力。因此,神经形态硬件中的RSNN也存在学习困境。
我们不知道以前关于RSNN的在线梯度下降学习方法的工作,无论是监督学习还是强化学习(RL)。然而,存在基于8的非脉冲神经网络的梯度下降在线近似的先前工作,我们在讨论部分进行了回顾。
来自神经科学的两个实验数据流提供了有关大脑中在线网络学习组织的线索:
首先,大脑中的神经元在分子水平上保持着先前活动的迹,例如,以钙离子或激活的CaMKII酶9的形式。特别是,它们保持对突触前神经元在突触后神经元之前发放的事件的淡化记忆,众所周知,如果随后是自上而下的学习信号,则会诱导突触可塑性10-12。这样的迹通常被称为资格迹。
其次,在大脑中,存在大量自上而下的信号,例如多巴胺、乙酰胆碱和与误差相关的负性相关的神经发放13,它们将行为结果告知当地的神经元群体。此外,已发现多巴胺信号14,15对不同的目标神经元群体具有特异性,而不是全局性的。我们在我们的学习模型中将这种自上而下的信号称为学习信号。
对循环神经网络中梯度下降学习的数学基础的重新分析告诉我们应该如何将局部资格迹和自上而下的学习信号最佳组合——而不需要随着时间的推移对信号进行反向传播。由此产生的学习方法e-prop如图1d所示。它的学习速度比BPTT慢,但往往接近BPTT的性能,从而为RSNN的学习困境提供了第一个解决方案。此外,e-prop也适用于具有更复杂神经元模型的RSNN,例如LSNN。这种新的学习范式阐明了大脑如何学会识别口语中的音素、解决时间分配问题以及仅从奖励中获得新行为。
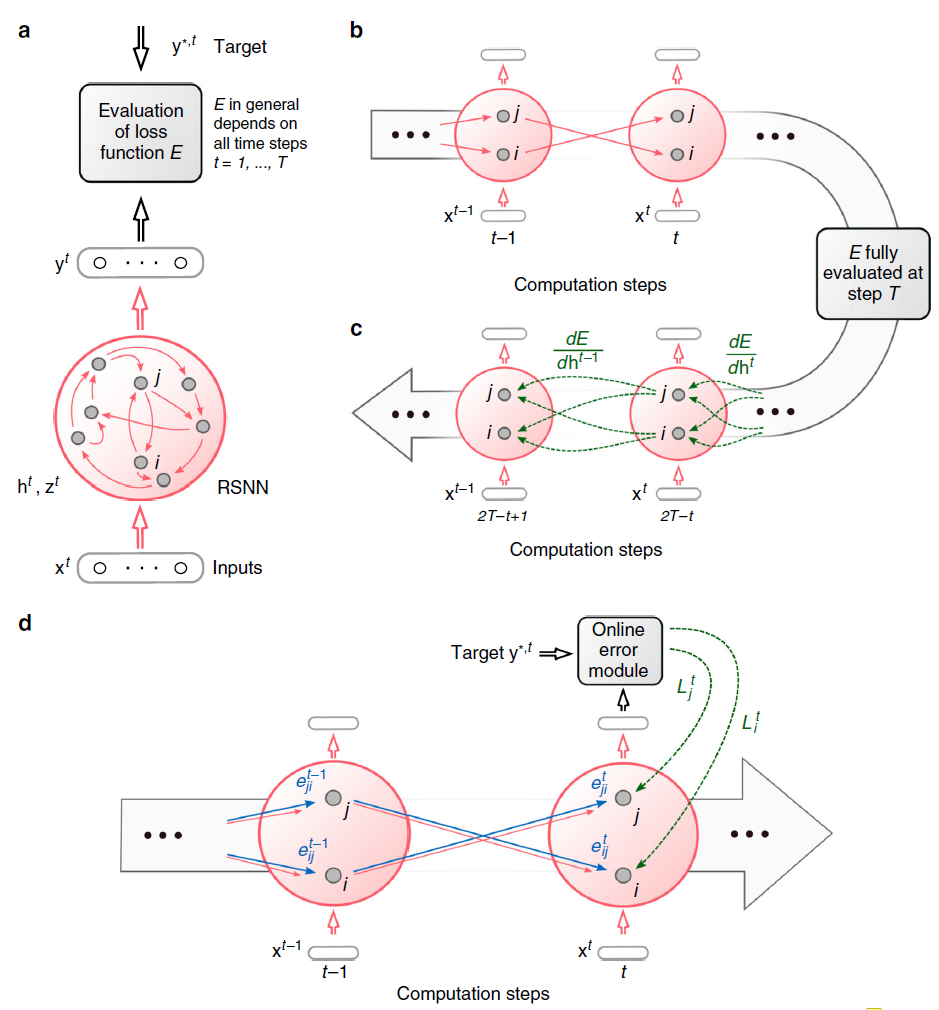
图1:BPTT和e-prop的方案。(a) 对于RSNN计算的每个时间步骤 t,具有网络输入 x,神经元脉冲 z,隐含神经元状态 h 和输出目标 y* 的RSNN。输出神经元 y 提供网络脉冲 z 的加权和的低通滤波器。(b) BPTT计算网络的展开版本中的梯度。对于每个时间步骤 t,它都有RSNN神经元的新拷贝。从RSNN的神经元 i 到神经元 j 的突触连接被一组前馈连接代替,每个时间步骤 t,将时间步骤 t 时层中神经元 i 的拷贝到时间步骤t + 1时层中神经元 j 的拷贝。此数组中的所有突触都具有相同的权重:RSNN中此突触连接的权重。(c) 在前馈计算经过层很长时间之后,BPTT的损失梯度会及时反向传播,并以离线方式跨突触逆行。(d) e-prop的在线学习动态。资格迹的前馈计算以蓝色表示。根据等式(1),这些与在线学习信号结合在一起。
Results
Mathematical basis for e-prop. 脉冲被建模为二值变量![]() ,如果神经元 j 在时间 t 发放,则假设值为1,否则值为0。在模型中让 t 在小的离散时间步长上变化是很常见的,例如,长度为1ms。网络学习的目标是找到使给定损失函数E最小化的突触权重W。E可能取决于网络中的所有或一部分脉冲。在回归或分类学习的情况下,E测量每个输出神经元 k 在时间 t 的实际输出
,如果神经元 j 在时间 t 发放,则假设值为1,否则值为0。在模型中让 t 在小的离散时间步长上变化是很常见的,例如,长度为1ms。网络学习的目标是找到使给定损失函数E最小化的突触权重W。E可能取决于网络中的所有或一部分脉冲。在回归或分类学习的情况下,E测量每个输出神经元 k 在时间 t 的实际输出![]() 与其给定目标值的偏差
与其给定目标值的偏差![]() (图1a)。在RL中,目标是优化智能体的行为以最大化获得的奖励。在这种情况下,E衡量当前智能体策略的缺陷以收集奖励。
(图1a)。在RL中,目标是优化智能体的行为以最大化获得的奖励。在这种情况下,E衡量当前智能体策略的缺陷以收集奖励。
从神经元 i 到神经元 j 的突触权重Wji的梯度dE/dWji告诉我们应该如何改变这个权重以减少E。原则上可以估计——尽管隐含离散变量![]() 是不可微分——借助合适的伪导数来处理参考文献3,4中的脉冲。关键创新是严格证明(参见"方法"),梯度dE/dWji可以表示为RSNN计算的时间步长 t 上的乘积之和,其中第二个因素只是不依赖于E的局部梯度:
是不可微分——借助合适的伪导数来处理参考文献3,4中的脉冲。关键创新是严格证明(参见"方法"),梯度dE/dWji可以表示为RSNN计算的时间步长 t 上的乘积之和,其中第二个因素只是不依赖于E的局部梯度:
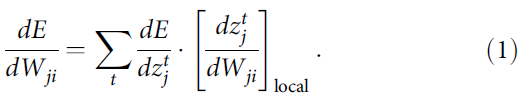
该局部梯度被定义为在时间 t 和之前的时间步长与神经元 j 的隐藏状态![]() 有关的偏导数的乘积之和,可以在RNN的前向计算期间通过简单的递归进行更新(公式14))。这个项
有关的偏导数的乘积之和,可以在RNN的前向计算期间通过简单的递归进行更新(公式14))。这个项![]() 不是近似值。相反,它收集了有关网络梯度dE/dWji的最大信息量,这些信息可以以前向方式在局部进行计算。因此,它是e-prop的关键因素。由于它对于简单的神经元模型(其内部状态完全由其膜电位捕获)减少到通常称为突触可塑性的资格迹的项的变体12,我们还指:
不是近似值。相反,它收集了有关网络梯度dE/dWji的最大信息量,这些信息可以以前向方式在局部进行计算。因此,它是e-prop的关键因素。由于它对于简单的神经元模型(其内部状态完全由其膜电位捕获)减少到通常称为突触可塑性的资格迹的项的变体12,我们还指:

作为资格迹。但是大多数生物神经元都有额外的隐藏变量,这些变量在较慢的时间尺度上变化,例如具有发放阈值自适应的神经元的发放阈值。此外,神经元中这些较慢的过程对于获得与LSTM网络类似的强大计算能力的脉冲神经元至关重要。因此,这种资格迹![]() 用于适应神经元的形式(参见公式(25))对于理解e-prop是必不可少的,并且它是导致RSNN计算能力质量飞跃的主要驱动力,这是可以通过生物学合理的学习实现的。公式(1)和(2)产生表示:
用于适应神经元的形式(参见公式(25))对于理解e-prop是必不可少的,并且它是导致RSNN计算能力质量飞跃的主要驱动力,这是可以通过生物学合理的学习实现的。公式(1)和(2)产生表示:

的损失梯度,我们将![]() 称为神经元 j 的学习信号。这个公式定义了一个清晰的程序,用于通过突触可塑性的局部规则来逼近网络损失梯度:在步骤 t 中改变每个权重Wji与
称为神经元 j 的学习信号。这个公式定义了一个清晰的程序,用于通过突触可塑性的局部规则来逼近网络损失梯度:在步骤 t 中改变每个权重Wji与![]() 成比例,或者将这些所谓的标签累积在一个隐藏变量中,该变量偶尔会转换为实际权重变化。因此,e-prop是一种严格意义上的在线学习方法(见图1d)。特别是,不需要像BPTT那样展开网络。
成比例,或者将这些所谓的标签累积在一个隐藏变量中,该变量偶尔会转换为实际权重变化。因此,e-prop是一种严格意义上的在线学习方法(见图1d)。特别是,不需要像BPTT那样展开网络。
由于学习信号![]() 的理想值
的理想值![]() 也捕获了神经元 j 的当前脉冲输出
也捕获了神经元 j 的当前脉冲输出![]() 可能通过其他神经元的未来脉冲对E的影响,因此其精确值通常在时间 t 不可用。我们将其替换为一个近似值,例如
可能通过其他神经元的未来脉冲对E的影响,因此其精确值通常在时间 t 不可用。我们将其替换为一个近似值,例如![]() ,它忽略了这些间接影响(这个偏导数
,它忽略了这些间接影响(这个偏导数![]() 用四舍五入的∂表示它仅捕获脉冲
用四舍五入的∂表示它仅捕获脉冲![]() 对损失函数E的直接影响)。这种近似只考虑了当前在RSNN的输出神经元 k 处产生的损失,并将它们与神经元特定的权重Bjk路由到网络神经元 j (见图2a):
对损失函数E的直接影响)。这种近似只考虑了当前在RSNN的输出神经元 k 处产生的损失,并将它们与神经元特定的权重Bjk路由到网络神经元 j (见图2a):
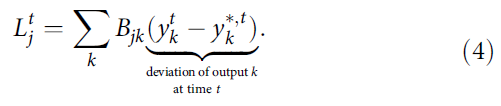
虽然这个近似的学习信号![]() 只捕获了在当前时间步长 t 出现的误差,但它在公式(3)中组合在一起,具有可以追溯到神经元 j 过去的资格迹
只捕获了在当前时间步长 t 出现的误差,但它在公式(3)中组合在一起,具有可以追溯到神经元 j 过去的资格迹![]() (见图3b),从而通过向后传播信号(如在BPTT中)减轻了解决时间信度分配问题的需要。
(见图3b),从而通过向后传播信号(如在BPTT中)减轻了解决时间信度分配问题的需要。
有几种策略可以为这个在线学习信号选择权重Bjk。在对称e-prop中,我们将其设置为等于![]() 要求的从神经元 j 到输出神经元 k 的突触连接的相应权重
要求的从神经元 j 到输出神经元 k 的突触连接的相应权重![]() 。请注意,这个学习信号实际上会在网络中没有循环连接的情况下准确地实现
。请注意,这个学习信号实际上会在网络中没有循环连接的情况下准确地实现![]() 。生物学上更合理的是避免权重共享的两种e-prop变体:在随机e-prop中,所有权重Bjk的值——即使对于没有突触连接到输出神经元 k 的神经元 j——都是随机选择的并保持固定,类似前馈网络的广播对齐16-18。在自适应e-prop中,除了使用随机反向权重之外,我们还让Bjk通过一个简单的局部可塑性规则进化,该规则反映了应用于
。生物学上更合理的是避免权重共享的两种e-prop变体:在随机e-prop中,所有权重Bjk的值——即使对于没有突触连接到输出神经元 k 的神经元 j——都是随机选择的并保持固定,类似前馈网络的广播对齐16-18。在自适应e-prop中,除了使用随机反向权重之外,我们还让Bjk通过一个简单的局部可塑性规则进化,该规则反映了应用于![]() 的可塑性规则,用于神经元 j 突触连接到输出神经元 k (见补充说明2)。
的可塑性规则,用于神经元 j 突触连接到输出神经元 k (见补充说明2)。
由此产生的突触可塑性规则(参见Methods)看起来类似于先前针对LIF神经元特殊情况提出的可塑性规则12,而没有缓慢改变隐藏变量。特别是,它们涉及突触后去极化作为因素之一,类似于参考文献19中基于数据的Clopath规则,分析见补充说明6。
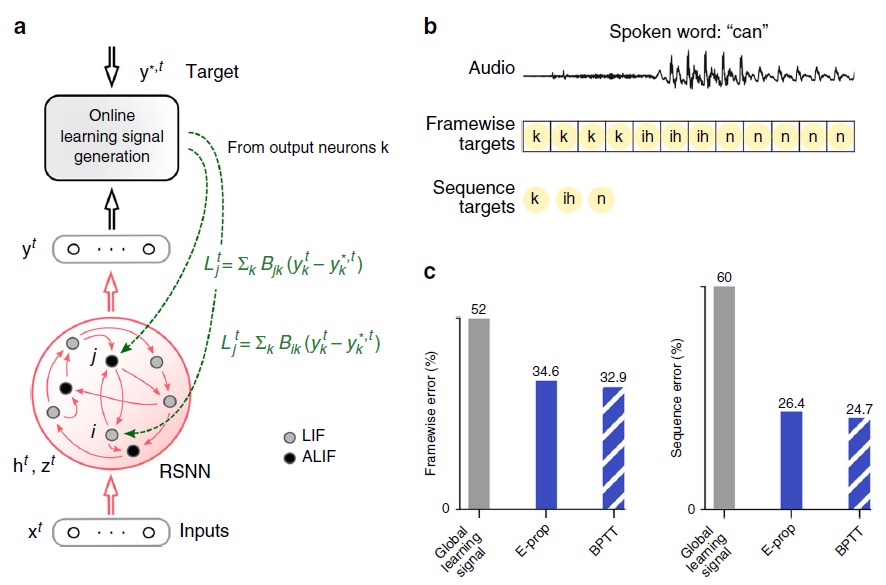
图2:BPTT和e-prop用于学习音素识别的比较。(a) e-prop的网络架构,针对由LIF和ALIF神经元组成的LSNN进行了说明。(b) TIMIT的两个版本的输入和目标输出。(c) LSNN中BPTT和对称e-prop的性能由用于框架目标的800个神经元和用于序列目标的2400个神经元组成(随机和自适应e-prop产生了相似的结果,请参见补充图2)。为了获得全局学习信号基准,将神经元特定的反馈替换为全局反馈。
Learning phoneme recognition with e-prop. 音素识别任务TIMIT20是不同类型的循环神经网络和不同学习方法的时间处理能力最常用的基准之一。它有两个版本。两者都使用来自美国八个方言地区的630名说话者所说的句子的声学语音信号作为输入(参见图2b顶部的示例片段)。在更简单的版本中,例如在参考文献21,目标是识别每10 ms时间范围内说出61个音素中的哪一个(逐帧分类)。在参考文献22的更复杂版本中,它在语音到文本转录中实现了人类水平表现的重要一步,目标是识别整个口语句子中的音素序列,独立于它们的时间(序列转录)。仅由LIF神经元组成的RSNN在使用BPTT3的TIMIT上甚至没有达到良好的性能。因此,我们在这里考虑LSNN,其中神经元的随机子集是具有发放率自适应的LIF模型的变体(自适应LIF (ALIF)神经元),请参阅Methods。命名为LSNN是因为RSNN模型的这种特殊情况可以通过BPTT的训练实现与LSTM网络类似的性能3。
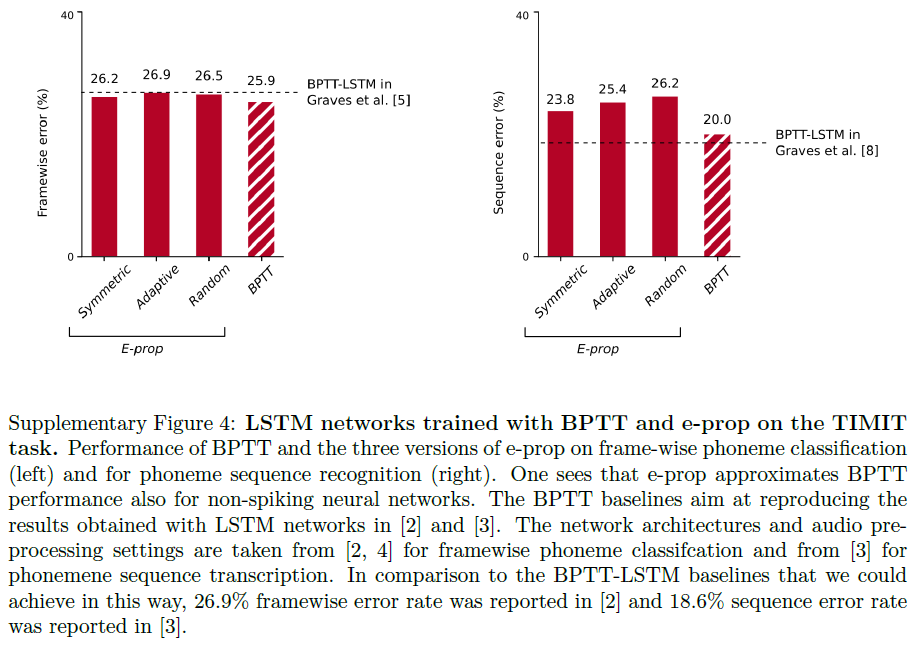
对于两个版本的TIMIT,e-prop都非常接近LSNN上BPTT的性能,如图2c所示。此外,LSNN可以在没有任何神经元发放率超过12 Hz (脉冲计数超过32个口语句子)的情况下解决逐帧分类任务,这表明它们以节能的脉冲编码(而不是发放率编码)方式运行。对于更难的TIMIT版本,我们按照参考文献22进行训练,一个复杂的LSNN,由三个循环网络的前馈序列组成。我们的结果表明,e-prop也可以很好地处理这种更复杂的网络结构的学习。在补充图4中,我们还展示了e-prop和BPTT在LSTM网络上在相同任务上的性能。这些数据表明,对于两个版本的TIMIT,用于LSNN的e-prop的性能与用于LSTM网络的BPTT的性能相当接近。此外,他们表明e-prop还为LSTM网络提供了一种功能强大的在线学习方法。
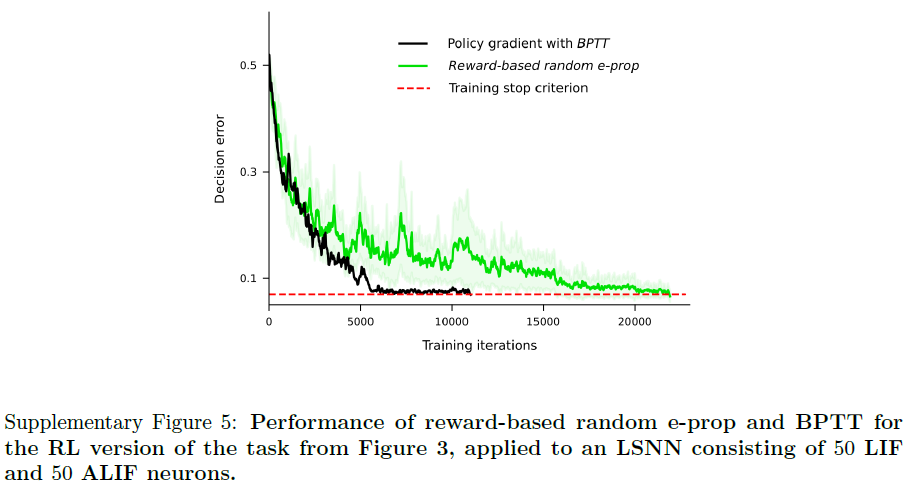
Solving difficult temporal credit assignment. 大脑中认知计算的一个标志是能够超越纯粹的反应模式:随着时间的推移整合不同的感官线索,并等到合适的时机到来才采取动作。神经科学中的大量实验在学习此类任务后分析神经编码(参见例如参考文献14,23)。但是,如何在大脑的RSNN中模拟这种认知计算的学习仍然是未知的。为了测试e-prop是否可以解决这个问题,我们考虑了在参考文献23,14的实验中研究的相同任务。一只啮齿动物在虚拟环境中沿着线性轨道移动,在那里它遇到了左右几个视觉线索,见图3a和补充电影1。后来,当它到达T形路口时,它不得不决定是左转还是右转。当它转向它之前接收到大部分视觉线索的那一侧时,它就会得到奖励。这项任务并不容易学习,因为受试者需要找出最后一个提示在哪一侧或提示以何种顺序呈现都无关紧要。相反,受试者必须学会分别计算每一侧的线索并比较两个结果数字。此外,在给予奖励之前很久就需要正确处理提示。我们在补充图5中表明,LSNN可以通过e-prop以完全相同的方式仅从奖励中学习此任务。但由于e-prop如何解决潜在的时间信度分配问题的方式对于这项任务的监督学习版本更容易解释,我们在这里讨论这样一种情况,即教师在每次试验结束时告诉受试者什么会是正确的决定。这对于任何在线学习方法来说仍然是一个具有挑战性的场景,因为非零学习信号![]() 仅在试验的最后150毫秒期间出现(图3b)。因此,所有突触可塑性都必须在最后150毫秒内发生,也就是在处理输入线索之后很久。尽管如此,e-prop能够解决这个学习问题,参见图3c和补充电影2。它只需要多一点时间就能通过BPTT达到与离线学习相同的性能水平(参见补充电影3)。尽管该任务甚至无法通过具有没有自适应神经元的常规RSNN的BPTT解决(图3c中的红色曲线),但如果RSNN包含自适应神经元,则前面讨论的所有三个e-prop变体都可以解决它。我们在补充说明2中解释了如何通过由兴奋性和抑制性神经元组成的稀疏连接的LSNN来解决此任务:通过将随机重连接24集成到e-prop中。
仅在试验的最后150毫秒期间出现(图3b)。因此,所有突触可塑性都必须在最后150毫秒内发生,也就是在处理输入线索之后很久。尽管如此,e-prop能够解决这个学习问题,参见图3c和补充电影2。它只需要多一点时间就能通过BPTT达到与离线学习相同的性能水平(参见补充电影3)。尽管该任务甚至无法通过具有没有自适应神经元的常规RSNN的BPTT解决(图3c中的红色曲线),但如果RSNN包含自适应神经元,则前面讨论的所有三个e-prop变体都可以解决它。我们在补充说明2中解释了如何通过由兴奋性和抑制性神经元组成的稀疏连接的LSNN来解决此任务:通过将随机重连接24集成到e-prop中。
但是,如果在2250 ms长试验的最后150 ms之前,所有学习信号都相同为0,那么LSNN中的神经元如何学习记录和计数输入线索(参见图3b的第二行到最后一行)?
为了回答这个问题,我们应该注意到,时间 t 时神经元 j 的发放可以通过两种不同的方式影响随后时间点t'>t时的损失函数E:通过路径 (i) 它影响神经元 j 的慢隐藏变量的未来值(例如,其发放阈值),这可能会影响t'时神经元 j 的发放,这反过来又可能直接影响时间t'的损失函数。通过途径 (ii),它影响t'时其他神经元j'的发放,直接影响t'时的损失函数。
在对称和自适应e-prop中,使用偏导数![]() 作为e-prop的学习信号
作为e-prop的学习信号![]() ,而不是总导数
,而不是总导数![]() ,这在网上不可用。这将阻止沿路线 (ii) 的梯度信息流。但资格迹使路线 (i) 上的流程保持畅通。因此,即使是对称和自适应的e-prop也可以通过在线学习解决图3的时间信度分配问题:沿着路径 (i) 流动的梯度信息使神经元能够学习如何在前1050 ms的时间点 t 处理感觉线索,尽管这只会在损失变为非零时的时间点t'>2100 ms时影响损失。
,这在网上不可用。这将阻止沿路线 (ii) 的梯度信息流。但资格迹使路线 (i) 上的流程保持畅通。因此,即使是对称和自适应的e-prop也可以通过在线学习解决图3的时间信度分配问题:沿着路径 (i) 流动的梯度信息使神经元能够学习如何在前1050 ms的时间点 t 处理感觉线索,尽管这只会在损失变为非零时的时间点t'>2100 ms时影响损失。
这在图3b的最后第3行中展示:慢分量![]() ;适应神经元 j 的eji随典型的长时间常数(发放率适应)衰减(见公式(24)和补充电影2)。当这些迹从试验开始延伸到其最后阶段时,它们能够学习在任何学习信号变为非零之前超过1050 ms到达的左和右输入线索的差异响应,如图3b的第2到最后一行所示。因此,资格迹为梯度信息的传播提供了所谓的通向未来的高速公路。这些可以被看作是BPTT在向后通行过程中使用的高速公路的生物学合理替代品(见补充电影3)。
;适应神经元 j 的eji随典型的长时间常数(发放率适应)衰减(见公式(24)和补充电影2)。当这些迹从试验开始延伸到其最后阶段时,它们能够学习在任何学习信号变为非零之前超过1050 ms到达的左和右输入线索的差异响应,如图3b的第2到最后一行所示。因此,资格迹为梯度信息的传播提供了所谓的通向未来的高速公路。这些可以被看作是BPTT在向后通行过程中使用的高速公路的生物学合理替代品(见补充电影3)。
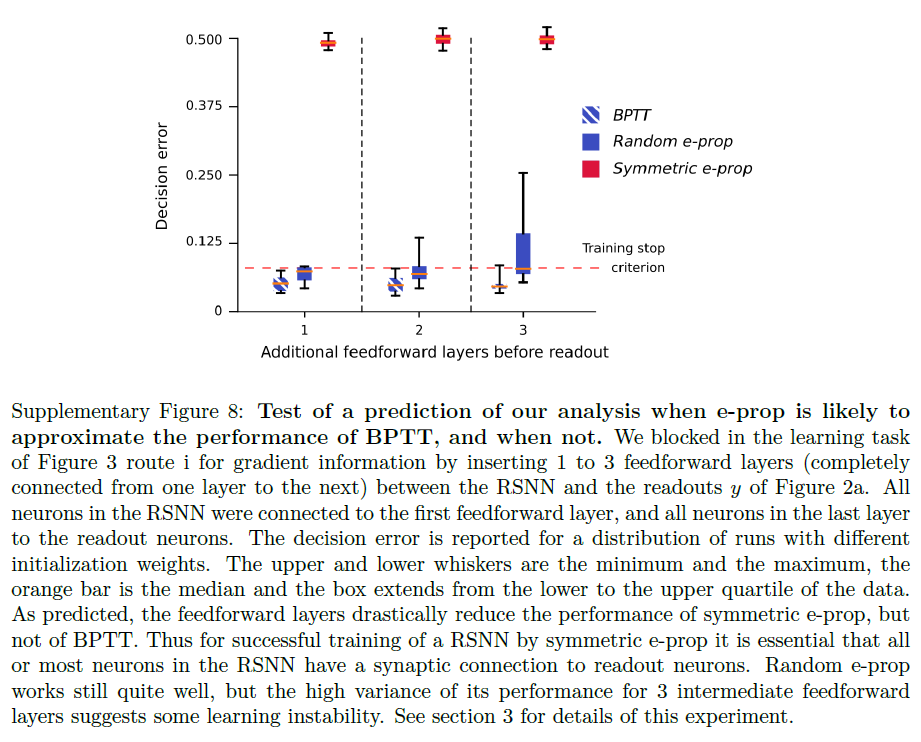
该分析还告诉我们,当对称e-prop很可能无法接近BPTT的性能时:如果沿路线 (i) 的梯度前向传播无法到达损失函数值变得显著的后期时间点t'。在图3的实验中,可以通过添加到具有图2a所示的标准架构的LSNN来人工诱导这一点,该LSNN具有前馈SNN的隐藏层,LSNN和读出神经元之间的通信必须通过该层流动。这些隐藏层的神经元j'阻断通路 (i) ,而使通路 (ii) 开放。因此,图3的任务仍然可以通过BPTT通过这种修改后的网络架构学习,但不能通过对称e-prop学习,参见补充图8。
识别随机e-prop的性能远远落后于BPTT的任务更为困难,因为误差信号也会发送到与读出神经元没有直接联系的神经元。对于深度前馈网络,参考文献25中显示了广播对齐,如参考文献17,18中所定义,对于困难的图像分类任务,无法达到Backprop的性能。因此,我们预计,在困难的分类任务中,随机e-prop将表现出与深度前馈SNN类似的缺陷。我们不知道人工RNN广播对齐失败的相应演示,尽管它们可能存在。一旦找到它们,它们可能会指向随机e-prop对RSNN失败的任务。目前,我们还不知道有任何此类事件。
图3d提供了对随机e-prop中随机抽取的广播权重的功能作用的洞察:这些权重的差异决定了每个神经元 j 在试验的第一阶段是否学习对来自左侧或右侧的线索作出更多反应。这一观察结果表明,RSNN的神经元特异性学习信号的优势在于,它们可以为任务相关的网络输入创建多种特征检测器。因此,这些特征检测器的适当加权和稍后能够消除网络输出处的剩余误差,类似于前馈网络的情况16。
我们想指出,在基于奖励的e-prop中使用熟悉的actor-critic方法(我们将在下一节讨论)提供了一个额外的渠道,通过该渠道,关于未来损失的信息可以判断e-prop学习者在当前时间步 t 的突触可塑性:通过估计V(t)当前状态的值,该值通过内部生成的奖励预测误差同时学习。
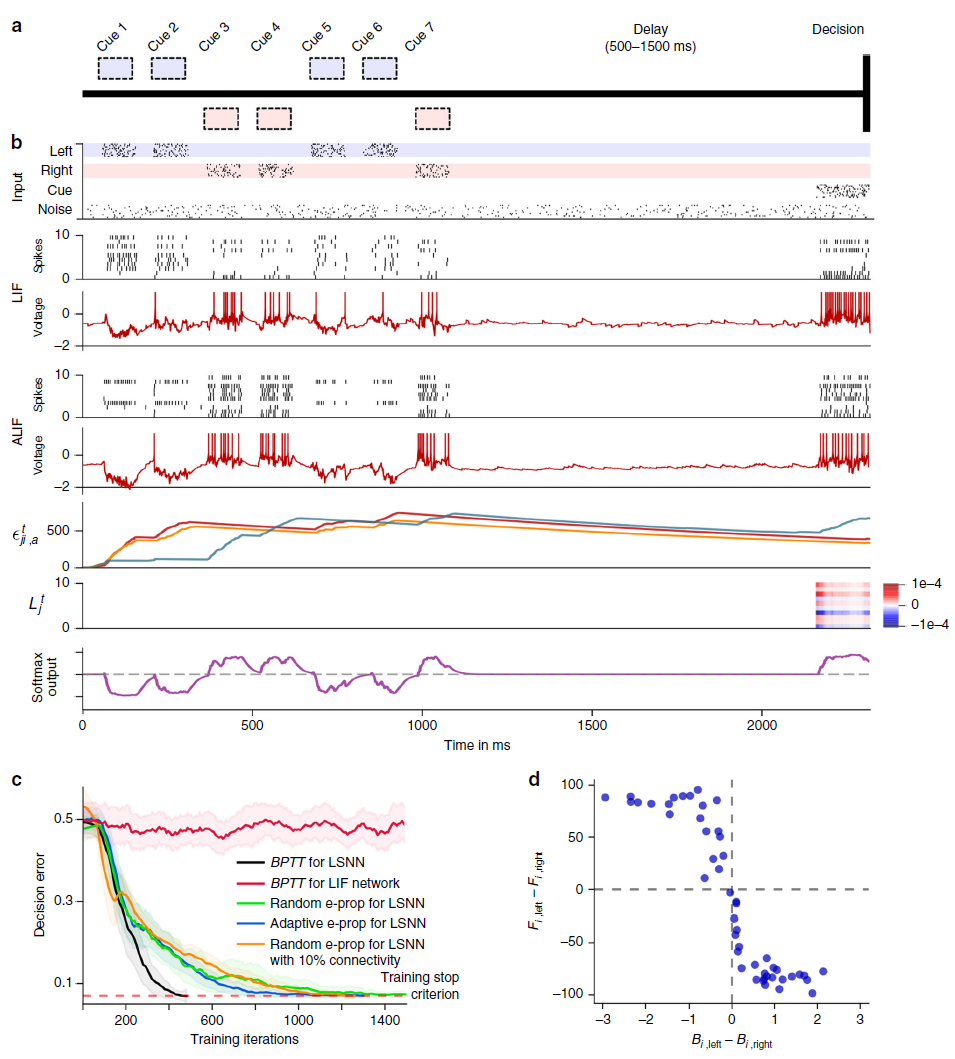
图3:解决具有困难的时序信度分配的任务。(a) 参考文献23,14的相应啮齿动物实验的设置,参见补充影片1。(b) 输入脉冲,50个LIF样本神经元中10个和50个ALIF样本神经元中10个的脉冲活动,两个样本神经元 j 的膜电位(更准确地:![]() ),三个资格迹的慢分量的样本,10个神经元的样本学习信号和softmax网络输出。(c) BPTT和两个e-prop版本应用于LSNN的学习曲线,BPTT应用于RSNN,而无需调整神经元(红色曲线)。橙色曲线显示了稀疏连接的LSNN(由兴奋性神经元和抑制性神经元组成)对e-prop的学习性能(遵守了戴尔定律)。阴影区域是通过20次运行计算得出的平均精度的95%置信区间。(d) 随机e-prop中学习信号的k = left/right时,随机抽取的广播权重Bjk与学习后对左右输入分量的灵敏度之间的相关性。fj,left(fj,right)是学习后左(右)线索的呈现过程中神经元 j 的平均发放率。
),三个资格迹的慢分量的样本,10个神经元的样本学习信号和softmax网络输出。(c) BPTT和两个e-prop版本应用于LSNN的学习曲线,BPTT应用于RSNN,而无需调整神经元(红色曲线)。橙色曲线显示了稀疏连接的LSNN(由兴奋性神经元和抑制性神经元组成)对e-prop的学习性能(遵守了戴尔定律)。阴影区域是通过20次运行计算得出的平均精度的95%置信区间。(d) 随机e-prop中学习信号的k = left/right时,随机抽取的广播权重Bjk与学习后对左右输入分量的灵敏度之间的相关性。fj,left(fj,right)是学习后左(右)线索的呈现过程中神经元 j 的平均发放率。
Reward-based e-prop. 通过巧妙地将BPTT应用到RL26,深度RL显著提升了机器学习和AI的最新技术水平。我们发现,在深度RL方法范围内可以说是最强大的RL方法之一,在生物学上并非直接不可信,策略梯度与actor-critic相结合,可以通过e-prop实现。这产生了生物学合理且硬件友好的深度强化学习算法基于奖励的e-prop。LSNN在此学习了价值函数的近似值(critic)和随机策略(actor)。特定于神经元的学习信号在基于奖励的e-prop中与传递奖励预测误差的全局信号相结合(图4b)。与监督情况相反,学习信号![]() 取决于与外部目标信号的偏差,学习信号在这里传达随机选择的动作如何偏离网络当前提出的动作均值。
取决于与外部目标信号的偏差,学习信号在这里传达随机选择的动作如何偏离网络当前提出的动作均值。
在此类RL任务中,学习者需要探索其环境,并找出在何种状态下哪些动作会得到奖励27。没有老师会告诉学习者什么动作是最佳的;事实上,学习者可能永远不会发现这一点。尽管如此,BPTT等学习方法对于强大的RL形式(通常称为Deep RL26)至关重要。在那里,人们使用内部生成的教学信号训练循环人工神经网络。我们在这里展示了深度RL原则上也可以由大脑的神经网络执行,因为e-prop在这个RL上下文中也接近于BPTT的性能。然而,需要另一种新成分来证明这一点。之前在深度RL上解决复杂任务(例如赢得Atari游戏)的工作需要额外的机制来避免使用非线性函数逼近器引起的众所周知的不稳定性,例如并行使用多个交互学习器。由于这种并行学习方案在生物学上似乎不合理,因此我们在此介绍了一种避免学习不稳定性的新方法:我们表明,学习阶段长度和学习率的合适时间表也可以缓解深度强化学习中的学习不稳定性。
我们为深度强化学习提出了一个在线突触可塑性规则(5),它类似于等式(3),不同之处在于这里对![]() 项应用了衰减记忆滤波器Fγ,其中γ是给定的未来奖励折扣因子和
项应用了衰减记忆滤波器Fγ,其中γ是给定的未来奖励折扣因子和![]() 表示资格迹
表示资格迹![]() 的低通滤波副本(参见Methods)。这一项在突触可塑性规则中与奖励预测误差δt = rt + γVt+1 − Vt相乘,其中rt是在时间 t 收到的奖励。这会产生以下形式的瞬时权重变化:
的低通滤波副本(参见Methods)。这一项在突触可塑性规则中与奖励预测误差δt = rt + γVt+1 − Vt相乘,其中rt是在时间 t 收到的奖励。这会产生以下形式的瞬时权重变化:
![]()
以前的RL三因素学习规则通常采用![]() 12,28的形式。因此,他们仅通过将网络神经元的输出与奖励预测误差相关联来估计策略的梯度。由于所得梯度估计中的高噪声,这种方法的学习能力非常有限。相比之下,在基于奖励的e-prop的可塑性规则(5)中,资格迹首先与特定于神经元的反馈
12,28的形式。因此,他们仅通过将网络神经元的输出与奖励预测误差相关联来估计策略的梯度。由于所得梯度估计中的高噪声,这种方法的学习能力非常有限。相比之下,在基于奖励的e-prop的可塑性规则(5)中,资格迹首先与特定于神经元的反馈![]() 相结合,然后再与奖励预测误差δt相乘。我们在Methods中分析表明,这产生了与使用BPTT的深度强化学习相似的策略和价值梯度的估计。此外,与之前提出的三因素学习规则相比,此规则(5)也适用于LSNN。
相结合,然后再与奖励预测误差δt相乘。我们在Methods中分析表明,这产生了与使用BPTT的深度强化学习相似的策略和价值梯度的估计。此外,与之前提出的三因素学习规则相比,此规则(5)也适用于LSNN。
我们在经典基准任务26上测试了基于奖励的e-prop,以从奖励中学习智能行为:赢得由Arcade学习环境提供的Atari视频游戏29。为了赢得这样的游戏,智能体需要学习从游戏屏幕的像素中提取显著信息,并推断特定动作的价值,即使在遥远的未来获得奖励。事实上,即使在机器学习中,学习赢得Atari游戏对RL来说也是一个严峻的挑战。此外,人工神经网络和BPTT,以前的解决方案还需要经验回放(对许多帧和更早发生的动作序列的完美记忆)或共享突触权重更新的众多并行智能体的异步训练。我们在这里展示了LSNN也可以通过e-prop学习,通过单个智能体的在线学习来赢得Atari游戏。如果智能体使用增加回合长度的时间表——学习率与该长度成反比,那么这在单个智能体和没有回合回放的情况下成为可能。使用此方案,智能体可以在学习的第一阶段体验多样化且不相关的短回合,从而产生有用的技能。随后,智能体可以使用更长的回合微调其策略。
首先,我们考虑了著名的Atari游戏Pong(图4a)。在这里,智能体必须学会使用球拍的上下运动以巧妙的方式击球。如果对手无法接住球,则获得奖励。我们为此任务使用基于奖励的e-prop训练了一个智能体,并在图4c和补充视频4中展示了一个样本试验。与常见的深度强化学习解决方案相比,智能体在这里以严格的在线方式学习,随时只接收游戏屏幕的当前帧。在图4d中,我们证明了这种生物学上现实的学习方法也能获得有竞争力的分数。
如果不坚持在线设置,智能体只接收视频屏幕的当前帧,而是最后四帧,那么大约一半的Atari游戏的获胜策略已经可以通过前馈神经网络学习(参见参考文献26的补充表3)。然而,对于其他Atari游戏,例如Fishing Derby(图5a),它甚至在参考文献26中显示,应用于LSTM网络的深度RL比任何用于前馈网络的深度RL方法获得了高得多的分数,这在那里被考虑。因此,为了测试基于在线奖励的e-prop对那些需要增强时间处理的Atari游戏的威力,我们在Fishing Derby游戏中对其进行了测试。在这个游戏中,智能体必须尽可能多地钓到鱼,同时避免鲨鱼用身体的任何部位接触到鱼,而对手先钓到鱼。我们在图5c中显示,应用于LSNN的基于在线奖励的e-prop实际上确实达到了与应用于LSTM网络的参考离线算法相同的性能。我们在图5d中展示了学习后的随机试验,我们可以识别两种不同的学习行为:第一,通过躲避鲨鱼,第二个通过收集鱼。智能体已经学会了根据情况的需要在这两种行为之间切换。
总的来说,我们推测基于奖励的e-prop的变体将能够解决大多数深度RL任务,而这些任务可以通过机器学习中的在线actor-critic方法来解决。

图4:e-prop在Atari游戏Pong中的应用。(a) 在此,玩家(绿色球拍)必须胜过对手(浅棕色)。当对手无法反弹球时获得奖励(一个小白方块)。为了达到这个目的,智能体必须学会用球拍的边缘击球,这会导致难以预测的轨迹。(b) 该智能体是通过LSNN实现的。提供游戏当前视频帧的像素作为输入。在由LSNN处理视频帧流的过程中,随机策略以在线方式生成操作。同时,可以预测未来奖励。当前的预测误差将反馈到LSNN和对帧进行预处理的脉冲CNN。(c) 使用基于奖励的e-prop学习后,对LSNN进行样本试验。从上到下:随机动作的概率,未来奖励的预测,随机突触的学习动态(任意单位),240个样本LIF神经元中10个和160个样本ALIF神经元中10个的脉冲活动以及位于上方脉冲栅格底部的两个样本神经元的膜电位。(d) 受基于奖励的e-prop训练的LSNN的学习进度,报告为一个回合中收集的奖励总和。学习曲线在五个不同的运行中取均值,阴影区域代表标准差。有关我们的结果与A3C之间比较的更多信息,请参见补充说明5。
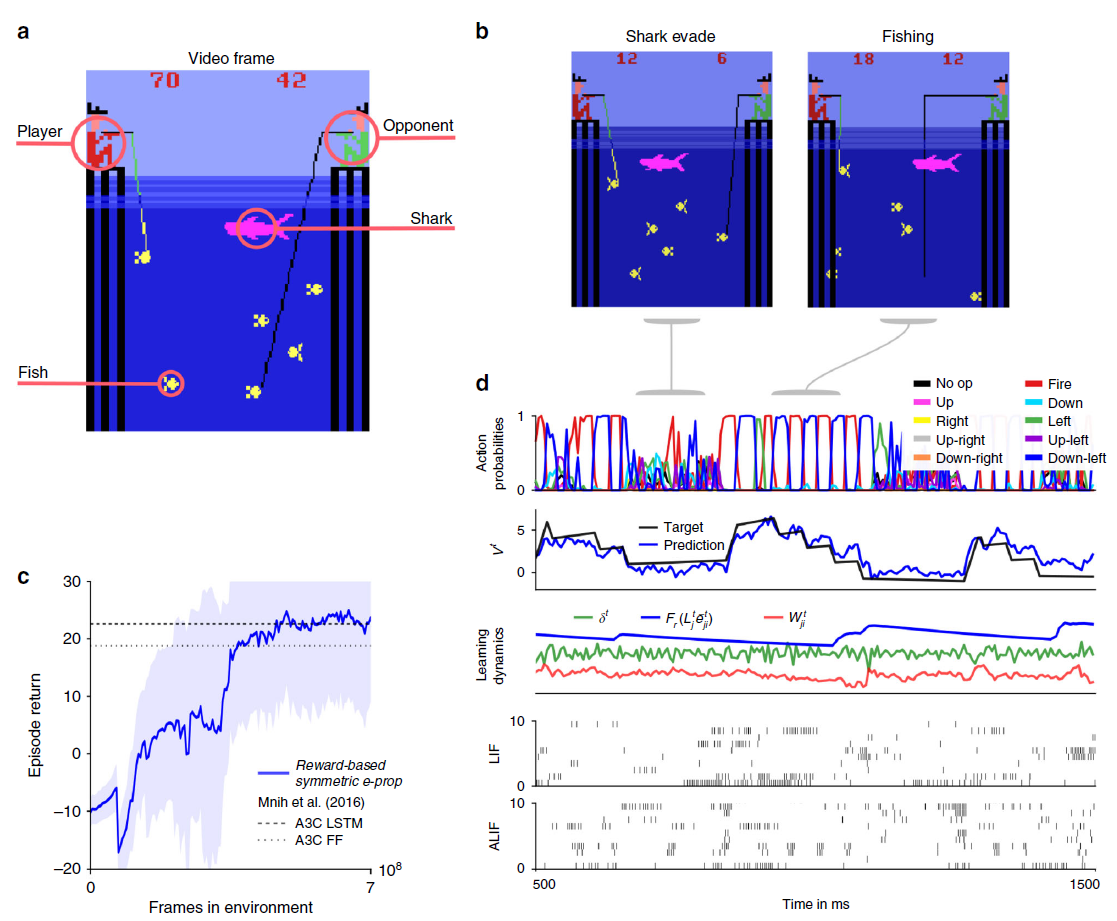
图5:学习赢得Atari游戏Fishing Derby的e-prop应用。(a) 在此,玩家必须与对手竞争,并尝试从海中捕捞更多的鱼。(b) 一旦鱼被咬了,智能体必须避免鲨鱼碰到鱼。(c) 训练好的网络的样本试验。从上到下:随机动作的概率,未来奖励的预测,随机突触的学习动态(任意单位),180个样本LIF神经元中20个和120个样本ALIF神经元中20个的脉冲活动。(d) 如图4d所示,使用基于奖励的e-prop训练的LSNN的学习曲线。
Discussion
我们提出,为了了解大脑中神经网络的计算功能和神经编码,需要了解建立和维护这些可塑性机制的组织。到目前为止,BPTT是唯一的候选者,因为没有其他学习方法可以为RSNN模型提供足够强大的计算功能。但由于BPTT不被视为具有生物学现实意义5,因此它无助于我们理解大脑中的学习。e-prop为这一困境提供了解决方案,因为它不需要生物学上不切实际的机制,但仍然使RSNN能够学习困难的计算任务,实际上几乎和BPTT一样。此外,它使RSNN能够在节能的稀疏发放机制中解决这些任务,而不是诉诸发放率编码。
e-prop依赖于大脑中大量可用的两种类型的信号,但它们在学习中的确切作用尚未被理解:资格迹和学习信号。由于e-prop基于透明的数学原理(参见公式(3)),它为两种类型的信号以及突触可塑性规则提供了一个规范模型。有趣的是,由此产生的学习模型表明,许多生物神经元的一个特征方面——缓慢变化的隐藏变量的存在——为RSNN如何在没有及时反向传播的误差信号的情况下学习的问题提供了可能的解决方案:缓慢变化的神经元隐藏变量导致资格迹在更长的时间跨度内前向传播,因此能够与后来出现的瞬时误差信号相吻合(见图3b)。
e-prop理论做出了一个具体的可实验检验的预测:突触资格迹的时间常数与突触后神经元发放活动的历史依赖性的时间常数相关。它还表明,实验发现的不同大脑区域中神经元群体的发放活动的不同时间常数与它们处理学习时间信度分配中相应延迟范围的能力相关。
最后,e-prop理论为实验发现的多巴胺信号多样性对不同神经元群体的功能作用提供了假设14。以前的基于奖励的学习理论要求将相同的学习信号发送到所有神经元,基本公式(1)对于e-prop假设,理想的自上而下的神经元群学习信号取决于其对网络性能(损失函数)的影响,因此应该是特定于目标的(参见图2c和补充说明6)。事实上,参考文献31中e-prop的学会学习结果表明,关于大脑区域可能的学习任务范围的先验知识可以在进化时间尺度上进一步优化自上而下的学习信号,从而能够从少数甚至单一的试验中学习。
以前训练RSNN的方法并非旨在近似BPTT。相反,他们中的一些人依靠控制理论来训练一个混乱的脉冲神经元库32-34。其他人使用FORCE算法35,36或它的变体35,37–39。然而,FORCE算法并没有被认为是生物学上现实的,因为每个突触权重的可塑性规则需要了解所有其他突触权重的当前值。参考文献35中考虑的通用任务是在监督下学习如何生成模式。我们在补充图1和图7可以看出,RSNN也可以使用生物学合理的学习方法e-prop来学习此类任务。
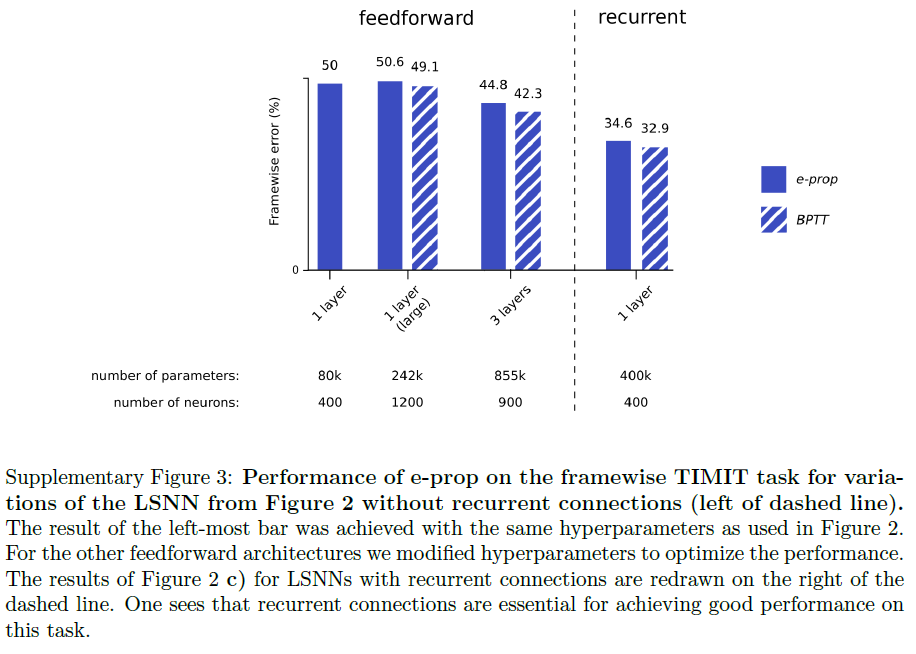
已经提出了几种在脉冲神经元的前馈网络中近似随机梯度下降的方法,参见例如参考文献40-44。正如之前在参考文献45,46中提出的那样,这些使用像e-prop一样的伪梯度来克服脉冲神经元的不可微性。参考文献40,42,43得出了前馈网络的突触可塑性规则,参考文献得出了前馈网络的突触可塑性规则,该规则由学习信号和描述神经元 j 的脉冲对传入突触的权重Wji的依赖性的导数(资格迹)的乘积组成(如e-prop)。但是在循环网络中,j 的脉冲输出也间接依赖于Wji,通过网络中的循环允许神经元 j 的脉冲有助于其他神经元的发放,进而影响突触前神经元 i 的发放。因此,如果将这些用于前馈网络的方法转移到循环连接的网络,则无法再在局部计算相应的资格迹。因此,参考40建议需要研究他们对RSNN方法的扩展。
以前关于非脉冲RNN的在线梯度下降学习算法设计的工作是基于实时循环学习(RTRL)8。RTRL本身很少被使用,因为它每个时间步骤的计算复杂度是O(n4),如果 n 是神经元的数量。但随后提出了RTRL的有趣近似(参见参考文献47作为综述):一些随机近似48,它们是O(n3)或仅适用于小型网络49,以及最近的两个确定性O(n2)近似50,51。后者实际上是与e-prop的第一次出版31同时编写的。本文与50之间的结构差异在于,他们的方法要求学习信号在RNN中的神经元之间传输,具有单独学习的权重。51为基于发放率的神经元推导出类似于随机e-prop的学习规则。但是这项工作没有解决除监督回归之外的其他学习形式,例如强化学习,也没有在脉冲神经网络中学习,或者在具有慢速隐藏变量的更强大类型的RNN中学习,例如LSTM网络或LSNN。
e-prop也有复杂度O(n2),实际上是O(S)(如果 S 是突触连接的数量)。这个界限是最优的——除了常数因子——因为这是仅仅模拟RNN的渐近复杂度。e-prop的关键点是其资格迹的一般形式(13)收集了对损失梯度的所有贡献,这些贡献可以以前馈方式在局部计算。这种通用形式可以应用到具有缓慢变化的隐藏变量的脉冲神经元,例如具有发放率适应的神经元,这是RSNN达到LSTM网络计算能力的基本要素3。我们认为,这种方法可以在将来的工作中被拓展,适用于伪衍生物的各种生物学更现实的神经元模型。它还可以将这些严格派生的资格迹与来自RL的基于奖励的e-prop(公式(5))的资格迹(语义相同但算法上非常不同)相结合,从而将深度RL的力量带到RSNN。结果,我们能够在图2中显示。如图2-5所示,RSNN可以学习从e-prop理论产生的突触可塑性生物学合理的规则,以解决诸如音素识别、随着时间的推移整合证据并等待合适的时机采取动作以及赢得Atari游戏等任务。这些是现代基于学习的人工智能的基础任务,但迄今为止还没有用RSNN解决。因此,e-prop为如何通过大脑的神经网络学习和控制智能行为这一主要悬而未决的问题提供了一个新的视角。
除了e-prop对神经科学和认知科学研究的明显影响之外,e-prop还为机器学习方法提供了一个有趣的新工具,其中BPTT被近似值取代,以提高计算效率。我们已经在补充图4中表明,e-prop为LSTM网络提供了一种强大的在线学习方法。此外,来自e-prop的资格迹与来自参考52的合成梯度的组合甚至提高了LSTM网络在复杂的机器学习问题上的性能,例如复制重复任务和Penn Treebank单词预测任务31。eprop的其他未来扩展可以探索与基于注意力的模型的组合,以涵盖多个时间尺度。
最后,e-prop提出了一种有前途的新方法,用于在神经形态芯片上实现强大的RSNN片上学习。然而,BPTT不在当前的神经形态硬件的范围内,e-prop的实现似乎没有提供严重的障碍。我们的结果表明,e-prop的实现将在神经形态硬件的片上学习能力方面提供质的飞跃。
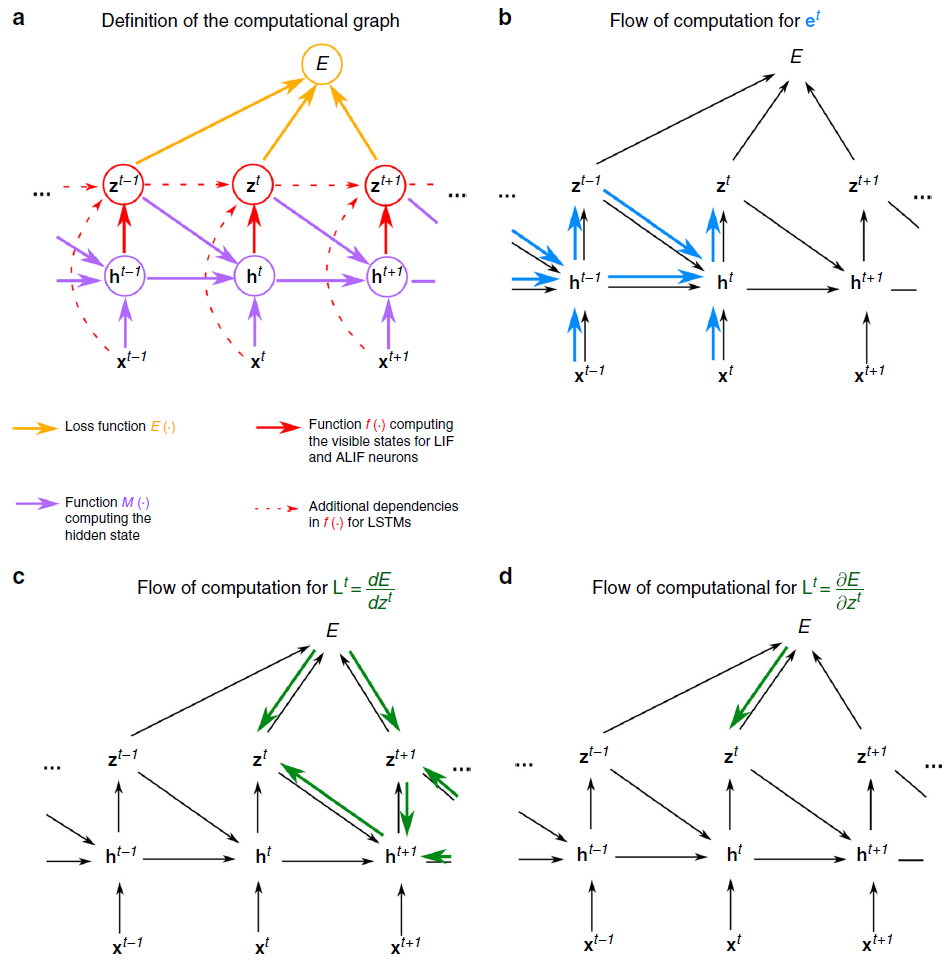
图6:计算图和梯度传播。(a) 假设隐含神经元状态,神经元输出,网络输入以及通过数学函数的损失函数E之间的数学依赖性由彩色箭头表示。(b–d) 合并到等式3的损失梯度中的两个分量et和Lt的计算流程可以用类似的图形表示。(b) 遵循等式14,资格迹的计算流正在及时前进。(c) 相反,理想学习信号L要求在时间上反向传播梯度。(d) 因此,尽管资格迹是精确计算的,但在e-prop应用程序中L是近似的,以产生在线学习算法。
Methods
Network models. 为了展示e-prop方法的通用性,我们使用适用于许多循环神经网络模型(不仅适用于RSNN和LSNN)的一般形式来定义循环神经网络的动力学。LSTM网络等非脉冲模型也适合这种形式主义(见补充说明4)。网络动态由图6中的计算图总结。将可观察状态(例如脉冲)表示为zt,将隐含状态表示为ht,将输入表示为xt,并使用Wj收集到达神经元 j 的突触的所有权重,函数M定义了神经元 j 的隐含状态的更新:![]() 和函数 f 定义了神经元 j 的可观察状态的更新:
和函数 f 定义了神经元 j 的可观察状态的更新:![]() (对于LIF和ALIF神经元,f 简化为
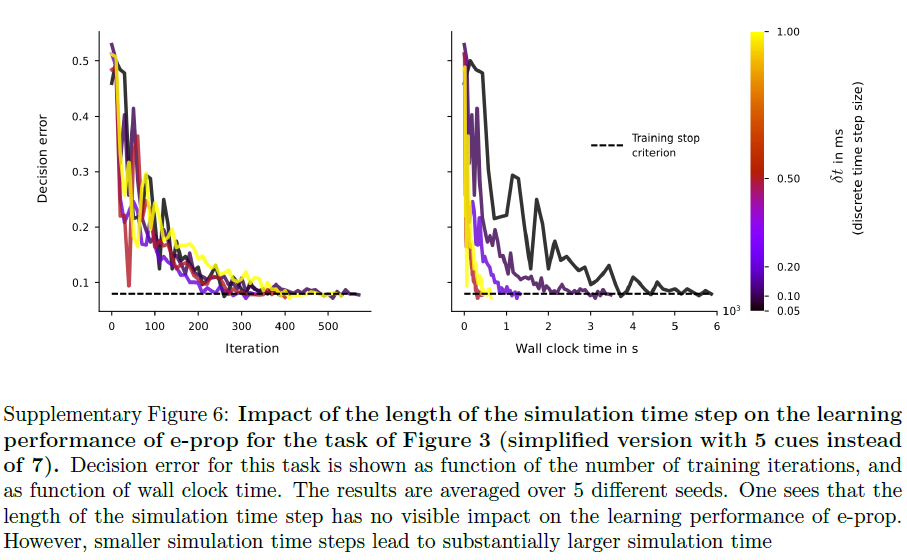
(对于LIF和ALIF神经元,f 简化为![]() )。我们为所有模拟选择了δt = 1ms的离散时间步长。补充图6中报告的图3任务的较小时间步长的控制实验表明,时间步长的大小对e-prop的性能没有显著影响。
)。我们为所有模拟选择了δt = 1ms的离散时间步长。补充图6中报告的图3任务的较小时间步长的控制实验表明,时间步长的大小对e-prop的性能没有显著影响。



Gradient descent for RSNNs.
Network output and loss functions.
Notation for derivatives.
Notation for temporal filters.
Mathematical basis for e-prop.
Derivation of eligibility traces LIF neurons.
Eligibility traces for ALIF neurons.
Synaptic plasticity rules resulting from e-prop.




Data availability
作者可应合理要求提供支持本研究结果的数据。TIMIT和ATARI基准任务的数据在以前的工作(DOI [https://doi.org/10.1613/jair.3912])和参考文献20(DOI [https://doi.org/10.6028/nist.ir.4930])中发布。时序信度分配任务的数据由上述代码存储库中提供的自定义代码生成。
Code availability
e-prop的实现解决了图2-5,与本文的发表一起公开:https://github.com/IGITUGraz/eligibility_propagation。
Supplementary materials for: A solution to the learning dilemma for recurrent networks of spiking neurons


Supplementary Figures



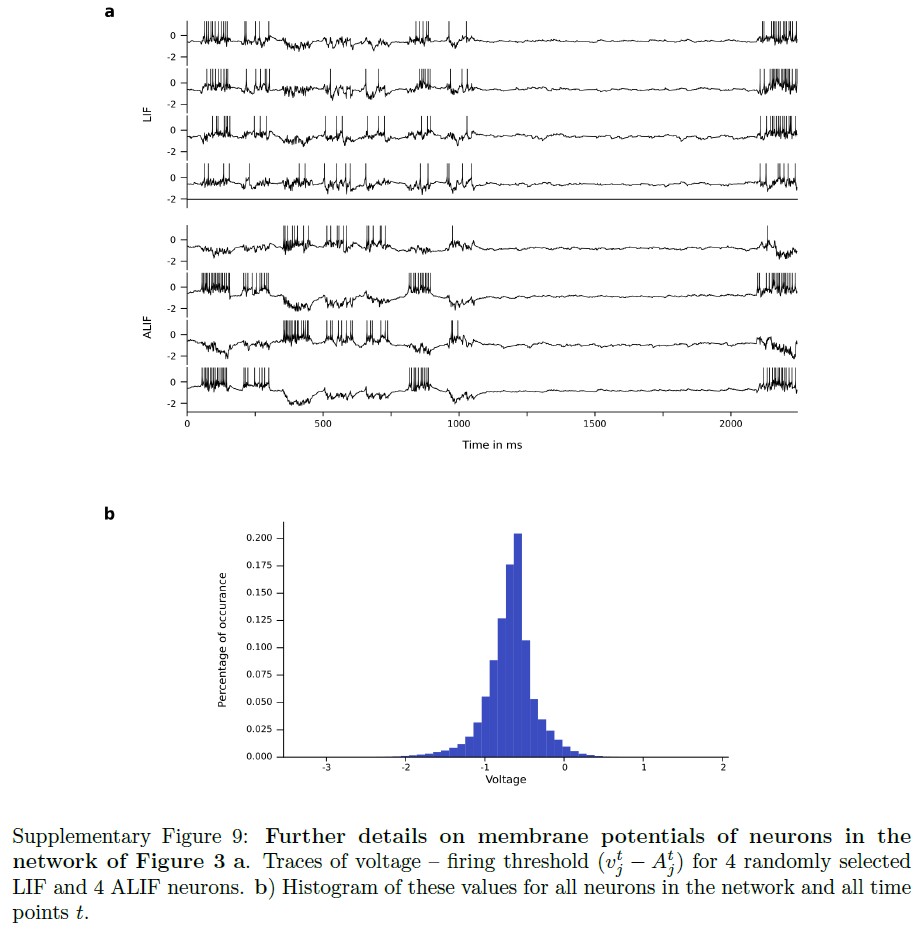
Supplementary Tables
Supplementary Notes
1 Eligibility traces
Results中的“Mathematical basis for e-prop”一节中介绍了资格迹。在这里,我们提供有关资格迹的更多信息。首先,我们讨论作为衍生品的资格迹的另一种观点。其次,我们在方法中扩展了对LSNN资格迹的处理,以包括非均匀突触延迟。
Viewing eligibility traces as derivatives

Eligibility traces for LSNNs with membrane potential reset
在方法中导出的资格迹不考虑重置项。我们在这里得出可以纠正这一点的资格迹。然而请注意,当在音素识别和时间信度分配困难的任务中使用这个更复杂的模型时,我们没有观察到改进。


Eligibility traces for LSNNs with non-uniform synaptic delays

2 Optimization and regularization procedures
Optimization procedure
Firing rate regularization for LSNNs
Adaptive e-prop and weight decay regularization
Voltage regularization
Optimization with rewiring for sparse network connectivity
3 Supervised learning with e-prop
Synaptic plasticity rules for e-prop in supervised learning
Simulation details: framewise phoneme recognition task (Figure 2)
Simulation details: phoneme sequence recognition with CTC (Figure 2)
Applying e-prop to an episodic memory task
Simulation details: task where temporal credit assignment is difficult (Figure 3)
4 Applying supervised learning with e-prop to artificial neural networks (LSTM networks)
Phoneme recognition with LSTM networks and e-prop
Simulation details: framewise phoneme recognition task with LSTM networks (Supplementary Figure 4)
Simulation details: phoneme sequence recognition with CTC and LSTM networks (Supplementary Figure 4)
LSTM network model


Eligibility traces for LSTM units

5 Reward-based e-prop: Application of e-prop to deep RL
Synaptic plasticity rules for reward-based e-prop
在此,我们推导出由损失函数 E 的梯度产生的突触可塑性规则,如等式(32)中的方法中给出的,参见图4b的网络架构。作为具有策略梯度的通用actor-critic框架的结果,该损失函数将策略Eπ(actor)的损失函数和价值函数EV(critic)相加结合。
我们考虑两种情况:首先,一个简化的情况,在每次试验中,在试验结束时采取一个动作。这是任务的基于奖励的版本的设置,其中图3的时间信度分配很难,有关性能结果,请参见补充图5。其次,我们分析了一个更一般的案例,其中在整个试验过程中都采取了动作。这是Atari任务的设置(图4, 图5)。对于这两种情况,我们推导出损失函数 E 的部分Eπ和EV的梯度,并表达由这些梯度产生的可塑性规则。





Simulation details: RL version of the task where temporal credit assignment is difficult (Supplementary Figure 5)
本实验中考虑的任务与图3中的相同,但是虽然该任务被制定为监督学习,但网络在这里使用强化学习设置进行训练。试验结束时奖励为1,如果智能体选择了比另一方有更多线索的一方,否则不给予奖励。网络模型与监督设置中的相同。结果是在10次不同的运行中计算得出的,如补充图5所示:该任务可以通过基于奖励的e-prop来学习。
Details of the decision process: 在任务的强化学习设置中,一个二元动作形式化了智能体在试验结束时的决定("左"或"右")。该决策是根据使用上述softmax操作从网络输出计算得出的概率 k 进行采样的。
Details of the learning procedure: 为了学习,我们模拟了64次试验的批次,并在每批次结束时应用了权重变化。独立于学习方法,我们使用Adam来实现权重更新,使用在64次试验中累积的梯度,使用5×10-3的学习率和默认超参数[6]。对于随机e-prop,我们从均值为0,方差为1的高斯分布中对广播权重Bjk进行采样。为了避免过高的发放率,如补充说明2中所述,正则化应用于creg = 0.1和目标发放率ftarget = 10 Hz。
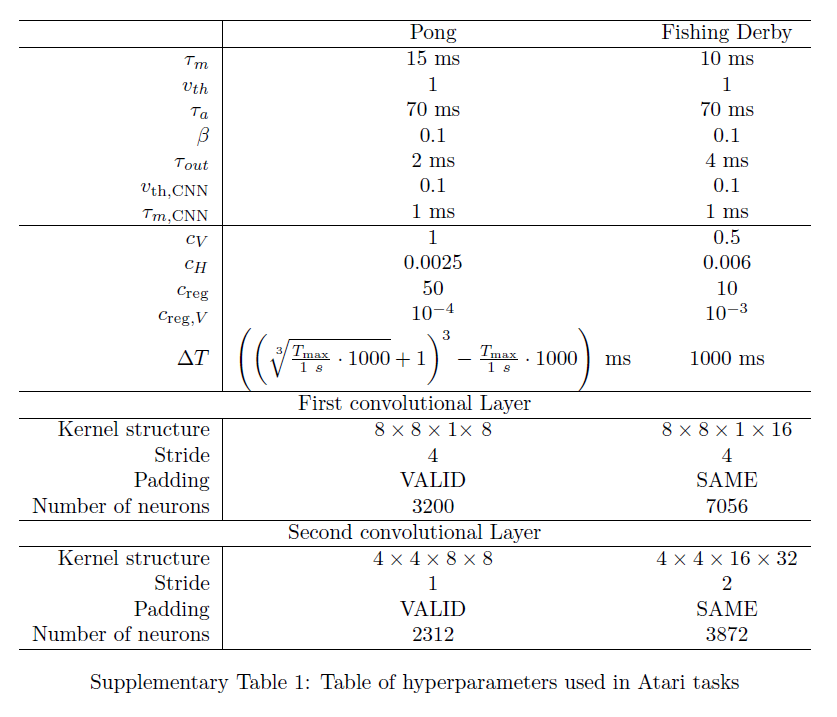
Simulation details: Atari task (Figures 4 and 5)
Details of the Atari simulator and of the input scheme: 对于我们所有的实验,我们都使用Arcade学习环境来模拟各种Atari游戏。该模拟器将来自智能体的动作作为输入,并通过重复相同的动作4次来提高游戏的动态性。然后,模拟器会产生奖励反馈以及新的视频帧。产生的视频帧的形状为宽160像素,高210像素,每个像素具有3个描述其颜色的值。我们首先将彩色视频帧转换为灰度视频帧,并将其缩放为84 x 84。灰度值(假设值介于0到255之间)除以255。在我们的实验中,这些观察值每个给定5 ms作为输入xt, ... , xt+4,并被提供给脉冲智能体。
Details of evaluation: 图4和5中报告的结果是通过5次不同的运行计算得出的,其中每次运行的特征是不同的随机种子。对于每次运行,这会导致智能体的不同随机初始权重和用于对随机动作进行采样的不同随机数。由于学习方法的相似性,我们选择将我们的脉冲智能体与[19]的表S3中报告的结果进行比较。但是请注意,评估协议中存在一些差异:
- [19]中报告的结果是50个最佳运行中的5个,而我们报告的是5个运行的平均值;
- 他们的评估协议涉及人类的起始条件,这意味着评估回合是通过人类游戏进行初始化的,而我们以多达30个无操作动作随机开始回合。
Details of the network model: 智能体的网络结构由一个脉冲CNN和一个LSNN组成。脉冲CNN由5512个用于Pong的LIF神经元组成(分别为10928个用于Fishing Derby的LIF神经元)。这些神经元分为两层。第一层的神经元接收到视频帧卷积产生的输入电流。这些神经元的脉冲通过具有卷积权重结构的突触传播到第二层神经元。偏差是两个卷积的通道特定的,所有相应的超参数见表1。两个卷积层中的所有神经元的膜时间常数均为τm,CNN ms,阈值为vth,CNN,见表1。为了使学习实验的计算时间在我们的计算资源范围内,我们不得不使用非常高的输入帧率。因此,每5 ms向网络呈现一幅新图像。这迫使我们将预处理CNN中脉冲神经元的膜常数设置为1 ms的非生物学低值。我们推测,使用较大的计算资源模拟相同的学习过程,当输入帧的呈现时间可以乘以某个因子F,比如F=20时,脉冲CNN将能够用神经元处理这些视觉输入,神经元的膜时间常数乘以相应的因子F,从而使它们进入生物学范围。
LSNN由Pong的240个LIF神经元和160个ALIF神经元组成(Fishing Derby分别为180个LIF神经元和120个ALIF神经元),并从第二个卷积层的所有神经元接收脉冲输入。膜时间常数τm,基准阈值vth,适应时间常数τa和适应强度 β 在表1中报告。不应期设置为5 ms。LSNN中的所有突触延迟均为1 ms。输出yt,Vt定义为输出神经元的膜电压,其膜时间常数τout在表1中报告。这些输出神经元收到了网络中所有神经元(包括卷积层中的神经元)的脉冲信号。
Details of the action set and of the action generation: 根据手头的游戏选择有效动作集。对于Pong,我们使用了一组3个有效动作:向上、向下和保持(无操作)。对于Fishing Derby,我们使用了9种可能的动作选择:保持(无操作)、发放、上、右、左、下、右上、左上、右下和左下。根据离散概率分布对动作进行采样,其中第 k 个动作的采样概率为![]() 。由于智能体在5毫秒内接收到相同的视频帧,因此每5毫秒后才会生成动作。
。由于智能体在5毫秒内接收到相同的视频帧,因此每5毫秒后才会生成动作。
Details of the learning procedure: 智能体接受了总共250·106个动作生成的训练,对应于Atari 模拟器的109个视频帧(动作在内部重复4次)。我们根据补充方程(45)计算了由基于奖励的对称e-prop产生的梯度。一个常见的学习方案是使用生活在环境的平行副本中的actor,这些actor可以在正在进行的回合中定期相互交流梯度[19]。但是这个方案很难提供大脑学习的模型。出于这个原因,我们设计了一个增加长度的回合时间表,并仅在32个回合完成后才执行权重更新(Fishing Derby为64)。单个智能体可以通过局部突触可塑性来实现该算法。然而,这个方案相当于并行模拟这32个独立的回合——但没有学习智能体之间的通信而不是顺序。这种观察可用于节省模拟时间。
对于Pong,CNN的权重仅被训练以最小化神经活动的正则化,因此它不需要学习信号。对于Fishing Derby,由于每个神经元都连接到输出神经元,我们定义广播权重![]() 使CNN中的神经元与输出权重对称:
使CNN中的神经元与输出权重对称:![]() 。
。
由于模拟限制,我们在Pong每500毫秒(Fishing Derby为150毫秒)后将衰减内存滤波器![]() 以及资格向量
以及资格向量![]() 重置为零。使用Adam [6]应用权重更新,学习率为10-3(参数 ε 设置为1)。在Fishing Derby中,如果超过1000的范数,我们会裁剪这些梯度。在训练开始时,最大回合长度Tmax被限制为1000毫秒,并且在每8750秒后增加ΔT,见表1。我们使用了折扣因子γ = 0.998。请注意,动作仅在每5毫秒后生成。在Eπ和EV之间权衡的互系数cV可以在表1中找到。我们还应用了补充公式(44)中的熵正则化,以防止过早收敛到次优策略。表1提供了将此损失EH添加到目标的系数cH的值。为了避免过高的发放率,如2中所述应用了正则化。目标发放率由ftarget = 20 Hz给出。我们使用进一步的正则化来防止膜电压假设ψj为零的值。
重置为零。使用Adam [6]应用权重更新,学习率为10-3(参数 ε 设置为1)。在Fishing Derby中,如果超过1000的范数,我们会裁剪这些梯度。在训练开始时,最大回合长度Tmax被限制为1000毫秒,并且在每8750秒后增加ΔT,见表1。我们使用了折扣因子γ = 0.998。请注意,动作仅在每5毫秒后生成。在Eπ和EV之间权衡的互系数cV可以在表1中找到。我们还应用了补充公式(44)中的熵正则化,以防止过早收敛到次优策略。表1提供了将此损失EH添加到目标的系数cH的值。为了避免过高的发放率,如2中所述应用了正则化。目标发放率由ftarget = 20 Hz给出。我们使用进一步的正则化来防止膜电压假设ψj为零的值。
6 Evaluation of four variations of e-prop (Supplementary Figure 7)
A truncated eligibility trace for LIF neurons
Global broadcast weights
Temporally local broadcast weights
Replacing the eligibility trace by the corresponding term of the Clopath rule
Simulation details: pattern generation task


