强化学习模型实现RL-Adventure(DQN)
源代码:https://github.com/higgsfield/RL-Adventure
在Pytorch1.4.0上解决bug后的复现版本:https://github.com/lucifer2859/DQN
DQN Adventure: from Zero to State of the Art
This is easy-to-follow step-by-step Deep Q Learning tutorial with clean readable code.
The deep reinforcement learning community has made several independent improvements to the DQN algorithm. This tutorial presents latest extensions to the DQN algorithm in the following order:
1. Playing Atari with Deep Reinforcement Learning(DQN with experience replay)
[[arxiv]](https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf) CoRR 2013
[[code]](https://github.com/higgsfield/RL-Adventure/blob/master/1.dqn.ipynb)
本文提出了基于经验回放的DQN,标志着DQN的诞生,也标志着深度强化学习的诞生。
经验回放(experience replay):将经验(即历史的状态、动作、奖励等)存储起来,再在存储的经验中按一定的规则采样。
经验回放主要有"存储"和"采样回放"两大关键步骤。
- 存储:将轨迹以(St,At,Rt+1,St+1)等形式存储起来;
- 采样回放:使用某种规则从存储的(St,At,Rt+1,St+1)中随机取出一条或多条经验。
经验回放有以下好处。
- 在训练Q网络时,可以消除数据的关联,使得数据更像是独立同分布的(独立同分布是很多有监督学习的证明条件)。这样可以减小参数更新的方差,加快收敛。
- 能够重复使用经验,对于数据获取困难的情况尤其有用。

![]()


2. Human-level control through deep reinforcement learning(DQN with target network)
[[arxiv]](https://www.nature.com/articles/nature14236) Nature 2015
[[code]](https://github.com/devsisters/DQN-tensorflow)
本文提出了目标网络(target network)这一概念,目标网络是在原有的神经网络之外再搭建一份结构完全相同的网络。原先就有的神经网络称为评估网络(evaluation network)。在学习的过程中,使用目标网络来进行自益得到回报的评估值,作为学习的目标。在权重更新的过程中,只更新评估网络的权重,而不更新目标网络的权重。这样,更新权重时针对的目标就不会再每次迭代都变化,是一个固定的目标。在完成一定次数的更新后,再将评估网络的权重值赋给目标网络,进而进行下一批更新。这样,目标网络也能得到更新。由于在目标网络没有变化的一段时间内回报的估计是相对固定的。目标网络的引入增加了学习的稳定性。所以,目标网络目前已经成为深度Q学习的主流做法。


3. Deep Reinforcement Learning with Double Q-learning(Double DQN)
[[arxiv]](https://arxiv.org/abs/1509.06461) AAAI 2016
[[code]](https://github.com/higgsfield/RL-Adventure/blob/master/2.double%20dqn.ipynb)
双重Q学习可以消除最大化偏差(maximization bias)。
本文将双重Q学习用于DQN,得到双重DQN(Double DQN,DDQN)。考虑到DQN已经有了评估网络和目标网络两个网络,所以双重DQN在估计回报时只需要用评估网络确定动作,用目标网络确定回报的估计即可。
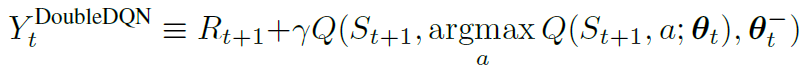

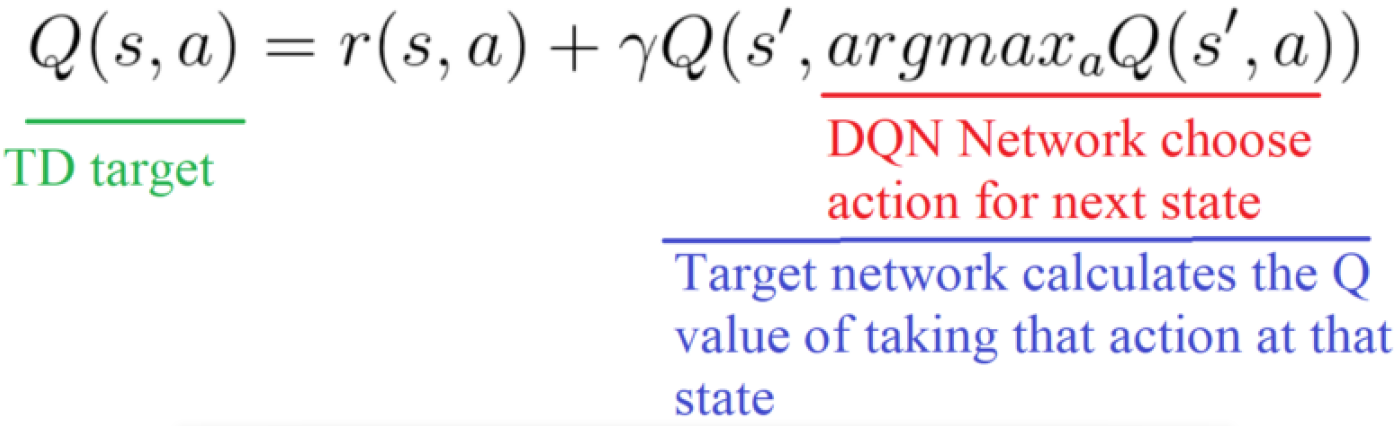
![]()
4. Dueling Network Architectures for Deep Reinforcement Learning(Dueling DQN)
[[arxiv]](https://arxiv.org/abs/1511.06581) ICML 2016
[[code]](https://github.com/higgsfield/RL-Adventure/blob/master/3.dueling%20dqn.ipynb)
本文提出了一种神经网络结构——对偶网络(dual network)。
对偶网络理论利用动作价值函数和状态价值函数之差定义了一个新的函数——优势函数A(advantage function):
![]()
由于同一个Q函数事实上存在着无穷多种分解为V函数和A函数的方式。为了不给训练带来不必要的麻烦,往往可以通过增加一个由优势函数导出的量,使得等效的优势函数满足固定的特征,使得分解唯一。常见的方法有以下两种:
- 考虑优势函数的最大值,令
![]()
- 考虑优势函数的平均值,令
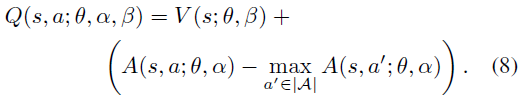
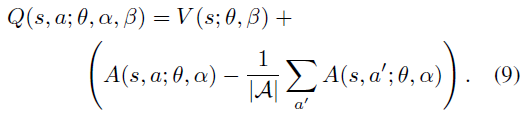
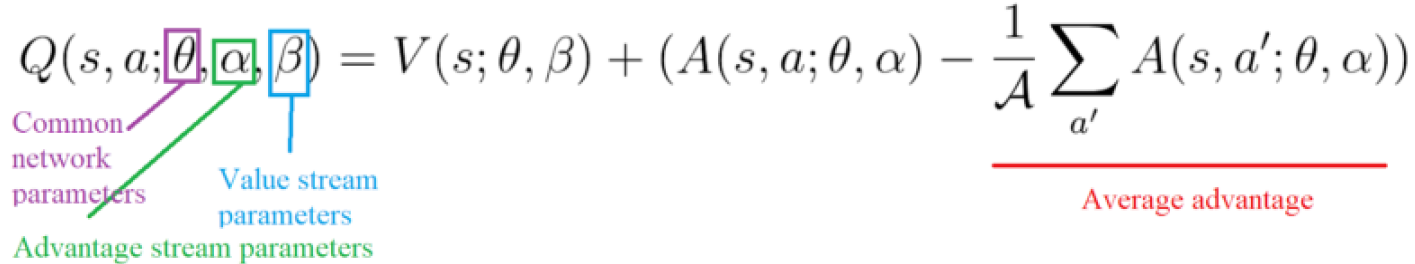
5. Prioritized Experience Replay(PER,Prioritized DQN)
[[arxiv]](https://arxiv.org/abs/1511.05952) ICLR 2016
[[code]](https://github.com/higgsfield/RL-Adventure/blob/master/4.prioritized%20dqn.ipynb)
本文提出了优先回放。优先回放的思想是为经验池里的经验指定一个优先级,在选取经验时更倾向于选择优先级高的经验。

6. Noisy Networks for Exploration(Noisy DQN)
[[arxiv]](https://arxiv.org/abs/1706.10295) ICLR 2018
[[code]](https://github.com/higgsfield/RL-Adventure/blob/master/5.noisy%20dqn.ipynb)
[[blog]](https://www.cnblogs.com/lucifer1997/p/17526784.html)
本文提出了一种将参数化的噪音加入到神经网络权重上去的方法来增加强化学习中的探索,称为NoisyNet。
用于探索的NoisyNet可以替代原本的ε-贪婪策略(DQN -> NoisyNet-DQN)。
Noisy Linear Layer:
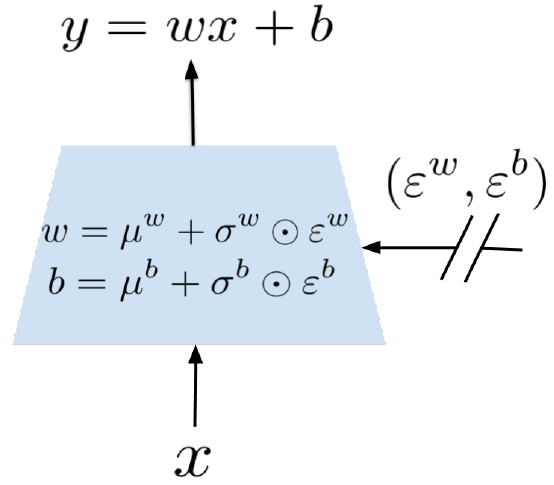
The NoisyNet-DQN Loss:
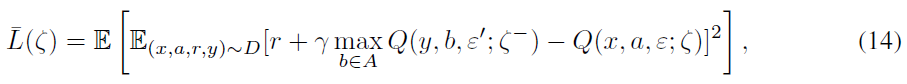
The NoisyNet-Dueling Loss:
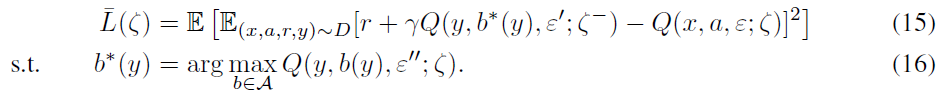
7. A Distributional Perspective on Reinforcement Learning(C51)
[[arxiv]](https://arxiv.org/pdf/1707.06887.pdf) ICML 2017
[[code]](https://github.com/higgsfield/RL-Adventure/blob/master/6.categorical%20dqn.ipynb)
[[blog]](https://www.cnblogs.com/lucifer1997/p/13278861.html)
本文主张采用分布观点来进行强化学习,研究的主要对象是期望价值为Q的随机回报Z。此随机回报也由递归方程描述,但具有分布性质:
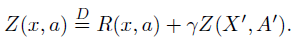

8. Rainbow: Combining Improvements in Deep Reinforcement Learning
[[arxiv]](https://arxiv.org/abs/1710.02298) AAAI 2018
[[code]](https://github.com/higgsfield/RL-Adventure/blob/master/7.rainbow%20dqn.ipynb)
源代码缺乏关键的多步回报以及优先重播的实现。
[[code]](https://github.com/Kaixhin/Rainbow)
本文研究了DQN算法的六个扩展(双重DQN、优先DQN、对偶DQN、多步回报、分布DQN以及带噪DQN),并实证研究了它们的组合。实验表明,该组合在数据效率和最终性能方面均提供了Atari 2600基准测试的最先进性能。本文还提供了详细的消融研究结果,显示了每个组件对整体性能的贡献。
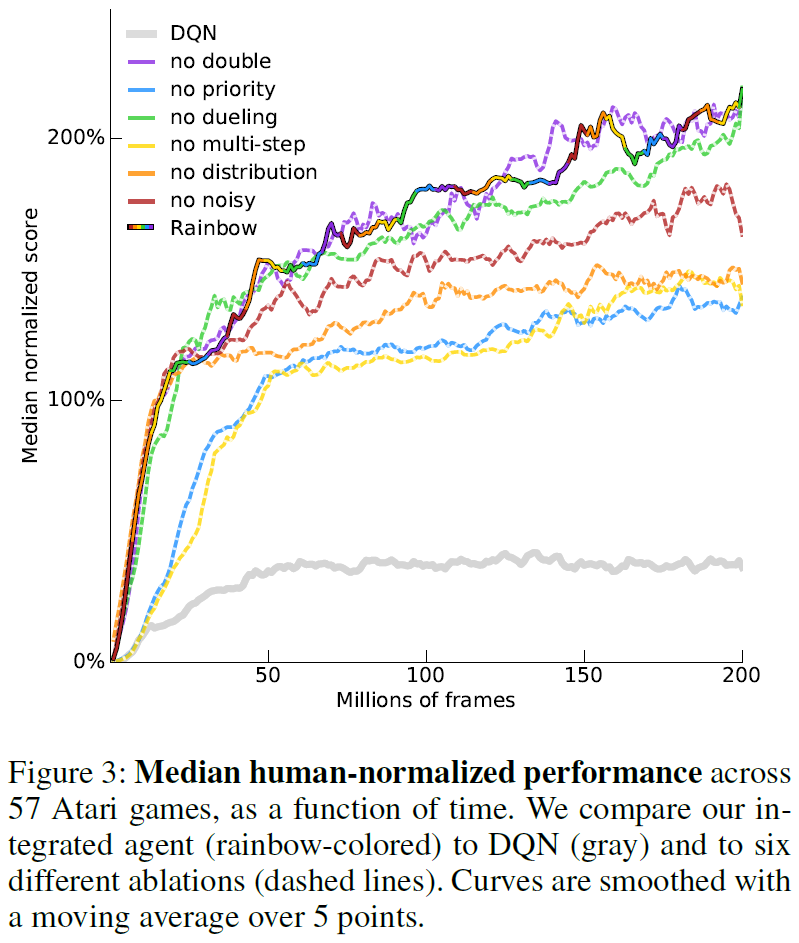
9. Dopamine: A Research Framework for Deep Reinforcement Learning
[[arxiv]](https://arxiv.org/abs/1812.06110)
[[code]](https://github.com/google/dopamine)
Dopamine Rainbow智能体(Castro et al., 2018),是对原始Rainbow智能体的开源实现(Hessel et al., 2018),但是做出了一些简化的设计选择。原始智能体通过使用(a) 分布学习目标,(b) 多步回报,(c) Adam优化器,(d) 优先回放,(e) 双重Q学习,(f) 对偶结构,以及(g) 带噪的探索网络。Dopamine Rainbow智能体仅使用这些调整的前四个,在Hessel et al. (2018)的原始分析中被确定为该智能体最重要的方面。
10. Distributional Reinforcement Learning with Quantile Regression(QR-DQN)
[[arxiv]](https://arxiv.org/pdf/1710.10044.pdf) AAAI 2018
[[code]](https://github.com/higgsfield/RL-Adventure/blob/master/8.quantile%20regression%20dqn.ipynb)
[[blog]](https://www.cnblogs.com/lucifer1997/p/13278817.html)
首先,本文将现有结果扩展到近似分布设置。其次,本文提出了一种与理论公式相一致的新颖的分布强化学习算法。

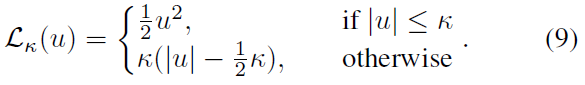
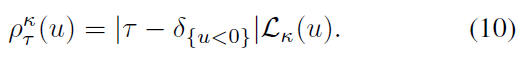
11. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
[[arxiv]](https://arxiv.org/abs/1604.06057) NIPS 2016
[[code]](https://github.com/higgsfield/RL-Adventure/blob/master/9.hierarchical%20dqn.ipynb)

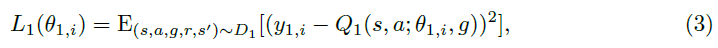
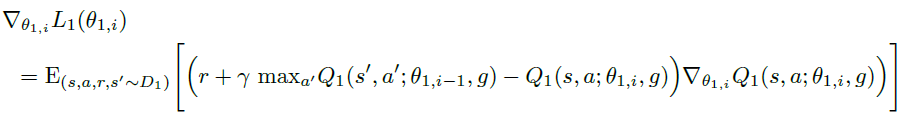
12. Neural Episodic Control
[[arxiv]](https://arxiv.org/pdf/1703.01988.pdf) ICML 2017
[[code]](#)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号