强化学习第二版第17章笔记——前沿技术
在本章中大家将接触一些超出本书范围的话题,但是我们认为这些话题对于强化学习的未来非常重要。很多话题会超出我们所熟知的知识范围,并且有些会把我们带出马尔可夫决策过程(MDP)框架。
17.1 广义价值函数和辅助任务
不管在这种类似于价值函数的预测过程中,我们累加的是什么信号,我们都称其为这种预测的累积量。我们将其形式化地表示成一个累积信号Ct ∈ R,在这种记号下,广义价值函数(general value function, GVF)将记为:
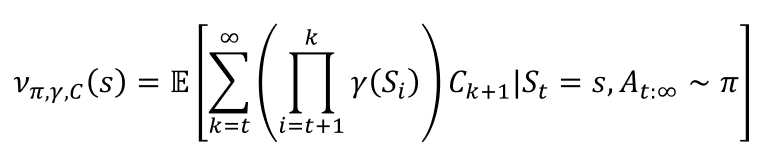
为什么预测和控制长期收益之外的信号可能有用呢?这类信号控制任务是在最大化收益的主任务之外额外添加的辅助任务。一个答案是,预测和控制许多不同种类的信号可以构建一种强大的环境模型。
辅助任务帮助主任务的一种简单情形是它们可能需要一些相同的表征。有些辅助任务可能更简单,延迟更小,动作和结果之间的关联关系更加明晰。如果在简单的辅助任务中,可以很早发现好的特征,那么这些特征可能会显著地加速主任务的学习。没有什么理由可以解释为什么这是对的,但是在很多情况下这看起来很有道理。
另一个理解为何学习辅助任务可以提升表现的简单的方法是类比于经典条件反射这一心理学现象。
最后,也许辅助任务最重要的作用,是改进了我们本书之前所做的假设:即状态的表示是固定的,而且智能体知道这些表示。为了解释这个重要作用,我们首先要回过头来了解本书所做的假设的重要性以及去除它所带来的影响。这将在17.3中介绍。
17.2 基于选项理论的时序摘要
马尔可夫决策过程形式上的一个吸引人的地方是,它可以有效地用在不同时间尺度的任务上。我们可以用它来形式化许多任务。这些任务在时间尺度上差异很大,然而每一个都可以表达成马尔可夫决策过程(MDP),然后用本书中讲述的规划和学习过程完成。所有这些任务都涉及由与环境的相互作用、序贯决策以及一个随时间积累的收益构成的目标,因此它们都可以被形式化成马尔可夫决策过程。
尽管所有这些任务都可以被形式化为MDP,但是我们可能认为它们不能被形式化为一个单一的MDP,因为这些过程涉及的时间尺度都不同,例如选择的种类和动作都截然不同。人类可以无缝地在各个时间层次上切换,而没有一点转换的痕迹。那么MDP框架可不可以被拉伸,从而同步地覆盖所有这些时间层次呢?
也许是可以的,一种流行的观点是:先形式化一个非常小的时间尺度上的MDP,从而允许在更高的层次上使用拓展动作(每个时刻对应于更低层次上的多个时刻)的规划。为了做到这一点,我们需要使用一个展开到多个时刻的"动作方针"的概念,并引入一个"终止"的概念。对这两个概念的通用的形式化方式是将它们用一个策略π和一个状态相关的终止函数γ来表达,就像在GVF中定义的那样。我们将这样的一个"策略-终止函数"二元组定义为一种广义的动作,称之为"选项"。在 t 时刻执行一个选项ω = <πω, γω>,就表示从πω(· | St)中获得一个动作At,然后在t+1时刻以1 - γω(St+1)的概率终止。如果选项不在t+1时刻停止,那么At+1从πω(· | St+1)中选择,而且选项在t+2时刻以1 - γω(St+2)的概率终止。很容易就可以把低层次的动作看作选项的一种特例——每一个动作a都对应于一个选项<πω, γω>,这个选项的策略会选出一个动作(对于每个s ∈ S,πω(s) = a),并且其终止函数是零(对于每个s ∈ S+,γω(s) = 0)。选项有效地拓展了动作空间。智能体可以选择一个低层次的动作/选项,在单步之后终止,或者选一个拓展的选项,它可能在执行多步之后才终止。
"选项"的架构设计允许它与低级别的动作进行角色互换。
17.3 观测量的状态
在本书中,我们都把学到的近似价值函数(还有第13章中的策略)写成关于状态的函数。这是本书的第 I 部分中介绍的方法的重大局限,在这些方法中,学习得到的价值函数用一张表格来表示,因此任意的价值函数都能被精确近似。这种情况等同于假设环境的状态完全可以被智能体感知。但是在很多情况下,传感器输入只会告诉你这个世界状态的部分信息。有些对象可能被其他的东西遮挡住了,或者在智能体的身后,亦或是在几里之外。在这些情况下,关于环境的很重要的一部分信息可能并不能直接观察到。而且,把学习到的价值函数实现为一个关于环境状态空间的表格,是一种过强的、不现实而且局限性很大的假设。
在本书第II部分提出的参数化函数逼近框架则限制要少得多,甚至可以说它是没有局限性的(虽然这种说法是有争议的)。在第II部分中,我们保留了学习到的价值函数(和策略)是关于环境的状态的函数这一假设,但是允许这些函数在参数化的框架下自由变化。一个有些令人吃惊而且并不被广泛认可的观点是,函数逼近包含了"部分可观测性"的很多方面。从这个意义上说,参数化函数逼近的情况包含了部分可观测性的情况。
然而,如果不显式地、明确地为部分可观测性建模,仍然有很多问题无法被深入研究。尽管我们在这里不能给出一个完整的处理部分可观测性的方法,但是我们可以大致列出需要做出的一些改变,以下是具体的四个步骤:
首先,我们需要改变问题:环境所提供的不是其状态的精确信息,而仅仅是观测量——这是一个依赖于状态的变量,就像机器人的传感器那样,提供关于状态的部分信息。
然后我们可以用观测量和动作的序列来恢复本书中提到的状态的概念。我们使用术语历史以及记号Ht表示一个轨迹从初始部分一直到当前的观测量:![]() 。历史代表了我们在不看数据流外部信息的情况下,对过去所能了解的最多信息(因为历史是整个过去的数据流)。
。历史代表了我们在不看数据流外部信息的情况下,对过去所能了解的最多信息(因为历史是整个过去的数据流)。
将强化学习的概念扩展到部分可观测的情况的第三步是需要考虑一些计算上的问题。特别是,我们希望状态是历史的紧凑的总结。状态更新函数在任何智能体的架构中都是解决部分可观测性问题的核心部分。它必须在计算上是高效的,因为在看到状态之前,我们不能采取任何动作或者做任何预测。
一个通过状态更新函数获得马尔可夫状态的典型例子采用了流行的贝叶斯方法,被称为"部分可观测MDP"(POMDP)。
另一个马尔可夫状态的例子是预测状态表示(PSR)。
在我们简短的概要介绍中,处理强化学习中的部分可观测性的第四步是重新引入近似的概念。
对于近似状态,学习状态更新函数是强化学习中的表示学习问题的一个重要组成部分。
17.4 设计收益信号
强化学习相较于有监督学习的一个主要优势是,强化学习并不依赖与细节性的监督信息:生成一个收益信号并不依赖于"智能体的哪个动作才是正确的"这一先验知识细节。但是强化学习的成功应用很大程度上依赖于我们的收益信号在多大程度上符合了设计者制定的目标,以及这些信号能够多好地衡量在达到目标过程中的进步。出于这些原因,设计收益信号是任何一个强化学习应用的重要部分。
17.5 遗留问题
在这一节中我们强调6个更长远的问题,有待未来研究去解决。
第一个问题是,我们仍然需要更强大的参数化函数逼近方法,它应当可以在完全增量式和在线式的设置下很好地工作。基于深度学习和人工神经网络的方法是这个方向上的重要一步,但是它们仍然只是在极大的数据集上批量训练才能得到很好的效果,要么是大量离线地自我对局博弈,要么是通过多个智能体在同一个任务上交错地采集经验来学习。这些以及其他的一些设置都是为了解决当下的深度学习方法的局限,即深度学习方法在增量式、在线式学习的设定下会陷入挣扎,而增量式和在线式学习又恰恰是本书中强调的最自然的强化学习方法的特质。这个问题又被称作“灾难性的干扰”,或者“相关的数据”。每当学习到一些新的东西时,它都倾向于忘记之前学的东西,而不是将新知识作为补充,这会导致之前学习到的那些优点都丢失。例如“回放缓存”之类的技术经常被用于储存和重新导出旧的数据,使得之前学到的优点不止于永久丢失。我们必须诚实地说,目前的深度学习方法并不完全适合在线学习。我们找不到这种限制无法解决的理由,但是迄今为止,在保持深度学习优势的同时解决这个问题的算法仍然还没有被设计出来。大部分当下的深度学习研究的导向是在这个限制下工作而不是去掉这个限制。
第二点(也许是紧密相连的),我们仍然需要一些方法来学习特征表示,使得后续的学习能够很好地推广。
第三点,我们仍然需要使用可扩展的方法在学习到的环境模型中进行规划。
未来使规划方法可以在学习得到的环境上有效地使用,我们还需要做很多工作。
第四个在未来的研究中需要重点解决的问题,是自动化智能体的任务选择过程,智能体在这些任务上工作并且使用这些任务提升自己的竞争力。在机器学习中,人类设计者为智能体设计学习的目标是一件很常见的事情。因为这些任务是提前已知而且固定的,因此它们可以被内嵌在学习算法的代码中。然而如果我们看得更远一些,则我们可能希望智能体对于将来想掌握什么技能做出自己的选择。这可能是某个特定的已知的大任务中的一个子任务,或者它们可能意图创造一些积木式的模块,允许智能体在一些尚未见过但是将来可能面临的问题上更加高效地学习。
任务就是一个一个的问题,而人工神经网络的内容就是这些问题的答案。我们期望将来有一个完整的层次化的问题与现代深度学习方法提供的层次化的答案相匹配。
第五个我们认为对未来研究至关重要的问题是,通过实现某些可计算的好奇心来推动行为和学习之间的相互作用。
最后一个在将来的研究中需要注意的问题是开发足够安全(达到可以接受的程度)的方法将强化学习智能体嵌入真实物理环境中,从而保证强化学习带来的好处超过其带来的危害。这是未来研究最重要的方向之一。
17.6 人工智能的未来
强化学习与心理学及神经科学的联系(第14和15章)弱化了其与人工智能其他的长期目标之间的关联,即揭示关于心智的一些关键问题,以及心智如何从大脑中产生。强化学习已经帮助我们理解了大脑的奖励机制、动机和做决策的过程。因此有理由相信,在与计算精神疾病学相结合之后,强化学习将会帮助我们研发治疗精神呢紊乱,包括药物滥用和药物成瘾的方法。
强化学习在未来将会取得的另一个成就是辅助人类决策。在模拟仿真环境中进行强化学习,从中得到的决策函数可以指导人类做决策,比如教育、医疗、交通、能源、公共部门的资源调度。
因此,包括强化学习在内的人工智能应用,其安全性是一个需要重视的课题。
一个强化学习智能体可以通过与真实世界环境、模拟环境(模拟真实世界的一部分)或者这两者的结合环境进行交互而学习。
然而,展现强化学习的全部潜力需要将智能体置于真实世界的经验流中,在我们的真实世界中行动、试探、学习,而不是仅仅在它们的虚拟世界中。
仔细设计奖励函数是非常重要的,它帮助智能体砸真实世界中行动,且不会给人类以观察其行为和动机并轻易干扰它的行为的机会。
如何把强化学习智能体的目标调整成我们人类的目标,仍然是个难题。
另一个强化学习在真实世界中行动和学习带来的挑战是,我们不仅仅关注智能体学习的最终效果,而且关注其在学习时的行为方式。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号