BindsNET学习系列 —— LearningRule
相关源码:bindsnet/bindsnet/learning/learning.py
1、LearningRule
class LearningRule(ABC): # language=rst """ Abstract base class for learning rules. """ def __init__( self, connection: AbstractConnection, nu: Optional[Union[float, Sequence[float]]] = None, reduction: Optional[callable] = None, weight_decay: float = 0.0, **kwargs ) -> None: # language=rst """ Abstract constructor for the ``LearningRule`` object. :param connection: An ``AbstractConnection`` object. :param nu: Single or pair of learning rates for pre- and post-synaptic events. :param reduction: Method for reducing parameter updates along the batch dimension. :param weight_decay: Constant multiple to decay weights by on each iteration. """ # Connection parameters. self.connection = connection self.source = connection.source self.target = connection.target self.wmin = connection.wmin self.wmax = connection.wmax # Learning rate(s). if nu is None: nu = [0.0, 0.0] elif isinstance(nu, float) or isinstance(nu, int): nu = [nu, nu] self.nu = torch.zeros(2, dtype=torch.float) self.nu[0] = nu[0] self.nu[1] = nu[1] # Parameter update reduction across minibatch dimension. if reduction is None: if self.source.batch_size == 1: self.reduction = torch.squeeze else: self.reduction = torch.sum else: self.reduction = reduction # Weight decay. self.weight_decay = 1.0 - weight_decay if weight_decay else 1.0 def update(self) -> None: # language=rst """ Abstract method for a learning rule update. """ # Implement weight decay. if self.weight_decay: self.connection.w *= self.weight_decay # Bound weights. if ( self.connection.wmin != -np.inf or self.connection.wmax != np.inf ) and not isinstance(self, NoOp): self.connection.w.clamp_(self.connection.wmin, self.connection.wmax)
学习规则的抽象基类,可以包括权重衰减和权重截断。
2、NoOp(没有效果的学习规则)
class NoOp(LearningRule): # language=rst """ Learning rule with no effect. """ def __init__( self, connection: AbstractConnection, nu: Optional[Union[float, Sequence[float]]] = None, reduction: Optional[callable] = None, weight_decay: float = 0.0, **kwargs ) -> None: # language=rst """ Abstract constructor for the ``LearningRule`` object. :param connection: An ``AbstractConnection`` object. :param nu: Single or pair of learning rates for pre- and post-synaptic events. :param reduction: Method for reducing parameter updates along the batch dimension. :param weight_decay: Constant multiple to decay weights by on each iteration. """ super().__init__( connection=connection, nu=nu, reduction=reduction, weight_decay=weight_decay, **kwargs ) def update(self, **kwargs) -> None: # language=rst """ Abstract method for a learning rule update. """ super().update()
没有效果的学习规则(默认),直接继承自学习规则的抽象基类。
3、PostPre(STDP的在线实现)
class PostPre(LearningRule): # language=rst """ Simple STDP rule involving both pre- and post-synaptic spiking activity. By default, pre-synaptic update is negative and the post-synaptic update is positive. """ def __init__( self, connection: AbstractConnection, nu: Optional[Union[float, Sequence[float]]] = None, reduction: Optional[callable] = None, weight_decay: float = 0.0, **kwargs ) -> None: # language=rst """ Constructor for ``PostPre`` learning rule. :param connection: An ``AbstractConnection`` object whose weights the ``PostPre`` learning rule will modify. :param nu: Single or pair of learning rates for pre- and post-synaptic events. :param reduction: Method for reducing parameter updates along the batch dimension. :param weight_decay: Constant multiple to decay weights by on each iteration. """ super().__init__( connection=connection, nu=nu, reduction=reduction, weight_decay=weight_decay, **kwargs ) assert ( self.source.traces and self.target.traces ), "Both pre- and post-synaptic nodes must record spike traces." if isinstance(connection, (Connection, LocalConnection)): self.update = self._connection_update elif isinstance(connection, Conv2dConnection): self.update = self._conv2d_connection_update else: raise NotImplementedError( "This learning rule is not supported for this Connection type." ) def _connection_update(self, **kwargs) -> None: # language=rst """ Post-pre learning rule for ``Connection`` subclass of ``AbstractConnection`` class. """ batch_size = self.source.batch_size # Pre-synaptic update. 突触前脉冲发放时基于突触后迹更新突触权重(下降) if self.nu[0]: source_s = self.source.s.view(batch_size, -1).unsqueeze(2).float() target_x = self.target.x.view(batch_size, -1).unsqueeze(1) * self.nu[0] self.connection.w -= self.reduction(torch.bmm(source_s, target_x), dim=0) del source_s, target_x # Post-synaptic update. 突触后脉冲发放时基于突触前迹更新突触权重(上升) if self.nu[1]: target_s = self.target.s.view(batch_size, -1).unsqueeze(1).float() * self.nu[1] source_x = self.source.x.view(batch_size, -1).unsqueeze(2) self.connection.w += self.reduction(torch.bmm(source_x, target_s), dim=0) del source_x, target_s super().update() def _conv2d_connection_update(self, **kwargs) -> None: # language=rst """ Post-pre learning rule for ``Conv2dConnection`` subclass of ``AbstractConnection`` class. """ # Get convolutional layer parameters. out_channels, _, kernel_height, kernel_width = self.connection.w.size() padding, stride = self.connection.padding, self.connection.stride batch_size = self.source.batch_size # Reshaping spike traces and spike occurrences. source_x = im2col_indices( self.source.x, kernel_height, kernel_width, padding=padding, stride=stride ) target_x = self.target.x.view(batch_size, out_channels, -1) source_s = im2col_indices( self.source.s.float(), kernel_height, kernel_width, padding=padding, stride=stride, ) target_s = self.target.s.view(batch_size, out_channels, -1).float() # Pre-synaptic update. if self.nu[0]: pre = self.reduction( torch.bmm(target_x, source_s.permute((0, 2, 1))), dim=0 ) self.connection.w -= self.nu[0] * pre.view(self.connection.w.size()) # Post-synaptic update. if self.nu[1]: post = self.reduction( torch.bmm(target_s, source_x.permute((0, 2, 1))), dim=0 ) self.connection.w += self.nu[1] * post.view(self.connection.w.size()) super().update()
简单的STDP规则,包括突触前和突触后的脉冲活动。默认情况下,突触前更新为负(-学习率1 × 突触前脉冲 × 突触后发放迹),突触后更新为正(学习率2 × 突触前发放迹 × 突触后脉冲)。
4、WeightDependentPostPre
class WeightDependentPostPre(LearningRule): # language=rst """ STDP rule involving both pre- and post-synaptic spiking activity. The post-synaptic update is positive and the pre- synaptic update is negative, and both are dependent on the magnitude of the synaptic weights. """ def __init__( self, connection: AbstractConnection, nu: Optional[Union[float, Sequence[float]]] = None, reduction: Optional[callable] = None, weight_decay: float = 0.0, **kwargs ) -> None: # language=rst """ Constructor for ``WeightDependentPostPre`` learning rule. :param connection: An ``AbstractConnection`` object whose weights the ``WeightDependentPostPre`` learning rule will modify. :param nu: Single or pair of learning rates for pre- and post-synaptic events. :param reduction: Method for reducing parameter updates along the batch dimension. :param weight_decay: Constant multiple to decay weights by on each iteration. """ super().__init__( connection=connection, nu=nu, reduction=reduction, weight_decay=weight_decay, **kwargs ) assert self.source.traces, "Pre-synaptic nodes must record spike traces." assert ( connection.wmin != -np.inf and connection.wmax != np.inf ), "Connection must define finite wmin and wmax." self.wmin = connection.wmin self.wmax = connection.wmax if isinstance(connection, (Connection, LocalConnection)): self.update = self._connection_update elif isinstance(connection, Conv2dConnection): self.update = self._conv2d_connection_update else: raise NotImplementedError( "This learning rule is not supported for this Connection type." ) def _connection_update(self, **kwargs) -> None: # language=rst """ Post-pre learning rule for ``Connection`` subclass of ``AbstractConnection`` class. """ batch_size = self.source.batch_size source_s = self.source.s.view(batch_size, -1).unsqueeze(2).float() source_x = self.source.x.view(batch_size, -1).unsqueeze(2) target_s = self.target.s.view(batch_size, -1).unsqueeze(1).float() target_x = self.target.x.view(batch_size, -1).unsqueeze(1) update = 0 # Pre-synaptic update. if self.nu[0]: outer_product = self.reduction(torch.bmm(source_s, target_x), dim=0) update -= self.nu[0] * outer_product * (self.connection.w - self.wmin) # Post-synaptic update. if self.nu[1]: outer_product = self.reduction(torch.bmm(source_x, target_s), dim=0) update += self.nu[1] * outer_product * (self.wmax - self.connection.w) self.connection.w += update super().update() def _conv2d_connection_update(self, **kwargs) -> None: # language=rst """ Post-pre learning rule for ``Conv2dConnection`` subclass of ``AbstractConnection`` class. """ # Get convolutional layer parameters. ( out_channels, in_channels, kernel_height, kernel_width, ) = self.connection.w.size() padding, stride = self.connection.padding, self.connection.stride batch_size = self.source.batch_size # Reshaping spike traces and spike occurrences. source_x = im2col_indices( self.source.x, kernel_height, kernel_width, padding=padding, stride=stride ) target_x = self.target.x.view(batch_size, out_channels, -1) source_s = im2col_indices( self.source.s.float(), kernel_height, kernel_width, padding=padding, stride=stride, ) target_s = self.target.s.view(batch_size, out_channels, -1).float() update = 0 # Pre-synaptic update. if self.nu[0]: pre = self.reduction( torch.bmm(target_x, source_s.permute((0, 2, 1))), dim=0 ) update -= ( self.nu[0] * pre.view(self.connection.w.size()) * (self.connection.w - self.wmin) ) # Post-synaptic update. if self.nu[1]: post = self.reduction( torch.bmm(target_s, source_x.permute((0, 2, 1))), dim=0 ) update += ( self.nu[1] * post.view(self.connection.w.size()) * (self.wmax - self.connection.wmin) ) self.connection.w += update super().update()
STDP规则涉及突触前和突触后的脉冲活动。突触前更新为负(-学习率1 × 突触前脉冲 × 突触后发放迹 × (weight - weightmin)),突触后更新为正(学习率2 × 突触前发放迹 × 突触后脉冲 × (weightmax - weight)),两者都依赖于突触权重的大小。
5、Hebbian
class Hebbian(LearningRule): # language=rst """ Simple Hebbian learning rule. Pre- and post-synaptic updates are both positive. """ def __init__( self, connection: AbstractConnection, nu: Optional[Union[float, Sequence[float]]] = None, reduction: Optional[callable] = None, weight_decay: float = 0.0, **kwargs ) -> None: # language=rst """ Constructor for ``Hebbian`` learning rule. :param connection: An ``AbstractConnection`` object whose weights the ``Hebbian`` learning rule will modify. :param nu: Single or pair of learning rates for pre- and post-synaptic events. :param reduction: Method for reducing parameter updates along the batch dimension. :param weight_decay: Constant multiple to decay weights by on each iteration. """ super().__init__( connection=connection, nu=nu, reduction=reduction, weight_decay=weight_decay, **kwargs ) assert ( self.source.traces and self.target.traces ), "Both pre- and post-synaptic nodes must record spike traces." if isinstance(connection, (Connection, LocalConnection)): self.update = self._connection_update elif isinstance(connection, Conv2dConnection): self.update = self._conv2d_connection_update else: raise NotImplementedError( "This learning rule is not supported for this Connection type." ) def _connection_update(self, **kwargs) -> None: # language=rst """ Hebbian learning rule for ``Connection`` subclass of ``AbstractConnection`` class. """ batch_size = self.source.batch_size source_s = self.source.s.view(batch_size, -1).unsqueeze(2).float() source_x = self.source.x.view(batch_size, -1).unsqueeze(2) target_s = self.target.s.view(batch_size, -1).unsqueeze(1).float() target_x = self.target.x.view(batch_size, -1).unsqueeze(1) # Pre-synaptic update. update = self.reduction(torch.bmm(source_s, target_x), dim=0) self.connection.w += self.nu[0] * update # Post-synaptic update. update = self.reduction(torch.bmm(source_x, target_s), dim=0) self.connection.w += self.nu[1] * update super().update() def _conv2d_connection_update(self, **kwargs) -> None: # language=rst """ Hebbian learning rule for ``Conv2dConnection`` subclass of ``AbstractConnection`` class. """ out_channels, _, kernel_height, kernel_width = self.connection.w.size() padding, stride = self.connection.padding, self.connection.stride batch_size = self.source.batch_size # Reshaping spike traces and spike occurrences. source_x = im2col_indices( self.source.x, kernel_height, kernel_width, padding=padding, stride=stride ) target_x = self.target.x.view(batch_size, out_channels, -1) source_s = im2col_indices( self.source.s.float(), kernel_height, kernel_width, padding=padding, stride=stride, ) target_s = self.target.s.view(batch_size, out_channels, -1).float() # Pre-synaptic update. pre = self.reduction(torch.bmm(target_x, source_s.permute((0, 2, 1))), dim=0) self.connection.w += self.nu[0] * pre.view(self.connection.w.size()) # Post-synaptic update. post = self.reduction(torch.bmm(target_s, source_x.permute((0, 2, 1))), dim=0) self.connection.w += self.nu[1] * post.view(self.connection.w.size()) super().update()
简单的Hebbian学习规则。突触前后的更新都为正(分别为学习率1 × 突触前脉冲 × 突触后发放迹,以及学习率2 × 突触前发放迹× 突触后脉冲)。
6、MSTDP
class MSTDP(LearningRule): # language=rst """ Reward-modulated STDP. Adapted from `(Florian 2007) <https://florian.io/papers/2007_Florian_Modulated_STDP.pdf>`_. """ def __init__( self, connection: AbstractConnection, nu: Optional[Union[float, Sequence[float]]] = None, reduction: Optional[callable] = None, weight_decay: float = 0.0, **kwargs ) -> None: # language=rst """ Constructor for ``MSTDP`` learning rule. :param connection: An ``AbstractConnection`` object whose weights the ``MSTDP`` learning rule will modify. :param nu: Single or pair of learning rates for pre- and post-synaptic events, respectively. :param reduction: Method for reducing parameter updates along the minibatch dimension. :param weight_decay: Constant multiple to decay weights by on each iteration. Keyword arguments: :param tc_plus: Time constant for pre-synaptic firing trace. :param tc_minus: Time constant for post-synaptic firing trace. """ super().__init__( connection=connection, nu=nu, reduction=reduction, weight_decay=weight_decay, **kwargs ) if isinstance(connection, (Connection, LocalConnection)): self.update = self._connection_update elif isinstance(connection, Conv2dConnection): self.update = self._conv2d_connection_update else: raise NotImplementedError( "This learning rule is not supported for this Connection type." ) self.tc_plus = torch.tensor(kwargs.get("tc_plus", 20.0)) self.tc_minus = torch.tensor(kwargs.get("tc_minus", 20.0)) def _connection_update(self, **kwargs) -> None: # language=rst """ MSTDP learning rule for ``Connection`` subclass of ``AbstractConnection`` class. Keyword arguments: :param Union[float, torch.Tensor] reward: Reward signal from reinforcement learning task. :param float a_plus: Learning rate (post-synaptic). :param float a_minus: Learning rate (pre-synaptic). """ batch_size = self.source.batch_size # Initialize eligibility, P^+, and P^-. if not hasattr(self, "p_plus"): self.p_plus = torch.zeros( batch_size, *self.source.shape, device=self.source.s.device ) if not hasattr(self, "p_minus"): self.p_minus = torch.zeros( batch_size, *self.target.shape, device=self.target.s.device ) if not hasattr(self, "eligibility"): self.eligibility = torch.zeros( batch_size, *self.connection.w.shape, device=self.connection.w.device ) # Reshape pre- and post-synaptic spikes. source_s = self.source.s.view(batch_size, -1).float() target_s = self.target.s.view(batch_size, -1).float() # Parse keyword arguments. reward = kwargs["reward"] a_plus = torch.tensor( kwargs.get("a_plus", 1.0), device=self.connection.w.device ) a_minus = torch.tensor( kwargs.get("a_minus", -1.0), device=self.connection.w.device ) # Compute weight update based on the eligibility value of the past timestep. update = reward * self.eligibility self.connection.w += self.nu[0] * self.reduction(update, dim=0) # Update P^+ and P^- values. self.p_plus *= torch.exp(-self.connection.dt / self.tc_plus) self.p_plus += a_plus * source_s self.p_minus *= torch.exp(-self.connection.dt / self.tc_minus) self.p_minus += a_minus * target_s # Calculate point eligibility value. self.eligibility = torch.bmm( self.p_plus.unsqueeze(2), target_s.unsqueeze(1) ) + torch.bmm(source_s.unsqueeze(2), self.p_minus.unsqueeze(1)) super().update() def _conv2d_connection_update(self, **kwargs) -> None: # language=rst """ MSTDP learning rule for ``Conv2dConnection`` subclass of ``AbstractConnection`` class. Keyword arguments: :param Union[float, torch.Tensor] reward: Reward signal from reinforcement learning task. :param float a_plus: Learning rate (post-synaptic). :param float a_minus: Learning rate (pre-synaptic). """ batch_size = self.source.batch_size # Initialize eligibility. if not hasattr(self, "eligibility"): self.eligibility = torch.zeros( batch_size, *self.connection.w.shape, device=self.connection.w.device ) # Parse keyword arguments. reward = kwargs["reward"] a_plus = torch.tensor( kwargs.get("a_plus", 1.0), device=self.connection.w.device ) a_minus = torch.tensor( kwargs.get("a_minus", -1.0), device=self.connection.w.device ) batch_size = self.source.batch_size # Compute weight update based on the eligibility value of the past timestep. update = reward * self.eligibility self.connection.w += self.nu[0] * torch.sum(update, dim=0) out_channels, _, kernel_height, kernel_width = self.connection.w.size() padding, stride = self.connection.padding, self.connection.stride # Initialize P^+ and P^-. if not hasattr(self, "p_plus"): self.p_plus = torch.zeros( batch_size, *self.source.shape, device=self.connection.w.device ) self.p_plus = im2col_indices( self.p_plus, kernel_height, kernel_width, padding=padding, stride=stride ) if not hasattr(self, "p_minus"): self.p_minus = torch.zeros( batch_size, *self.target.shape, device=self.connection.w.device ) self.p_minus = self.p_minus.view(batch_size, out_channels, -1).float() # Reshaping spike occurrences. source_s = im2col_indices( self.source.s.float(), kernel_height, kernel_width, padding=padding, stride=stride, ) target_s = self.target.s.view(batch_size, out_channels, -1).float() # Update P^+ and P^- values. 前者跟踪突触前脉冲的影响,后者跟踪突触后脉冲的影响 self.p_plus *= torch.exp(-self.connection.dt / self.tc_plus) self.p_plus += a_plus * source_s self.p_minus *= torch.exp(-self.connection.dt / self.tc_minus) self.p_minus += a_minus * target_s # Calculate point eligibility value. self.eligibility = torch.bmm( target_s, self.p_plus.permute((0, 2, 1)) ) + torch.bmm(self.p_minus, source_s.permute((0, 2, 1))) self.eligibility = self.eligibility.view(self.connection.w.size()) super().update()
奖励调节STDP (R-STDP),改编自(Florian 2007)<https://florian.io/papers/2007_Florian_Modulated_STDP.pdf>

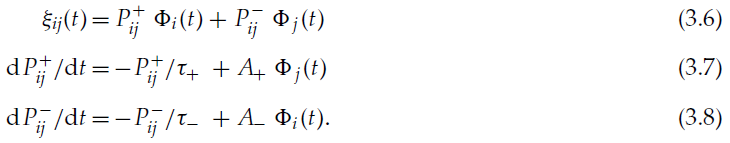
7、MSTDPET
class MSTDPET(LearningRule): # language=rst """ Reward-modulated STDP with eligibility trace. Adapted from `(Florian 2007) <https://florian.io/papers/2007_Florian_Modulated_STDP.pdf>`_. """ def __init__( self, connection: AbstractConnection, nu: Optional[Union[float, Sequence[float]]] = None, reduction: Optional[callable] = None, weight_decay: float = 0.0, **kwargs ) -> None: # language=rst """ Constructor for ``MSTDPET`` learning rule. :param connection: An ``AbstractConnection`` object whose weights the ``MSTDPET`` learning rule will modify. :param nu: Single or pair of learning rates for pre- and post-synaptic events, respectively. :param reduction: Method for reducing parameter updates along the minibatch dimension. :param weight_decay: Constant multiple to decay weights by on each iteration. Keyword arguments: :param float tc_plus: Time constant for pre-synaptic firing trace. :param float tc_minus: Time constant for post-synaptic firing trace. :param float tc_e_trace: Time constant for the eligibility trace. """ super().__init__( connection=connection, nu=nu, reduction=reduction, weight_decay=weight_decay, **kwargs ) if isinstance(connection, (Connection, LocalConnection)): self.update = self._connection_update elif isinstance(connection, Conv2dConnection): self.update = self._conv2d_connection_update else: raise NotImplementedError( "This learning rule is not supported for this Connection type." ) self.tc_plus = torch.tensor(kwargs.get("tc_plus", 20.0)) self.tc_minus = torch.tensor(kwargs.get("tc_minus", 20.0)) self.tc_e_trace = torch.tensor(kwargs.get("tc_e_trace", 25.0)) def _connection_update(self, **kwargs) -> None: # language=rst """ MSTDPET learning rule for ``Connection`` subclass of ``AbstractConnection`` class. Keyword arguments: :param Union[float, torch.Tensor] reward: Reward signal from reinforcement learning task. :param float a_plus: Learning rate (post-synaptic). :param float a_minus: Learning rate (pre-synaptic). """ # Initialize eligibility, eligibility trace, P^+, and P^-. if not hasattr(self, "p_plus"): self.p_plus = torch.zeros((self.source.n), device=self.source.s.device) if not hasattr(self, "p_minus"): self.p_minus = torch.zeros((self.target.n), device=self.target.s.device) if not hasattr(self, "eligibility"): self.eligibility = torch.zeros( *self.connection.w.shape, device=self.connection.w.device ) if not hasattr(self, "eligibility_trace"): self.eligibility_trace = torch.zeros( *self.connection.w.shape, device=self.connection.w.device ) # Reshape pre- and post-synaptic spikes. source_s = self.source.s.view(-1).float() target_s = self.target.s.view(-1).float() # Parse keyword arguments. reward = kwargs["reward"] a_plus = torch.tensor( kwargs.get("a_plus", 1.0), device=self.connection.w.device ) a_minus = torch.tensor( kwargs.get("a_minus", -1.0), device=self.connection.w.device ) # Calculate value of eligibility trace based on the value # of the point eligibility value of the past timestep. self.eligibility_trace *= torch.exp(-self.connection.dt / self.tc_e_trace) self.eligibility_trace += self.eligibility / self.tc_e_trace # Compute weight update. self.connection.w += ( self.nu[0] * self.connection.dt * reward * self.eligibility_trace ) # Update P^+ and P^- values. self.p_plus *= torch.exp(-self.connection.dt / self.tc_plus) self.p_plus += a_plus * source_s self.p_minus *= torch.exp(-self.connection.dt / self.tc_minus) self.p_minus += a_minus * target_s # Calculate point eligibility value. self.eligibility = torch.ger(self.p_plus, target_s) + torch.ger( source_s, self.p_minus ) super().update() def _conv2d_connection_update(self, **kwargs) -> None: # language=rst """ MSTDPET learning rule for ``Conv2dConnection`` subclass of ``AbstractConnection`` class. Keyword arguments: :param Union[float, torch.Tensor] reward: Reward signal from reinforcement learning task. :param float a_plus: Learning rate (post-synaptic). :param float a_minus: Learning rate (pre-synaptic). """ batch_size = self.source.batch_size # Initialize eligibility and eligibility trace. if not hasattr(self, "eligibility"): self.eligibility = torch.zeros( batch_size, *self.connection.w.shape, device=self.connection.w.device ) if not hasattr(self, "eligibility_trace"): self.eligibility_trace = torch.zeros( batch_size, *self.connection.w.shape, device=self.connection.w.device ) # Parse keyword arguments. reward = kwargs["reward"] a_plus = torch.tensor( kwargs.get("a_plus", 1.0), device=self.connection.w.device ) a_minus = torch.tensor( kwargs.get("a_minus", -1.0), device=self.connection.w.device ) # Calculate value of eligibility trace based on the value # of the point eligibility value of the past timestep. self.eligibility_trace *= torch.exp(-self.connection.dt / self.tc_e_trace) # Compute weight update. update = reward * self.eligibility_trace self.connection.w += self.nu[0] * self.connection.dt * torch.sum(update, dim=0) out_channels, _, kernel_height, kernel_width = self.connection.w.size() padding, stride = self.connection.padding, self.connection.stride # Initialize P^+ and P^-. if not hasattr(self, "p_plus"): self.p_plus = torch.zeros( batch_size, *self.source.shape, device=self.connection.w.device ) self.p_plus = im2col_indices( self.p_plus, kernel_height, kernel_width, padding=padding, stride=stride ) if not hasattr(self, "p_minus"): self.p_minus = torch.zeros( batch_size, *self.target.shape, device=self.connection.w.device ) self.p_minus = self.p_minus.view(batch_size, out_channels, -1).float() # Reshaping spike occurrences. source_s = im2col_indices( self.source.s.float(), kernel_height, kernel_width, padding=padding, stride=stride, ) target_s = ( self.target.s.permute(1, 2, 3, 0).view(batch_size, out_channels, -1).float() ) # Update P^+ and P^- values. self.p_plus *= torch.exp(-self.connection.dt / self.tc_plus) self.p_plus += a_plus * source_s self.p_minus *= torch.exp(-self.connection.dt / self.tc_minus) self.p_minus += a_minus * target_s # Calculate point eligibility value. self.eligibility = torch.bmm( target_s, self.p_plus.permute((0, 2, 1)) ) + torch.bmm(self.p_minus, source_s.permute((0, 2, 1))) self.eligibility = self.eligibility.view(self.connection.w.size()) super().update()
带资格迹的奖励调节STDP (R-STDP with eligibility trace),改编自(Florian 2007)<https://florian.io/papers/2007_Florian_Modulated_STDP.pdf>
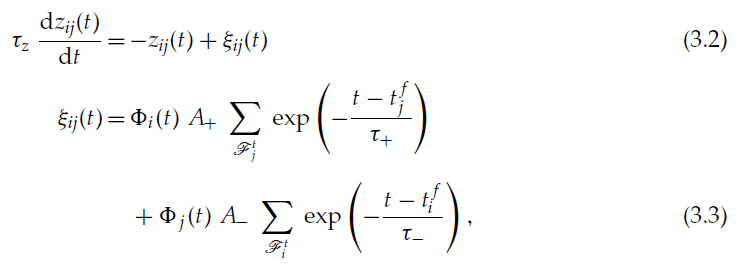
8、Rmax
class Rmax(LearningRule): # language=rst """ Reward-modulated learning rule derived from reward maximization principles. Adapted from `(Vasilaki et al., 2009) <https://intranet.physio.unibe.ch/Publikationen/Dokumente/Vasilaki2009PloSComputBio_1.pdf>`_. """ def __init__( self, connection: AbstractConnection, nu: Optional[Union[float, Sequence[float]]] = None, reduction: Optional[callable] = None, weight_decay: float = 0.0, **kwargs ) -> None: # language=rst """ Constructor for ``R-max`` learning rule. :param connection: An ``AbstractConnection`` object whose weights the ``R-max`` learning rule will modify. :param nu: Single or pair of learning rates for pre- and post-synaptic events, respectively. :param reduction: Method for reducing parameter updates along the minibatch dimension. :param weight_decay: Constant multiple to decay weights by on each iteration. Keyword arguments: :param float tc_c: Time constant for balancing naive Hebbian and policy gradient learning. :param float tc_e_trace: Time constant for the eligibility trace. """ super().__init__( connection=connection, nu=nu, reduction=reduction, weight_decay=weight_decay, **kwargs ) # Trace is needed for computing epsilon. assert ( self.source.traces and self.source.traces_additive ), "Pre-synaptic nodes must use additive spike traces." # Derivation of R-max depends on stochastic SRM neurons! assert isinstance( self.target, SRM0Nodes ), "R-max needs stochastically firing neurons, use SRM0Nodes." if isinstance(connection, (Connection, LocalConnection)): self.update = self._connection_update else: raise NotImplementedError( "This learning rule is not supported for this Connection type." ) self.tc_c = torch.tensor( kwargs.get("tc_c", 5.0) ) # 0 for pure naive Hebbian, inf for pure policy gradient. self.tc_e_trace = torch.tensor(kwargs.get("tc_e_trace", 25.0)) def _connection_update(self, **kwargs) -> None: # language=rst """ R-max learning rule for ``Connection`` subclass of ``AbstractConnection`` class. Keyword arguments: :param Union[float, torch.Tensor] reward: Reward signal from reinforcement learning task. """ # Initialize eligibility trace. if not hasattr(self, "eligibility_trace"): self.eligibility_trace = torch.zeros( *self.connection.w.shape, device=self.connection.w.device ) # Reshape variables. target_s = self.target.s.view(-1).float() target_s_prob = self.target.s_prob.view(-1) source_x = self.source.x.view(-1) # Parse keyword arguments. reward = kwargs["reward"] # New eligibility trace. self.eligibility_trace *= 1 - self.connection.dt / self.tc_e_trace self.eligibility_trace += ( target_s - (target_s_prob / (1.0 + self.tc_c / self.connection.dt * target_s_prob)) ) * source_x[:, None] # Compute weight update. self.connection.w += self.nu[0] * reward * self.eligibility_trace super().update()
基于奖励最大化原理的奖励调节学习规则,改编自(Vasilaki et al., 2009)<https://intranet.physio.unibe.ch/Publikationen/Dokumente/Vasilaki2009PloSComputBio_1.pdf>





 浙公网安备 33010602011771号
浙公网安备 33010602011771号