
The neurobiology of deep reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Current biology : CB, no. 11 (2020)
为了产生适应性行为,动物必须从与环境的交互中学习。描述控制该学习过程的算法以及它们如何在大脑中实现是神经科学的主要目标。一百多个世纪以前,Thorndike,Pavlov等人对动物学习进行了仔细且受控的观察,确定了直观的规则,使动物(包括人类)可以通过将感官刺激和动作与奖励相关联来从其经验中学习。但是,从以简单的范式解释学习到解密在丰富且动态的环境中如何解决复杂的问题已经证明是困难的(图1)。最近,这项工作已经获得了计算机科学家和工程师的帮助,他们希望在计算机中仿真智能自适应行为。在动物行为学文献的启发下,AI的先驱者开发了一个严格的数学原理框架,可以在此框架内对基于奖励的学习进行形式化和研究。RL领域不仅成为机器学习和AI的福音,而且还为有兴趣破译大脑如何实施RL算法的生物学家提供了理论基础。
RL智能体解决复杂的高维学习问题的能力通过使用深度神经网络得到了显著增强(深度RL,图1)。借助不断增长的计算资源,深度RL算法现在可以在许多定义完善的复杂任务上胜过人类专家,尽管仍然存在明显的差距。本入门手册的目的不是回顾快速发展的入门领域的进展,也不是比较各种算法的实现。相反,我们认为,熟悉为机器学习开发的算法可以帮助神经科学家以计算精确的方式更好地理解人和动物如何从与环境的交互中学习。重要的是,深度RL的发展可以帮助激发关于大脑如何实现神经回路级解决方案以应对这些挑战的新思路。
在本入门中,我们将简要回顾RL的基本概念,并讨论传统方法的一些缺点以及使用深度RL可以克服这些缺点的方法。然后,我们考虑大脑如何实施深度RL中的一些想法,具体来说就是:相对价值编码;策略正规化;并有效探索大型解决方案空间。

Solving reinforcement learning problems with deep neural networks
在RL中,可以将从经验中学习的问题简化为与其环境交互的智能体(可以是机器或动物)。在此交互的每个步骤 t,智能体观察状态s(t),并制定确定其动作a(t)的策略。每个动作依次导致奖励r(t),并将状态更改为s(t + 1)。目标是学习一种策略,该策略以某种方式将状态映射到动作,以在一定时间范围内最大化累积奖励(价值)。学习最优策略的一种方法是探索不同状态下的不同动作,并使用奖励反馈来更新在给定状态下执行给定动作的价值估计。价值估计的偏差称为奖励预测误差,该误差用于更新价值估计,并由此更新策略。
在现实世界中,状态和动作都是高维连续的,这意味着智能体无法为每个状态-动作对的价值("价值函数",图1)构建查询表。这就是维数灾难。解决此问题的一种方法是找到高维状态和动作空间的低维表征,以便可以在更易处理的领域中学习良好的策略。例如,如果奖励在整个空间中变化平稳(对于觅食动物来说是一个合理的假设),则用其在欧氏空间中的坐标来表示状态将使智能体有效地进行泛化:在空间的一个区域中发现奖励会增加邻近区域的价值。但是,不能总是先验地确定有用的表征。如果奖励的空间分布取决于其他因素(例如,地形,季节,块枯竭和更新率),则价值函数将无法通过简单的空间位置函数很好地近似。
经典的RL算法通常使用状态和动作空间的固定和预定表征(例如,在上面的示例中为欧氏坐标系)。正如我们已经看到的,表征的选择会限制RL智能体的能力。现代的深度RL算法通过学习状态和动作表征以及状态-动作对和策略的价值来克服这个问题,这一过程被称为"端到端"学习。这是通过使用深度神经网络来完成的,深度神经网络由类似神经元的非线性处理单元组成,当连接到网络中时,可以仿真我们大脑执行的计算(图1)。为了进行RL,一种常用的结构是前馈网络,其中的单元排列成层,相邻层中的单元之间紧密连接,而一层中的单元之间没有连接。
这样的深度神经网络通过将状态和动作映射到价值并调整网络参数以最大化未来奖励,从而学习有效的表征。信号通过一个层次结构沿一个方向传播,首先是"原始"感觉输入(状态信息),最后是每个动作的标量价值估计。在网络的每一层,输入都丢失了一些细节,从而形成了一个"信息瓶颈",迫使网络(在学习过程中)找到状态信息的紧凑(低维)表征,这对RL很有用。
重要的是,深度神经网络可以学习表示任何连续函数,使其非常适合来近似状态-动作对及其价值之间的复杂高维映射。此属性来自具有许多自由参数的大型神经网络——神经元之间的连接权重——可以调整为近似任何输入-输出函数(通用函数近似属性)。缺点是,深度网络会"过拟合"稀疏数据,因此可能无法适当地泛化到新情况。大型网络表示任何复杂函数的能力(其表达能力)与使用小数据集过拟合的风险之间的这种紧张关系是深度RL中的一个主要问题,我们将在下面讨论。
在接下来的部分中,我们重点介绍三个算法思想,这些思想已显示出对深度RL的希望,并讨论了它们为神经科学提供的见解。这些示例仅用于说明而不是穷举。我们将在引言结尾处得出一些一般性结论。
Variance reduction using relative value coding
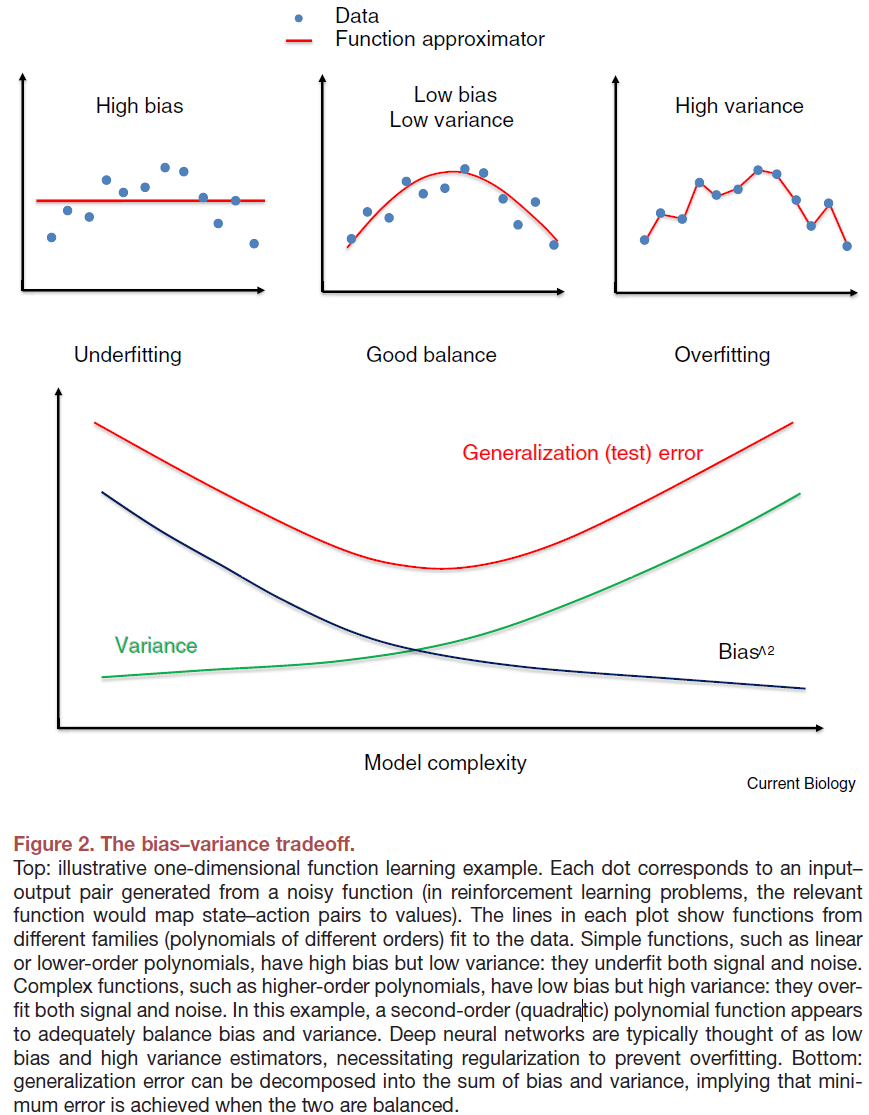
泛化性和过拟合之间紧张关系的一种表达方式是说,深度神经网络具有较低的偏差(在有足够数据的情况下,它们可以近似正确的函数)和较高的方差(对于较小的数据集,近似误差往往会很大)。低偏差是好的,因为它意味着预测不会系统地错误(图2)。高方差是一个问题,因为它会导致可靠的泛化精度,并且是由于深度网络对小数据集中的随机性非常敏感:每次使用不同的样本进行训练时,它们都会为你提供不同的近似值。为了确保深度RL从相对较少的样本中获得良好的策略,重要的是通过减少方差而又不引入过多的偏差来管理这种偏差-方差的折衷(图2)。
方差的一种来源来自奖励中与动作无关的波动。举例说明,设想在城市中的餐馆中优化食物选择(例如,鸡肉或牛排)。由于餐厅("状态")的"良好程度"会有所不同,因此选择给定类型的食物("动作")的奖励在很大程度上可以独立于动作本身。从某种意义上说,这将花费更长的时间来学习每个状态-动作对的价值,这实际上会给策略增加噪声。对于深度RL而言,这尤其成问题,因为与"浅层"函数近似相比,深度函数近似更容易拟合噪声。减少这种方差的有效方法是学习相对于特定状态(餐厅的"良好程度")的平均动作价值的动作(鸡或牛排)的价值。这些相对价值被称为"优势",学习它们有助于深度网络从稀疏观察中泛化而不会增加过多的偏差。
越来越多的证据表明,大脑会根据"优势"学习并编码动作和刺激的价值。例如,眶额皮层中的神经元——参与决策和奖励处理的大脑区域——代表相对于给定状态下其他可用选项的结果价值。就像感觉神经元一样,将价值编码神经元的发放率进一步归一化为拟合可能遇到的价值的范围。深度RL提供了一个计算原理,说明了为什么大脑(一个负责根据稀疏观测进行泛化的网络)应该使用相对价值代码。
Policy regularization in neural networks
解决偏差-方差折衷的另一种方法是通过"正则化"策略以确保策略不会过拟合稀疏数据——根据数据的复杂性对其进行惩罚。以迷信仪式为例,例如在团队参加比赛之前,总是戴着纸板帽子在纸板箱中吃橙子。这样的策略似乎与团队获胜无关,但这很可能是偶然的缘故。正则化技术可确保除非有确凿的证据证明此类策略有效,否则它们将受到不利影响。
关于是否实现策略正则化的线索可以来自考虑奖励预测误差。当对深度网络的预测始终不佳时,通常是由于过拟合所致,在这种情况下,首选低方差解决方案(更强的策略正则化)(图2)。另一方面,如果预测良好,则方差增加可能有助于将系统推向更复杂(甚至可能更准确)的策略。将此思想应用于神经生物学可以帮助解释为什么多巴胺的消耗(例如帕金森氏病)会导致运动变异性增加。在正常的大脑中,阶段性多巴胺的减少意味着预测变得更好(误差很小),在这种情况下,较高的方差(较弱的正则化)可能是有益的。
预测误差与正则化之间的联系也可以解释为什么调节纹状体多巴胺效应的基因变异与RL任务中的选择变异性相关。但是,具有高偏差的深度网络也会产生始终不佳的预测,这可以通过智能体探索策略空间的新部分来弥补,这意味着更高(而不是更低)的策略方差。至少在理论上,可以通过考虑其统计量来解决解释预测误差信号时的某些歧义。大脑是否这样做尚不清楚。
深度RL还可以使人对大脑如何实现策略正则化产生一些直觉。深度网络正则化的一种方法是对强大的连接进行惩罚,这可能会使网络连接稀疏(许多连接强度被推向零)。除了策略正则化之外,这种稀疏化还可以使网络实现更快且更可靠。同样,神经回路中的突触修剪与许多形式的学习有关,并且是关键时期可塑性的标志。与深度RL的类比表明,这可能是大脑正则化学到的策略的一种机制,从而使它们的实现更加有效且鲁棒。
Balancing exploration and exploitation in neural networks
与如何调节可变性相关的问题是RL中的探索与开发困境。在每个时间步骤中,智能体必须决定是执行预测最高奖励的动作还是探索以前未采取的动作。从长远来看,探索可以导致确定更好的选择。平衡探索与开发的一种经典方法是将探索引导到很少被访问的状态和动作(这些价值的不确定性较高)。有时称为"基于计数的探索",并具有强大的理论保证。但是,这不能直接应用于很少(如果曾经)重访同一状态-动作对的高维连续状态-动作空间。
在广阔的状态/动作空间中进行有效探索的一种方法是随机化价值函数。由于深度RL中的策略通常是由经过训练的权重的神经网络参数化的,因此将价值函数随机化会给策略增加探索性噪声(一种称为随机探索的策略)。事实证明,可以通过在选择动作时向网络权重添加噪声来实现有效的探索。
与RL理论相一致,在人类和动物模型中的行为研究都表明,大脑调节探索性变异性以促进学习。与深度RL中一样,向基础神经网络中的权重添加噪声是一个合理的机制。对于较短的时间尺度,此噪声可能是由突触传递的概率性质驱动的,而较长的时间尺度探索可能是由缓慢的树突状脊柱体积和形态的结构变化引起的,众所周知,随着时间的推移,这些变化会连续且随机地波动。我们推测,这些随机波动会驱动估值回路中的噪声,从而使价值函数随机化。在深度RL文献中尚未系统地解决不同时间尺度的贡献。这样做可能会导致新的更有效的多尺度探索算法。
Conclusions
鉴于深度网络是受神经科学启发的,并且之所以有效是因为它们具有在真实的神经回路中也能找到的特性,一个诱人的假设是大脑实施了深度RL。正如我们在这里提到的,这种类比可以阐明大脑功能的多个方面。尽管我们已经解决的计算问题(偏差-方差和探索-开发难题)适用于任何RL算法,但由于它们具有高度的表达能力,因此对于深度神经网络(可能还包括生物网络)尤其重要。
同时,存在类比分解的方法:深度网络比生物大脑(尤其是人类的大脑)需要更多的训练数据,其学习算法(尤其是反向传播)做出了生物学上难以置信的假设,并且缺乏真实大脑的认知灵活性。所有这些挑战目前是密集研究工作的重点。因此,我们希望这种类比一旦得到适当的细化,将为思考大脑中的RL提供有用的框架。


