Biologically Inspired SNN for Robot Control
摘要:郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

IEEE Transactions on Cybernetics, no. 1 (2013): 115-128
Abstract
本文提出了一种基于SNN的机器人控制器,该控制器受生物系统的控制结构启发。通过使用具有短时可塑性的动态突触来沿着网络传输信息。学习是通过使用TD学习规则实现的长期突触可塑性进行的,以使机器人能够学习将正确的运动与适当的输入条件相关联。网络自组织以提供对机器人遇到的环境的记忆。使用带有激光和声纳接近传感器的Pioneer机器人仿真器来验证沿墙任务的网络性能,并给出结果。
I. INTRODUCTION
许多移动机器人应用需要在复杂环境中进行机动,为此,机器人需要感知和响应环境中的事件。生物体能很好地完成这类任务,因此,研究人员一直致力于开发基于生物神经系统的模型。由于与生物神经元功能相似,脉冲神经网络(SNN)可以模拟大脑的基本过程,包括神经信息处理、可塑性和学习。SNN提供了一种受生物学启发的方法来处理不同感觉模式和计算的数据[1],在这种方法中,已经证明脉冲发放时间在神经元信息处理中非常重要[2]。通过模拟周围神经和中枢神经系统的化学和电功能,SNN可以提供比其他方法更真实的生物学行为,因此本文使用SNN。通过单个脉冲传递信息的神经元的脉冲特性在计算上比sigmoidal神经网络更强大,因此,SNN在信号处理、真实世界数据分类、语音识别、空间导航、轨迹跟踪、路径规划、决策、动作选择或电机控制等方面有着广泛的应用。
蓝色大脑项目[3]指出通过测试计算机模拟的假设可以从分子水平到智能出现更好地理解大脑。Cortex项目[4]正在使用SNN,试图了解我们大脑的低层次成分是如何产生复杂的高层次属性的。Hopfield报告了一个有趣的海马状网络模型,它可以学习环境的心理地图,并在给定的环境中进行运动规划[5]。该网络由一组具有all-to-all兴奋联系的位置细胞组成。脉冲时序依赖性增强是用来加强细胞之间的联系,激活在一个密切的时间接近。该机制随后用于路径规划。针对轨迹跟踪和设定值控制任务,提出了几种脉冲神经控制器模型。Di Paolo [6]在移动机器人导航任务中应用了一种进化方法来训练SNN控制器,方法是只进化每个神经元的可塑性模型和时间特性。结果表明,在相同条件下,SNN控制器比基于速率的控制器能够更快且更可靠地达到稳定状态。这一领域的研究尚处于萌芽阶段,许多因素尚不清楚。对大脑不完全理解的例子包括:认为大脑中可能存在100多种不同的神经递质,许多神经递质的功能还没有完全理解[7]。在大脑的突触[8]和神经元[9], [10]中也可能存在量子效应,但其程度尚不清楚。
SNN具有学习和决策的能力,尽管不完全了解神经功能,为此,使用SNN控制器的沿墙绕行应用已被报道。混合系统已经发表,其中一个遗传算法(GA)的基础上的进化特性的物种修改属性的SNN。在[11]中创建了一个由GA修改的突触值的沿墙绕行SNN。与使用模糊逻辑(FL)控制器相比,SNN具有更好的响应,并且SNN的性能也优于使用标准GA控制器。遗传算法也被用于另一个出版物[12],以优化从一层中的两个神经元到下一层中的十个神经元的连通性,从而实现机器人运动而不碰撞墙壁。使用了一个模拟机器人,混合SNN比单独使用遗传算法有更好的性能。文献[13]中实现了SNN和FL的混合控制器,其中一个模拟机器人基于FL规则集学习行为,并使用脉冲神经元实现行为。实验证明了成功的避障和目标跟踪行为。
混合系统为软件中SNN的缓慢进程提供了暂时的好处,因为它们提供了更快的突触修改、连接和学习行为的速度。虽然功能系统是用SNN结合其他方法建立起来的,但是混合系统在生物体神经系统建模中是不现实的。例如,GA在一个生命周期内不会改变神经系统的值,FL在突触和神经元结构中没有基础。
文献中已经报道了使用无混合系统的SNN的壁跟随应用。[14]中使用了静态SNN结构,由13个神经元组成,分成三层。在仿真机器人上进行了实验研究,结果表明该机器人具有良好的沿墙绕行行为。另一个SNN使用STDP规则以生物启发的方式改变其突触效能[15]。SNN与它的环境相互作用,从而学会通过接近或远离对象来在房间中导航。文献[16]中的SNN也能够通过生物激发的长期突触可塑性进行学习,实验表明,SNN学会了在迷宫中导航。前面描述的SNN具有学习能力,并且运动决策是通过其网络结构做出的。然而,它们可以通过短期可塑性、自组织和不同任务的神经元簇等机制以更精确的生物学方式实现。
虽然可以使用简单的if-then规则执行沿墙绕行任务,但该任务还可以用于测试较低级别(SNN)结构中是否出现较高级别的行为。本文将SNN应用于一个沿墙绕行任务,以测试信息是否通过促进突触正确地通过网络路由,以及通过学习期望的决策功能是否也能被看到。在本文中,SNN使用一维传感器作为输入,这在应用上有一定的局限性。
目前研究的主要目标是实现短期和长期突触可塑性。以生物为基础的路由信息驱动使用促进动态突触是实现短期可塑性。以前的文献[17], [18]中已经使用了动态突触。然而,他们使用if-then规则在每一个突触的促进和抑制之间进行转换。本文中的突触参数并不是按照人为的规则进行转换的。相反,它们是以一种更具生物性的方式实现的,以产生通过网络的脉冲的正确路由。长期突触可塑性是利用TD规则来学习沿墙绕行行为。有一些TD学习规则应用于SNN应用的例子[19], [20]。然而,对于SNN中的突触修改来说,还没有实现在沿墙绕行任务中学习运动的期望。此任务所需的TD参数对于沿墙绕行应用是唯一的,并进行了详细描述。因此,本论文的重点是开发一个以生物学精度为目标的机器人控制器。
本文的其余部分组织如下。第二节介绍了脉冲神经元模型。第三节描述了自组织SNN。第四节讨论了使用Pioneer机器人的仿真器测试SNN。第五节给出了实验结果和分析,第六节讨论后,第七节总结了本文。
II. NEURON MODEL
存在神经元的计算模型,例如Hodgkin和Huxley [21],Izhikevich [22]和FitzHugh–Nagumo [23],它们具有不同程度的生物学合理性。本文选择使用LIF神经元模型,因为它需要最少的计算,同时又类似于体内和体外的生物神经元[24]。LIF模型在[25]中被表示为:
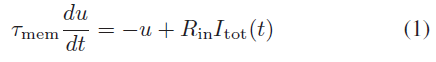
其中τmem (= 40 ms)是膜时间常数,Rin (= 100MΩ)是输入电阻。u是神经元电压与静息电位的偏移,而Itot(t)是来自所有突触的总电流,由:

其中Isyn是来自单个突触的电流,由下式定义:
![]()
其中,绝对突触功效(ASE)是突触提供给突触后神经元的总电荷(本文以基本单位纳安为单位进行测量)。y 是突触神经递质与突触后受体结合的活动部分,导致离子通道打开,离子流流入突触后神经元,直到通道关闭[26]。
突触的重复激活可导致兴奋性促进突触中突触后电流增加或抑制突触时电流降低[27]。[25]中描述了抑制突触中 y 的动力学方程,这被表示为:

其中sp是一个二值,表示是否存在脉冲,如[17]中所述。参数 x 和 z 分别是处于恢复状态和非活跃状态的神经递质的比例。恢复时间常数为τrec,神经递质失活的时间常数为τin。USE是对突触功效的利用,突触功效是可以激活的最大资源比例。
在促进突触中,USE可以随着连续输入脉冲而增长。参照(7),![]() 是一段时间内USE的运行总量,反映了钙离子的积累和消耗[28],替代了(4)和(5)中的USE,在[25]中被描述为:
是一段时间内USE的运行总量,反映了钙离子的积累和消耗[28],替代了(4)和(5)中的USE,在[25]中被描述为:
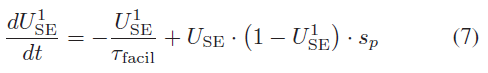
其中τfacil是促进时间常数。
基于时序脉冲间隔(ISI),促进生物学SNN中的突触路径信息。ISI是从一个脉冲到神经元之间相同连接上的下一个脉冲所经过的时间。[29]使用大鼠的新皮层以显示这种促进突触的路径,其中当通过一个轴突的脉冲传递给两个单独的促进突触时,脉冲会产生不同的响应。他们报告说,USE,τrec和τfacil的值在各种生物学促进突触中是不同的,并且这种差异导致神经元的输出以不同的电压量影响其连接的神经元。在所提出的SNN中实现了这种路由机制,以提高网络的生物合理性,从而提高控制器的生物学精度。
为了找到适合ISI范围的USE,τrec和τfacil值,使用C语言对程序进行了编码,并在促进突触中加入了脉冲序列输入,持续了几秒钟。几秒钟后(y 增长和稳定的时间),记录了最大的 y 并将其添加到一个Matlab文件中。对于给定范围内的每个ISI重复此操作。在Matlab中打开文件,并绘制了ISI范围内的 y 曲线。调整USE,τrec和τfacil值,然后重复该过程,直到找到绘制曲线的理想顶点为止。所提出的SNN中的τin促进值和每个压抑值都来自文献[25]中的现象学突触。
III. SELF-ORGANIZING SNN
沿墙绕行的应用需要知道距离和方向,以实现适当的运动。任意选择离墙太近的距离需要远离墙,选择离墙太远的距离需要朝向墙。如果方向与墙平行,则选定为理想的距离执行沿墙绕行并向前移动。否则,如果朝向墙或远离墙,则朝向墙或远离墙的向前和旋转运动将继续沿墙绕行过程。当接近一堵墙时,必须做出选择:是沿左侧的墙还是右侧的墙。这对适当的移动有影响,因为向墙移动或离开墙可能需要在不同的方向上移动,这取决于墙在哪一侧。此外,机器人必须从不同的运动中获得期望的知识,并从这些期望中实现正确的运动。
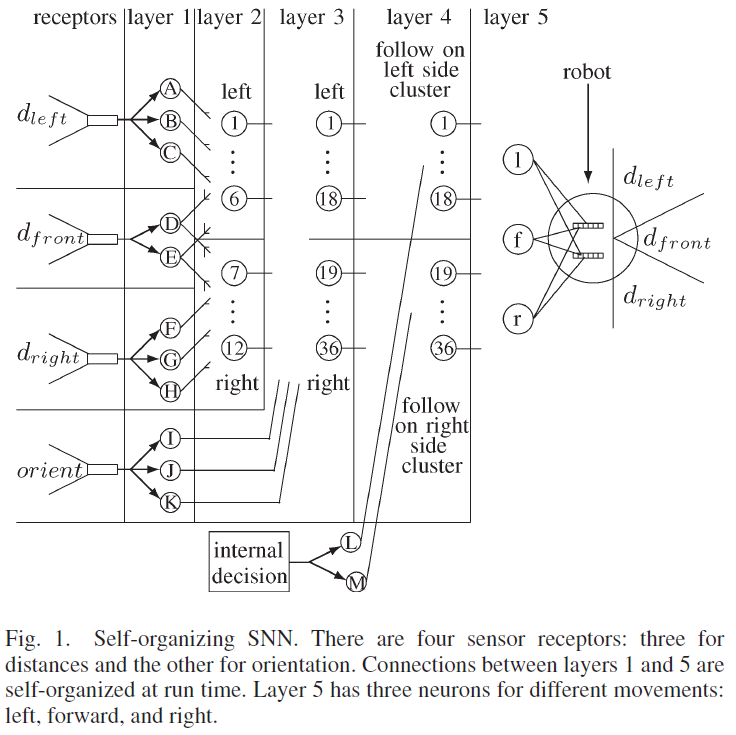
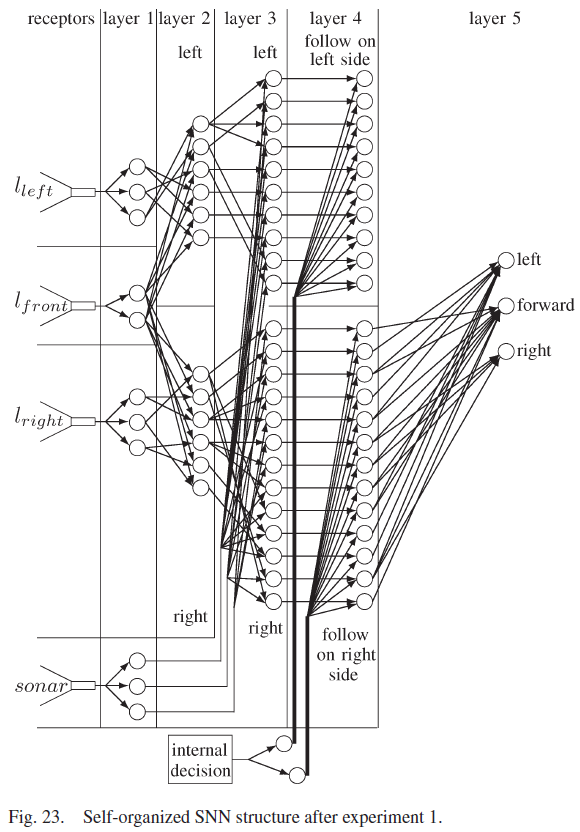
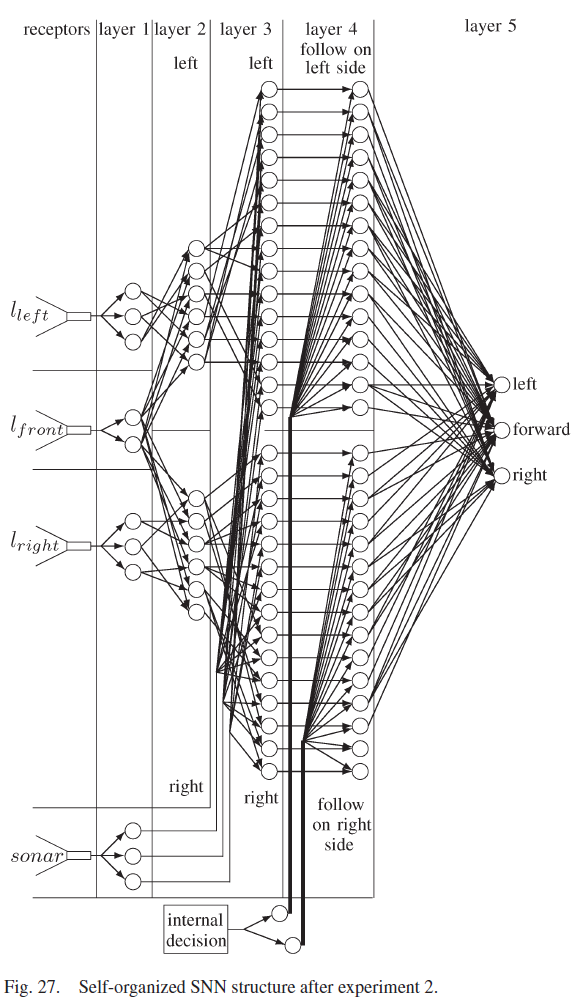
所提出的自组织SNN结合了这些元素,并建立在以前的工作[18]的基础上,其中SNN针对机器人遇到的每一种新的环境条件不断地自组织其结构。SNN如图1所示,由五层组成。传感器感受器将环境信息转化为脉冲序列。第1层将传感器感受器输入分离为距离和方向。第二层融合了前面和侧面的距离信息。第3层融合了距离和方向数据,而第4层分离了机器人执行离散动作所需的数据。学习发生在第5层的突触上,它包含三个神经元,每个神经元导致不同的运动。从第一层到第五层的连接是自组织的,因为在网络开始时没有连接,并且连接是在机器人经历其环境时形成的。相反,从感受器到第1层和从第5层到电机的连接是硬连线的。本文中使用的突触是基于具有短期可塑性反应的生物突触[25]。促进突触刺激第1层到第4层的神经元,其功能是激活一个独特的第4层神经元,以适应不同的环境条件和任务决策。第4层的神经元与抑制性突触协同作用,抑制性突触激活第5层的神经元,而无需等待y的增加。
注意,当一个神经元的输出脉冲频率高于其簇中所有其他神经元时,该神经元被定义为活跃的。另一方面,神经元被定义为不活动的,因为促进突触过滤掉随后层中的高ISI脉冲序列。

A. Layer 1
第1层中有11个神经元,每个神经元都硬连线至四个传感接收器之一。图2所示的dfront接收器接收有关从机器人正面到物体的距离的输入。它将信息转换为在第1层中导致两个神经元D和E的脉冲序列。
图3显示了神经元D和E突触中活性神经递质的百分比[(5)中的y],同时显示出可塑性取决于ISI。每个第1层的突触的USE值为0.05。与神经元D相关的突触的τrec = 200 ms,τfacil = 915 ms,这导致较高的活动状态和较小的ISI,这些值如图3(a)所示。如图3(b)所示,与神经元E相关的突触的τrec = 804 ms,τfacil = 4000 ms,在较大的ISI的作用下会导致较高的活动状态。
如果使用的神经递质大于16.76%,则将这些突触处的ASE值设置为这样的强度:一个突触前脉冲会导致突触后神经元产生一个输出脉冲。较小地利用突触资源需要至少一个额外的突触前脉冲才能发生突触后脉冲。因此,当机器人距对象的距离小于0.9 m时[ISI小于178 ms,使用(15)],而神经元E在距离大于或等于0.9 m时处于活动状态,因此突触参数导致神经元D处于活动状态(ISI大于或等于178 ms)。可以任意选择值0.9 m (178ms ISI)作为从机器人前端到最近感应物体的可接受距离。
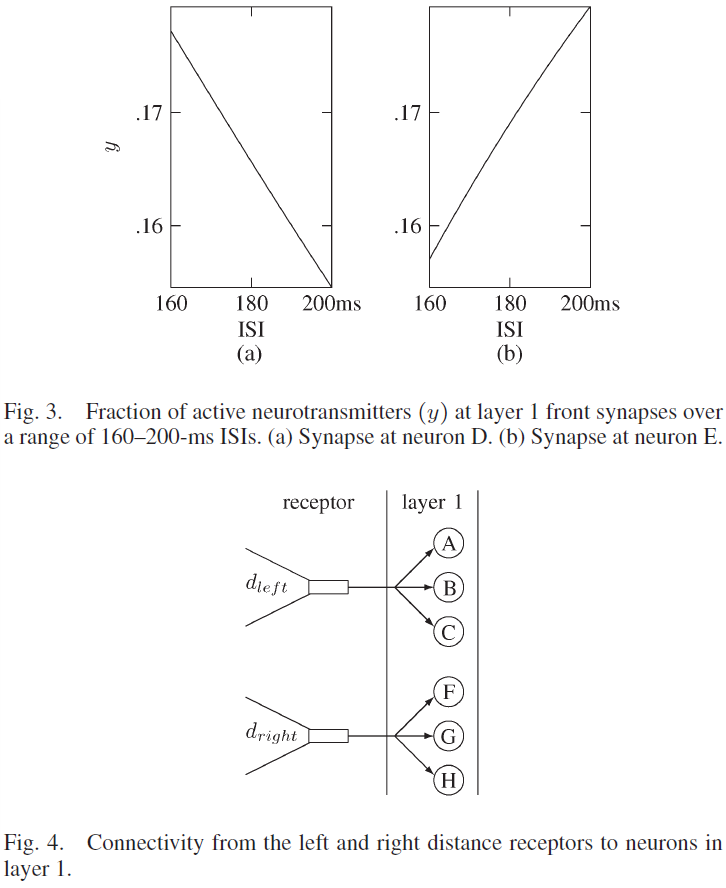
第1层中的六个神经元从两个接收器接收输入,这两个接收器对机器人与其两侧各最近的物体之间的距离敏感。三个神经元连接到dleft接收器,三个神经元连接到dright接收器。图4显示了这些接收器与标记为A, B, C和F, G, H的神经元的连通性。
通往神经元A和F的路径中的突触具有τrec = 200 ms和τfacil = 915 ms。在图5(a)中,在160-200 ms的范围内显示了具有这些参数的ISI的活动状态,其中,突触参数显示出随着ISI的减少而增加的活动。与神经元B和G相关的突触的τrec = 505 ms,τfacil = 1455 ms。选择这些值以确保刺激神经元B和G的突触在180 ms的ISI时发挥最大作用,如图5(b)所示。如图5(c)所示,通向神经元C和H的路径中的突触的τrec = 826 ms,τfacil = 4000 ms,随着ISI的增加,导致更高的活动状态。
如果利用的神经递质数量超过16.728%,则旁突触处的ASE值将使一个突触前脉冲产生一个突触后神经元输出脉冲,如果活动的神经递质较少,则突触后脉冲还需要进一步的突触前脉冲。因此,当机器人的左侧和右侧距对象的距离小于0.9 m (ISI小于178 ms)时,旁突触参数会导致神经元A和F处于活动状态。神经元B和G在大于或等于0.9 m且小于或等于1.1 m的中间距离(ISI大于或等于178 ms且小于或等于182 ms)中处于活动状态。神经元C和H在距对象大于1.1 m (ISI大于182 ms)的远距离处活动。从机器人侧面到最近的感测对象的距离可以任意选择大于或等于0.9 m (178 ms ISI)且小于或等于1.1 m (182 ms ISI)。
方向接收器(图6中的方向)对机器人最靠近物体的一侧敏感,来自接收器的线性ISI由下式给出:

该接收器刺激标记为I,J和K的三个神经元的突触,如图6所示。每个神经元的突触具有与每个侧向距离突触相同的参数,并且这些突触值激活三个突触值之一。神经元适用于每种可能的环境条件。当机器人的正面朝向最近的墙壁时,神经元I处于活动状态。当机器人与墙并排时,神经元J处于活动状态,而当机器人的方位背对墙时,神经元K处于活动状态。选择(8)中的ISI值以针对三个突触中的每一个产生最大激活状态 y,如图5所示。

B. Layer 2: Front and Side Distance Fusion
第2层由左右两个神经元簇组成。两种不同距离接收器的融合发生在该层中。左集群处理来自机器人正面和左侧的信息,而右集群处理来自正面和右侧的信息。这种映射类似于人的神经系统,在该系统中,来自视野的左前和左端的信息被传递到大脑一个半球的视觉皮层,而来自左前和右端的信息则在大脑另一半球的视觉皮层中被处理。在网络执行开始时,第2层中的任何神经元都没有连接。
进入第2层的连通性如图7所示,其中来自每个接收器的随机神经元代表活动层1的神经元。当两个以前从未一起活动的接收器dleft和dfront激活了两个神经元时,这些神经元将连接到未连接的左侧第2层神经元。同样地,来自接收器dright和dfront的两个活动神经元第一次连接到未连接的右2层神经元,这是因为这两个第1层神经元首次一起活动。连接的这种自组织是网络学习和保留有关其直接环境的知识的方式。
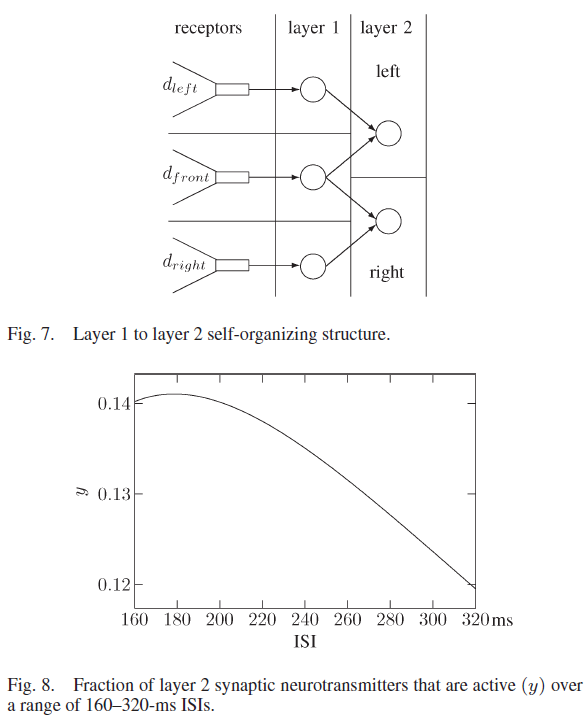
与第2层突触相关的促进突触参数为USE = 0.03,τrec = 600 ms和τfacil = 1950 ms。在图8中显示了在一系列ISI上使用这些值的活跃神经递质的百分比,其中当ISI大于或等于160 ms且小于或等于ISI时,可以看到活性处于最大值,几乎没有变化。当ISI大于200 ms时,活动会降低。这些突触参数从非活动的第1层神经元中过滤掉信息,并在第1层中有两个相连且活动的神经元的地方维护信息。
C. Layer 3: Distance and Orientation Fusion
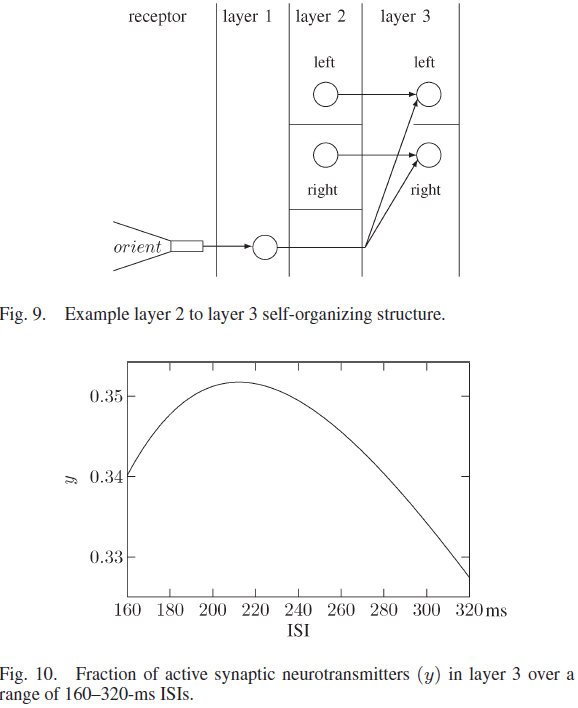
两种不同的传感器类型(距离和方向)的融合发生在第3层中。该层中的神经元开始时没有连通性。图9显示了与第3层的连接,其中来自定向受体的随机神经元和来自第2层各侧的随机神经元分别代表主动取向和第2层神经元。首次同时激活的来自定向受体和左2层簇的神经元连接到未连接的左3层神经元。未连接的右第3层神经元也发生连接,这是来自定向受体和右第2层簇的神经元同时活动的第一种情况。对于机器人到墙壁的每个经历的距离和方向,这都会导致唯一的第3层输出发放状态。
第3层中的每个突触都具有以下参数:USE = 0.05,τrec = 250 ms和τfacil = 4000 ms。与第2层参数相比,这些值对较大的ISI产生更强的抑制,如图10所示。该层中的USE小于第2层USE,因为活性百分比更高,并导致一个活动的第3层左侧的神经元,右侧的一个活动层3神经元,ISI在160到200 ms之间。
D. Layer 4: Decision Activation
机器人的最佳运动取决于要执行的任务。如果机器人跟随左侧的墙壁,向左移动会使机器人更靠近墙壁,而如果机器人跟随右侧的墙壁,向右移动会使机器人更靠近墙壁。因此,给定相同的传感器输入,不同的任务应该执行不同的动作。因此,有必要激活将执行确定任务的神经元群体,而不激活执行其他任务的群体。图1显示了包含两个神经元群体的第4层,一个用于跟随机器人左侧的墙壁,另一个用于跟随机器人右侧的墙壁。
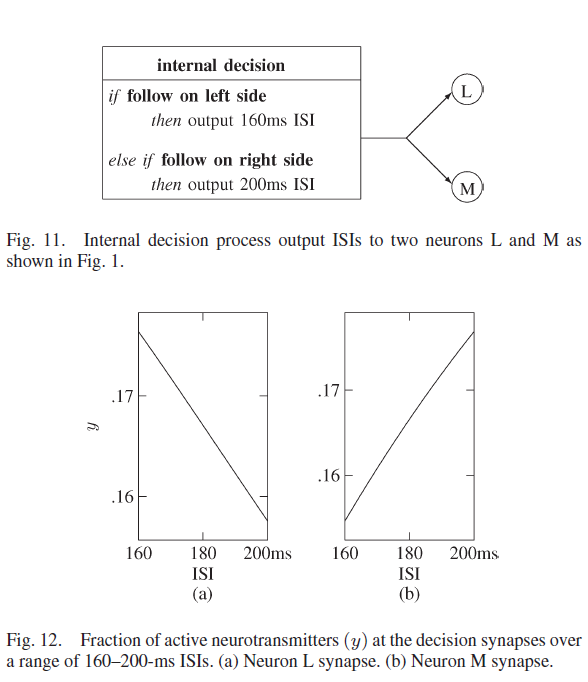
为了激活相应的群体,从内部决策向两个神经元发送脉冲信号,以指定机器人要跟随的一侧。图11 显示了激活每个决策的过程,其中当机器人的任务是跟随左侧的墙壁时,神经元L和M都以160 ms的ISI接收脉冲,而当机器人的任务是跟随其右侧的墙壁时,则为200 ms。
请注意,内部决策过程不接收任何输入。关于参与动作的决定是在网络之外选择的。在未来的工作中,这个决定可以作为网络的判断(即墙靠近一侧)或作为指令(例如语音激活方向)来实现。在当前的工作中,决策ISI是在SNN执行之前选择的。
刺激神经元L和M以及第4层神经元的突触的短期突触参数USE = 0.05。神经元L通路中的突触参数为τrec = 250 ms和τfacil = 980 ms,图12(a)显示在ISI为160 ms时比在ISI为200 ms时的活动更多。与神经元M相关的突触有τrec = 820 ms和τfacil = 4000 ms,图12(b)显示这些参数会导致更多的活动,ISI为200 ms,而不是160 ms。这些突触参数导致神经元L在决定跟随左侧的墙壁时激活,而神经元M在决定跟随右侧时激活。
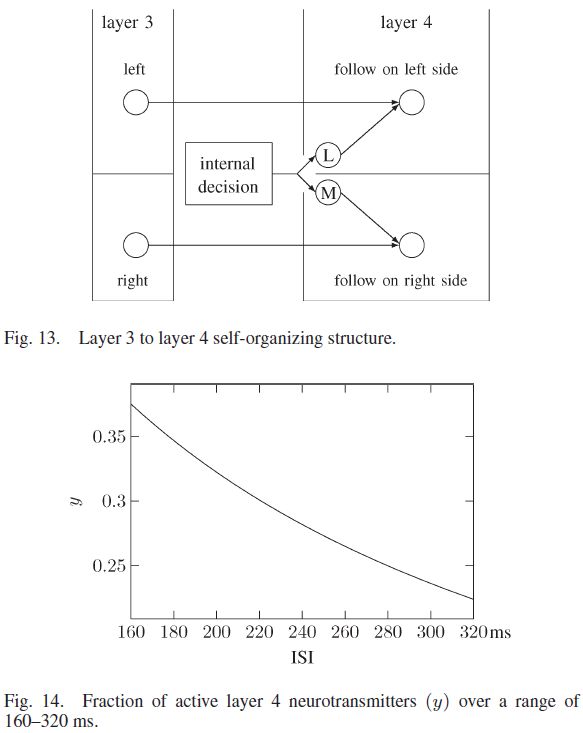
第4层中的神经元开始时没有连接。当第2层神经元和第3层神经元之间形成连接时,新连接的第3层神经元连接到它在第4层中最近的地理邻居。从内部决策神经元刺激相关神经元群体也同时形成到第4层神经元的连接。如图13所示,其中左侧和右侧的第3层神经元连接到第4层神经元,刺激每个群体的决策神经元也连接到第4层神经元。因此,第4层中的独特神经元对于每个独特的正面接近度、侧面接近度、墙壁方向和任务决策都是活跃的。
从第3层神经元输出刺激第4层神经元的突触具有τrec = 10 ms和τfacil = 2000 ms的促进参数。这些突触的ASE值使得活动输入大大增加突触后电位,突触参数随着ISI上升而显著降低活动,这过滤掉了大的ISI脉冲序列,如图14所示。
来自内部决策神经元的突触参数与进入第3层的突触相同,它们对突触前ISI的影响如图10所示。这些突触的活动随着160-200 ms的ISI的增加而增加,它用来自第3层神经元的突触中相同范围的ISI来抵消活动的减少。在每个第4层突触中,从决策和第3层神经元开始,较大的ISI会导致活动减少,从而过滤掉较大的ISI序列。
E. Layer 5: Motor Control
第5层有三个神经元,每个神经元控制不同的运动:向前、向左转和向右转。在第一种情况下,第4层神经元输出一个脉冲,并且该神经元与每个第5层神经元完全连接。然后,当同一个第4层神经元输出后续脉冲时,网络开始学习要执行的运动。这是通过学习在给定任务、距离和方向的情况下对每个动作的期望来实现的。由于左转和右转的连通性和互斥性,机器人可以学习五种不同的运动:向前、向左前、向右前、向左转和向右转。

F. Layer 6: Learning
在大脑的运动区域,学习受到来自感觉接收器的持续反馈的影响[30]。在[31]中指出,"现在有压倒性的证据,从多巴胺能脉冲序列的直接测量和多巴胺瞬变的快速电化学测量,多巴胺传递的阶段性变化携带奖励预测误差信号。"中脑中的多巴胺能神经元接收感觉输入并向参与控制随意运动的非局部突触提供多巴胺神经递质[32]。当多巴胺在突触后释放到突触间隙时,它会与多巴胺受体结合并成为"一种神经调节剂,改变目标神经元对其他神经递质的反应"[33]。在与其受体解除结合后,多巴胺可以被带到血液中。为了保持多巴胺的恒定水平,多巴胺能神经元输出基准量的神经递质。每个运动都有一个预期的结果,如果结果好于预期,就会释放比基准量更大的多巴胺,从而导致长期增强[34]。比预期更糟糕的结果会导致多巴胺释放量低于基准,从而导致长期抑制。多巴胺能系统提供了一种根据运动输出后的感觉反馈来学习运动期望的方法。
多巴胺会影响ASE的值,因为激活突触中的多巴胺能神经递质会导致更高的突触后电压。中脑多巴胺能神经元活动的增加对应于奖励行为,而多巴胺的减少是错误行为的结果[32], [35]。据报道,多巴胺的奖励和抑制恰好符合TD学习规则的行为[31]。TD模型与中脑多巴胺神经元的阶段性活动之间的可比结果显示在[36]中。
TD学习规则基于未来奖励 r 的期望值V,可以表示为:

其中 γ 是介于0和1之间的折扣率。V 在每个时间步骤 t 更新,其中计算移动奖励并修改未来奖励。TD规则,表示为δt,在[37]中写为:
![]()
其中 S 是每个 t 的状态。γ 是设置为0.99的折扣率,已发现它可以再现多巴胺神经元输出[38]。
在每个 t,ASE被修改为:
![]()
其中 η 是在这些实验中设置为10 nA的学习率系数。当奖励大于期望时,ASE被加强,当奖励小于期望时,ASE被削弱。当期望与奖励匹配时,ASE没有修改。
请注意,奖励 r 对于学习上下文是唯一的。SNN中TD学习的示例包括Potjans等人[19]的机器人网格映射,其中 r 取决于在5 × 5网格中找到到目标方格的最快路径。另一个例子是Kubota和Wakisaka [20]对位置相关记忆的环境学习,其中 r 是根据机器人发生的特定情绪计算得出的。本文实现了长期突触可塑性,其中 r 随着机器人靠近目标而逐渐变大,需要定义目标以学习墙跟随。
(未完待续)

IV. PIONEER ROBOT
如图16所示,模拟的Pioneer 3机器人用于验证自组织SNN的性能。机器人为SNN提供声纳和激光输入,而SNN为机器人提供电机动作。接下来,将对机器人的这三个方面(声纳,激光和电机)进行描述,以了解SNN与机器人外部环境的连接。
有两个声纳阵列用于确定机器人到墙壁的方向。一排在机器人的前面,一排在机器人的后面。每个阵列包含八个声纳传感器,如图17所示。传感器围绕机器人的周围放置,每个传感器的前后间隔20°间隔,侧面传感器间隔40°[42]。机器人周围的16个声纳传感器使周围环境大致360°接近。传感器以公制距离的形式使它们回到物体附近。最靠近墙壁的传感器可显示墙壁相对于机器人的方向,即在机器人的正面,背面或旁边。公式(8)使用此信息从朝向感受体计算出一个ISI。Pioneer机器人还具有激光扫描仪,该激光扫描仪能够检测物体的接近程度。但是,激光扫描仪无法感应到机器人的后半部,这对于判断机器人相对于墙壁的方向是必要的。
激光束连接到机器人的顶部,并位于机器人的前部附近,以便于从右到左扫描0º-180º范围。与声纳一样,激光读数将返回到物体的度量接近度。用激光而不是声纳进行扫描的一个优势在于,声纳传感器的位置是间歇性的,因此当激光扫描每半度时,声纳传感器的位置无法完全感知周围区域,尤其是在近距离时。因此,已知利用激光可以更准确地读取环境,尤其是当墙追踪环境中机器人靠近目标时。
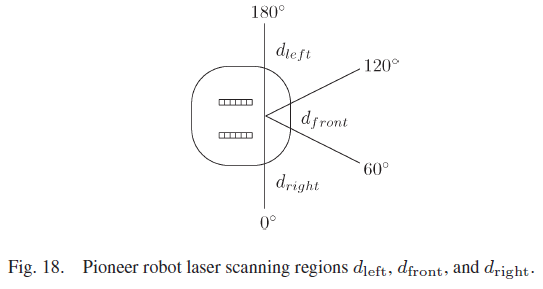
沿墙绕行任务需要有关离墙的距离的知识。如图18所示,机器人前面的区域被任意划分为三个区域,激光扫描仪将读取这些区域。
来自每个区域的最小读数用于为SNN提供三个区域从激光扫描仪到物体的最接近距离。传感器读数以米为单位表示到物体的距离。Pioneer机器人对最远9 m的距离敏感。出于沿墙绕行的目的,不需要区分大于2 m的距离,因此,在传感器读数较大的情况下,该距离设置为2 m。
使用以下映射,三个d接收器中的每一个都将激光输入转换为线性ISI脉冲序列:
![]()
导致输入到第1层的ISI在160-200 ms的范围内。
机器人有三个轮子。机器人后部有一个无动力的旋转脚轮,以支撑机器人的重量并提供平衡,同时允许在各个方向上移动。机器人左侧和右侧的另外两个轮子可以通过电机移动。尽管本文中的速度是恒定的,但每个电动轮都可以以不同的速度在前进和后退方向上移动。组合轮子后,它们可以将机器人操纵到地板上的任何位置。

V. EXPERIMENTAL RESULTS AND ANALYSIS
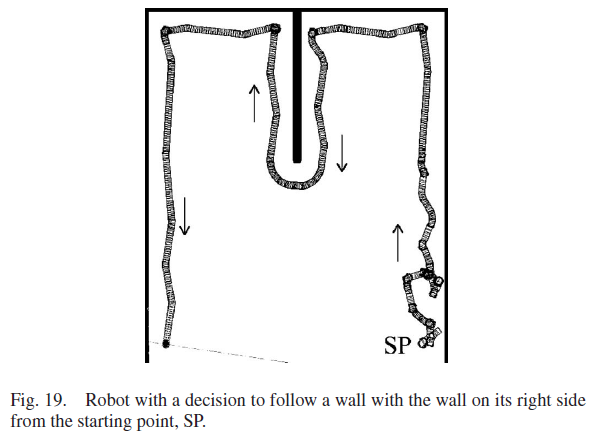
模拟环境由与一堵墙垂直的三堵平行墙组成。中间平行壁比其他平行壁短得多,可以在图19中看到。SNN用三个实验进行了测试。在第一个实验中,SNN被赋予了学习机器人右侧跟随墙的任务。这项任务的目的是确定机器人是否学会在围栏内导航。
机器人被放置在墙边,墙在机器人的右侧。实验过程中经历了每一种距离感,从第1层到第2层的左右群体中的6个神经元都形成了连接。23个第3层神经元与第2层形成了连接,其中10个在左群体中,13个在右群体。然后,这些神经元中的每一个都连接到第4层中最近的地理邻居。由于内部决策是在右侧跟随,两个决策神经元在200 ms的ISI处收到脉冲,这激活了刺激右侧跟随的神经元群体。第4层的13个神经元群体在实验期间被发放,每个都全连接到第5层神经元。12个神经元完成了对三个动作的期望学习。另一个神经元没有足够的时间体验它的环境来尝试所有三个动作。左侧群体中连接了10个第4层神经元,由于这些神经元都没有被发放,因此它们与第5层之间没有形成任何连接。
在完成学习的12个第4层神经元中,有两个神经元学会了让机器人向前移动。四个第4层神经元学会了让机器人左转,没有一个学会让机器人右转。三个神经元学会了向前和向左移动机器人,三个神经元学会了向前和向右移动机器人。图20显示了第4层右侧跟随群体中每个神经元在y轴上学到的ASE分布。+符号代表前向神经元的ASE值,o代表导致左转的神经元的ASE值,x是右转神经元的突触值。未显示切断连接处和学习尚未完成的连接处的ASE值。
图21显示了在实验1中的学习序列期间,来自第八层中4个神经元刺激三层中5个神经元的ASE修改。实线代表前向神经元的ASE。虚线(学习epoch 1的最高ASE)是右侧神经元的ASE,虚线(epoch 1的最低 ASE)是左侧神经元的ASE。所有ASE值都初始化为100。以随机顺序选择运动(向前、左转和右转)。第4层到第5层ASE使用TD学习规则从100进展到110,然后到109.9。在t = 3没有错误,因为学习规则已经收敛到正确的期望。在t = 3之后保持连接,因为ASE并不比在t = 0时弱。ASE到右侧神经元的ASE使用TD学习规则从100到114.243,然后到109.857,最后到108.429。随着机器人逐渐了解向右转的期望,发生了较小的更新。左侧神经元的ASE降低到97.2429,受体输入的变化足以停止学习序列。直到左转和右转都完成后,权重才再次发生变化。发生这种情况时,左侧神经元的ASE比右侧神经元的ASE少11.186,导致左侧ASE被切断。在学习后第五层中的4个神经元每次发放时,抑制与前向和右侧神经元的突触连接都会导致突触后增强,因此机器人会向前-向右移动。
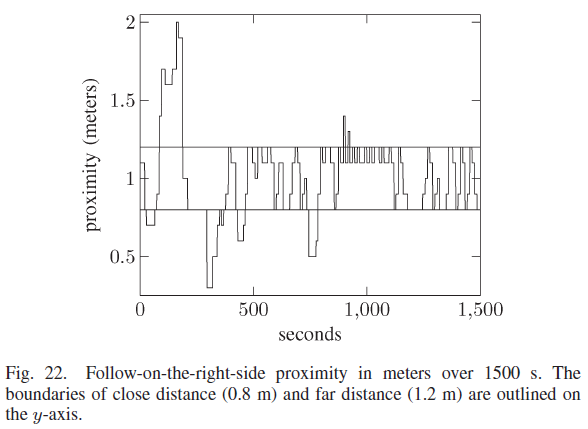
机器人与墙壁的接近度如图22所示,持续时间为1500 秒(25 分钟)。目标距离显示在0.8和1.2 m处的两条水平线内。随着学习过程的开始,机器人在前500 秒的大部分时间都在目标距离之外。大多数学习已在800 秒前结束。机器人在1000 s之前两次偏离目标区域,这与图19中的180° 转弯相吻合。然而,机器人之前在远离墙壁时学习了正确的动作并迅速返回到目标距离。在最后的500 秒内,机器人没有偏离目标距离,因为机器人已经学会了在目标距离时针对墙壁的每个不同方向的正确动作。
机器人成功地适应了新环境,并学会了在右侧跟随墙。图19显示了机器人在第一个实验中学习正确运动决策时的路径,图23显示了实验结束时的SNN连接。
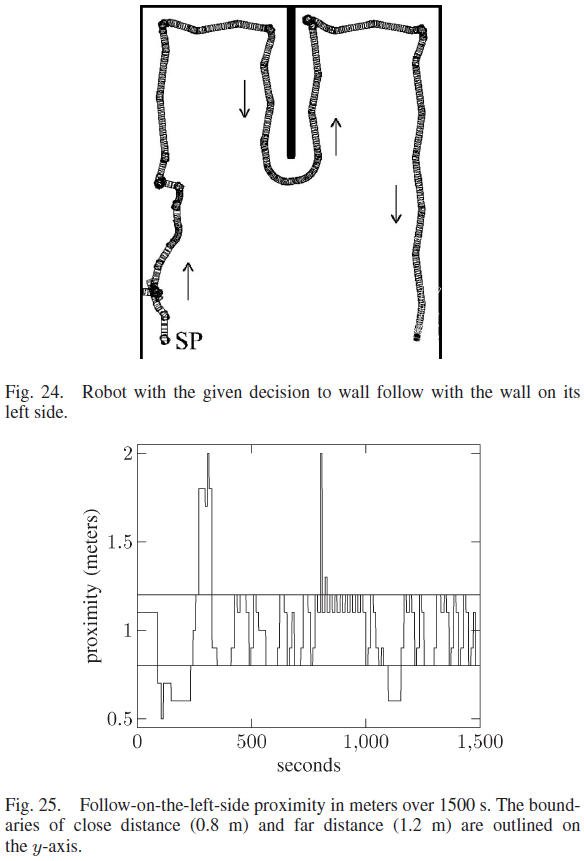
第二个实验涉及沿左侧墙绕行,机器人的路径如图24所示。连接性与之前的实验保持一致。在第二个实验中,7个第3层神经元连接到第2层神经元;五个神经元在左侧,两个在右侧。第一个实验增加的连接性导致第3层和第4层中有30个连接的神经元。该实验中的内部决策是跟随左侧的墙壁,因此,决策神经元以160 ms的ISI接收脉冲。这仅导致第4层的左侧变为活动状态。层4中的12个神经元完成学习。层4中的3个神经元被发放,但不足以让每个动作都被学习并因此保持全连接。有两个神经元在第3层和第4层的右侧连接,同时在左侧跟随,但在右侧跟随时没有发放,并且与第5层没有连接。
机器人在左侧跟随时靠近墙壁的情况如图25所示。机器人在前400秒的大部分时间都在目标距离之外,因为在左侧学习跟随墙壁的过程开始了。当机器人到达图24所示的180° 转弯时,机器人在400到800秒内停留在目标距离内。在此转弯期间,机器人两次超出目标距离;然而,它利用之前远离墙壁时获得的知识迅速返回。在1100 s时,机器人的前侧和左侧都非常靠近墙壁,必须学习正确的动作才能从墙壁返回目标距离和方向。机器人随后没有偏离其目标。
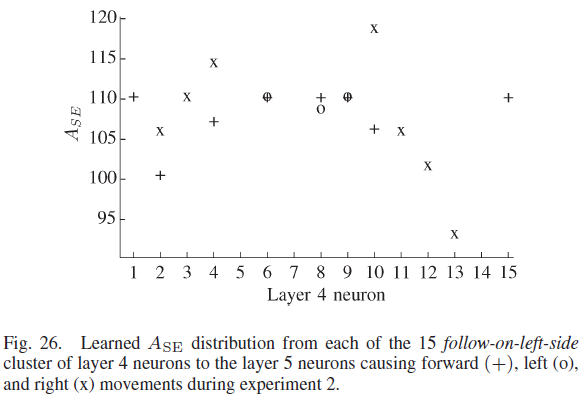
图26显示了每个第4层神经元的学到的ASE(y轴)分布。在左侧完成学习跟随墙的12个第4层神经元中,有两个神经元学会了让机器人向前移动。没有神经元了解到左转具有最大的期望。然而,四个第4层神经元学会了将机器人向右转动。三个神经元学会了向前和向左移动机器人,三个第4层神经元学会了向前和向右移动机器人。
第二个实验结束时自组织SNN的连通性如图27所示。
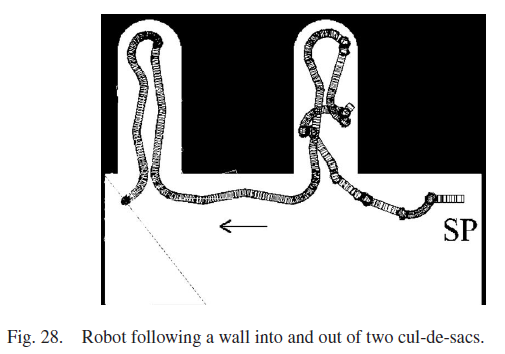
许多移动机器人研究人员使用死胡同环境作为跟随墙行为的基准实验。 最后的实验涉及一个房间,里面有两条通往死胡同的路径。当机器人向第一个死胡同移动时,它的动作很混乱,因为必须学习每个动作的期望。在机器人到达第二个死胡同之前,SNN了解了许多期望,并且它成功地跟随进入了这个随后的死胡同。本实验中机器人的运动路径如图28所示。从本实验中也可以看出,机器人成功地逃离了两个死胡同,这证明了所提出的控制方法的鲁棒性。
VI. DISCUSSION
SNN不区分墙和任何障碍物或其他物体。接近传感器仅与物体与机器人的特定距离有关。因此,SNN接近目标(如盒子或桌子)的方式与实验中接近墙壁的方式相同,机器人在其左侧或右侧围绕物体移动。
实验中使用的房间让机器人遇到每一个可能的距离范围,这些知识被学习并保存在第一层和第二层之间的神经元的全连接中。在第3层有30个由连接的神经元所表示的独特的距离和方向。机器人在学习过程中会遇到大量的距离和角度,这是由于机器人在学习过程中会将自己放置在许多不同的近距和方向上。
机器人跟墙所需观察的距离与机器人前方是否与物体有足够的距离、跟墙侧是否为理想距离、机器人在给定方向下的轨迹是否良好有关。这些知识只通过前面的两个距离神经元和三个侧面距离和方向神经元传递。所提出的设计结果包括:机器人只知道前方物体是近还是远;机器人的侧面是靠近、中距离还是远离物体;方向是朝向、平行还是远离物体。将更多的神经元添加到第1层将产生以下结果:它将提供不同程度的接近、理想和远离;机器人应该能够更精确地调整自己以适应对象;并且轨迹不会像实验中所示的那样弯曲。
SNN能够处理传感器数据中的噪声。当接收到传感器输入的神经元在接近边界处激活时,向d或朝向感受器引入的噪声只能破坏SNN中的活动。例如,假设一个传感器太近,并且非常接近太近和目标距离的边界。噪声可能会导致代表目标距离的神经元变得活跃,并使距离太近的神经元变得不活跃。然而,如果这导致机器人错误地进一步移动到过近区域,则后续读数将足够远地进入过近区域,噪声无法将读数推入目标距离,并且每个区域内都有足够的空间,使得机器人距离第5层神经元移动的目标仍然足够远把它拿走。图19和24表明,机器人能够成功地执行任务,没有噪声、不确定性和不精确性的问题。
VII. CONCLUSION
本文提出了一种基于传感器融合、路由动态突触、自组织和TD学习的仿生SNN机器人控制系统。实验表明,机器人通过长期的突触修改学习到正确的动作。SNN认识到,这种行为通过其自组织的记忆结构,从其经验丰富的环境中带来了最大的期望。促进突触通过SNN应用了正确的信息路由,机器人成功地学会了跟随墙的每一边。
所提出的SNN能够感知其所处的环境,并使用从相同环境中的先前经验中获得的期望来执行任务。人类能够更进一步,不用呆在房间里就能回忆起房间的精确地图。这将为今后人工神经网络的研究提供一个非常有趣的课题。从一个房间的精确地图,可以与当前传感器输入进行比较,以确定机器人在哪个房间,或者房间内的元素是否已经移动。
高级算法如Kalman滤波能够预测动态目标的轨迹。由于作者希望在较低的水平上实现他们的工作,而且大脑做出预测的方式还没有完全被理解,因此这一点没有被纳入提议的SNN中。一般来说,对于SNN要实现这一点,可能需要反馈回路来给数据提供时间维度,并且从那里可以进行预测。如果在未来的工作中能够实现这一点,那么通过投射动态物体的运动并移动机器人来避开它们,将使所提出的SNN变得更好。
本文提出的SNN在有限的软件计算条件下,通过沿墙绕行试验证明了其功能。由于顺序计算每个神经元的时间开销和每个突触的动态状态,所提出的SNN比其他沿墙绕行应用要慢。在硬件中模拟每个神经元和突触并行工作的SNN(就像在大脑中发生的那样)将提高计算速度。未来工作的下一个项目将把提议的SNN原样放在连接到真实机器人的现场可编程门阵列上。
在转移到硬件之后,SNN最终可以用于高级应用。如第六节所建议的,将第1层神经元的数量增加到网络的当前设计中,将允许从更丰富的传感器(如照相机)进行处理,从而增强环境的敏感性。然后SNN将有可能基于目标识别来学习更高级的行为,而不是仅基于当前存在的距离识别来学习。通过添加声音等感觉,机器人可以根据听觉指令执行动作,从而改进关于跟随墙壁哪一侧的决定。进一步的输出神经元可以实现更精确的运动。这些附加功能可以使用本文中描述的机制,如路由的短期可塑性和学习的长期可塑性。然而,由于增加了计算成本,仅建议在硬件上增加SNN的生物真实性。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号