元强化学习简介
元强化学习简介
本来笔者只是想简单做个元强化学习的材料整理,但是做着做着,感觉还是可以讲点什么东西的。虽然笔者能力有限,但是还是希望能够分享一点拙见,以供后来者上手参考。也欢迎大家批评指正。
要讲元强化学习,首先肯定是要先了解一下元学习的相关概念。
学会如何学习的方法被称为元学习。元学习的目标是在接触到没见过的任务或者迁移到新环境中时,可以根据之前的经验和少量的样本快速学习如何应对。元学习有三种常见的实现方法:
- 学习有效的距离度量方式,即事物背后的关联(基于度量的方法);
- 使用带有显式或隐式记忆储存的RNN,学习如何建模(基于模型的方法);
- 训练以快速学习为目标的模型,学会如何学习(基于优化的方法)。
关于更加广泛的meta-RL开源代码调研,参见https://www.cnblogs.com/lucifer1997/p/13698232.html
目录:
元学习
Meta-Learning: Learning to Learn Fast
知乎-元学习(Meta Learning)与迁移学习(Transfer Learning)的区别联系是什么?
知乎-有哪些比较好的元学习(meta learning)领域的学习资源?
Meta-Learning in Neural Networks: A Survey
好的机器学习模型经常需要大量的数据来进行训练,但人却恰恰相反。小孩子看过一两次猫和小鸟后就能分辨出它们的区别。会骑自行车的人很快就能学会骑摩托车,有时候甚至不用人教。那么有没有可能让机器学习模型也具有相似的性质呢?如何才能让模型仅仅用少量的数据就学会新的概念和技能呢?这就是元学习要解决的问题。
我们期望好的元学习模型能够具备强大的适应能力和泛化能力。在测试时,模型会先经过一个自适应环节(adaptation process),即根据少量样本学习任务。经过自适应后,模型即可完成新的任务。自适应本质上来说就是一个短暂的学习过程,这就是为什么元学习也被称作学会学习。
元学习可以解决的任务可以是任意一类定义好的机器学习任务,像是监督学习,强化学习等。具体的元学习任务例子有:
- 在没有猫的训练集上训练出来一个图片分类器,这个分类器需要在看过少数几张猫的照片后分辨出测试集的照片中有没有猫(小样本学习)。
- 训练一个玩游戏的AI,这个AI需要快速学会如何玩一个从来没玩过的游戏(元强化学习)。
机器学习围绕一个具体的任务展开,然而在生物体的一生中,学习的永远不只是一个任务。与之相对应的叫做元学习,元学习旨在掌握一种学习的能力,使得智能体可以掌握很多任务。如果用数学公式表达,这就好比先学习一个函数F(x),代表一种抽象的学习能力,在此基础上学习f(x)对应具体的任务。
我们做一个比喻,机器学习学习某个数据分布X到另一个分布Y的映射。而元学习学习的是某个任务集合D到每个任务对应的最优函数f(x)的映射(任务到学习函数的映射)。基本的元学习思路是学到一个能够很好地筛选得到有用的归纳偏差(inductive bias,即"学习器用来预测尚未遇到的给定输入的输出的一组假设")的能力,在此基础上寻找能够适应多任务的F。这个想法有点像是我们面对某个只有少量数据的任务时,会使用在相关任务的大数据集上预训练的模型,然后进行微调(fine-tuning)。像是图形语义分割网络可以用在ImageNet上预训练的模型做初始化。相比于在一个特定任务上微调使得模型更好地拟合这个任务,而元学习更进一步,它的目标是让模型优化以后能够在多个任务上表现得更好,类似于变得更容易被微调。
小样本学习(Few-shot classification)是元学习的在监督学习中的一个实例。数据集D经常被划分为两部分,一个用于学习的支持集(support set) S,和一个用于训练和测试的预测集(prediction set) B,即 D=⟨S,B⟩ 。K-shot N-class分类任务,即支持集中有N类数据,每类数据有K个带有标注的样本。
常见方法
元学习主要有三类常见的方法:基于度量的方法(metric-based),基于模型的方法(model-based),基于优化的方法(optimization-based)。Oriol Vinyals在NIPS 2018的meta-learning symposium上做了一个很好的总结:

(*) kθ是一个衡量 xi 和 x 相似度的核方法。
接下来我们会回顾各种方法的经典模型。
一、基于度量的方法
基于度量的元学习的核心思想类似于最近邻算法(k-NN分类、k-means聚类)和核密度估计。该类方法在已知标签的集合上预测出来的概率,是support set中的样本标签的加权和。 权重由核函数kθ算得,该权重代表着两个数据样本之间的相似性。
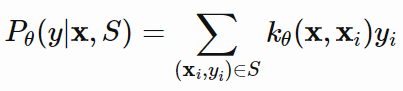
因此,学到一个好的核函数对于基于度量的元学习模型至关重要。Metric learning正是针对该问题提出的方法,它的目标就是学到一个不同样本之间的度量或者说是距离函数。任务不同,度量质量的定义也不同。但它一定在任务空间上表示了输入之间的联系,并且能够帮助我们解决问题。
下面列出的所有方法都显式的学习了输入数据的嵌入向量(embedding vectors),并根据其设计合适的核函数(点击查看详情)。
-
Convolutional Siamese Neural Network
-
Matching Networks
- Simple Embedding
- Full Context Embedding
-
Relation Network
-
Prototypical Networks
二、基于模型的方法——利用RNN网络和外部存储来实现"记忆"
最直观的方法,使用基于RNN的技术记忆先前任务中的表征等,这种表征将有助于学习新的任务。
基于模型的元学习方法不对 Pθ(y|x)作出任何假设。Pθ(y|x)是由一个专门用来快速学习的模型生成的,快速学习指的是这个模型可以根据少量的训练快速更新参数。有两种方式可以实现快速学习:1. 设计好模型的内部架构使其能够快速学习,2. 用另外一个模型来生成快速学习模型的参数。
1. Memory-Augmented Neural Networks
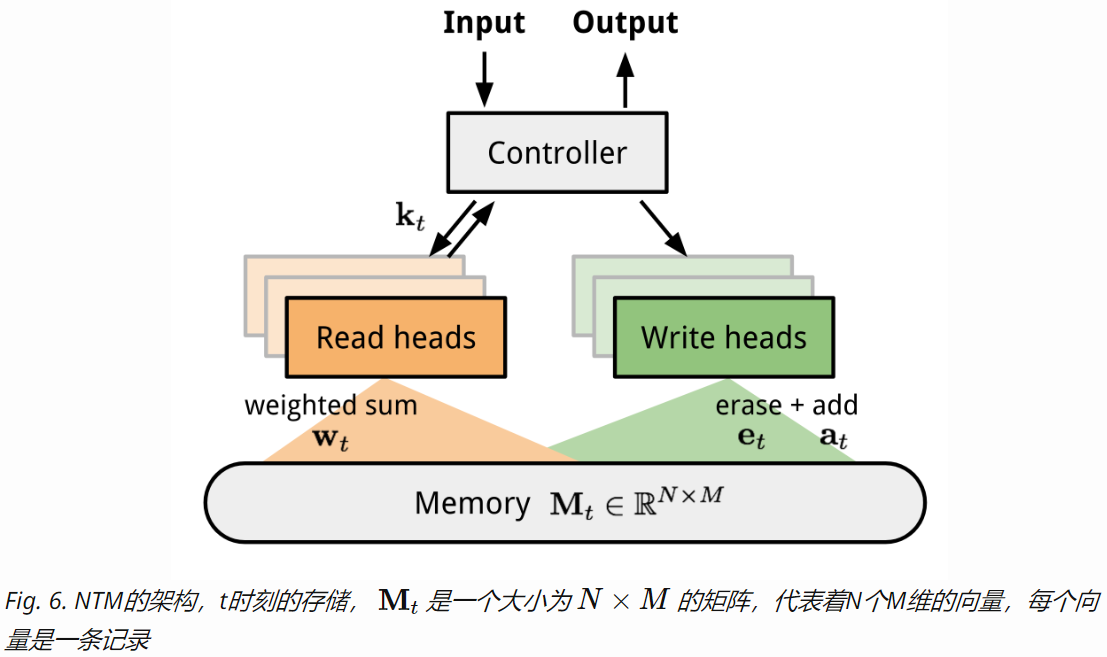
许多模型架构使用了外部存储器来帮助神经网络学习,像是Neural Turing Machines和Memory Networks。使用外部存储器,让神经网络能够更容易地学到新知识并提供给以后使用。这样的模型被称为MANN("Memory-Augmented Neural Network")。注意,只使用了内部存储器的RNN并不是MANN,比如RNN、LSTM。
MANN的目的是在仅给定几个训练样本的情况下,快速编码新的信息并适应新的任务,因此MANN非常适合用于元学习。Santoro et al. (2016)以Neural Turing Machine (NTM)为基础,对训练和存储读写机制(也称为"寻址机制",即如何对存储向量分配注意力权重)做了一系列的修改。如果你对NTM或寻址机制不太熟悉的话,可以参见原作者之前博文中的NTM介绍。
简要回顾一下,NTM由一个控制器神经网络和存储器组成。控制器学习如何通过软注意力(soft attention)读写存储器,而存储器相当于是一个知识库。注意力权重是由寻址机制生成的,由询问的内容和位置共同决定。
MANN for Meta-Learning
为了在元学习中使用MANN,我们需要训练这个网络使得它能够快速提炼新任务的信息,而且能够快速稳定的查询之前存储的特征。
Santoro et al., 2016提出了一种有意思的训练方式,他们强迫存储器保留当前样本的信息直到对应的标签出现。在每个回合中,标签有一步的延迟 ,即每次给出的训练对为(xt+1,yt)。
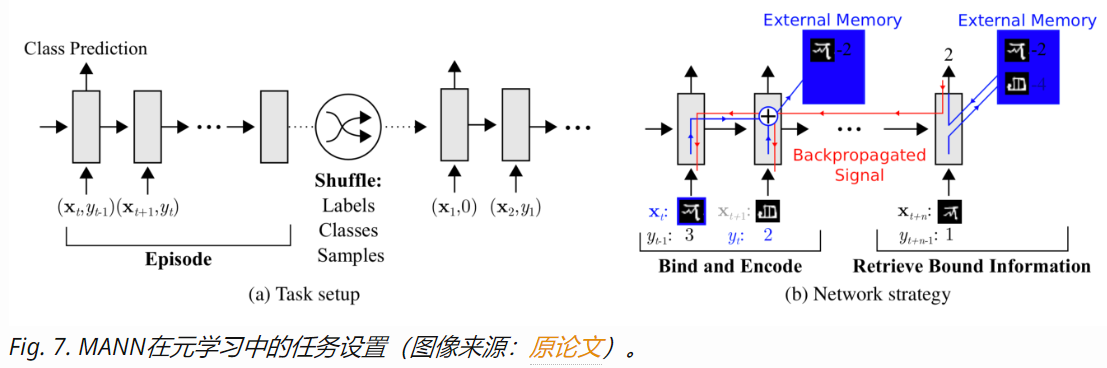
通过这种设定,MANN会学到要记住新数据集的信息,因为存储器需要保留着当前输入的信息,并且在对应的标签出现的时候取回之前存储的信息进行预测。
接下来,我们看看存储器是完成信息的存储和取回的。
Addressing Mechanism for Meta-Learning
为了让模型更加适应元学习,除了改变训练过程,作者还增加了一个完全基于内容的寻址机制。
如何从存储器中取回信息?
读取注意力(read attention)完全由内容相似度决定。
首先,根据 t 时刻的输入x,控制器生成一个键值特征向量kt。然后用类似于NTM的方法,计算键值特征向量和存储器中每个向量的cosine距离,经过softmax归一化,得到一个读取权重向量![]() 。读取向量rt是对存储器中所有向量的加权和:
。读取向量rt是对存储器中所有向量的加权和:

Mt是 t 时刻的存储器矩阵,Mt(i)是该矩阵中的第 i 行,即第 i 个向量。
如何往存储器中写入信息?
写入新信息的寻址机制跟缓存置换机制很像。为了更好的适应元学习的任务,MANN使用的是最近最少使用算法(Least Recently Used Access, LRUA)。LRUA算法会优先覆盖最少使用的,或者最近刚用过的存储位置。
除了LRUA,还有许多其他的缓存置换算法。根据场景的不同,其他的算法可能有更好的表现。另外相比于人为指定一种缓存替换机制,根据存储使用的规律,学出一套寻址策略可能效果更好。
这里的LRUA以一种所有运算都可微分的方式实现:

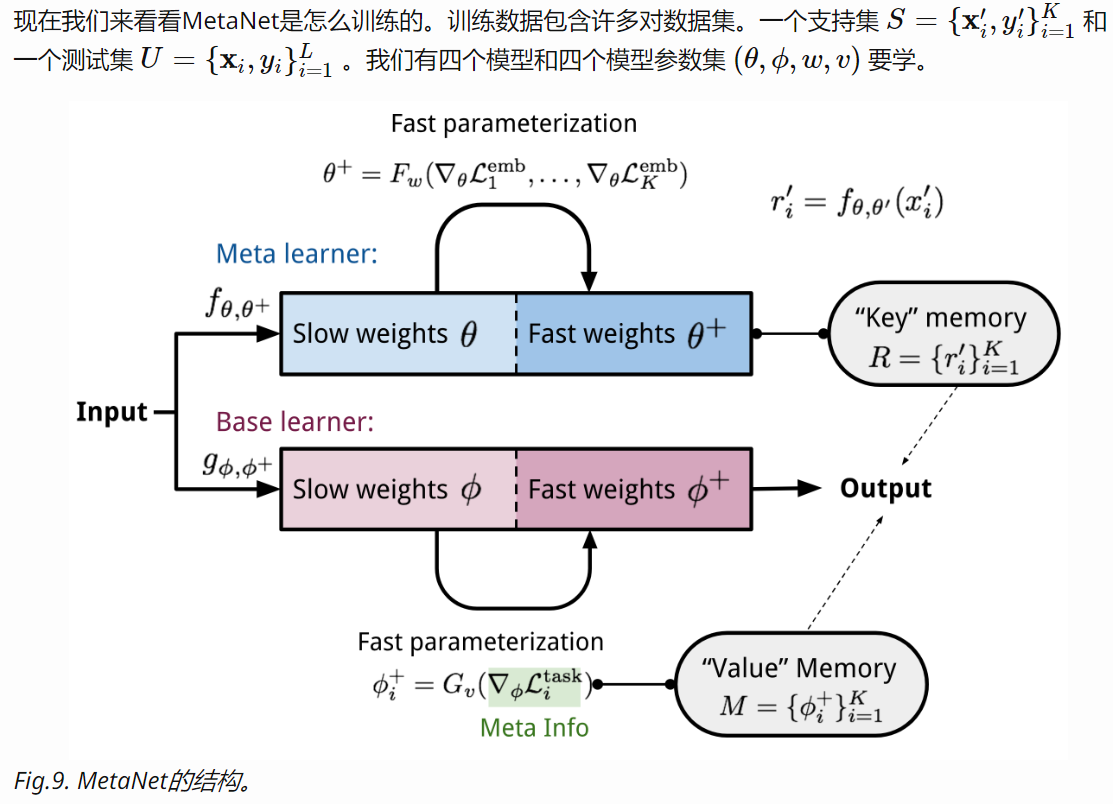
2. Meta Networks
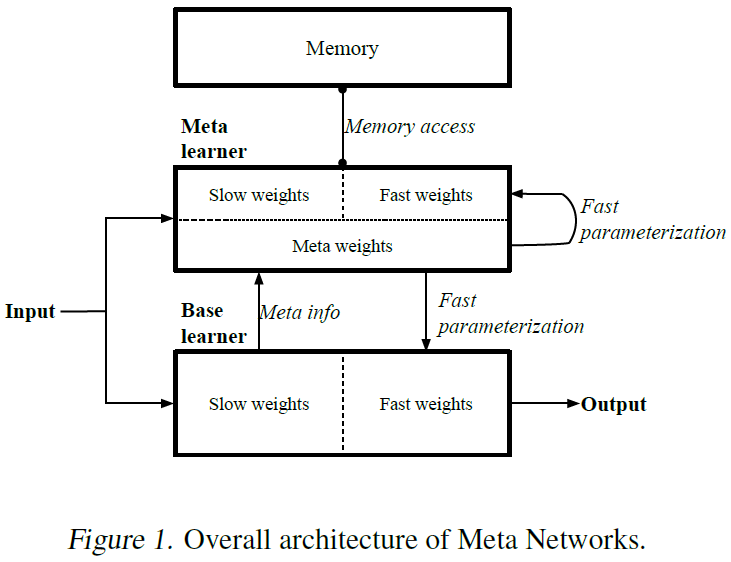
Meta Networks (Munkhdalai & Yu, 2017),简称MetaNet,是一个专门针对多任务间快速泛化设计的元学习模型,模型结构和训练过程都经过了调整。
MetaNet的总体结构如图1所示。MetaNet由两个主要的学习组件组成,即基学习器和元学习器,并配备了外部存储器。学习在不同的空间(即元空间和任务空间)中的两个级别进行。基学习器在输入任务空间中执行,而元学习器在与任务无关的元空间中操作。通过在抽象元空间中进行操作,元学习器支持持续学习并跨不同任务执行元知识获取。为此,基学习器首先分析输入任务。然后,基学习器以较高阶元信息的形式向元学习器提供反馈,以解释其在当前任务空间中的状态。基于元信息,元学习器可以快速参数化自身和基学习器的参数,以便MetaNet模型可以识别输入任务的新概念。具体来说,MetaNet的训练权重在不同的时间尺度上发展:通过学习算法(即REINFORCE)更新标准慢速权重,在每个任务的范围内更新任务级快速权重,并对于特定的输入示例更新示例级快速权重。最终,配备有外部存储器的MetaNet允许快速学习和归纳。
在MetaNet框架下,定义可以从学习者那里获得的元信息的类型非常重要。尽管元信息的其他表征也适用,但我们使用损失梯度作为元信息。MetaNet具有两种类型的损失函数,它们具有不同的目标:为良好表征学习器标准定义的表征(即嵌入)损失和用于输入任务目标的主要(任务)损失。
配备外部存储器的MetaNet可以看作是存储器增强神经网络(MANN)。
Fast Weights
MetaNet的快速泛化能力依赖于"快参数(fast weights)"。一般神经网络的权重是根据目标函数进行随机梯度下降更新的,但这个过程很慢。一种更快的学习方法是利用另外一个神经网络,预测当前神经网络的参数,预测出来的参数被称为快参数。而普通SGD生成的权重则被称为慢参数。
在MetaNet中,损失梯度作为元信息,被用于生产学习快参数的模型。慢参数和快参数在神经网络中被结合起来用于预测。快参数是针对任务进行优化产生的参数,使用快参数相当于针对当前的任务进行了优化。下图显示了结合慢参数和快参数的层增强MLP,其中⨁是元素加法.
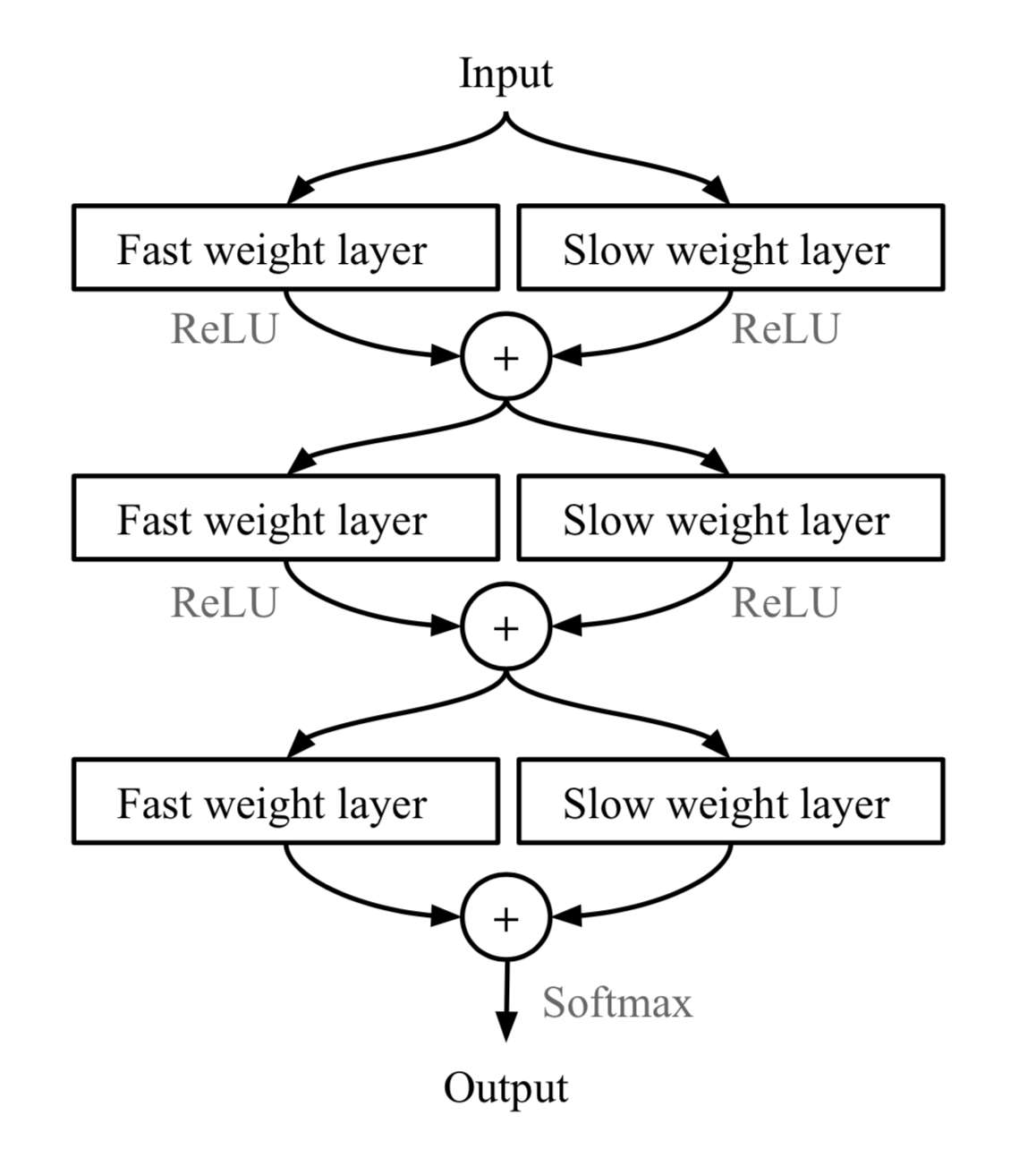
Model Components
MetaNet的关键组件是:
- fθ: 一个由θ决定的编码函数,发挥着元学习器的作用。负责把原始输入编码为特征向量。类似Siamese Neural Network,我们希望训练这个编码函数使得能够根据其生成的特征向量判断两个输入是否属于同一类(验证任务)。
- gϕ: 一个由ϕ决定的基学习器,负责完成真正的学习任务。
如果我们就此打住的话,这基本就是Relation Network。 但MetaNet,给这两个模型额外增加了快参数(参加Fig. 8)。
因此,我们需要额外两个模型,分别用于生成 f 和 g 的快参数。
- Fw: 一个由 w 决定的LSTM,用于学习嵌入函数 f 的快参数 θ+。它把 f 在验证任务上的损失梯度作为输入。
- Gv: 一个由 v 决定的神经网络,根据基学习器 g 的损失梯度学习其快参数 ϕ+。学习器的损失梯度被视作任务的元信息。

三、基于优化的方法——学习微调 (Learning to Fine-Tune)
深度学习模型通过反向传播梯度进行学习。然后基于梯度的优化方法并不适用于仅有少量训练样本的情况,也很难在短短几步之内达到收敛。那怎样才能调整现有的优化算法使得模型能够在仅有少量样本的情况下学好呢?这就是基于优化的元学习算法的目标。
- LSTM Meta-Learner
- Why LSTM?
- Model Setup
- MAML
- First-Order MAML
- Reptile
- The Optimization Assumption
- Reptile vs FOMAML
元强化学习
https://lilianweng.github.io/lil-log/2019/06/23/meta-reinforcement-learning.html
https://blog.floydhub.com/meta-rl/
根据上面元学习的分类,目前主流的元强化学习方法主要可以分为两类:
- 基于模型的元强化学习(当下比较火热的类脑方法,利用RNN可以与大脑的前额叶皮层建立对应)
- 基于优化的元强化学习(用于元强化学习的元学习算法,例如MAML)
一、基于模型的元强化学习
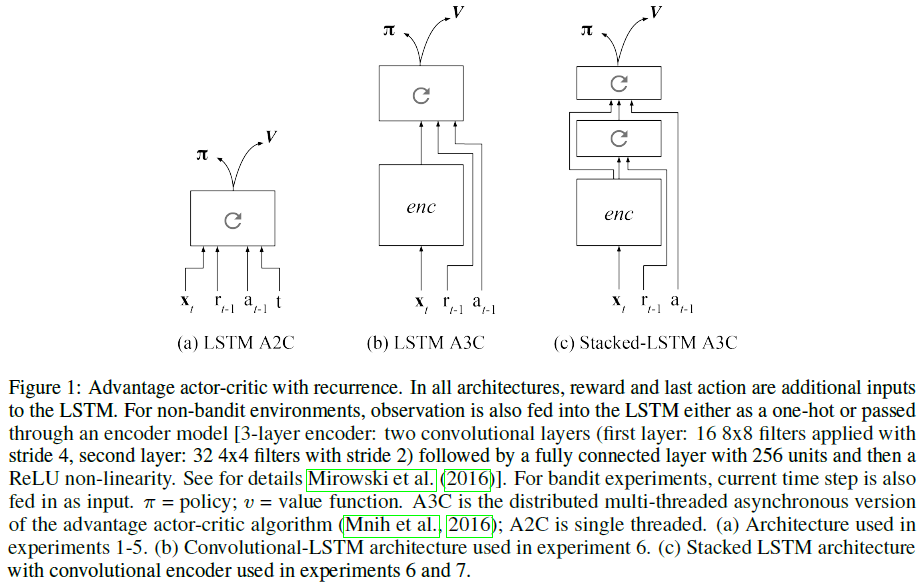
基于模型的元RL的总体配置与普通的RL算法非常相似,不同之处在于,除了当前状态st之外,最近奖励rt-1和最近动作at-1也被合并到策略观察中。
- RL:πθ(st) → A上的一个分布
- 元RL:πθ(at-1, rt-1, st) → A上的一个分布
此设计的目的是将历史记录馈入模型,以便策略可以内化当前MDP中状态,奖励和动作之间的动态,并相应地调整其策略。这与Hochreiter系统中的设置非常吻合。Meta-RL和RL2都实施了LSTM策略,而LSTM的隐含状态充当了跟踪轨迹特征的记忆。由于该策略是周期性的,因此无需明确地将最近状态作为输入提供。
训练过程如下:
- 采样得到一个新的MDP,Mi ~ M;
- 重置模型的隐含状态;
- 收集多个轨迹并更新模型权重;
- 从步骤1开始重复。
元RL中包含三个关键组件:
- A Model with Memory:RNN保持隐含状态。因此,它可以通过在部署期间更新隐含状态来获取并记住有关当前任务的知识。没有记忆,元RL将无法工作。
- Meta-learning Algorithm:元学习算法是指我们如何更新模型权重以进行优化,以便在测试时快速解决看不见的任务。在Meta-RL和RL2论文中,元学习算法都是LSTM的普通梯度下降更新,其中MDP的切换之间具有隐含状态重置。
- A Distribution of MDPs:尽管智能体在训练期间面临各种环境和任务,但它必须学习如何适应不同的MDP。
当然,在本文该分类的研究中,把最近的一些使用RNN的方法也算入该类中。
Learning to Reinforcement Learn: CogSci, 2017
[Code] https://github.com/awjuliani/Meta-RL (Tensorflow)
[Target] 元学习用于快速学习的RNN权重;
[Feature] 基于上下文的元RL方法;
近年来,深度RL系统在许多具有挑战性的任务领域中都获得了超出人类的性能。但是,此类应用的主要局限性在于它们对大量训练数据的需求。因此,当前的一个关键目标是开发能够快速适应新任务的深度RL方法。在当前的工作中,我们介绍了应对这一挑战的新颖方法,我们将其称为深度元RL。先前的工作表明,循环网络可以在完全受监督的上下文中支持元学习。我们将此方法扩展到RL设置。出现的是使用一种RL算法训练的系统,但其循环动态实现了第二个非常独立的RL程序。第二个学习到的RL算法可以在任意方面与原始算法不同。重要的是,由于它是被学习的,因此将其配置为利用训练域中的结构。我们通过一系列七个概念验证实验来解开这些问题,每个实验都检验了深度元RL的关键方面。我们考虑了扩展与扩大该方法的前景,并指出了对神经科学潜在的重要意义。
让我们将马尔可夫决策过程(MDP)的分布(先验)写为D。我们想要证明元RL能够学习先验相关的RL算法,从某种意义上说,它将在从D或D的微小修改获得的MDP上平均表现良好。适当结构化的智能体,嵌入RNN,通过回合与一系列MDP环境(也称为任务)交互来进行训练。在新回合开始时,对新的MDP任务m~D和该任务的初始状态进行采样,并重置智能体的内部状态(即,其循环单元上的激活模式)。然后,智能体程序将在此环境中执行一定离散时间步骤的动作选择策略。在每个步骤 t 处,根据在当前回合期间在MDP m中交互的智能体的整个历史Ht = {x0, a0, r0, ... , xt-1, at-1, rt-1, xt}的函数执行动作at ∈ A (从回合开始以来观察到的状态{xs}0≤s≤t,动作{as}0≤s<t和奖励{rs}0≤s<t的集合,当循环单位已重置)。训练网络权重使得在所有步骤和回合中观察到的奖励总和最大化。
训练后,智能体的策略是固定的(即权重已冻结,但由于环境的输入和循环层的隐含状态而导致激活发生变化),并根据从相同的分布D或对该分布的轻微修改中提取的一组MDP对其进行评估(以测试智能体的泛化能力)。在任何新回合的评估开始时,都会重置内部状态。由于智能体了解到的策略是历史相关的(因为它利用循环网络),因此当暴露于任何新的MDP环境时,它就能够适应和部署优化该任务奖励的策略。
RL^2: Fast Reinforcement Learning via Slow Reinforcement Learning (RL2):ICLR 2017
[Target] 元学习用于快速学习的RNN权重;
[Feature] 同策;梯度下降;TRPO的一阶实现;GRU;基于上下文的元RL方法;
深度RL已经成功地自动学习了复杂的行为。但是,学习过程需要大量的试验。相比之下,动物可以通过几次试验而学习新的任务,这得益于它们对世界的了解。本文力图弥合这一差距。与其设计一种"快速"的RL算法,不如将其表示为RNN并从数据中学习。在我们提出的方法RL2中,该算法以RNN的权重进行编码,这些权重是通过通用("慢速")RL算法缓慢学习的。RNN接收典型RL算法将接收的所有信息,包括观察,动作,奖励和终止标志;并且在给定的马尔可夫决策过程(MDP)中跨回合保留其状态。RNN的激活将"快速"RL算法的状态存储在当前(以前未见过)的MDP上。我们在小规模和大规模问题上通过实验评估RL2。在小规模方面,我们训练它来解决随机生成的多臂赌博机问题和有限的MDP。训练完RL2后,它在新MDP上的性能接近人工设计的算法,并具有最优性保证。在大规模方面,我们在基于视觉的导航任务上对RL2进行了测试,并表明它可以扩展到高维问题。
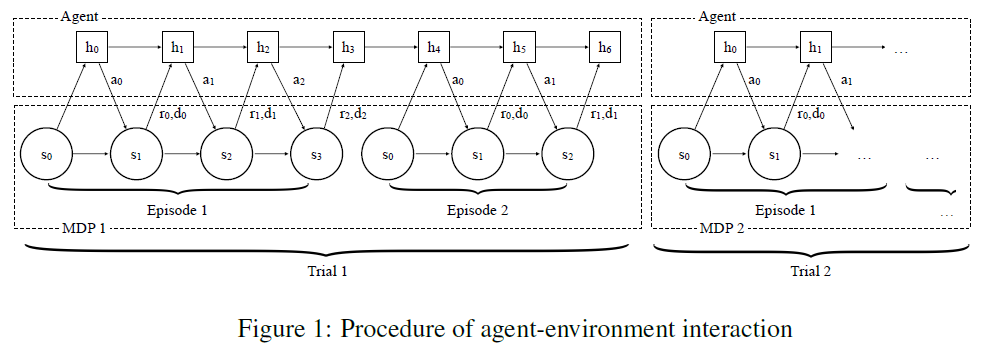
智能体与环境之间的交互过程如图1所示。这里,每个试验恰好由两个回合组成,因此n =2。对于每个试验,从ρM抽取一个单独的MDP,对于每个回合,从特定于相应MDP的初始状态分布中抽取一个新的s0。在接收到由智能体产生的动作时,环境计算奖励rt,前向计算下一个状态st+1。如果回合已终止,则会将终止标志dt设置为1,否则默认为0。将下一个状态st+1,动作at,奖励rt和终止标志dt组合在一起,形成策略的输入,它以隐含状态ht+1为条件,生成下一个隐含状态ht+2和动作at+1。在回合结束时,策略的隐含状态将保留到下一个回合,但不会在两次试验之间保留。
Prefrontal cortex as a meta-reinforcement learning system: Nature Neuroscience, 2018
[Target] 元学习用于快速学习的RNN权重;
[Feature] 基于上下文的元RL方法;
在过去的20年中,基于奖励的学习的神经科学研究已经集中在经典模型上,在该模型中,神经递质多巴胺通过调节神经元之间突触连接的强度,在情况,动作和奖励之间建立联系。然而,越来越多的最新发现使该标准模型处于压力之下。现在,我们利用AI的最新进展来介绍基于奖励的学习的新理论。在这里,多巴胺系统训练大脑的另一部分,即前额叶皮层,作为其自己的独立式学习系统进行操作。这种新的观点容纳这样一种发现:既激励标准模型,又可以优雅地处理更广泛的观察结果。这为将来的研究提供了新的基础。
A Simple Neural Attentive Meta-Learner:ICLR 2018
[Target] 元学习捕获问题本质的高层次策略;
[Feature] 时序卷积;软注意力;
深度神经网络在拥有大量数据的环境中表现出色,但在数据稀缺或需要快速适应任务变化时往往会遇到困难。作为回应,最近在元学习中的工作提出了对元学习器进行相似任务分布的训练,以期通过学习捕获(被要求解决的)问题本质的高层次策略,并将其泛化到新颖却相关的任务。但是,许多新的元学习方法都是经过大量手动设计的,或者使用专门用于特定应用的结构,或者使用硬编码算法组件来限制元学习器解决任务的方式。我们提出了一类简单且通用的元学习器架构,该架构使用时序卷积和软注意力的新颖组合。前者从过去的经验中收集信息,而后者则用于确定特定的信息。在迄今为止最广泛的元学习实验中,我们评估了一些基准测试任务所产生的简单神经注意力学习器(Simple Neural AttentIve Learning, SNAIL)。在监督学习和强化学习中的所有任务上,SNAIL都能获得最先进的性能。

Reinforcement Learning, Fast and Slow: Trends in Cognitive Sciences, May 2019
[Target] 元学习用于快速学习的RNN权重;
[Feature] 基于上下文的元RL方法;
近年来,深度RL方法在AI方面取得了令人瞩目的进步,在从Atari到Go到无限制扑克等领域都超过了人类的性能。这一进展引起了对了解人类学习感兴趣的认知科学家的关注。但是,人们一直担心,深度RL的样本效率可能太低——也就是说,它可能太慢——无法为人类学习提供一个合理的模型。在本综述中,我们通过描述最近开发的技术来反驳这种批评,这些技术使深度RL能够更灵活地运行,比以前的方法更快地解决问题。尽管这些技术是在AI环境中开发的,但我们提出它们可能会对心理学和神经科学产生深远的影响。这些AI方法产生的关键见解涉及快速RL和较慢的更多增量学习形式之间的基本联系。
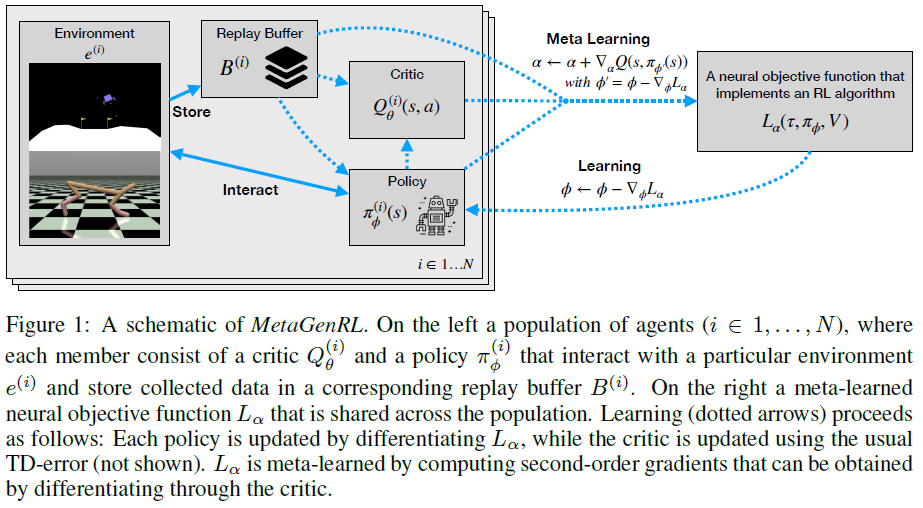
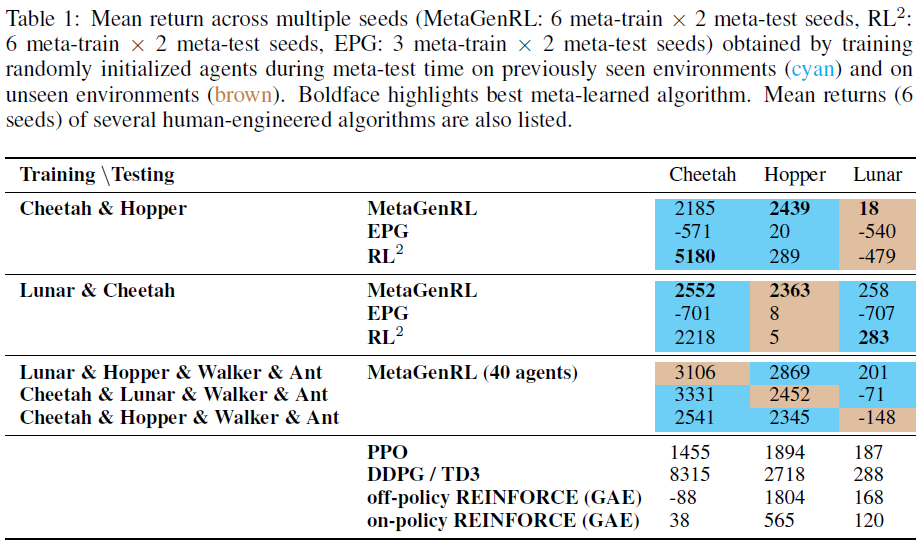
Improving Generalization in Meta Reinforcement Learning using Learned Objectives (MetaGenRL): ICLR 2020
[Code] http://louiskirsch.com/code/metagenrl (Ray, Tensorflow Ray)
[Target] 元学习一个神经目标函数,计算梯度以指导策略更新;
[Feature] 异策;二阶梯度(元梯度下降);元学习神经目标;LSTM;基于群体的元优化;基于梯度与上下文的元RL方法;
生物进化将许多学习者的经验提炼为人类的一般学习算法。我们新颖的元强化学习算法MetaGenRL受此过程启发。MetaGenRL提取了许多复杂智能体的经验,以元学习一种低复杂度的神经目标函数,该函数决定了未来单独的学习方式。与最近的meta-RL算法不同,MetaGenRL可以推广到与元训练完全不同的新环境。在某些情况下,它甚至优于人工设计的RL算法。MetaGenRL在元训练期间使用异策二阶梯度,可大大提高其采样效率。

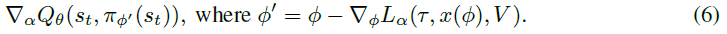

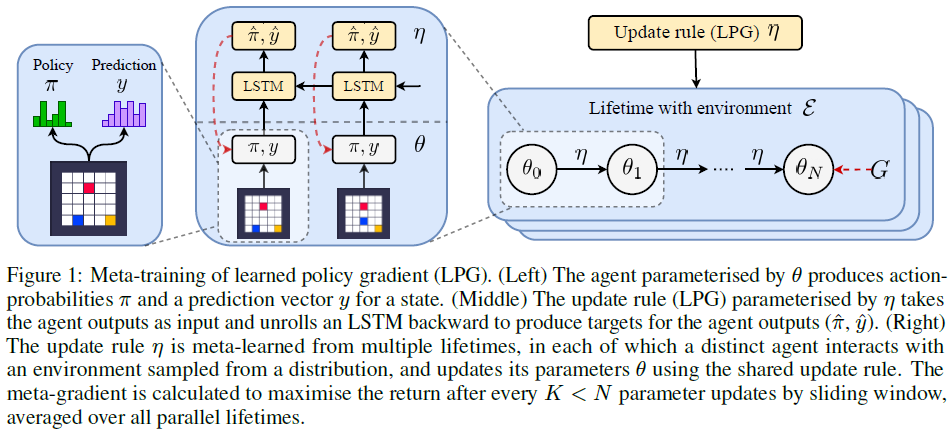
Discovering Reinforcement Learning Algorithms (LPG): arXiv:2007.08794v1 [cs.LG] 17 Jul 2020
[Target] 元学习一个基于环境𝑝(𝜀)和初始智能体参数𝑝(𝜃0)的分布的最优更新规则;
[Feature] 同策;二阶梯度(元梯度下降);元学习自举机制;基于梯度与上下文的元RL方法;
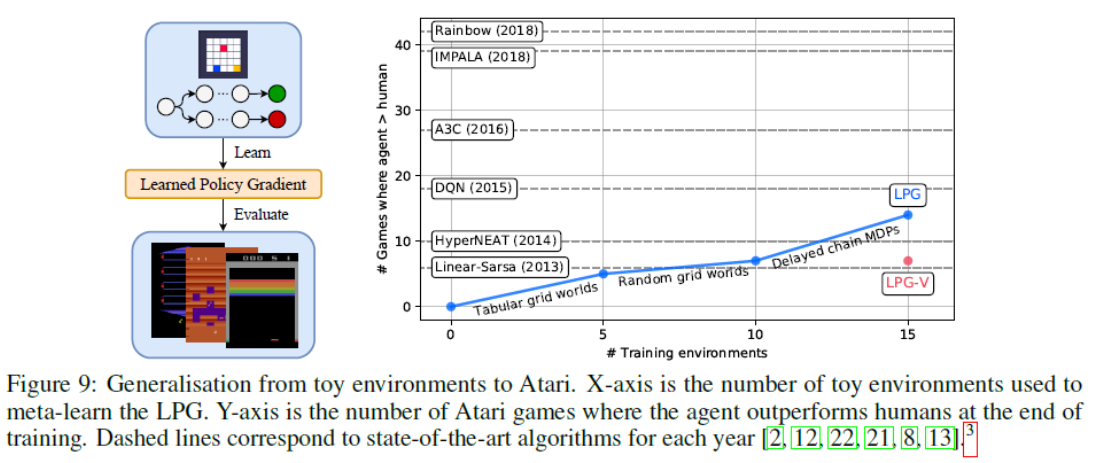
RL算法根据经过多年研究手动发现的几种可能规则之一来更新智能体的参数。从数据中自动发现更新规则可能会导致效率更高的算法,或者更适合特定环境的算法。尽管已经进行了尝试来应对这一重大的科学挑战,但是仍然存在一个未决的问题,即发现RL基本概念的替代方法(例如价值函数和时序差分学习)是否可行。本文介绍了一种新的元学习方法,该方法通过与一组环境交互来发现整个更新规则,其中包括"预测什么"(例如价值函数)和"如何从中学习"(例如自举)。此方法的输出是RL算法,我们称为学习型策略梯度(LPG)。实证结果表明,我们的方法发现了它自己的替代价值函数的概念。此外,它发现了一种自举机制来维持和使用其预测。出乎意料的是,仅在toy环境中进行训练时,LPG可以有效地推广到复杂的Atari游戏中,并达到非凡的性能。这表明从数据中发现通用RL算法的潜力。
尽管LPG仍然落后于诸如A2C之类的高级RL算法,但LPG不仅在训练环境上而且在一些Atari游戏中也胜过A2C,这表明LPG专门研究特定类型的RL问题,而不是严格比A2C差。另一方面,图9显示,随着训练环境数量的增加,泛化性能快速提高,这表明,一旦有更多的环境可用于元训练,发现通用的RL算法可能是可行的。


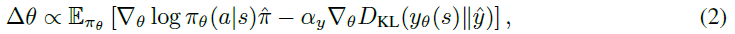
![]()
二、基于优化的元强化学习
基于优化的元强化学习是更新模型参数的方法,以便在新任务上实现良好的泛化性能。MAML(Finn et al., 2017)和Reptile(Nichol et al., 2018)都是属于此类算法。
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (MAML):ICML 2017
[Code] github.com/cbfinn/maml (用于回归和监督实验),github.com/cbfinn/maml_rl (用于RL实验) (the TensorFlow rllab version)
[Target] 元学习易于微调的初始化权重;
[Feature] 同策;梯度下降;基于梯度的元RL方法;
我们提出了一种与模型无关的元学习算法,从某种意义上说,该算法可与通过梯度下降训练的任何模型兼容,并适用于各种不同的学习问题,包括分类,回归和RL。元学习的目标是针对各种学习任务训练模型,以便仅使用少量训练样本即可解决新的学习任务。在我们的方法中,对模型的参数进行了显式训练,以使少量梯度步骤和来自新任务的少量训练数据将对该任务产生良好的泛化性能。实际上,我们的方法训练出的模型易于微调。我们证明了这种方法在两个小样本图像分类基准上产生了最先进的性能,在小样本回归上产生了良好的结果,并加快了使用神经网络策略进行策略梯度RL的微调。

在RL中,小样本元学习的目标是使智能体仅使用少量测试设置经验就可以快速获取新测试任务的策略。新任务可能涉及达成新目标或在新环境中成功达成先前训练的目标。例如,智能体可能会学会快速找出迷宫的导航方式,以便面对新的迷宫时,可以确定如何仅用几个样本就能可靠地到达出口。在本节中,我们将讨论如何将MAML应用于RL的元学习。
每个RL任务Ti包含初始状态分布qi(x1)和转换分布qi(xt+1|xt, at),并且损失LTi对应于(负)奖励函数R。因此,整个任务是一个马尔可夫决策过程(MDP)的范围为H,允许学习者查询有限数量的样本轨迹以进行小样本学习。MDP的任何方面都可能因p(T)中的任务而异。正在学习的模型fθ是在每个时间步骤t∈{1, ... , H}从状态xt映射到动作at分布的策略。任务Ti和模型fΦ的损失如下:
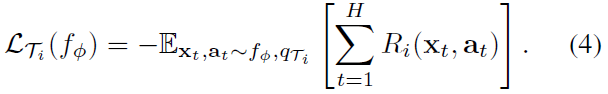
在K-shot RL中,可以使用fθ和任务Ti的K部署(x1, a1, ... , xH)和相应的奖励R(xt, at)来适应新任务Ti。由于期望奖励通常由于未知的动态而无法区分,因此我们使用策略梯度方法来估计模型梯度更新和元优化的梯度。由于策略梯度是基于策略的算法,因此在适应fθ期间的每个额外梯度步骤都需要来自当前策略![]() 的新样本。我们在算法3中详细介绍了该算法。该算法与算法2的结构相同,主要区别在于步骤5和步骤8需要从与任务Ti对应的环境中采样轨迹。该方法的实际实现还可以使用最近针对策略梯度算法提出的各种改进,包括状态或动作相关的基准和信任区域(Schulman et al., 2015)。
的新样本。我们在算法3中详细介绍了该算法。该算法与算法2的结构相同,主要区别在于步骤5和步骤8需要从与任务Ti对应的环境中采样轨迹。该方法的实际实现还可以使用最近针对策略梯度算法提出的各种改进,包括状态或动作相关的基准和信任区域(Schulman et al., 2015)。

On First-Order Meta-Learning Algorithms (Reptile): arXiv: Learning, 2018
[Code] https://github.com/openai/supervised-reptile (用于监督学习)
[Target] 元学习易于微调的初始化权重;
[Feature] 一阶元学习算法;基于梯度的元RL方法;
本文考虑了存在任务分布的元学习问题,并且我们希望获得一个表现良好的智能体(即快速学习),该智能体在从该分布中采样到以前没见过的任务时表现良好。我们分析了一组算法,用于学习可以在新任务上快速微调的参数初始化,仅使用一阶导数进行元学习更新。该族包括并概括了一阶MAML,它是通过忽略二阶导数获得的MAML的近似值。它还包括Reptile,这是我们在此处引入的新算法,该算法通过重复采样任务,对其进行训练并将初始化朝该任务的训练权重进行偏移。我们扩展了Finn et al.的结果,说明一阶元学习算法在一些公认的针对小样本分类的基准上表现良好,并且我们提供了旨在理解这些算法为何起作用的理论分析。

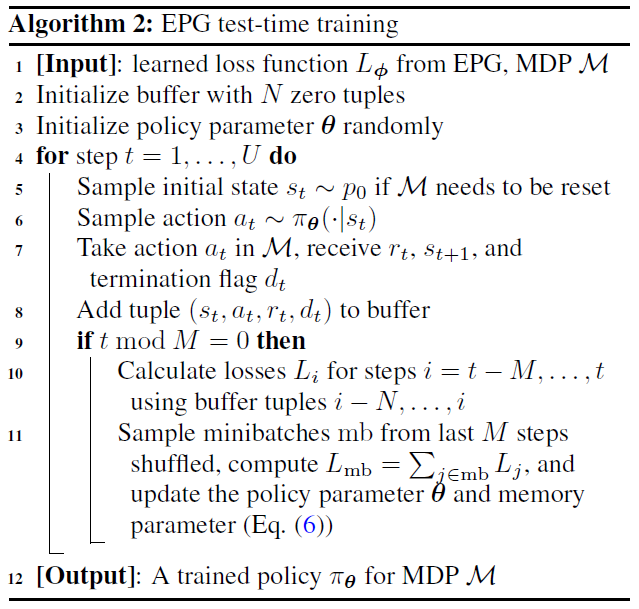
Evolved Policy Gradients (EPG):NeurIPS, 2018
[Code] https://github.com/openai/EPG (Chainer)
[Target] 元学习一个可微的损失函数;
[Feature] 同策;进化策略;基于梯度的元RL方法;
我们提出了一种元学习方法,用于学习基于梯度的RL算法。这个想法是要逐步形成一种可微的损失函数,这样智能体就可以通过优化其策略以最大程度地减少这种损失,获得较高的奖励。损失是通过智能体经验的时序卷积来参数化的。由于这种损失在考虑智能体历史方面的能力上具有很高的灵活性,因此可以快速学习任务。实验结果表明,与现成的策略梯度方法相比,我们的进化策略梯度算法(EPG)在几种随机环境下可以更快地学习。我们还证明,EPG的学习损失可以推广到分布外的测试时间任务,并且表现出与其他流行的元学习算法不同的行为。

![]()
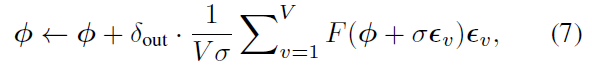
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables (PEARL):arXiv: Learning, 2019
[Code] https://github.com/katerakelly/oyster (RLkit:Reinforcement learning framework and algorithms implemented in PyTorch.)
[Target] 元学习一个概率编码器,该编码器将从过去的经验中收集必要的统计信息到上下文变量中,使策略执行任务;
[Feature] 异策;基于上下文的元RL方法;
深度RL算法需要大量经验才能学习单个任务。原则上,元强化学习(meta-RL)算法使智能体能够从少量经验中学习新技能,但一些主要挑战阻碍了它们的实用性。当前的方法严重依赖于同策经验,从而限制了其采样效率。在适应新任务时,也缺乏推断任务不确定性的机制,从而限制了它们在稀疏奖励问题中的有效性。在本文中,我们通过开发一种异策的元RL算法来解决这些挑战,该算法可以分离任务推断和控制。在我们的方法中,我们对潜在任务变量执行在线概率过滤,以从少量经验中推断出如何解决新任务。这种概率解释可以进行后验采样,以进行结构化和有效的探索。我们演示了如何将这些任务变量与异策RL算法集成在一起,以实现元训练和适应效率。在几个meta-RL基准测试中,我们的方法在样本效率和渐近性能方面都比以前的算法好20-100倍。


Meta Learning via Learned Loss (ML3):CoRR, 2019
[Target] 元学习参数化损失函数;
[Feature] 同策;二阶梯度(元梯度下降);基于梯度的元RL方法;
通常,从有限的一组选项中试探性地选择损失函数,正则化机制和训练参数模型的其他重要方面。在本文中,我们将朝着使该过程自动化的第一步迈进,以期产生能够更快且更强大的训练模型。具体而言,我们提出了一种用于学习参数化损失函数的元学习方法,该方法可以推广到不同的任务和模型架构中。我们开发了一条用于"元训练"损失函数的流水线,旨在最大程度地提高在其下训练的模型性能。在监督学习和RL任务中,我们的学习损失所产生的损失态势显著提高了特定于任务的原始损失。此外,我们证明了我们的元学习框架足够灵活,可以在元训练时合并其他信息。此信息可影响学习到的损失函数,从而使环境无需在元测试时间内提供此信息。
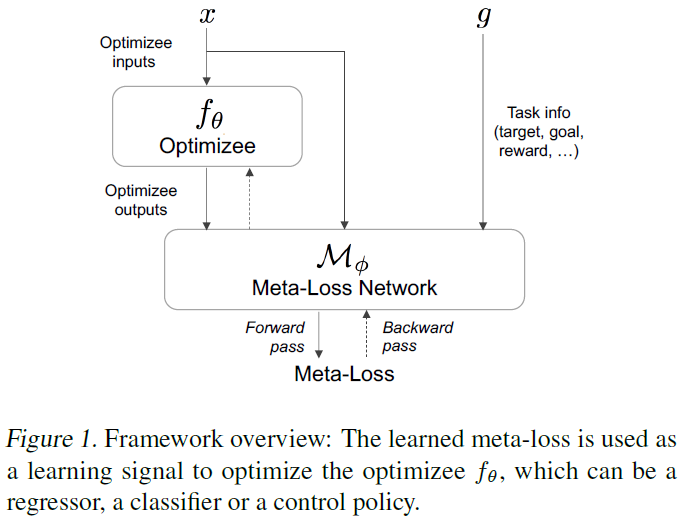


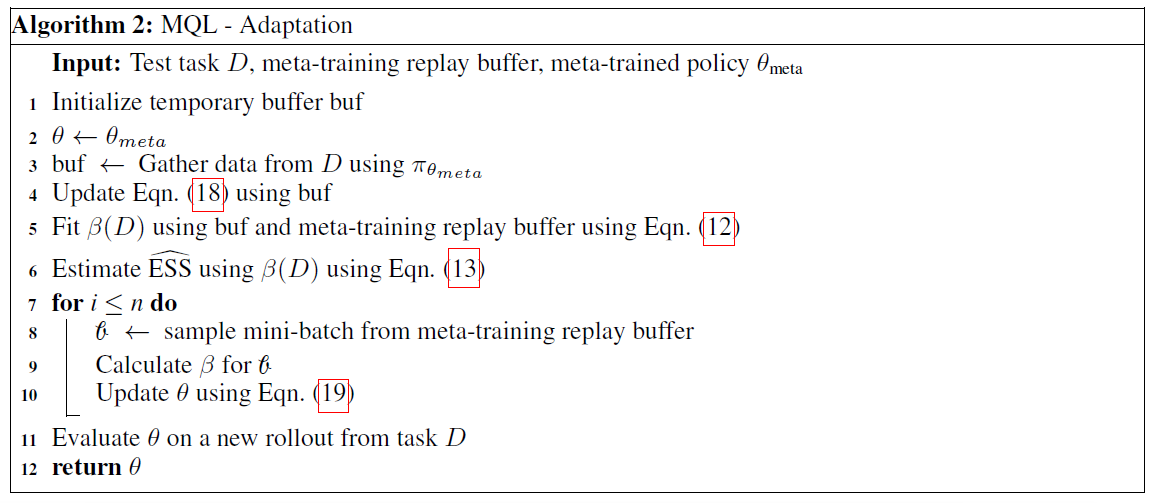
Meta-Q-Learning:ICLR 2020
其他翻译:https://zhuanlan.zhihu.com/p/109064006
[Feature] 异策;元Q学习;
本文介绍了Meta-Q-Learning (MQL),这是一种用于元强化学习(meta-RL)的新的异策算法。MQL基于三个简单的想法。首先,我们表明,如果可以访问表示过去轨迹的上下文变量,则Q学习将与最新的meta-RL算法相当。其次,在训练任务中最大化多任务目标的平均奖励是对RL策略进行元训练的有效方法。第三,元训练经验缓存中的过去数据可以被回收,以使策略适用于新任务。MQL借鉴了倾向估计中的想法,从而扩大了用于适应的可用数据量。在标准连续控制基准上进行的实验表明,MQL与meta-RL中的最新技术相比具有优势。

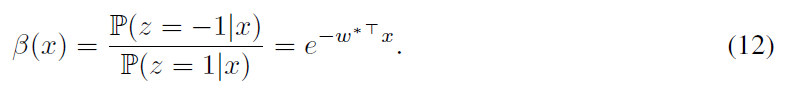
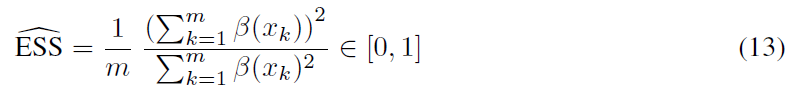
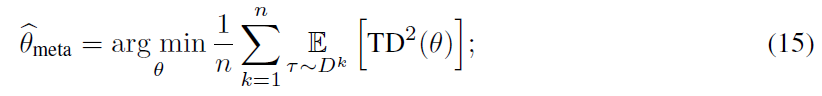
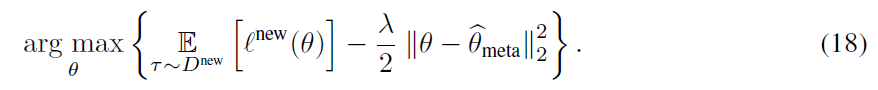
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号