How Attention Can Create Synaptic Tags for the Learning of Working Memories in Sequential Tasks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

PLOS COMPUTATIONAL BIOLOGY, no. 3 (2015)
Abstract
智力是我们学习对新刺激和新情况做出适当反应的能力。联想皮层中的神经元被认为是这种能力必不可少的。在学习过程中,这些神经元被调到相关特征,并开始以记忆延迟期间的持续活动来表示它们。这个学习过程还没有被很好地理解。在此,我们开发了一种生物学合理的学习方案,该方案解释了试错学习如何诱导与任务相关的信息的神经元选择性和工作记忆表示。我们提出响应选择阶段将注意力反馈信号发送到较早的处理级别,在负责刺激-响应映射的那些连接处形成突触标记。然后,全局释放的神经调节剂与标记的突触相互作用,以确定其可塑性。由此产生的学习规则赋予神经网络以持久性活动的形式创建任务相关信息的新工作记忆表示的能力。它是非常通用的:它解释了关联神经元如何学习记忆存储与任务相关的信息,以用于线性和非线性刺激-响应映射,如何根据任务需求将它们调整为类别边界或模拟变量,以及它们如何学习将概率证据整合到感知决策中。
Author Summary
工作记忆是智力的基石。人们可以想象的大多数(如果不是全部)任务需要某种形式的工作记忆。工作记忆任务的最优解决方案取决于过去提供的信息,例如,基于数百米之前的路标在十字路口选择正确的方向。有趣的是,像猴子这样的动物很容易学会困难的工作记忆任务,只需在执行所需行为时获得诸如果汁之类的奖励即可。大脑关联区域中的神经元在此过程中起着重要作用。这些区域整合了感知和记忆信息以支持决策。这些关联神经元中的一些已被调到相关特征,并记住以后持续不断地增加其活动所需的信息。但是,人们对这些神经元如何获得与任务相关的调优还不太了解。在此,我们制定了一种简单的生物学合理的学习机制,该机制可以解释神经元网络如何通过试错学习来学习各种各样的工作记忆任务。我们还表明,该模型所学习的解决方案与在类似任务上进行训练的动物中的解决方案具有可比性。
Introduction
只需在适当的时间给予奖励,就可以训练诸如猴子之类的动物执行复杂的认知任务。它们可以学习将感觉刺激映射到响应,记忆与任务相关的信息以及整合和组合不可靠的感觉证据。训练在皮质的"多需求"区域中诱导出新的刺激和记忆表征[1]。例如,如果训练猴子记住视觉刺激的位置,则顶叶外侧皮层(LIP)中的神经元会将此位置表示为持续提高其发放率[2,3]。但是,如果动物学习视觉分类任务,则LIP细胞的持续活动会被调整到类别之间的边界[4],而如果任务是感觉上的决策,则神经元会整合概率证据[5]。在体感系统中已经观察到训练对持续活动的类似效果。如果训练猴子比较连续的触觉刺激的频率,则会在体感、前额叶和运动皮层中形成模拟变量的工作记忆表征[6]。
哪种学习机制会在这些任务中引起适当的工作记忆?我们在这里概述了AuGMEnT(注意力门控记忆标记),这是一种新的强化学习[7]方案,它解释了试错学习过程中工作记忆的形成,并受到了注意力和神经调节系统在神经元可塑性的门控中作用的启发。AuGMEnT解决了学习理论中的两个众所周知的问题:时序和结构信度分配[7,8]。如果智能体必须学习仅在一系列干预动作之后才能获得奖励的动作,就会出现时序信度分配问题,因此很难将信度分配给适当的动作。AuGMEnT像以前的时序差分RL理论一样解决了这个问题[7]。它学习动作价值(被称为Q值[7]),即在世界的特定状态下执行时针对特定动作预测的奖励金额。如果结果偏离奖励预测,则根据实验结果,编码全局奖励预测误差(RPE)的神经调节信号会控制突触可塑性,从而改变Q值[9-12]。AuGMEnT的关键新特性是它还可以学习需要工作记忆的任务,从而超越了标准RL模型[7,13]。
AuGMEnT还解决了多层网络的结构性信度分配问题。应该更改哪些突触以提高性能?AuGMEnT通过"注意力"反馈机制解决了这个问题。输出层具有到较早级别的单元的反馈连接,这些反馈连接为负责所选动作的那些单元提供了反馈[14]。我们建议,该反馈信号标记[15]具有相关的突触,并且标记的持久性(被称为资格迹[7,16])允许在动作和RPE之间经过时间的情况下进行学习[参见17]。我们将在这里证明AuGMEnT在神经科学上的合理性。这些结果的初步的和技术性的版本已经在会议上提出[18]。
Model
Model architecture
我们使用AuGMEnT来训练由三层单元组成的网络,该单元由两层可修改的突触连接(图1)。时间是离散步骤的模型。
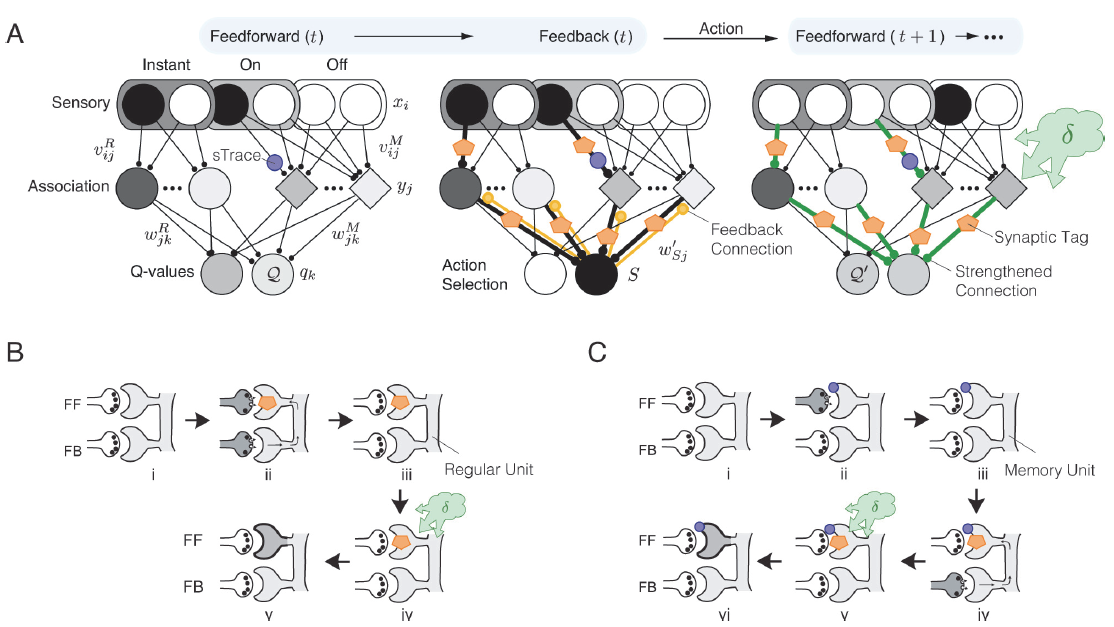
图1. 模型架构
A,模型由一个感觉输入层组成,该感觉输入层具有对输入进行编码的单元(瞬时单元)仅在刺激出现时(开-单元)或消失时(关-单元)才响应的瞬态单元。关联层包含常规单元(圆圈),其活动依赖于瞬时输入单元,并且集成了从瞬态感觉单元接收输入的记忆单元(菱形)。如果突触处于活动状态,则从输入层到记忆单元的连接会保持突触迹(sTrace; 蓝色圆圈)。第三层中的单元编码动作价值(Q值)。计算前馈激活后,"赢家通吃"竞争确定获胜动作(请参阅中间面板)。动作选择会导致反馈信号达到较早的级别(通过反馈连接![]() ,请参见中间面板),该信号在负责所选动作的突触处放置突触标记(橙色五边形)。如果下一个动作S'的预测Q值(QS')加上所获得的奖励r(t)高于QS,则全局释放的神经调节剂δ (请参见等式(17))与标记的突触相互作用,以增强标记突触的强度(绿色连接)。如果预测值低于期望值,则标记突触的强度会降低。
,请参见中间面板),该信号在负责所选动作的突触处放置突触标记(橙色五边形)。如果下一个动作S'的预测Q值(QS')加上所获得的奖励r(t)高于QS,则全局释放的神经调节剂δ (请参见等式(17))与标记的突触相互作用,以增强标记突触的强度(绿色连接)。如果预测值低于期望值,则标记突触的强度会降低。
B,常规单元标记过程的示意图。FF是前馈连接,而FB是反馈连接。前馈和反馈激活的组合在步骤ii中产生突触标记。标记与全局释放的神经调节剂δ相互作用以改变突触强度(步骤iv, v)。
C,记忆单元的标记过程。任何突触前馈激活都会产生突触迹(步骤ii; sTrace-紫色圆圈)。来自选择用于动作的Q值单元的反馈信号在带有突触迹的突触上创建突触标记(步骤iv)。神经调节剂可以与标记相互作用以修改突触强度(v, vi)。
Input layer
在每个时间步骤的开始,前馈连接通过可修改的连接vij将信息从感觉层传播到关联层。感觉层代表具有瞬时和瞬态单元的刺激(图1)。瞬时单元表示当前的感觉刺激x(t),并在存在刺激时活跃。瞬态单元表示刺激的变化,其行为类似于感觉皮层中的"开(+)"和"关(-)"细胞[19]。它们对关于前一个时间步骤t-1的感觉输入中的正负变化进行编码:
![]()
![]()
其中[·]+是阈值运算,对于所有负值均返回0,但使正值保持不变。因此,每个输入都由三个感觉单元表示。我们假设所有单元在试验开始时的活动为零(t = 0),并且在试验的第一个时间步骤t = 1。
Association layer
网络的第二个(隐含)层对关联皮质建模,并包含常规单元(图1中的圆圈)和记忆单元(菱形)。我们使用"常规单元"一词来反映以下事实:它们是规则的sigmoidal单元,在没有输入的情况下不会表现出持续的活动。常规单元 j 通过连接![]() (上标R索引突触到常规单元,而
(上标R索引突触到常规单元,而![]() 是偏差权重)完全连接到感觉层中的瞬时单元 i。它们的活动由以下因素决定:
是偏差权重)完全连接到感觉层中的瞬时单元 i。它们的活动由以下因素决定:

其中![]() 表示突触输入,σ表示sigmoidal激活函数。
表示突触输入,σ表示sigmoidal激活函数。
![]()
尽管我们的结果不取决于σ的特定选择。![]() 的导数可以方便地表示为:
的导数可以方便地表示为:
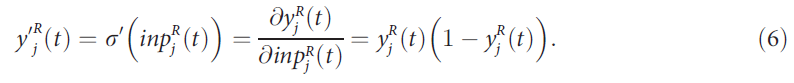
记忆单元 m (图1中的菱形)通过连接![]() (上标M索引突触到记忆单元)完全连接到感觉层中的瞬态(+/-)单元,并且在试验期间将其输入进行整合:
(上标M索引突触到记忆单元)完全连接到感觉层中的瞬态(+/-)单元,并且在试验期间将其输入进行整合:
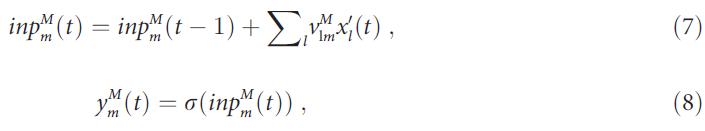 其中我们使用表示+和-细胞的简写
其中我们使用表示+和-细胞的简写![]() ,因此
,因此![]() 应该读作
应该读作![]() 瞬态输入单元和记忆单元之间的选择性连接是有利的。我们发现,当记忆单元也从瞬时输入单元接收输入时,学习方案就不稳定,因为在那种情况下,随着时间的推移,随着活动的增加,甚至恒定的微弱常数输入也会随着时序积分。但是,我们注意到,还有其他神经元机制可以阻止恒定输入的整合。例如,瞬时输入单元和记忆单元之间的突触可以快速适应,使得记忆单元仅在其输入中集成变化。
瞬态输入单元和记忆单元之间的选择性连接是有利的。我们发现,当记忆单元也从瞬时输入单元接收输入时,学习方案就不稳定,因为在那种情况下,随着时间的推移,随着活动的增加,甚至恒定的微弱常数输入也会随着时序积分。但是,我们注意到,还有其他神经元机制可以阻止恒定输入的整合。例如,瞬时输入单元和记忆单元之间的突触可以快速适应,使得记忆单元仅在其输入中集成变化。
仿真的集成过程会导致记忆单元活动的持续变化。不难发现,记忆单元的活动等于假设的常规单元的活动,该常规单元将同时从试验的所有先前时间步骤接收输入。为了使模型简单,我们没有仿真持续活动的机制,先前的工作已经解决了这些问题[20-22]。虽然在等式(7)中假设的完美集成在现实中不存在,我们建议对于持续时间相对较短的试验,这是可以接受的近似值,如下面将要描述的任务中所述。确实,有报道称内嗅皮层中的单个神经元整合体具有稳定的发放率,持续10分钟或更长时间[23],比此处模拟的试验长几个数量级。在行为动物的神经生理学研究中,神经元的行为类似于常规和记忆单元,例如LIP[2,3]和额叶皮层[24]将分别分类为视觉细胞和记忆细胞。
Q-value layer
第三层通过可塑连接wjk从关联层接收输入(图1)。它的任务是为每个可能的动作计算动作价值(即Q值[7])。具体来说,如果网络选择了处于当前状态 s 的动作 a,则Q值单元旨在表示剩余的试验的(折扣)期望奖励[7]:
![]()
其中,Eπ{·}项是根据动作选择策略π和γ∈[0, 1]在给定 a 和 s 的情况下的期望折扣未来奖励Rt,决定未来奖励 r 的折扣。明确写出以上期望以了解Q值被递归定义为:
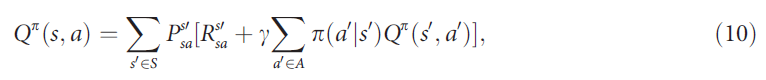
其中![]() 是转换矩阵,包含状态 s 中执行动作 a 会将智能体移动到状态s'的概率,
是转换矩阵,包含状态 s 中执行动作 a 会将智能体移动到状态s'的概率,![]() 是此转换的期望奖励,而S和A分别是状态和动作的集合。值得注意的是,动作选择策略π通常被认为是随机的。通过执行策略π,智能体根据概率分布π,
是此转换的期望奖励,而S和A分别是状态和动作的集合。值得注意的是,动作选择策略π通常被认为是随机的。通过执行策略π,智能体根据概率分布π,![]() 和
和![]() 对轨迹进行采样,其中每个观察到的转换都可以用来更新原始预测Q(st, at)。重要的是,诸如AuGMEnT之类的时序差分学习方案是无模型的,这意味着它们在改进其Q值的同时无需显式访问这些概率分布。
对轨迹进行采样,其中每个观察到的转换都可以用来更新原始预测Q(st, at)。重要的是,诸如AuGMEnT之类的时序差分学习方案是无模型的,这意味着它们在改进其Q值的同时无需显式访问这些概率分布。
Q值单元 k 通过连接![]() (来自常规单元,以
(来自常规单元,以![]() 作为偏差权重)和
作为偏差权重)和![]() (来自记忆单元)完全连接到关联层。动作价值qk(t)被估计为:
(来自记忆单元)完全连接到关联层。动作价值qk(t)被估计为:
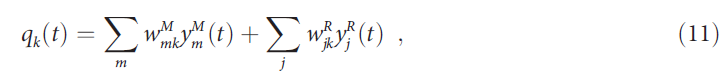
其中qk(t)旨在表示在时间步骤 t (即at = k)处的动作 k 的价值。在AuGMEnT中,状态 s 在等式(9)中由关联层中的激活向量表征。因此,关联层单元必须学会表示和记忆有关环境的信息,以计算所有可能动作 a 的价值。他们通过将相关信息记忆为持久性活动,从而将其用于下一个决策,从而将所谓的部分可观察的马尔可夫决策过程(POMDP)(其中最优决策依赖于过去呈现的信息)转换为更简单的马尔可夫决策过程(MDP)。
Action selection
动作选择策略π由Q值偏向的随机赢家通吃(WTA)竞争实现。网络通常会选择具有最高价值的动作 a,但偶尔会探索其他动作来改进其价值估计。我们使用Max-Boltzmann控制器[25]来实现动作选择策略π。它选择概率为1-ε的贪婪动作(最高qk(t),关系被随机打破),并从小概率 ε 的玻尔兹曼分布PB中采样一个随机动作 k:

该控制器确保模型探索所有动作,但通常选择期望价值最高的动作。我们假设控制器是在下游实现的,例如在运动皮层或基底神经节中,但不模拟动作选择的细节,这些细节先前已解决[26-30]。选择动作 a 之后,第三层的活动变为zk = δka,其中δka是Kronecker delta函数(如果k = a,为1,否则为0)。换句话说,选择的动作是选择过程之后唯一活跃的,然后向关联皮质(图1A中的橙色反馈连接)提供"注意力"反馈信号。
Learning
网络中的学习受两个控制可塑性的因素控制:全局神经调节信号(如下所述)和注意力反馈信号。一旦选择了一个动作,对获胜动作进行编码的单元将反馈到较早的处理级别,以创建突触标记[31,32],也称为负责突触上的资格迹[7,16](图1中的橙色五边形)。从关联层到运动层的连接的标记遵循赫布可塑性的形式:标记强度取决于动作选择(zk)后的突触前活动(yj)和突触后活动,因此标记仅在突触wja上形成在获胜(即被选择)运动单元 a 上:

其中,α控制标记的衰减。此处,Δ表示一个时间步骤的变化,即Tag(t + 1) = Tag(t) + ΔTag(t)。
根据神经生理学发现,在反馈连接处的标记形成遵循相同的规则,因此前馈和反馈连接的强度在学习过程中变得相似。因此,为获胜动作 a 提供强输入的招募单元也将获得最强的反馈(图1, 中间面板):他们将对 a 的结果负责。重要的是,注意力反馈信号还指导连接vij上标记的形成,以便最强地标记从输入层到负责的关联单元 j (强![]() )上的突触(图1B)。
)上的突触(图1B)。
对于常规单元,我们提出:
![]()
其中σ'是关联单元的激活函数σ (等式(5))的导数,该函数确定输入inpj的变化对单元 j 的活动的影响。这个想法已经在图1B中示出。来自获胜动作的反馈(图1B中的下部突触)可在前馈连接上的常规单元上形成标记。这些标记可以与全局释放的神经调节剂相互作用,这些神经调节剂通知所有突触有关RPE (图1中的绿色云"δ")。请注意,反馈连接仅影响关联层中表示的可塑性,而不影响模型当前版本中的活动。我们将在讨论中回到这一点。
除了突触标记,AuGMEnT还使用突触迹(sTrace, 图1A, C中的蓝色圆圈)来学习新的工作记忆。这些迹位于从感觉单元到记忆单元的突触上。这些突触中的任何突触前活动都会留下迹,并在试验期间持续存在。如果选择的动作之一向突触后记忆单元提供反馈信号(图1C中的面板iv),则该迹会产生一个标记,使突触可塑性现在可以与全局释放的神经调节剂相互作用:
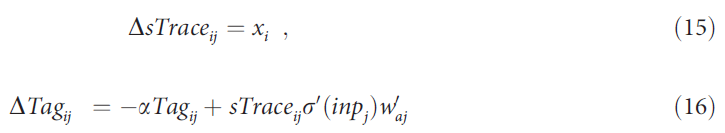
我们假设迹更新的时间尺度与标记更新相比较快,因此标记将使用最新的迹进行更新。迹在试验期间一直存在,但所有标记均呈指数衰减(0 < α < 1)。
在执行动作之后,网络可以接收奖励r(t)。此外,在时间步骤(t - 1)上的动作 a 可能会导致感觉刺激的改变。例如,在大多数对猴子视力的研究中,如果动物将视线引向注视点,就会出现视觉刺激。在模型中,新刺激会导致在下一个时间步骤 t 进行前馈处理,从而导致另一组Q值。为了评估 a 是好于还是差于预期,该模型将必须临时存储在系统中的预测结果Qa(t - 1)与赢得随后的随机WTA竞争的单元a'的奖励r(t)和折扣动作-价值Qa'(t - 1)的总和进行比较。这种时序差分学习规则称为SARSA [7,34]:
![]()
如果 a 的结果好于预期,则RPE δ(t)为正,如果更糟,则RPE δ(t)为负。在额叶皮层,基底神经节和中脑中发现了代表动作价值的神经元[12,35,36],一些眶额神经元专门编码了所选价值qa[37]。此外,腹侧被盖区和黑质中的多巴胺神经元代表δ [9,10,38]。在该模型中,神经调节剂的释放使δ在整个大脑中都可用(图1中的绿色云朵)。
所有突触的可塑性取决于δ和标记强度的乘积:

其中β是学习率,后一个等式也适用于反馈权重![]() 。这些等式抓住了AuGMEnT的关键思想:标记的突触对RPE负责,并相应地改变了它们的强度。值得注意的是,AuGMEnT对突触vij使用四因素学习规则。前两个因素是突触前和突触后活动决定标记的形成(等式(14)-(16))。第三个因素是来自运动选择阶段的"注意力"反馈,它确保仅在负责所选动作的电路中形成标记。第四个因素是RPE δ,它反映了动作的结果是否比预期的好还是差,并确定了标记突触的强度是增加还是减少。RPE的计算需要比较不同时间步骤中的Q值。在时间 t 的RPE取决于网络在t-1时选择的动作(参见等式(17)和下一节),但是引起该选择的单元的活动通常在时间 t 发生了变化。突触标记解决了此问题,因为它们标记了负责选择先前动作的那些突触。
。这些等式抓住了AuGMEnT的关键思想:标记的突触对RPE负责,并相应地改变了它们的强度。值得注意的是,AuGMEnT对突触vij使用四因素学习规则。前两个因素是突触前和突触后活动决定标记的形成(等式(14)-(16))。第三个因素是来自运动选择阶段的"注意力"反馈,它确保仅在负责所选动作的电路中形成标记。第四个因素是RPE δ,它反映了动作的结果是否比预期的好还是差,并确定了标记突触的强度是增加还是减少。RPE的计算需要比较不同时间步骤中的Q值。在时间 t 的RPE取决于网络在t-1时选择的动作(参见等式(17)和下一节),但是引起该选择的单元的活动通常在时间 t 发生了变化。突触标记解决了此问题,因为它们标记了负责选择先前动作的那些突触。
AuGMEnT是生物学合理的,因为控制着突触标记形成的等式(等式(13), (14), (16))和迹(等式(15))以及控制可塑性的等式(等式(18))仅依赖于突触处局部可用的信息。此外,神经生物学的发现支持了神经调节信号(如多巴胺)将RPE广播至网络中所有突触的假说[9,10,38]。
Results
现在,我们将给出主要的理论结果,即AuGMEnT学习规则将网络通过在线梯度下降所经历的转换的时序差分误差(等式(17))最小化。尽管不能保证AuGMEnT找到最优解决方案(我们无法提供收敛的证明),但我们发现它能够可靠地学习困难的非线性工作记忆问题,如下所示。
AuGMEnT minimizes the reward-prediction error (RPE)
AuGMEnT的目的是降低RPE δ(t),因为所有网络状态的低RPE都意味着可靠的Q值,以便网络可以选择在每个时间步骤上都能获得最大奖励的动作。RPE δ(t)表示两个量之间的比较:转换前的预测Q值qa(t - 1)和目标Q值r(t) + γqa'(t)观察到的奖励和下一个预测的Q值[7]。如果两个项都取消,则该预测是正确的。SARSA旨在通过调整网络权重 w 来改进预测qa(t - 1),使其更接近于观测值r(t) + γq'(t),以最小化预测误差。通过在线梯度下降对关于参数 w 的预测误差平方![]() 进行操作很方便[7,34]:
进行操作很方便[7,34]:
![]()
其中![]() 是预测Q值Qa(t - 1)相对于参数w的梯度。在等式(19)中,我们使用了
是预测Q值Qa(t - 1)相对于参数w的梯度。在等式(19)中,我们使用了![]() ,该式源自E(qa(t - 1))的定义。值得注意的是,仅针对采样的转换定义了E,因此该定义通常在网络经历的连续转换之间有所不同。为了符号上的方便,在本文的其余部分中,我们将E(qa(t - 1))缩写为
,该式源自E(qa(t - 1))的定义。值得注意的是,仅针对采样的转换定义了E,因此该定义通常在网络经历的连续转换之间有所不同。为了符号上的方便,在本文的其余部分中,我们将E(qa(t - 1))缩写为![]() 。
。
在本文的其余部分中,我们将等式(19)的负数称为"误差梯度"。如果奖励r(t)与折扣qa'(t)之和与上一时间步骤的预测qa(t - 1)明显偏离,则RPE较高。与其他SARSA方法一样,仅针对网络实际经历的转换执行突触权重的更新。换句话说,AuGMEnT是一种所谓的"同策"学习方法[7]。
我们将首先建立等式(19)中定义的在线梯度下降的等价关系,以及从常规单元到Q值单元的突触权重![]() 的AuGMEnT学习规则。根据等式(19),所选动作k = a在时间步骤t - 1的权重
的AuGMEnT学习规则。根据等式(19),所选动作k = a在时间步骤t - 1的权重![]() 应该更改为:
应该更改为:

其他权重k ≠ a保持不变。
现在我们将显示AuGMEnT引起突触强度的等效变化。它来自等式(11)![]() 对qa(t - 1)的影响(即等式(20)中的
对qa(t - 1)的影响(即等式(20)中的![]() )等于
)等于![]() ,即上一个时间步骤关联单元 j 的活动。此结果使我们可以将(20)重写为:
,即上一个时间步骤关联单元 j 的活动。此结果使我们可以将(20)重写为:
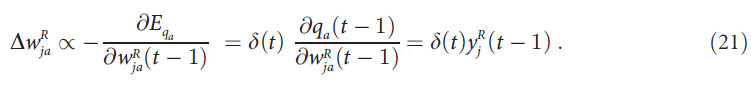
回顾等式(13)根据ΔTagja = -αTagja + yj (图1中的橙色五边形)更新突触到获胜输出单元 a 上的标记。在特殊情况下α = 1,可以得出在时间步骤 t 上![]() 和突触到输出单元k ≠ a上的标记为0。
和突触到输出单元k ≠ a上的标记为0。
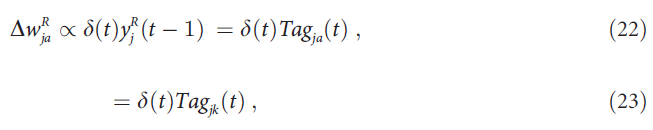
对于到选定动作 a 上的突触,第二个广义方程由以下事实得出:对于未选择的输出单元k ≠ a,![]() 。检验等式(18)和(23)表明,AuGMEnT实际上在与等式(19)的误差梯度相反的方向上采取了一个大小为β的步长(假设α = 1;我们在下面讨论α ≠ 1的情况)。
。检验等式(18)和(23)表明,AuGMEnT实际上在与等式(19)的误差梯度相反的方向上采取了一个大小为β的步长(假设α = 1;我们在下面讨论α ≠ 1的情况)。
记忆单元 m 和Q值单元 k 之间的突触更新等同于常规单元和Q值单元之间的突触更新。因此,
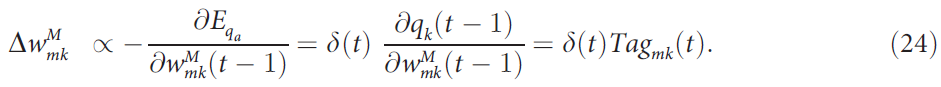
从Q值层到关联层的反馈连接![]() 和
和![]() 的可塑性遵循相同的规则,即连接
的可塑性遵循相同的规则,即连接![]() 和
和![]() 的更新,因此两个单元之间的前馈和反馈连接在学习过程中成比例[14]。
的更新,因此两个单元之间的前馈和反馈连接在学习过程中成比例[14]。
现在我们将显示输入层和常规关联单元(图1)之间的突触![]() 也根据上面定义的误差函数的负梯度而变化。应用链式规则来计算
也根据上面定义的误差函数的负梯度而变化。应用链式规则来计算![]() 对qa(t - 1)的影响可得出以下公式:
对qa(t - 1)的影响可得出以下公式:
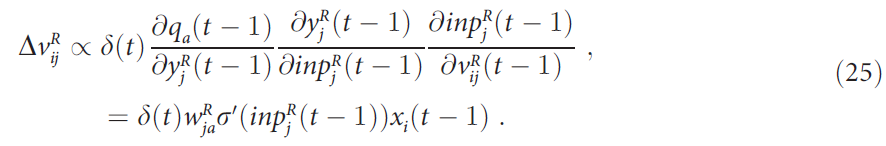
在时间t - 1处,单元 j 从选定Q值单元 a 接收到的注意力反馈量等于![]() ,因为一旦选择了单元 a 的活动,该活动就等于1。如上所述,学习使前馈和反馈连接的强度相似,因此可以将
,因为一旦选择了单元 a 的活动,该活动就等于1。如上所述,学习使前馈和反馈连接的强度相似,因此可以将![]() 估计为单元 j 从选定动作 a 接收到的反馈量
估计为单元 j 从选定动作 a 接收到的反馈量![]() :
:
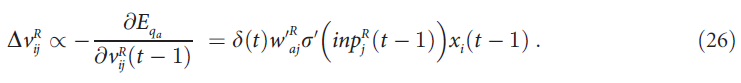
回顾等式(14),根据![]() 更新突触上的标记
更新突触上的标记![]() 。图1B示出了来自动作 a 的反馈如何控制标记形成过程。如果α = 1,则在时间步骤 t 上,
。图1B示出了来自动作 a 的反馈如何控制标记形成过程。如果α = 1,则在时间步骤 t 上,![]() 使得等式(26)可以写成:
使得等式(26)可以写成:
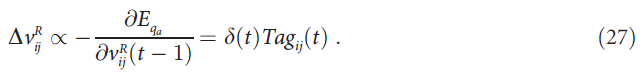
与等式(18)的比较证明,对于这些突触,AuGMEnT在与误差梯度相反的方向上也采取了一个大小为β的步长。
需要考虑的最后一组突触位于瞬态感觉单元和记忆单元之间。我们将记忆单元 m 的总输入![]() 近似为(参见等式(7)):
近似为(参见等式(7)):
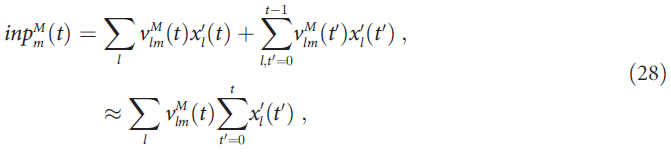
如果在试验过程中突触![]() 缓慢变化,则近似值很好。根据等式(19),这些突触的更新为:
缓慢变化,则近似值很好。根据等式(19),这些突触的更新为:
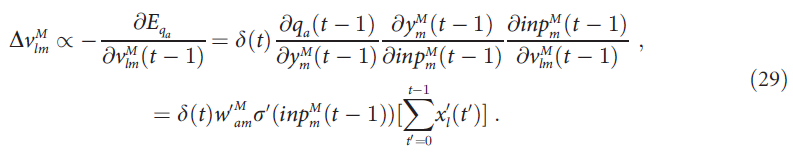
等式(15)指定ΔsTracelm = xl,从而使![]() ,直到时间t - 1为止输入单元的总突触前活动(图1C中的蓝色圆圈)。因此,等式(29)也可以写成:
,直到时间t - 1为止输入单元的总突触前活动(图1C中的蓝色圆圈)。因此,等式(29)也可以写成:
![]()
等式(16)指出![]() ,因为获胜动作 a 的反馈将迹转换为标记(图1C中的面板iv)。因此,如果α = 1,则
,因为获胜动作 a 的反馈将迹转换为标记(图1C中的面板iv)。因此,如果α = 1,则![]() ,因此:
,因此:
![]()
再次,等式(31)和(18)的比较表明,AuGMEnT在与误差梯度相反的方向上采取了一个大小为β的步长,就像所有其他类别的突触一样。我们得出结论,如果α = 1,则AuGMEnT会导致所有突触权重的在线梯度下降,以使TD误差最小。
AuGMEnT提供了一种称为SARSA的众所周知的RL方法的生物学实现,尽管它也超越了传统的SARSA [7],因为 (i) 包括记忆单元 (ii) 代表外部世界当前状态作为输入层的活动向量 (iii) 提供了一个关联层,该层有助于计算非线性地依赖于输入的Q值,从而提供误差反向传播学习规则[8]的生物学合理的等价物,以及 (iv) 使用突触标记和迹(图1B, C),因此可塑性的所有必要信息都可以在每个突触处局部获得。
标记和迹确定记忆单元的可塑性,并通过改进Q值估计来帮助降低RPE。如果记忆单元 j 从输入单元 i 接收到输入,则该输入的迹将在其余的试验中保持在突触vij处(图1C中的蓝色圆圈)。假设依次将 j 连接到在稍后时间点选择的动作 a。现在,单元 j 从 a 接收反馈,以使突触vij上的迹成为标记,使其对编码RPE δ的全局释放神经调节剂敏感(图1C中的面板iv)。如果 a 的结果好于预期(δ > 0)(图五中的绿色云朵),则vij增强(面板vi中的较厚突触)。当在以后的试验中再次出现激活单元 i 的刺激时,较大的vij会增加单元 j 的持续活动,从而增强表示 a 的Q值单元的活动,从而降低RPE。
AuGMEnT的突触标记对应于RL方案中使用的资格迹。在SARSA中,如果资格迹不是在每个时间步骤上都没有完全衰减,而是以参数λ ∈ [0,1] [7]指数增长,则学习速度会加快;结果规则称为SARSA(λ)。在AuGMEnT中,参数α发挥等效作用,并且可以通过设置α = 1 - λγ来获得精确的等效性,这可以通过在等式(13)(14)和(16)中进行此替换来验证(注意Tag(t + 1) = Tag(t) + ΔTag(t))。因此,标记随着Tag(t + 1) = λγTag(t)呈指数衰减,这等效于SARSA(λ)中资格迹的衰减。这些结果建立了生物学启发的AuGMEnT学习方案和RL方法SARSA(λ)之间的对应关系。试验结束时会出现特殊情况。在使用反映出向终端状态转换的δ更新权重之后,将记忆单元、迹、标记和Q值的活动设置为零(请参见[7])。
在结果部分的其余部分,我们将说明AuGMEnT如何训练图1形式的多层网络来执行各种各样的任务,这些任务已被用来研究猴子的联想皮层中的神经元表示。

Using AuGMEnT to simulate animal learning experiments
我们在四个不同的任务上测试了AuGMEnT,这些任务用于调查猴子中工作记忆表征的学习。前三个任务已用于研究学习对LIP区域神经元活动的影响,而第四项任务是研究多个皮质区域的触觉工作记忆。所有任务的总体结构都相似:猴子通过将视线对准固定点或触摸响应键来开始试验。然后刺激被呈现给猴子,并且在记忆延迟后它必须以正确的动作做出反应。在试验结束时,模型可以在两个可能的动作之间进行选择。如果此选择正确,则给予全部任务奖励(rf, 1.5个单元),而我们放弃试验,如果模型在执行信号之前做出错误选择或破坏固定点(释放键),则不给予任何奖励。
研究人员通常采用塑造策略来训练猴子完成这些任务。猴子从简单的任务开始,然后逐渐增加复杂性。在完成任务的中间目标(例如获得注视)时,通常会给予小额奖励。如果模型将视线直接引向固定点(触摸键),我们将通过提供少量塑造奖励(ri, 0.2个单元)来鼓励固定点(或触摸下面的触觉任务中的键)。在下一节中,我们将演示通过塑造来促使AuGMEnT进行网络训练。但是,在学习任何一项任务时塑造都不是必要的,但它可以提高学习速度,并可以在一定分配数量的训练试验中增加学习该任务的网络比例。
在所有仿真中,我们使用了关联层的单个固定配置(三个常规单元,四个记忆单元)和Q层(三个单元)以及一组学习参数(表1,2)。输入单元的数量随任务的变化而变化,因为感觉刺激的复杂性不同。但是,我们注意到,如果我们在某些任务中使用静默输入单元模拟固定的大型输入层,则下面描述的结果将是相同的,因为静默输入单元不会影响网络其余部分的活动。
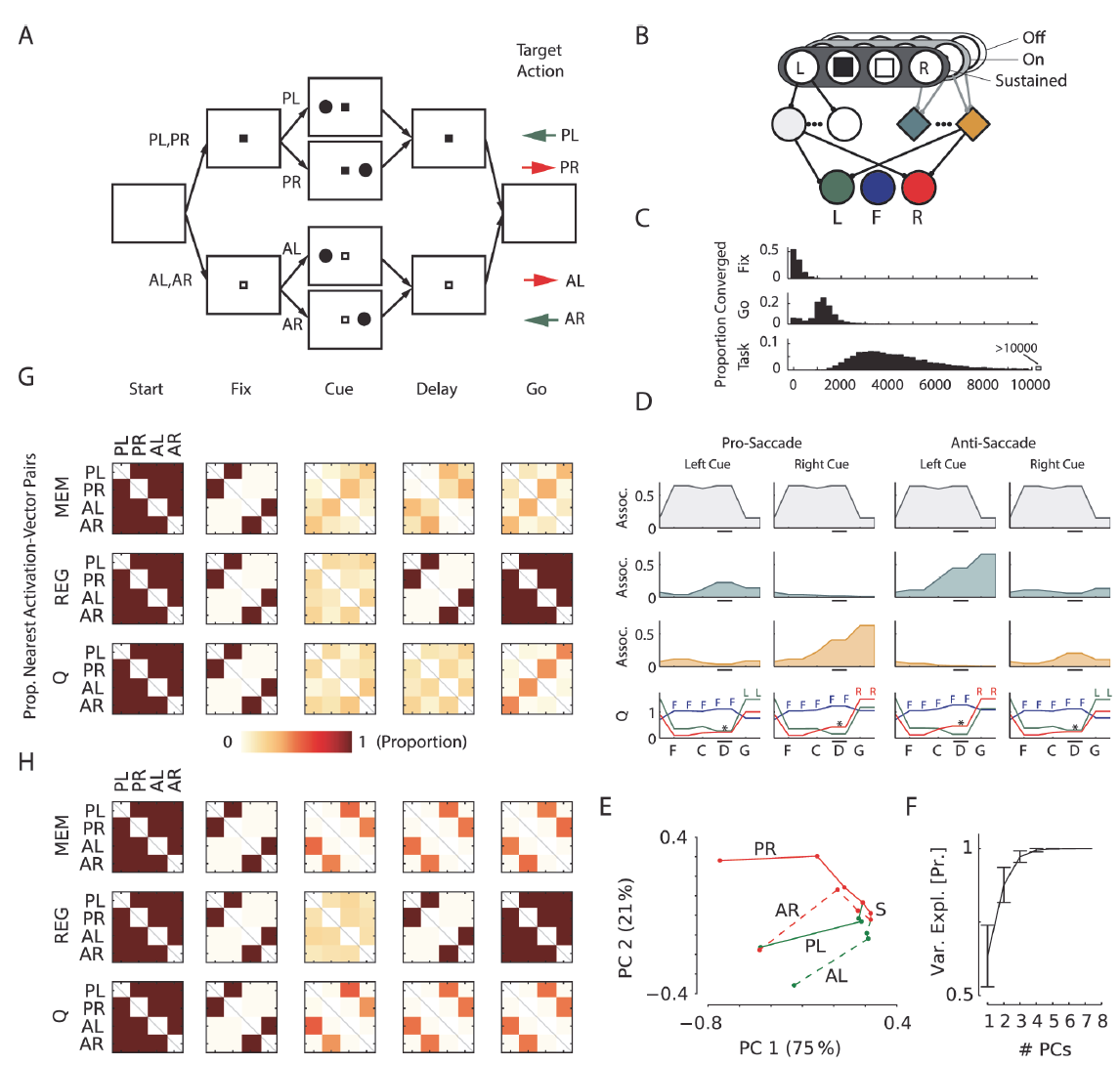
图2. 扫视/反扫视任务。A,任务的结构,已经说明了所有可能的试验。注视标记颜色指示在记忆延迟后是否需要扫视(P)或反扫视(A)。彩色箭头显示了指示的试验类型所需的动作。L:左提示; R:右提示。B,感觉层代表视觉信息(固定视点,左/右提示),具有持续的和短暂的(开/关)单位。Q值图层中的单位编码三个可能的眼睛位置:左(绿色),中心(蓝色)和右(红色)。C,时间学习过程:训练10000个网络,其中9945个在25000次试验内学到该任务。直方图显示了模型学会注视('fix'),保持注视直至发放"go"信号('go')并学会完整任务('task')时的试验分布。D,关联和Q层中示例单元的活动。灰色轨迹表示常规单元,绿色和橙色轨迹表示记忆单元。底部的图显示了Q值层单元的活动。彩色字母表示具有最高Q值的动作。像记忆单元一样,Q值单元也具有对提示位置(下图中的*)敏感的延迟活动,并且在激活信号后它们的活动增加。E,示例网络的四种不同试验类型的关联层激活序列的2D-PCA投影。S标记试验的开始(空白屏幕)。实扫视试验用实线显示,反扫视试验用虚线显示。颜色表示提示位置(绿色-左; 红色-右),标签表示试验类型(P/A = type pro/anti; L/R = cue left/right)。轴上的百分比显示PC解释的方差。F,平均方差解释为所有100个训练后的网络上PC数量的函数,误差条s.d. G,网络中不同单元类型的激活向量的成对分析(有关解释,请参见正文)。MEM:记忆;REG:常规。此面板与面板(A)中的事件对齐。矩阵中的每个正方形表示不同试验类型的活动向量最相似的网络所占的比例。色标如下所示。例如,任务'go'阶段中记忆单元矩阵的右上角正方形表示,大约25%的网络具有与Pro-Left和AntiRight试验最为相似的记忆激活向量。H,针对在只需要前扫视的任务版本上训练的网络的激活向量的成对分析。(G)中的约定。
Saccade/antisaccade task
第一项任务(图2A)是模仿Gottlieb和Goldberg[3]建立的记忆扫视/反扫视任务。每个试验都从一个空白屏幕开始(显示一个时间步骤)。然后显示的注视标记是黑色或白色,表明需要前扫视或反扫视。该模型必须在10个时间步骤内固定,否则试验将终止且无奖励。如果模型固定了两个时间步骤,我们会在屏幕的左侧或右侧提示一个时间步骤,并给出注视奖励ri。随后是两个时间步骤的记忆延迟,在此期间仅可见固定视点。在记忆延迟结束时,注视标记关闭。为了在前扫视条件下收集最终奖励rf,模型必须使眼睛移动到提示的记忆位置,并在反扫视试验中移动到相反的位置。如果模型未能在八个时间步骤做出响应,则试验将中止。
模型的输入单元(图2B)表示固定视点的颜色和周围提示的存在。三个Q值单元必须代表将视线指向屏幕中央、左侧和右侧的价值。该任务只能通过将提示位置存储在工作记忆中来解决,此外,还需要进行非线性转换,因此不能通过从感觉单元到Q值单元的线性映射来解决。我们对模型进行了最多25000次试验的训练,直到他们学会了任务为止。我们跟踪所有四种试验类型的准确性,以作为最近50次试验中正确答案的比例。当所有准确度达到0.9或更高时,学习和探索将被禁用(即β和ε设置为零),并且如果该模型准确地执行了所有试验类型,则我们认为学习成功。
我们发现,使用AuGMEnT学习此任务非常有效。我们沿任务学习轨迹区分了三个点:学习获得注视奖励('Fix'),学习注视直到注视标记消失('Go'),最后正确解决任务('Task')。为了确定'Fix'学习试验,我们在100个连续试验中的90个中确定了模型达到固定状态的时间点。该模型在224次试验(中值)后学会了注视(图2C)。在~1300次试验之后,该模型学会了保持注视直到发出信号,并在~4100次试验后成功学习了完整的任务。因此,学习过程通常比经过数月训练且每天进行1000多次试验的猴子至少快一个数量级。
为了研究塑造策略的效果,我们还训练了10000个没有额外注视奖励的网络(ri为零)。相比那些没有注视奖励的网络,其学会的可能性更高(99.45% vs 76.41%; χ2 = 2498, p < 10-6)。因此,塑造策略促进了AuGMEnT的训练,类似于它们在动物学习中的有益作用[39]。
训练好的网络的活动在图2D中进行了说明。关联单元之一(图2D中的灰色)和用于固定在显示器中心的Q单元(图2B, D中的蓝色)在注视开始时以及整个注视和记忆延迟中具有最强的活动性。如果记录在猕猴中,这些神经元将被分类为注视细胞。发出信号后,用于适当眼球运动的Q单元变得更加活跃。Q单元的活动还取决于记忆延迟期间的提示位置,例如在额眼区域(图2D中)观察到的[40]。此活动是由关联层中记忆单元的输入引起的,该输入将提示位置存储为其活动的持续增加(图2D中的绿色和橙色)。记忆单元也被调整为注视标记的颜色,从而将前扫视试验与反扫视试验区分开,这是解决该非线性任务所必需的联合选择性[41]。在关联层中,常规单元和记忆单元之间存在有趣的分工。记忆单元学会了记住提示位置。相反,常规单元学会了在屏幕上编码与任务相关的感官信息的存在。具体地说,只要存在固定视点,图2D(上排)中的注视细胞就会激活,当固定视点消失时会关闭,从而提示模型进行眼球运动。有趣的是,这两类记忆神经元和常规("光敏")神经元也出现在猴子的顶叶和额叶皮层区域[2,40],它们似乎起着相同的作用。
图2D提供了网络学习的表征的第一印象。为了更深入地了解关联层中支持从感觉单元到Q值单元的非线性映射的表征,我们对关联单元的激活进行了主成分分析(PCA)。我们从每个时间步骤的关联层激活构建了一个单独的(32x7)观察矩阵(四种试验类型中的每个都有7个关联单元和8个时间点),在这项任务的最终实验中,我们调查了是否为任务相关功能专门形成了工作记忆,其中网络的学习率β和探索率ε被设置为零。图2E展示了对于示例网络,激活向量到前两个主分量上的投影。可以看出,关联层中的活动反映了任务中的重要事件。固视点的颜色和提示位置提供有关正确操作的信息,并导致2D主成分(PC)空间中的"分裂"。在'Go'阶段,只有两种可能的正确操作:'left'用于Pro-Left和Anti-Right试验,否则为'right'。2D PC图显示,网络根据最优动作将空间分为三个部分:此处,'left'动作聚集在中间,而目标动作为'right'的两种试验类型与该群集相邻。这种模式(或通过中间的'right'动作将其反转)对于训练好的网络来说是典型的。图2F示出了在100个模拟网络中平均的,所解释的关联单元活动中的方差如何随着PC数量的增加而增加;前两个PC捕获了最多的方差。
为了调查在所有模拟网络中学习过程中形成的表征,我们接下来评估了常规和记忆关联单元以及Q值层中的单元的四种试验类型之间的激活模式(欧氏距离)的相似性(图2G)。对于每个网络,我们在距离最短的试验类型的矩阵中输入'1',在其他所有试验对中输入'0',然后通过对所得矩阵求均值,在所有网络上汇总结果。最初,对于所有试验类型,关联层中的活动模式都相似,但是在呈现出注视点和提示后,它们会有所不同。常规单元传达着很强的固定视点颜色表征(例如,左提示的前扫视试验中的活动与右提示的前扫视试验中的活动相似; 图2G中的PL和PR),其随时可见。记忆单元在延迟期间可以清楚地表示先前的提示位置(例如,图2G中的AL试验与PL试验相似,AR与PR试验相似)。根据需要,这些动作在需要相同动作的试验中变得相似(例如,AL试验变得与PR试验类似),对于Q值层中的单元也是如此。
在这项任务的最终实验中,我们调查了是否为任务相关功能专门形成了工作记忆。我们使用了相同的刺激,但现在只需要进行刺激,以使固定视点的颜色变得无关紧要。我们训练了100个网络,其中96个学会了任务,我们调查了激活模式的相似性。在这些网络中,记忆单元被调整到提示位置,而不是固定视点的颜色(图2H; 注意具有不同颜色固定点的试验(例如AL和PL试验)的类似活动模式)。因此,AuGMEnt专门在关联层中诱导了与任务相关的特征的选择性。
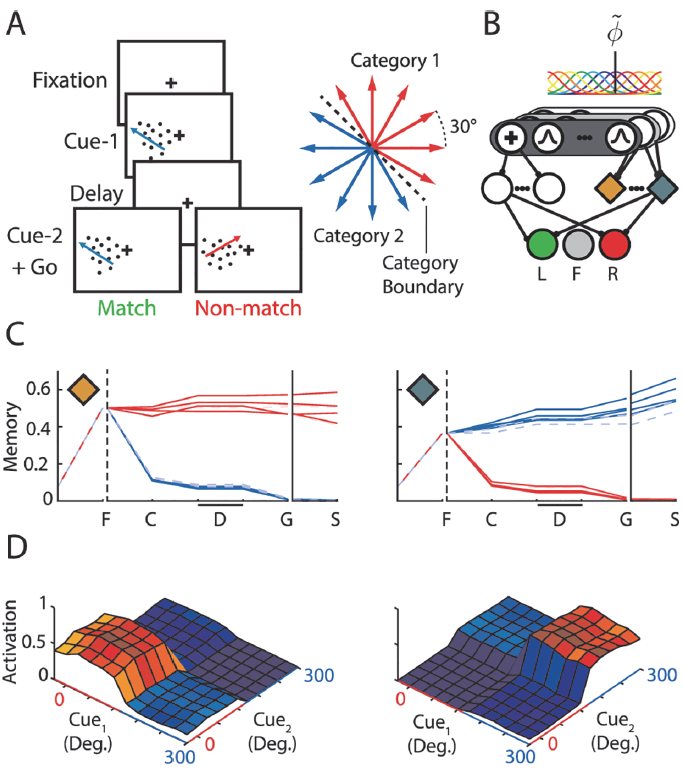
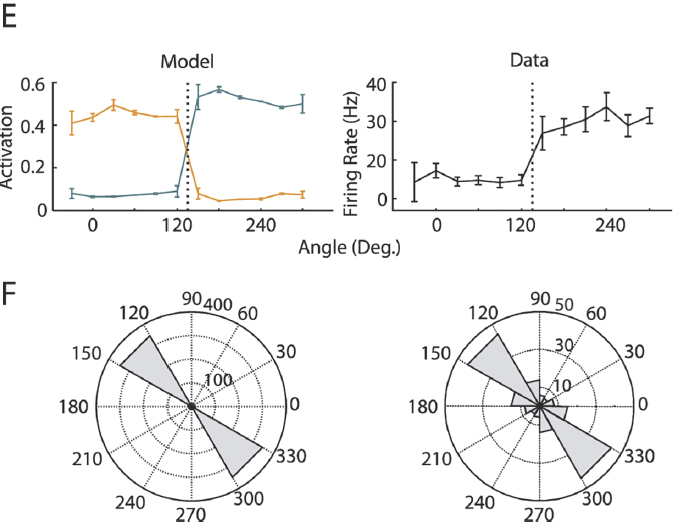
图3. 类别匹配任务。A,当网络将视线引向注视点时,我们提出了运动刺激(提示1),并在延迟后出现了第二个运动刺激(提示2)。当两个刺激属于同一类别(匹配)时,网络必须向左扫视;否则,则需要向右扫视。有十二个运动方向,分为两个类别(右)。B,感觉层具有代表固视点的单元和具有圆形高斯调整曲线的20个单元(标准差为12度),首选方向均匀地分布在单位圆上。C,由十二个提示1方向引起的训练网络中两个示例记忆单元的活动。每行代表一个试验,颜色代表提示类别。对最接近分类边界的提示的响应以较浅颜色的虚线绘制。F,固定标记开始;C,提示1出现。D,延迟;G,提示2出现('Go'信号);S,扫视。D,对于所有12x12线索组合,在任务的'Go'阶段中与(C)中相同的两个示例记忆单元的活动。标签和轴的颜色表示提示类别。E,左,在记忆延迟结束时记忆单元(以C表示)进行运动调整。误差棒跨试验显示,垂直虚线表示类别边界。右,一个典型的LIP神经元的调整(来自[4]),误差线显示标准差。F,左,方向变化的分布引起了来自100个网络的记忆单元在响应方面的最大差异。右,方向变化的分布引起了LIP神经元的最大反应差异(来自[4])。
Delayed match-to-category task
如果训练动物区分刺激类别,则猴子联想皮层中神经元的选择性会发生变化。训练后,额叶[42]和顶叶皮质[4]中的神经元对相同类别的刺激反应相似,并区分不同类别的刺激。在一项研究中[4],猴子不得不将运动刺激分为两类,以完成"分类的延迟匹配"任务(图3A)。他们首先必须看一个固定点,然后出现运动刺激,并且在延迟后出现了第二个运动刺激。猴子的反应取决于这两种刺激是来自同一类别还是来自不同类别。我们研究了AuGMEnT是否可以训练与延迟扫视/反扫视任务的网络具有相同架构(在关联层具有3个常规单元和4个记忆单元)的网络来执行此分类任务。我们使用了一个输入层,该输入层的固定点为一个单元,而形式为![]() 的圆形高斯调整曲线有20个单元(首选方向θc均匀分布在单位圆上,标准差σ为12度(图3B))。这两个类别由将十二个运动方向(相邻的运动方向相隔30度)分成两组六个方向的边界定义。
的圆形高斯调整曲线有20个单元(首选方向θc均匀分布在单位圆上,标准差σ为12度(图3B))。这两个类别由将十二个运动方向(相邻的运动方向相隔30度)分成两组六个方向的边界定义。
我们首先等待,直到模型将视线引向注视点。固定后的两个时间步骤,我们展示了十二个运动提示之一(提示1)(一个时间步骤),并给出了固定奖励ri(图3A)。我们在运动方向(标准差为5度)上添加了高斯噪声,以模拟感觉系统中的噪声。在随后的持续两个时间步骤的记忆延迟期间,该模型必须保持固定。然后,我们提出了第二个运动刺激(提示2),并且模型必须根据提示类别之间的匹配情况进行眼睛移动(左右移动;在此任务中注视标记没有关闭)。如果两个刺激属于同一个类别,我们需要向左移动眼睛,否则,则需要在提示2之后的8个时间步骤内向右移动眼睛。我们训练了100个模型,并使用相同的提示1对之前的50个试验测量了准确性。我们将学习阶段的持续时间确定为试验,所有提示1类型的准确性均达到80%。
尽管其简单的前馈结构在关联层中只有七个单元,但AuGMEnT训练了网络以在11550次试验的中位数内进行所有模拟。图3C展示了训练网络中的两个示例性记忆神经元的运动调节。从提示开始到整个延误期,这两个单元都具有类别选择性。图3D显示了两个提示的所有144个组合在'Go'时间(即提示2提示之后)这些单元的活动。图3E展示了在延迟时段期间记忆单元的调整。对于模拟的每个记忆单元(N = 400),我们确定了引起活动差异最大的方向变化(图3F),发现对于跨越一个类别的运动方向差异,这些单元在活动方面表现出最大的变化,就像LIP中的神经元一样[4](图3E, F, 右)。因此,AuGMEnT可以训练网络执行分类的延迟匹配任务,并为那些重要的特征变化引入记忆调整。
图4. 概率分类任务。A,网络固定后,我们在四个位置以随机顺序展示了四个形状。形状s1, ..., s4暗示着红色或绿色目标的位置:在各个试验中,它们的位置随机变化。奖励以概率![]() 分配给红色目标,其中
分配给红色目标,其中![]() ,否则指向绿色目标。插图显示了与提示si相关的权重wi。B,感觉层在屏幕的每一侧具有用于固视点的单位,用于目标的颜色的单元,并且在四个视黄醛位置中的每一个处具有用于符号的一组单位。C,试验中两个上下文相关的记忆单元和Q值单元(底部)的活动,其中四个盾形符号被提供给训练好的网络。绿色目标是最佳选择。F:注视开始;D:记忆延迟;G:注视偏移('Go'信号)。
,否则指向绿色目标。插图显示了与提示si相关的权重wi。B,感觉层在屏幕的每一侧具有用于固视点的单位,用于目标的颜色的单元,并且在四个视黄醛位置中的每一个处具有用于符号的一组单位。C,试验中两个上下文相关的记忆单元和Q值单元(底部)的活动,其中四个盾形符号被提供给训练好的网络。绿色目标是最佳选择。F:注视开始;D:记忆延迟;G:注视偏移('Go'信号)。
Probabilistic decision making task
我们已经表明,AuGMEnT可以训练单个网络来执行延迟的扫视/反扫视任务或"按类别匹配"任务,并将与任务相关的信息保持为持久性活动。LIP区域的持续活动也与知觉决策相关,因为LIP神经元会随着时间将感觉信息整合到决策任务中[43]。AuGMEnT可以训练完全相同的网络来整合证据以进行感知决策吗?
我们专注于最近的一项研究[5],其中猴子看到了红色和绿色的扫视目标,然后依次出现了四个符号。四个符号提供了关于红色或绿色的眼动目标被奖励诱骗的概率证据(图4A)。一些符号提供了支持红色目标的有力证据(例如,图4A插图中的三角形),其他符号提供了绿色目标(七边形)的有力证据,而其他符号则提供了较弱的证据。选择的模式表明,猴子对携带有力证据的符号分配了较高的权重,对信息较少的符号分配了较低的权重。以前只有一层可修改突触的模型可以学习此任务的简化线性版本,其中符号为两个动作之一提供了直接证据[44]。该模型使用了预连接的记忆,它无法模拟整个任务,即符号仅带有关于红色和绿色选择的证据,而红色和绿色目标的位置在各个试验中都不同。在此,我们测试了AuGMEnT是否可以使用三个常规单元和四个记忆单元训练我们的网络以执行完整的非线性任务。
正如猴子实验[5]一样,我们使用一系列复杂度更高的任务通过塑造策略训练了模型。我们将首先描述任务的最复杂版本。在这个版本中,模型(图4B)必须首先将视线直接引到注视点。在固定了两个时间步骤之后,我们给出了固定奖励ri并给出了有色目标以及在固定记号周围四个位置之一处的10个符号之一。在随后的三个时间步骤中,我们给出了其他符号。我们随机分配了红色和绿色目标的位置,连续显示的符号的位置以及试验中的符号序列。在显示所有符号(s1, ... , s4)之后存在两个时间步骤的记忆延迟,然后我们移除了固定点,作为对一个彩色目标进行扫视的提示。奖励rf以概率![]() 分配给红色目标,其中
分配给红色目标,其中![]() (wi在图4A中指定,插图),否则指向绿色目标。如果模型选择了最高奖励概率的目标,则该模型的选择被认为是正确的;如果奖励概率相等,则该模型的选择被认为是正确的。但是,只有在模型选择诱饵目标时,才给出rf,无论其是否具有最高奖励概率。
(wi在图4A中指定,插图),否则指向绿色目标。如果模型选择了最高奖励概率的目标,则该模型的选择被认为是正确的;如果奖励概率相等,则该模型的选择被认为是正确的。但是,只有在模型选择诱饵目标时,才给出rf,无论其是否具有最高奖励概率。
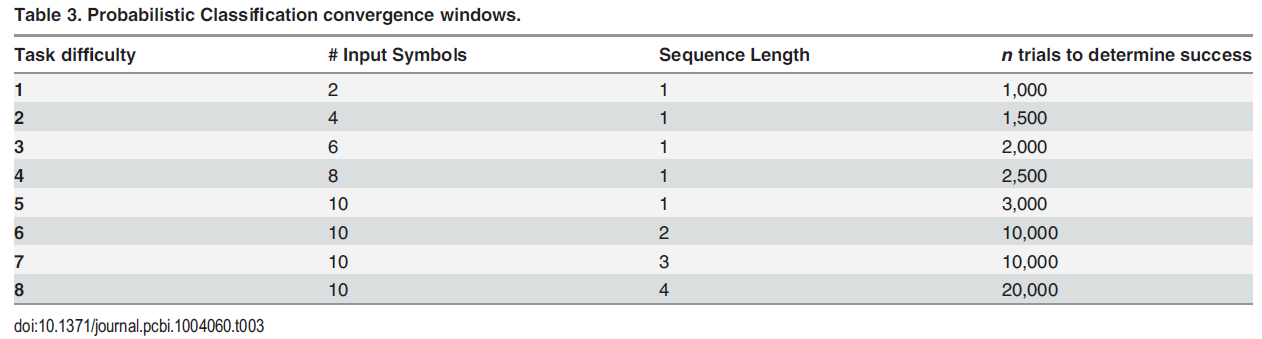
用于训练的塑造策略通过八个步骤逐渐增加了输入符号集(2, 4, ... , 10)和序列长度(1, ... , 4)(表3)。训练从两个"王牌"形状开始,这些形状保证了对正确决策的奖励(三角形和七边形,请参见图4A,插图)。我们认为,在前n次试验的成功率达到85%时,任务就已经学会了。随着可能的输入模式的数量增加,我们增加n以确保在确定收敛之前已经呈现了很大一部分可能的输入模式(请参见表3)。首先,通过添加具有下一个绝对权重的一对符号来增加难度,直到引入了所有形状(1-5级),然后增加序列长度(6-8级)。
通过这种塑造策略,AuGMEnT在总共500000次试验中成功地训练了100个网络中的99个。对模型进行标准训练(在最终任务中正确率达85%),在八个难度级别中总共进行了55234次试验,这比猴子学到的速度要快。在训练过程之后,记忆单元已经学会了将符号序列上红色或绿色选择的信息进行整合,并在记忆延迟期间将有关该选择的值的信息作为持久活动进行维护。图4C显示了在试验中示例网络的两个记忆单元和Q值单元的活动,其中屏蔽符号出现了四次,提供了有力的证据证明绿色目标被诱骗了。记忆单元对由红色和绿色扫视目标的位置确定的上下文敏感。如果绿色目标出现在右侧,则图4C第一行中的单元将为证据;如果绿色目标出现在左侧,则第二行中的单元将为证据。此外,随着更多证据的积累,这些记忆单元的活动逐渐增加。
LIP中神经元的活动与诱饵靶的对数似然相关[5]。为了研究对数似然度对记忆单元活动的影响,我们按以下方法计算了对数似然比(logLR)五分位数。我们枚举了所有10000个长度为4的符号组合s∈S,并计算了针对每个红色组合的扫视奖励目标的概率P(R|S)。接下来,我们针对长度为l∈{1, ... , 4}的序列sl计算奖励的条件概率P(R|sl)和P(G|sl) = 1 - P(R|sl)(边缘化在未被观察到的符号上)。然后,我们针对长度为 l 的每个特定序列,将LogLR(sl)计算为log10(P(R|sl)/P(G|sl)),并将其分为五分位数。
为了确定记忆单元的活动如何取决于目标被诱捕的对数可能性,我们首先观察下五分位数和上五分位数的完整序列,然后比较五分位数,以便每个单元增加它们的平均活动,然后比较它们的平均活动。然后,我们计算了对齐群体的平均五分位数内活动。图5A的上部面板显示了示例网络的四个记忆单元的平均活动如何取决于诱饵目标的对数可能性,下部面板显示了用于比较的LIP数据[5]。可以看出,记忆单元的活动与对数似然相关,就像LIP神经元一样。重要的是,从输入神经元到记忆细胞的突触权重取决于学习后符号的真实权重(图5B)。如图5C所示,该相关性在总体水平上也很强,该图显示了所有相关系数的分布(N = 396)。因此,突触在记忆神经元上的可塑性可以解释猴子如何评估符号,而AuGMEnT可以解释这些神经元如何学习整合最相关的信息。此外,我们的结果表明,AuGMEnT不仅训练关联单元以整合随机感官证据,而且还赋予它们针对解决此非线性任务所需的针对目标颜色和符号序列的所需混合选择性。
Vibrotactile discrimination task
先前的模拟解决了已用于研究猴子LIP区域神经元的任务。 我们的最后一次模拟研究了一项已用于研究触觉工作记忆的任务[6,45]。 在此任务中,猴子用一只手触摸按键,然后将两个振动刺激顺序施加到另一只手的指尖上(图6A)。 猴子必须指出第一振动刺激(F1)的频率是高于还是低于第二振动刺激(F2)的频率。 在试验结束时,动物通过释放键并按下两个按钮之一来表明其选择。 任务的总体结构与上述视觉任务的总体结构相似,但此处感兴趣的功能是它需要在两个标量值之间进行比较。 手指上感应到的F2和必须保留在工作内存中的F1。
最近的计算工作已经解决了触觉辨别任务的各个方面。 几个模型讨论了神经网络模型如何存储F1并将其与F2比较[46-48]。 最近,Barak等人。 [49]研究了在使用三种不同的监督学习方法训练的网络中记忆状态的动态,并将其与神经元数据进行了比较。 但是,这些先前的研究尚未通过生物学上合理的学习规则解决试触法对触觉辨别任务的学习。 因此,我们研究了AuGMEnT是否可以用三个常规单元和四个存储单元来训练用于LIP的同一网络来解决此任务。
输入层是在猴子的感觉区域S2之后建模的。 在该皮质区域中的神经元具有宽的调谐曲线,并根据触觉刺激频率单调增加或降低其放电速率[50]。 该模型的输入单元具有S形调整曲线r(x)= 1 /(1 + exp(w(θc-x))),其中10个中心点θc均匀分布在5.5Hz和49.5Hz之间的间隔内。 我们在每个θc处使用一对单位,其中一个单位随着刺激频率增加其活动性,而另一个则减少,因此总共有20个输入单位。 参数w确定调谐曲线的陡度,为+ / 5。 我们通过将独立的零均值高斯噪声(标准偏差7.5%)添加到输入单元的发射率上来对感官噪声进行建模。 我们还包括一个二进制输入单元,该信号表明皮肤与刺激装置接触(图6B中的单元S)。 关联层和Q值层与其他模拟的层相同(图6B)。
我们的第一个仿真处理了任务的版本,其中F1因试验而异[6]。 当指示皮肤与振动探针接触的输入单元激活并且模型必须在十个时间步内选择保持键时,试验开始,否则试验将终止。当模型在两个时间步长上把握了关键点时,将振动刺激(F1,在5到50 Hz之间均匀随机)呈现给网络一个时间步长,并给出较小的整形奖励(ri)。 接下来是记忆延迟,之后我们提出了第二个振动刺激(F2),它是从5到50 Hz之间的均匀分布得出的,但与F1的最小间隔为2 Hz。 如果F2低于F1,则模型必须在呈现F2之后的八个时间步中选择左按钮(图6B中的绿色Q值单位),否则选择右按钮(红色),以获得奖励rf。
为了确定模型的性能,我们将F1刺激的范围划分为9个5 Hz的仓,并跟踪每个仓在50次试验中的性能平均值。 当模型对每个F1达到80%的性能时,我们将禁用学习和探索(将学习参数β和ε设置为零),并针对20、30和40 Hz的F1刺激以及偏移为的F2刺激检查模型的性能。 [-10,-8,。 。 。,-2,2,。 。 。,8,10] Hz,重复每个测试20次。 如果模型对每个F1箱分类了最接近的F2频率(2 Hz距离),其最小精度为50%,而所有其他F2频率的精度高于75%,则我们认为学习是成功的。
AuGMEnT对所有100个模拟网络进行了训练,以在3,036个试验的中位数内进行标准评估。图7C示出了对于三个F1值以及对数据拟合的逻辑函数,这100个训练模型的平均选择(±s.d。)作为F2的函数[如在图6中]。 可以看出,该模型正确地指示F1是高于还是低于F2,并且该标准取决于值F1,这意味着该模型已学会将模拟标量值存储在其工作存储器中。 学习过程中出现了哪些记忆表征? 图6D示出了示例网络中的两个存储器单元的F1调谐。 通常情况下,音调是宽泛的,并且可以随F1的变化而增加或减小,类似于在猴子的额叶皮层中进行的实验[51]。 图6E示出了在100个训练网络中的400个存储单元与F1频率之间的线性相关性分布。 大多数单元表现出很强的正或负相关性,表明网络学会了将F1的存储器编码为存储单元的持久触发级别。
接下来,我们研究了该模型如何执行在提交F2之后必须进行的比较过程。 这个比较过程主要取决于两种刺激的表现顺序,但是它涉及通过相同的感觉输入和关联单元输入的信息[48]。 我们发现在比较期间,存储单元的确对F1和F2敏感。 图6F显示了两个示例存储单元和三个Q值单元对于F1为20或30 Hz的试验,然后是频率比F1高5Hz(实线)或低于F1的F2的响应 (虚线)。 存储单元的活动在存储延迟期间对F1进行编码,但是这些单元也对F2作出响应,因此在显示F2之后的活动取决于两个频率。 下部面板说明了Q值单位的活动。 直到显示F2为止,保持Q值单位(H,蓝色)的活动最高,从而导致模型按住关键点直到发出信号。 该部门没有区分需要按右键或按左键的试验。 左右按钮按下时Q值单位的活动(红色和绿色轨迹)说明了网络在go信号处如何做出正确的决策,因为适当动作的Q值最高(图1中的实线)。 图6F示出了如果F2> F1并且虚线F2 <F1)的活动。 例如,可以看出,由25Hz的F2在Q值层中引起的响应如何取决于先前的F1是20Hz(图6F左面板中的连续曲线)还是30Hz(图6F左侧的虚线)。 右侧面板)。
接下来,我们使用所有试验对来自100个网络(分别为N = 400、300和300个单位)的记忆,正则和Q值单位的活动度在回归阶段进行回归[见52]进行定量分析,以确定它们如何依赖于F1和F2。 呈现F2刺激的位置,以及5到50 Hz之间的两个频率的所有组合(步长为1Hz),

在此,a1和a2分别估算了单位活动对F1和F2的依赖性。 许多存储单元的活动取决于F1,也取决于F2(图6G,左),系数之间的总体负相关性(r = -0.81,p <10-6)表明,对于以下内容,单元倾向于更强烈地响应 就像在区域S2,猴子的前额叶皮层和内侧运动前皮层中观察到的那样,增加F1倾向于降低其对增加F2的响应,反之亦然[45,51,52]。 换句话说,根据此任务的要求,在比较阶段,许多存储单元已调整到F1和F2之间的差异。 尽管F1和F2会以相同的突触激活存储单元,但由于在比较阶段F1刺激已关闭并激活了感官层中的离单元,因此可能进行反向调整。 相比之下,F2刺激在任务的此阶段仍处于“打开”状态,因此编码F2的下级单位尚未将其输入提供给存储单元。 结果,存储单元的最终活动可以反映出任务所要求的F1和F2之间的差异。 常规单位只能访问当前刺激,因此只能在比较阶段将其调整为F2(图6G,中间)。 Q值单位反映了比较过程的结果(图6G,右):如所需动作所预测的,它们的F1和F2回归系数分为三类。
上述任务的版本要求在两个颤振频率之间进行比较,因为F1因试验而异。 埃尔南德斯(Hernández)等。 [6]还研究了任务版本,其中F1被固定进行了一系列试验。 在此版本中,猴子仅根据F2做出反应,而没有记住F1。 结果,在使用不同F1的新试验开始时,它们的性能下降了。 经过AuGMEnT培训的网络也只记住与任务相关的信息。 如果在培训期间固定了F1,则用AuGMEnT培训的网络也不会记住F1吗? 为了研究这个问题,我们训练了固定F1为30 Hz的模型[6],并提出了5-5 Hz(2.5 Hz间隔)范围内的F2刺激,距F1的最小距离为10 Hz。 当准确性达到90%(50个试验的运行平均值)时,我们估计该试验为收敛性。
AuGMEnT对所有100个网络进行了培训,以在1,390个试验的中位数范围内完成这项更简单的任务。 在学习了固定的F1任务后,我们按照[6]的要求对网络进行了20、30和40 Hz的F1刺激的块训练,而我们提出的F2刺激的频率为[[-10,-8,...,- 相对于F1为2,2,... ,, 8,10] Hz(共10个,每个显示150次)这些试验块具有伪随机顺序,但我们总是在最后一个块中给出30Hz F1。当我们在每个块之后立即进行测试时,我们发现这些模型能够很好地适应特定的F1。 但是,即使经过大量的F1刺激,这些模型也无法在经过广泛的街区训练后解决可变的F1任务。图6I显示了F1 = 30Hz的最后一个块之后100个网络的平均心理测度曲线。 颜色代表具有不同F1刺激的试验(如图6C所示)。 可以看出,这些模型忽略了F1并仅确定F2是高于还是低于30 Hz,就像猴子是通过阻塞程序训练的一样[6]。 因此,该模型可以解释为什么如果F1固定用于更长的试验块,猴子就不会学会比较这两种刺激。现在,存储器单元和Q值单元对F1和F2进行了相似的调整,而不是相反的调整(图6H的左右面板为正相关;与图6G相比为正相关),这表明训练受阻会导致训练失败。 学习从F2的表示中减去F1的存储轨迹。
我们得出结论,AuGMEnT能够在需要比较两个模拟刺激以及正确决定取决于刺激顺序的任务上训练网络。 记忆单元学会代表需要作为持续活动的分级级别存储的模拟值。 但是,如果将F1固定用于试验块,则网络不会记住F1,而是根据实验结果学习仅将其决定基于F2。
Varying the learning parameters and the size of the network
值得注意的是,AuGMEnT可以训练同一个简单的网络来执行广泛的任务,只需在适当的时候提供奖励即可。 在上述模拟中,我们固定了关联层和Q值层中的单位数,并使用了一组学习参数。 为了检验学习方案的稳定性,我们还针对学习率β和SARSA学习参数λ(如上文所述,因为α=1-λγ决定了标签衰减参数α)的各种值,评估了学习速度和收敛速度。 ,将γ保留为默认值)。 对于扫视/反扫视,类别匹配和触觉辨别任务,我们测试了β2{0.05,0.10,,1.0}和λ2{0.0,0.1,,0.9},而其他参数保持不变( 表1,2),并针对每种组合进行了100次仿真。 图7显示了收敛网络的比例和中值收敛试验。 概率分类任务的训练需要许多不同的训练阶段,并且需要更长的总体训练时间,因此我们使用较少的参数集对该任务进行了评估(图7,右)。 大多数网络汇聚在一起的学习参数范围很广,并且对于四个任务来说这些范围重叠,这表明AuGMEnT学习方案相对稳定可靠。
到目前为止,我们的模拟使用的固定网络在关联层中只有7个单元。 AuGMEnT还能训练具有更大关联层的网络吗? 为了进一步研究学习方案的一般性,我们进行了一系列模拟,其中关联单元的数量不断增加,将上述网络中的关联单元的数量乘以2、4,...。 。 ,在扫视/反扫视任务中分别训练128个网络,并训练100个不同大小的网络。 我们首先在不更改学习参数的情况下评估了这些较大的网络,发现在有限的网络大小范围内,学习在很大程度上不受影响,而对于32-128倍大的网络,性能却下降了(图8A)。 性能的下降很可能是由大量的突触引起的,与较小的网络相比,每个时间步长后导致对Q值的较大调整。 可以通过选择较小的β(学习率)和λ来补偿这种影响。我们将这些参数共同缩放1 2; 1 4和1 8并选择参数组合,对于每个网络大小,该组合都会导致最高的收敛速度和最快的中值收敛速度(图8B)。 如果按比例缩放学习参数,则较大网络的性能至少与具有7个单元的网络的性能一样好。 因此,AuGMEnT也可以成功地训练具有更大关联层的网络。
Discussion
AuGMEnT提供了一个新的理论框架,可以解释在试错学习过程中,神经元如何在顺序决策任务中如何调节到相关的感觉刺激。 该方案使用的单元受感官皮质中的瞬时和持续神经元启发[19],额叶皮层,基底神经节和中脑[12,35,36]的动作值编码神经元以及将记忆输入整合到联想皮层中的具有记忆功能的神经元。 据我们所知,AuGMEnT是第一个在生物学上似乎可行的学习方案,该方案在配有工作记忆的多层神经网络中实现SARSA。 该模型很简单,但能够学习各种艰巨的任务,这些任务需要非线性的感觉-运动转换,决策,分类和工作记忆。 AuGMEnT可以通过提供适当的感官输入和奖励意外事件来训练完全相同的网络来执行这些任务中的任一个,并且其学习的表示类似于在接受这些任务训练的动物中发现的表示。AuGMEnT是一种所谓的基于策略的方法,因为它仅依赖于网络在学习过程中遇到的Q值。 如果与神经网络结合使用,这些策略上的方法似乎比策略外的算法(例如Q学习,考虑了网络未经历的过渡)更稳定(请参见[53,54])。
AuGMEnT为需要记住的功能形成内存表示。 在延迟的扫视/反扫视任务中,训练会诱导持续的神经元活动,使其调整到提示位置和固定点的颜色,但前提是相关。 在分类任务中,单位对类别边界变得敏感,而在决策任务中,单位将感官证据与权重相结合,以获得更可靠的输入。 这些特性类似于猴子的LIP [2-5]和额叶皮层[24]中的神经元。 最终,记忆单元学会了在触觉任务中记忆和比较模拟值,就像在猴子的额叶皮层中观察到的一样[6,45]。
AuGMEnT做出了许多可以在未来的神经科学实验中检验的预测。第一个也是最重要的预测是,反馈连接通过诱导突触标签来控制连接的可塑性。 具体来说,该学习方案预测反馈连接对于在前馈连接上感应从感觉皮层到缔合皮层的标签的感应非常重要(图1B)。 第二个预测是突触中存在具有持续活动(即记忆单元)的神经元的痕迹,一旦来自响应选择阶段的反馈到达,神经元就会转化为标签,可能会在以后的某个时间点发生。 第三个预测是这些标签与全局释放的神经调节剂(例如多巴胺,乙酰胆碱或5-羟色胺)相互作用,它们决定突触变化(增强或抑制)的强度和体征。 这些标签的存在及其与神经调节物质的相互作用的神经生物学证据将在下面讨论。 最终的预测是,静止刺激会向具有持续活动的神经元提供瞬时输入。结果,较长时间可见的刺激不一定会导致活动增加。在我们的网络中,由于内存单元仅从“ on”和“ off”输入单元接收输入,因此可以防止斜坡上升。 但是,我们注意到,其他机制,例如将突触快速适应到存储单元上,也可以达到相同的效果。 相反,只要存在刺激,预计没有持续活动的缔合皮层神经元将接受连续输入。 这些具体的预测都可以在未来的神经科学工作中得到检验。
Role of attentional feedback and neuromodulators in learning
AuGMEnT实施四要素学习规则。 前两个因素是单元的突触前和突触后活动,还有两个附加的“门控因子”使突触可塑性增强。第一个门控因素是来自马达层中对所选动作进行编码的单元的反馈。 这些单元将注意力信号发送回较早的处理级别,以标记负责选择此动作的突触。 选择性心理学对学习的重要性得到了认知心理学实验的支持。 如果观察者为某项动作选择了刺激,注意力就会始终转移到这种刺激上[55],而这种选择性的注意信号会控制感知学习,从而使参加活动的对象对未来的行为产生更大的影响[56-58]。 此外,神经生理学研究表明存在这种反馈信号,因为运动皮层中编码动作的神经元会增强上游神经元的活动,从而为该动作提供输入[59,60]。
第二个使可塑性增强的门控因素是一个全局神经调节信号,该信号将RPE广播到许多大脑区域,并确定已标记的突触变化的信号和强度。 多巴胺经常被牵连,因为如果奖励期望值增加,多巴胺就会释放,并且会影响突触可塑性[10,38]。 乙酰胆碱也有潜在的作用,因为胆碱能细胞扩散地投射到皮层,对奖赏作出反应[61-63]并影响突触可塑性[61,64]。 此外,最近的一项研究表明,血清素能神经元也携带着奖励预测信号,并且血清素能神经元的光遗传学激活可以起到积极的增强作用[65]。通过神经调节信号和皮质皮质反馈连接的结合来指导突触可塑性是生物学上可行的,因为突触更新的所有信息都可在突触处获得。
Synaptic tags and synaptic traces
AuGMEnT中的学习取决于突触标签和痕迹。 突触可塑性在记忆细胞上的第一步是形成突触痕迹,一直持续到试验结束(图1C)。 第二步是迹线转化为一个标签,当所选择的马达单元反馈到存储单元。 最后一步是释放修饰标记突触的神经调节剂。 到常规(即非内存)关联单元上的突触的学习规则是相似的(图1B),但是标签直接在主动突触上形成,跳过了第一步。 但是,我们注意到,如果这些突触也具有在一个时间步长内衰减的痕迹,则会获得相同的学习规则。 突触可塑性需要一系列事件的假说[66,67]得到了突触复杂生物化学机制的支持。有突触标签的证据[15,31,32],最近的研究已经开始阐明它们的身份[32]。 即使在可塑性诱导事件[15,17,32]之后几秒或几分钟内释放,神经调节信号也会影响突触可塑性[15,17,32],这支持了它们与某种形式的标签相互作用的假说。
Comparison to previous modeling approaches
在具有激发神经元的生物启发式强化学习模型中[68-71],以及在连续变量的情况下近似人口活动的模型[14,16,21,44,67,72-74],已经取得了实质性进展。 许多模型依赖于Actor-Critic学习[7]或策略梯度学习[75]。 Actor-Critic模型的一个优点是模型组件与大脑区域有关[16,71,73]。 AuGMEnT具有这些模型的共同特征。 例如,它使用Q值的变化来计算RPE(等式(17))。 通过策略梯度学习方法[68,75]形成了另一类广泛使用的模型类别,其中单位(或突触[68])充当试图增加全球奖励的本地代理。 这些模型的优点是学习不需要了解单元对网络中其他单元的影响,但是缺点是学习过程无法很好地扩展到大型网络,在大型网络中本地活动与全球奖励之间的相关性是 弱[70]。 AuGMEnT使用来自选定动作的“注意”反馈来改善倾向性[14],它也可以推广到多层网络。 因此,它减轻了许多以前生物学上似乎合理的RL模型的局限性,这些模型只能训练单层可修改的突触权重并解决线性任务[16,21,44,67,70,71,73,76]和二元决策[21]。 ,44,67,70]。
与这些先前的模型不同,AuGMEnT是行动价值学习的模型(SARSA(λ)[7])。 它与以前的许多模型不同之处在于,它无需预先接线即可训练与任务相关的工作记忆表示的能力。 我们将记忆单元建模为积分器,因为在许多皮质区域中发现了在记忆延迟期间充当积分器并维持其活动的神经元[2-5,23,24]。 为了使模型简单,我们没有指定导致持续活动的机制,这种机制可能来自于跨皮质,丘脑和基底神经节的较大网络中的细胞内过程,局部回路混响或循环活动[20-22]。
一些研究在RL中包含了预先连接的工作记忆[21,44],但是在生物学上对新记忆的合理学习方面的工作相对较少。 早期的神经网络模型使用“时间反向传播”,但其机制在生物学上是不可信的[77]。 长短期记忆模型(LSTM)[78]是一种较新的流行方法。 LSTM中的工作内存依赖于内存单元的持久活动,类似于AuGMEnT所使用的活动。 但是,LSTM依靠生物学上难以置信的错误反向传播规则。 据我们所知,只有一个先前的模型通过神经生物学启发的学习方案解决了工作记忆的创建,即额叶基底神经节前工作记忆模型(PBWM)[72],这是Leabra认知架构的一部分[79,80]。 尽管AuGMEnT和Leabra的详细比较超出了本文的范围,但是提及一些关键区别还是很有用的。 首先,Leabra / PBWM框架的复杂性和详细程度要高于AuGMEnT。 PBWM框架使用十多个模块,每个模块都有自己的动态和学习规则,从而使形式分析变得困难。 我们选择使使用AuGMEnT训练的模型尽可能简单,以使学习更容易理解。 AuGMEnT的简单性是有代价的,因为许多功能仍然是抽象的(请参阅下一节)。 其次,PBWM模型使用教师来通知模型正确的决策,即它使用的信息不只是奖励反馈。 第三,PBWM是一种行为批评体系,可以学习状态的价值,而AuGMEnT可以学习行为的价值。 第四也是最后,工作记忆的机制存在重要差异。 在PBMW中,存储单元是双稳态的,模型配备了一个系统,可通过基底神经节控制前额叶皮层中的信息。 在AuGMEnT中,存储单元由输入层中的打开和关闭单元直接激活,并且它们具有连续的活动级别。 在AuGMEnT中,存储单元的活动配置文件取决于任务。 它可以训练存储单元,以整合概率决策的证据,将模拟值存储为持续活动的分级级别,还可以将具有几乎二进制响应的类别存储在延迟的类别匹配任务中。
Biological plausibility, biological detail and future work
我们认为AuGMEnT在生物学上是合理的,但是这句话是什么意思呢?我们的目标是提出一种基于Hebbian可塑性的学习规则,该规则受两个已知可控制可塑性的因素控制:一个在全球范围内释放并编码奖励预测误差的神经调节信号,以及一个突出显示网络部分的注意力反馈信号, 对行动的结果负责。 我们表明,这两个因素的组合(实际上可以在单个突触的水平上使用)可以导致突触强度的变化,该强度随网络经历的转换的奖励预测误差的梯度下降而下降。 同时,本模型仅提供有限程度的细节。 这种更抽象的模型的优点是它在数学上仍然易于处理。 不利的一面是,需要更多的工作来将建议的机制映射到特定的大脑结构上。 我们指出了在关联层中发展的调整与猴子的关联皮层中的调整之间的对应关系。现在,我们列出了一些我们做出的简化假设,而这些未来假设需要通过纳入更多生物学细节的未来模型来缓解。
首先,我们假设大脑可以计算SARSA时差误差,这意味着一个状态-动作组合的Q值与下一个组合的Q值之间的比较。 未来的建模研究可能包括大脑结构,用于存储先前选择的动作的Q值,同时计算新的动作值。 尽管我们不知道存储动作值的大脑结构集合,但先前的研究暗示内侧和外侧前额叶皮层在存储与动作相关的结局中[81,82]。 在试验过程中,随着新信息的出现,前额神经元甚至会更新预测结果[83]。 Actor-Critic体系结构提供了一种存储Q值的替代方法,该体系结构将值分配给各种状态,而不是状态-动作组合。 他们使用一个网络来估计状态值,并使用另一个网络来选择动作[16]。 有趣的是,[16]提出基底神经节可以通过比较间接路径中的活动来计算时间差异误差,间接路径中的活动可以存储上一个时间步的预测值,而直接路径中的活动可以编码下一个时间步长的预测值。 状态。 我们假设可以使用类似的电路来计算SARSA时间差异误差。 另外,我们也没有对动作选择过程本身进行建模,这被认为是在基底神经节中发生的(见[30])。
第二个简化是,我们没有将模型单位限制为抑制性的或兴奋性的—输出权重可以具有任一个符号,甚至在学习过程中它们甚至可以改变符号。 未来的研究可能会指定权重受约束的更详细的网络架构(例如[如72])。 确实,有可能将具有兴奋性和抑制性的网络改变为功能上等效的网络,而兴奋性和抑制性单元仅具有正的权重[84],但是像AuGMEnT这样的学习规则的必要概括将需要额外的工作。
第三个主要简化是AuGMEnT中的反馈连接会影响突触标签的形成,但不会影响较早处理级别的单位的活动。未来的研究可能包括反馈连接,这些连接也会影响较低层中单元的活动,并为传播反馈连接的活动的可塑性开发学习规则。如果经过反复试验,这些连接可能会进一步扩展神经网络可以完成的任务集。 在这种情况下,有趣的是,先前的研究表明,活性的前馈传播主要利用AMPA受体,而反馈作用更多地依赖于NMDA受体[85],NMDA受体在突触可塑性中起重要作用。 NMDA受体还在下部区域修饰神经元活动,另一个可能在反馈连接对可塑性的影响中具有特定作用的候选受体是代谢型谷氨酸受体,其在反馈途径中很显着[86,87]并已知会影响突触可塑性。 [88]。
第四个简化是,我们以离散步骤对时间建模,并使用了具有标量活动级别和可区分的激活函数的单位。 因此,在连续时间内使用尖峰神经元群体实现AuGMEnT值得研究。 我们将必要的生物学细节集成到类似AuGMEnT的网络中,这将减轻所有这些简化工作,从而简化未来的工作。
Conclusions
在此,我们已经证明,突触标签和神经调节信号之间的相互作用可以解释“多需求”关联区域中的神经元如何获取助记符信号,以完成明显分散的任务,这些任务需要工作记忆,分类或决策。 可以通过反复试验来训练单个网络来执行这些不同任务的发现意味着,这些学习问题现在适合于统一的强化学习框架。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号