Evolved Policy Gradients
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NeurIPS, (2018)
Abstract
我们提出了一种元学习方法,用于学习基于梯度的RL算法。这个想法是要逐步形成一种可微的损失函数,这样智能体就可以通过优化其策略以最大程度地减少这种损失,获得较高的奖励。损失是通过智能体经验的时序卷积来参数化的。由于这种损失在考虑智能体历史方面的能力上具有很高的灵活性,因此可以快速学习任务。实验结果表明,与现成的策略梯度方法相比,我们的进化策略梯度算法(EPG)在几种随机环境下可以更快地学习。我们还证明,EPG的学习损失可以推广到分布外的测试时间任务,并且表现出与其他流行的元学习算法不同的行为。
1. Introduction
当人们学会解决新的控制任务(例如拉小提琴)时,他们会立即感觉到该尝试什么。刚开始,他们可能会尝试快速粗暴的冲程,然后发出刺耳的声音,直觉就会知道这是错误的做法。仅仅通过聆听产生的声音,他们就可以感觉到是否正在朝着目标前进。实际上,人类可以使用非常完善的内部奖励函数,这些函数源于在其他运动任务上的先前经验,或者可能是通过听和演奏其他乐器获得的(36; 49)。
相反,大多数当前的RL智能体从头处理每个新任务。最初,他们不知道要尝试什么动作,也不希望得到什么结果。相反,他们完全依靠外部奖励信号来指导其初始行为。出自这样一片空白,RL智能体学习简单技能所需的时间比人类更长也就不足为奇了(21)。
我们在本文中的目的是设计一种对什么构成在新任务上取得进展具有先验概念的智能体。我们不是通过学到的行为策略对知识进行显式编码,而是通过学到的损失函数对知识进行隐式编码。最终目标是可以使用此损失函数快速学习新任务的智能体。
可以将这种方法视为元学习的一种形式,我们在其中学会学习算法。与传统机器学习中的挖掘规则不同的是,元学习不像在传统的机器学习中那样挖掘跨数据点的规则,而是通过注入任务分布的先验知识来设计能够跨任务泛化的算法(12)。
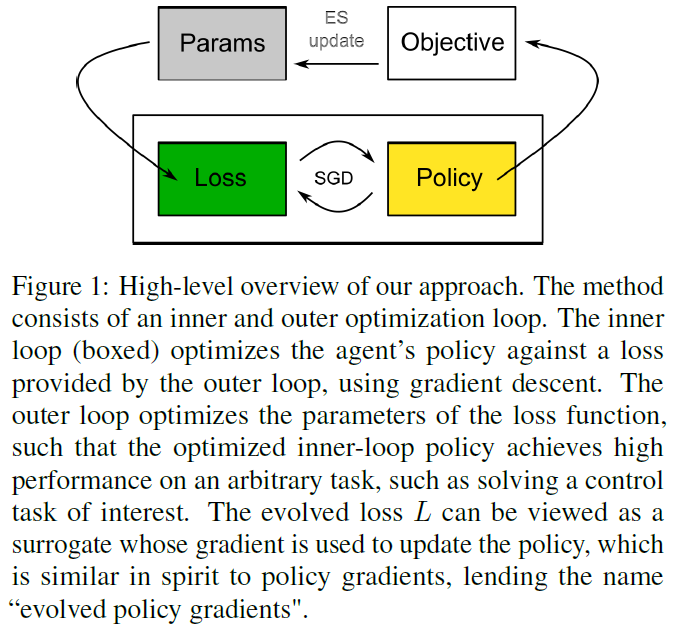
我们的方法包括两个优化循环。在内环中,智能体从一组任务的特定分布中学习解决任务的方法。智能体通过最小化外环提供的损失函数来学习解决此任务。在外循环中,调整损失函数的参数,以使在内环学习后获得的最终回报最大化。图1概述了这种方法。
尽管可以使用随机梯度下降(SGD)来优化内环,但是优化外环会带来很大的困难。外部目标的每次评估都需要训练一个完整的内环智能体,并且该目标不能写成我们正在优化的损失参数的显式函数。由于此优化问题中缺乏易于利用的结构,因此我们将进化策略(ES)(35; 46; 16; 37)作为黑盒优化器。进化损失L可以看作是替代损失(43; 44),其梯度用于更新策略,其本质上与策略梯度类似,引出"进化策略梯度"的名称。
除了对先验知识进行编码外,与当前的RL方法相比,学到的损失还具有许多优势。由于RL方法针对短期回报进行优化而不是考虑整个学习过程,因此它们可能会陷入局部最小值,而无法探索整个搜索空间。先前的工作添加了强调探索的辅助奖励项(8; 19; 32; 56; 6; 33)和熵损失项(31; 42; 15; 26)。通常使用单独的超参数来权衡这些项,该超参数不仅取决于任务,而且取决于智能体正在访问状态空间的哪一部分。因此,尚不清楚如何以有原则的方式将这些项包括在RL算法中。
使用ES来进化损失函数,可以使我们优化真实的目标,即最终训练到的策略性能,而不是短期回报。我们的方法还通过允许损失函数适应环境和智能体历史来改进标准RL算法,从而导致更快的学习速度,并且无需外部奖励即可获得学习的潜力。理论上,EPG可以与策略初始化元学习算法(例如MAML(11))结合使用,因为EPG对其优化的策略没有任何限制。
最近有很多关于元学习策略的工作,例如,(10; 59; 11; 25),值得一提的是为什么元学习损失而不是直接元学习策略?我们的动机是,我们希望损失函数是可以在完全不同的任务之间很好地泛化的目标。手工设计的损失函数当然是正确的:设计良好的RL损失函数,例如(45)中的函数,可以非常普遍地应用,发现它可以解决从玩Atari游戏到控制机器人(45)的问题。在第4节中,我们发现有证据表明,EPG所学到的损失可以训练智能体来解决在训练EPG的任务分布之外的任务。这种泛化行为与MAML (11)和RL2 (10)存在定性差异,这两者是直接元学习策略的方法,为损失学习的泛化潜力提供了初步的指示。
我们的贡献包括:
- 确切表达一种元学习方法,为RL智能体(称为EPG)学习可微的损失函数。
- 通过ES优化此损失函数的参数,克服了最终回报不是损失参数的显式函数的挑战。
- 设计一种损失架构,该架构通过时序卷积考虑智能体历史。
- 证明EPG产生了学习到的损失,与现成的策略梯度方法相比,它可以更快地训练智能体。
- 表明EPG学到的损失可以推广到分布外的测试时间任务,表现出与其他流行的元学习算法不同的行为。
我们在第2节中阐述了这一概念。第3节介绍了主要算法,第4节显示了其在几种随机连续控制环境中的结果。在第5节中,我们将我们的方法与文献中最相关的观点进行了比较。我们在第6节中讨论时结束了本文。EPG的实现可从以下网站获得:http://github.com/openai/EPG.
2. Notation and Background
3. Methodology
3.1. Metalearning Objective
3.2. Algorithm
3.3. Architecture
4. Experiments
4.1. Performance
4.2. Analysis
4.3. Generalization
5. Relation to Existing Literature
6. Discussion
A. Environment Description
B. Additional Experiments
C. Experiment Hyperparameters


 浙公网安备 33010602011771号
浙公网安备 33010602011771号