Solving the Distal Reward Problem through Linkage of STDP and Dopamine Signaling
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

BMC Neuroscience, no. Suppl 2 (2007): 15-2
Abstract
在巴甫洛夫式和工具性条件下,奖励通常是在奖励触发动作几秒钟后产生的,从而产生了一个被称为"远端奖励问题"的解释难题:如果 1)奖励到达时不再存在这些模式,并且 2)在等待奖励的所有神经元和突触都处于活跃状态,大脑如何知道大脑中哪些神经元负责奖励?在此,我们展示了如何通过具有由多巴胺(DA)调节的脉冲时间依赖可塑性(STDP)的皮质脉冲神经元模型网络来解决难题。尽管STDP是在毫秒的时间尺度上由几乎重合的发放模式触发的,但随后的突触可塑性的缓慢动态在几秒钟的关键时间内对细胞外DA浓度的变化敏感。在等待期间随机获得奖励不会影响STDP,因此不会使网络对正在进行的活动不敏感——这项关键功能将我们的方法与以前的理论研究区分开来,后者隐含地假设网络在等待期间是安静的,或者这些模式将保留下来,直到获得奖励为止。这项研究强调了精确发放模式在大脑动态中的重要性,并提出了以细胞外DA形式出现的整体扩散性强化信号如何在正确的时间选择性地影响正确的突触。
Keywords: classical conditioning, dopamine, instrumental conditioning, reward, simulation, spike-timing-dependent plasticity (STDP)
Introduction
学习线索和奖励(经典或巴甫洛夫条件反射)之间或线索、动作和奖励(工具或操作条件反射)之间的关联涉及通过奖励或惩罚来加强神经元活动(Pavlov 1927; Hull 1943; Houk, Davis, Beiser 1995; Schultz 1998; Dayan and Abbott 2001)。通常,奖励会在奖励预测线索或奖励触发动作之后几秒钟出现,这造成了一个解释性难题,在行为文献中称为"远端奖励问题"(Hull 1943),在强化学习文献中称为"信度"分配问题(Minsky 1963; Barto et al. 1983; Houk, Adams, Barto 1995; Sutton and Barto 1998; Dayan and Abbott 2001; Worgotter and Porr 2005)。事实上,动物怎么知道奖励之前的许多线索和行为中的哪一个应该被归功于奖励?在神经术语中,感觉线索和运动动作对应于神经元发放,如果在奖励到达时模式不再存在,大脑如何知道在所有可能模式的无限库中哪些发放模式对奖励负责?如果在等待奖励期间有许多神经元发放,它如何知道哪些神经元的哪些脉冲会导致奖励?最后,如果DA在全局范围内释放给许多突触,那么以神经调节剂多巴胺(DA)形式出现的常见强化信号(Schultz 1998, 2002; Seamans and Yang 2004; Schultz 2007a, 2007b)如何在正确的时间影响正确的突触?在本文中,我们展示了如何在具有DA调节可塑性的皮质脉冲神经元模拟网络中解决信度分配问题。
DA调节突触可塑性的一个重要方面是其增强长时程增强(LTP)和长时程抑制(LTD):在海马区,DA D1受体激动剂增强破伤风诱导的LTP,但如果激动剂在破伤风后15-25秒到达突触则效果消失(Otmakhova and Lisman 1996, p. 7481; 另见Impey et al., 1996; Barad et al. 1998),从而表明存在一个短暂的增强机会窗口。海马→前额叶皮质通路中的LTP通过在体内直接应用DA (Jay et al. 1996)或通过释放DA的腹侧被盖区(VTA)的爆发刺激得到增强(Gurden et al. 2000)。相应地,D1受体拮抗剂阻止LTP的维持(Frey et al. 1990; Impey et al. 1996),而激动剂通过阻断去能化促进它(Otmakhova and Lisman 1998),即使它们是在可塑性触发刺激之后应用的。DA还被证明可以增强前额叶皮层第5层锥体神经元中破伤风诱导的LTD (Otani et al., 2003),并且它可以控制纹状体投射神经元中的皮质纹状体LTP和LTD (Choi and Lovinger 1997; Centonze et al. 1999; Calabresi et al. 2000)。
脉冲时序依赖突触可塑性(STDP)涉及突触的LTP和LTD:在突触后神经元之前立即发放突触前神经元导致突触传递的LTP,并且发放的相反顺序导致LTD,如图1a,b所示(Levy and Steward 1983; Markram et al., 1997; Bi and Poo 1998; 另见Gerstner et al. 1996的理论论文)。可以合理地假设STDP的LTP和LTD组件由DA调节,其方式与它们在经典LTP和LTD协议中的方式相同(Houk, Adams, Barto 1995; Seamans and Yang 2004)。也就是说,特定的发放顺序会引起突触变化(正或负),如果在几秒钟的关键窗口期间存在细胞外DA,这种变化会增强。
在本文中,我们展示了STDP的DA调节具有工具调节的内置特性:它可以加强在毫秒时间尺度上发生的发放模式,即使它们之后是延迟几秒的奖励。该属性依赖于作为"突触资格迹"(Klopf 1982; Sutton and Barto 1998)或"突触标签"(Frey and Morris 1997)的缓慢突触过程的存在。这些过程是由几乎同时发生的脉冲模式触发的,但由于STDP的时间窗口很短,它们在等待奖励期间不受随机发放的影响。为了说明这一点,考虑2个神经元,每个神经元每秒发出1个脉冲,这与新皮质锥体神经元的自发发放率相当(所有层:小于1 Hz,通常小于0.1 Hz,第5层:4.1 Hz;Swadlow 1990, 1994)。几乎同时发生的发放将触发STDP并改变突触标签。然而,具有相同发放频率的后续随机脉冲将在50 ms内相互触发更多STDP并改变突触标签的概率非常小——平均每20秒一次(我们在Reinfocing a Synapse中详细说明了这一点)。在等待期间,突触标签对随机正在进行的活动的这种"不敏感性"是我们的方法与以前的研究(参见例如,Houk, Adams, Barto 1995; Seung 2003)区别开来的关键特征,它要求网络在等待期间保持安静,或者将模式保留为持续响应(Drew and Abbott 2006)。在本文中,我们展示了DA调节的STDP如何选择性地加强精确的脉冲时序模式,这些模式始终在奖励之前并忽略不导致奖励的其他发放。在文章的最后,我们讨论了为什么这种机制只有在精确的发放模式嵌入噪声海洋时才有效,以及为什么它在平均发放率模型中失败。
我们还提出了时序差分(TD)强化学习规则(Sutton 1988)的最重要方面的脉冲网络实现——DA的奖励触发释放从无条件刺激(US)到奖励预测条件刺激(CS)的转变(Ljungberg et al. 1992; Montague et al. 1996; Schultz et al. 1997; Schultz 1998, 2002, 2006b; Pan et al., 2005)。我们的模拟展示了STDP的DA调节如何在奖励电路中发挥重要作用并解决远端奖励问题。
Materials and Methods
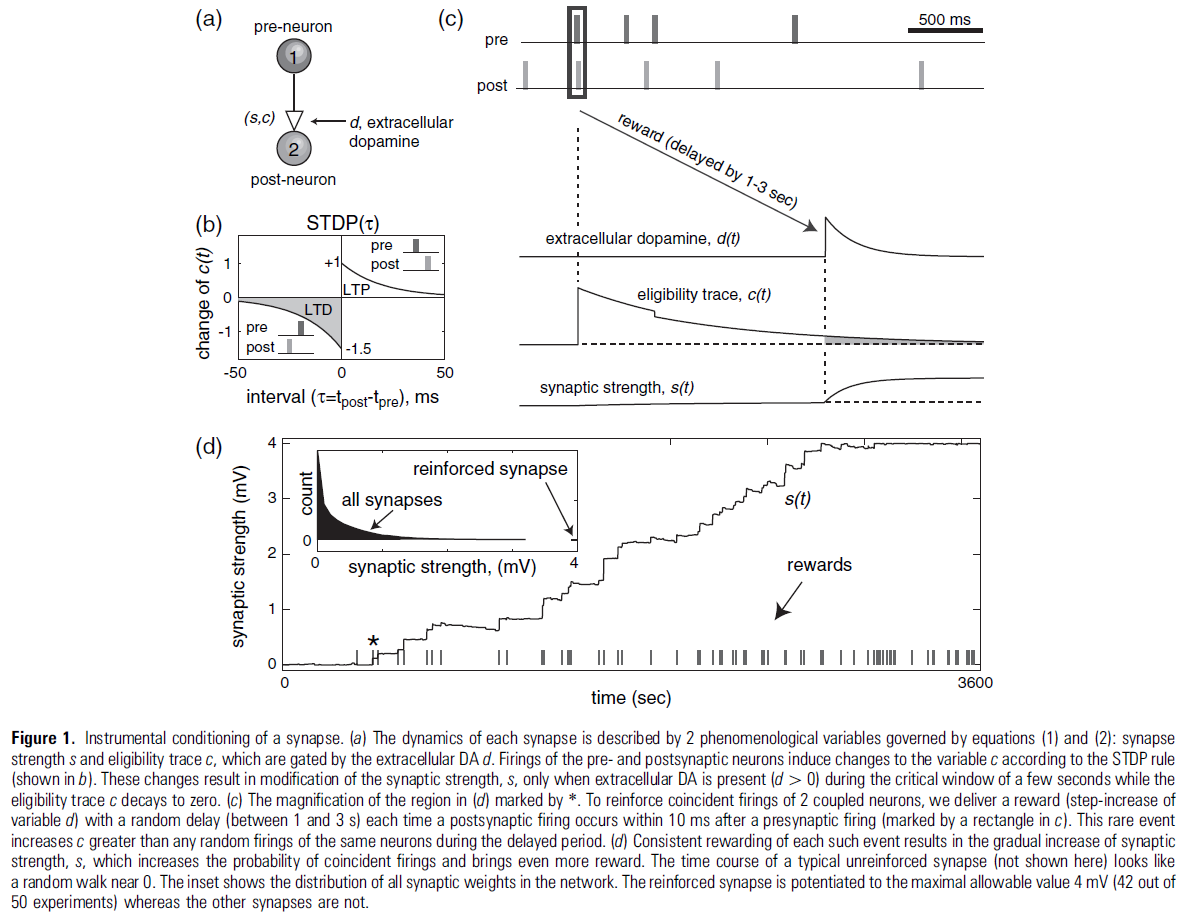
由于STDP和DA触发的细胞内过程的动力学细节尚不清楚,我们建议使用最简单的现象学模型来捕捉STDP的DA调节的本质。继Izhikevich et al. (2014)之后,我们使用2个现象学变量(图1a)描述每个突触的状态:突触强度/权重 s 和对可塑性很重要的酶的激活,例如CaMK-II的自磷酸化(Lisman 1989)、PKC或PKA的氧化,或其他一些相对缓慢的过程,充当突触标签:
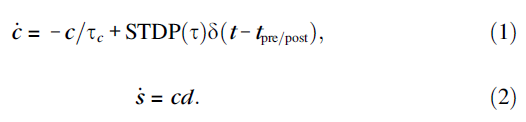
在这里和下面,d 描述了DA的细胞外浓度,δ(t)是逐步增加变量 c 的Dirac delta函数。突触前和突触后神经元的发放,分别发生在时间tpre/post,将 c 改变为图1b中描述的量STDP(τ),其中τ = tpost - tpre是脉冲间隔。该变量以时间常数τe = 1 s指数衰减到c = 0,如图1c所示。衰减率控制可塑性对延迟奖励的敏感性。实际上,c 充当突触修改的"资格迹"(Houk, Adams, Barto 1995),因为它允许通过由 d 控制的公式(2)改变突触强度 s。详细的生物物理/动力学模型可以更好地描述突触标签 c 的衰减。请注意,资格迹的衰减相对较快,因此在STDP触发事件5 s后DA的影响可以忽略不计,这与Otmakhova and Lisman (1996)的实验结果一致,他们在诱导可塑性后15-25秒交付DA,观察到没有影响。
该模型以生物物理学上合理的方式将突触特异性STDP中脉冲相互作用的毫秒时间尺度和由与行为时间尺度相对应的全局奖励信号调节的缓慢迹相结合。没有直接的实验证据支持或反对我们的模型;因此,该模型基于纯粹的理论考虑,对DA对STDP的作用做出了可检验的预测,而不是事后预测。
变量 d 描述了细胞外DA的浓度(μM),并且对于我们模型中的所有突触都是相同的(而对于不同的突触,c 和 s 是不同的)。我们假设:
![]()
其中τd是DA摄取的时间常数,DA(t)模拟由于中脑结构VTA和黑质致密部中多巴胺能神经元的活动而产生的DA来源。Montague et al. (2004)最近提出了基于Michaelis-Menten形式主义对DA动力学的更好描述。
在下面的模拟中,我们取τd = 0.2 s,它大于实验测量的纹状体中DA摄取的时间常数(大约0.1 s,Wightman and Zimmerman 1990; Garris et al. 1994),但小于前额叶皮层的时间常数(秒,参见Cass and Gerhardt 1995)。我们将DA的补品来源设为DA(t) = 0.01 lM/s,因此通过纹状体和前额叶皮层的微透析测量,DA的基准(补品)浓度为2 nM (Seamans and Yang 2004, p. 31)。我们将图1c中奖励的传递模拟为多巴胺能神经元的活动爆发,它将DA的浓度逐步增加0.5 lM(即,在奖励时刻trew,DA(t) = 0.5d(t - trew) lM/s),在Garris et al. (1994)测量的范围内,因为DA的强直水平远低于奖励期间的阶段水平,所以除非提供奖励(d 很大),否则不会发生突触强度的显著改变(d ≈ 0)。在图4中,对于VTAp组中的神经元发出的每个脉冲,我们使用DA(t) = 0.004d(t) lM/s。公式(1)和(2)的一个可能扩展是考虑对应于级联过程的突触标签向量(Fusi et al. 2005)。在这种情况下,STDP触发的突触资格迹增加不会是瞬时的,如图1c所示。相反,它会像突触阿尔法函数一样缓慢增加然后减少,但时间尺度更长。缓慢的增加会产生一个"不应期",对应于过早的奖励不敏感。
所有模拟均使用由提供MATLAB和C代码的Izhikevich (2006)详细描述的1000个脉冲神经元网络进行。该代码也可以在作者的网页www.izhikevich.com上找到。该网络具有80%的常规脉冲类型的兴奋性神经元和20%的快速脉冲类型的抑制性神经元(Connors and Gutnick 1990),代表皮质小柱的2/3层部分。神经元以10%的概率随机连接,因此每个平均神经元有100个突触。这些连接与模拟带噪的微型PSP的随机输入相结合,使神经元以1 Hz左右的平均频率发放类似泊松的脉冲序列。这种低频率的发放对于连续脉冲偶然落入STDP时间窗口的"低概率"很重要(新皮质层2/3的发放率远低于1 Hz,Swadlow 1990, 1994)。最大轴突传导延迟取为1 ms。每个兴奋性突触根据公式(1)和(2)进行修改,STDP如图1b所示,但权重限制在0到4 mV的范围内(即裁剪到0至4 mV)。兴奋到兴奋和兴奋到抑制的突触连接都遵循相同的STDP规则。人们可以对后者使用不同的、更生理的STDP规则,甚至保持它们固定(非可塑性)。我们的选择是为了简单起见并与脉冲模型的先前实现保持一致(Izhikevich 2006)。抑制性突触在模型中不是可塑性的。图1b中的LTD区域比LTP区域大50%,因此任何2个神经元的不相关发放都会导致它们之间的突触强度降低(Kempter et al. 1999a, 1999b; Song et al. 2000)。由于自发活动,网络中兴奋性突触的强度收敛到图1d插图中描绘的指数分布。请注意,所有突触都比最大允许值4 mV弱得多,并且大多数小于0.1 mV。
Results
下面我们使用1000个具有DA调节STDP的皮层神经元的脉冲网络来说明增强嵌入噪声海洋的精确发放模式的各个方面。
Reinforcing a Synapse
Classical (Pavlovian) Conditioning
Stimulus-Response Instrumental Conditioning
Shift of DA Response from US to Reward-Predicting CS in Classical Conditioning
Discussion
我们使用带有DA调节STDP的脉冲网络展示了巴甫洛夫和工具式调节的生物学合理实现以及TD强化学习的某些方面。基于DA调节经典LTP和LTD的实验证据,我们假设DA具有允许STDP发生的许可且启用效应——这是一个以前从未提出过的可测试假设。尽管STDP以毫秒为单位起作用,但突触可塑性的缓慢生化动态可能使其对延迟数秒的DA奖励敏感。我们将脉冲网络解释为代表前额叶皮层的一小部分,从中脑接收大量多巴胺能投射并投射到中脑(Seamans and Yang, 2004),尽管该理论也可以应用于新纹状体和基底神经节。我们的模拟表明了一种神经合理的机制,即如何学习线索、动作和延迟奖励之间的关联(图1-3),以及DA响应如何从US转变为奖励预测CS(图4)。
Spiking Implementation of Reinforcement Learning
Seung (2003)、Hasselmo (2005)以及Koene和Hasselmo (2005)已经提出了强化学习的脉冲实现,并且还有更多基于突触资格迹的模型(参见例如Houk, Davis, Beiser 1995)。所有这些模型都有一个共同的缺点:它们要求网络在等待奖励期间相对安静。事实上,等待期间的随机神经元活动会触发所有突触中的突触传递,改变资格迹,并阻碍学习。相比之下,STDP在等待期间对随机发放不敏感,但只对精确发放模式敏感。由于精确模式集在所有可能的发放模式空间中都是稀疏的,因此DA调节的STDP利用了这一事实,并提供了一种优越的强化学习机制。
Rao和Sejnowski (2001)明确考虑了STDP和TD之间的关系,但他们提出了相反的问题:如何从TD获得STDP作用于毫秒时间尺度以及由此产生的STDP如何取决于树突位置?
Synaptic Eligibility Traces
由变量c (见公式1)建模的突触可塑性的缓慢动态导致突触资格迹的存在(Houk, Adams, Barto 1995)。这是经典机器学习算法中的一个古老思想,其中资格迹被分配给线索和动作,如TD(λ)学习规则(Houk, Davis, Beiser 1995; Sutton and Barto 1998; Worgotter and Porr 2005)。为了使机器学习算法起作用,网络需要提前知道所有可能的线索和动作的集合。相比之下,有大量可能的脉冲时序模式可以触发STDP,并且可以代表脉冲网络的未指定线索和动作(Izhikevich 2006)。它们中的任何一个都可以与环境或实验者的奖励相关联,并且网络可以使用比TD(k)或其他机器学习算法更具有生物学合理性的方式自行找出哪一个。
Spiking Implementation of TD
我们的模型展示了TD强化学习某些方面的可能脉冲网络实现:DA响应从US到奖励预测CS的转变。我们强调这个属性不是内置在模型中的,但是当我们允许突触到VTA投射神经元上的突触像网络中的任何其他突触一样受到DA的影响时,它就会自发地出现。因此,转变是应用于突触电路的DA调节STDP的一般属性,投射到VTA。这种转变的机制非常出人意料:它利用了STDP对CS呈现期间US、CS和VTA投射神经元发放的精细时间结构的敏感性,如图4e所示。
请注意,图4中的DA响应不是TD算法所需的真正错误预测信号,因为当省略US时,该模型未能表现出VTAp组活动中的发放率(下降)降低(Montague et al., 1996; Schultz 1998)。一方面,由于CS和US之间的间隔是随机的,因此预期不会出现萧条。然而,即使间隔是固定的,也不会发生萧条,因为没有内部时钟或预期信号告诉网络何时会出现US。为了抑制发放率,可以模拟尾状核和苍白球产生的US预期信号(Watanabe 1996; Suri and Schultz 2001; Lauwereyns et al. 2002),并在US预期的那一刻刺激抑制性神经元到达(建模尾状核和苍白球不在本文的范围内)。另请注意,图4中的DA响应并未表现出延迟的逐渐变化,正如TD模型所预测的那样,而是从US跳跃到奖励预测CS,这与在体内实验中观察到的效果更一致(Pan et al. 2005)。与这些记录一致,图4中对US的DA响应并未完全减弱,但仍高于基准水平。最后,训练后意外出现的US会导致模型中DA反应减弱,因为US→VTAp的突触连接被抑制,也就是说,关联是未学习的,与体内记录显示强烈反应相反(Schultz 1998, 2002)。因此,DA调节STDP足以在脉冲活动和突触可塑性的生物学相关项中重现TD强化学习的某些方面,但不是所有方面。为了解决所有方面,需要改进网络架构并引入类似于基底神经节的解剖回路。
Spiking versus Mean Firing Rate Models
我们的研究强调了大脑动态中精确发放模式的重要性:本文提出的机制仅在奖励预测刺激与精确发放模式相对应时才起作用。我们只考虑了嵌入噪声海的同步模式,但同样的机制对于多时触发模式同样有效,即时间锁定但不同步(Izhikevich 2006)。有趣的是,基于发放率的学习机制无法强化这些模式。事实上,提示的呈现,例如图2中的S1,不会增加任何神经元的发放率;它只是添加、删除或更改S1中50个神经元中每个神经元的单个脉冲时间。特别是,神经元继续以每秒1-2个脉冲的频率发放类似泊松分布的脉冲序列。有关刺激的信息仅包含在脉冲的相对时间中,脉冲在图2中被视为垂直条纹,可有效触发STDP。同一网络的平均发放率描述将导致神经元活动具有恒定值,对应于恒定发放率,不可能知道刺激何时发生。
相反,DA调节的STDP将无法加强发放率模式。事实上,大的发放率波动会产生多个具有随机pre-post顺序的重合脉冲,因此由LTD主导的STDP将导致突触强度的平均下降(Kempter et al. 1999a, 1999b; Song et al. 2000)。因此,即使巧合并不罕见,STDP仍然可以将由于基于发放率的动态引起的偶然巧合与由于脉冲时间动态引起的因果关系分离(Wulfram Gerstner 向作者强调了这一点)。这就是DA调节STDP与基于发放率的学习规则的不同之处,这就是为什么选择性地强化精确发放模式但对发放率模式不敏感的原因如此有效。
Reward versus Punishments
人们不仅可以使用我们的方法对奖励进行建模,还可以对惩罚进行建模。事实上,我们可以将变量d视为高于某个基准水平的细胞外DA浓度。在这种情况下,d的负值被解释为低于基准的浓度,导致主动忘记发放模式,即惩罚。另一种实现惩罚的方法是假设DA仅控制STDP的LTP部分。在这种情况下,DA信号的缺失导致突触连接的整体抑制(惩罚),DA的某些中间值导致STDP的LTD和LTP部分之间的平衡(基准),而强DA信号导致符合条件的增强突触连接(奖励)。有轶事证据表明STDP曲线在前额叶和运动皮质中具有非常小的LTP部分(Desai NS,个人交流)。该模型做出了一个可测试的预测,即如果在突触可塑性诱导期间或之后立即存在DA,则STDP曲线看起来会大不相同。
Conclusion
STDP的DA调节为远端奖励/信度分配问题提供了一个优雅的解决方案:只有几乎重合的脉冲模式被奖励强化,而奖励延迟期间不相关的脉冲不影响资格迹(变量c),因此会被网络忽略。与之前的理论研究相比,1) 网络在等待奖励期间不必保持安静,2) 不必通过神经元的重复活动保留奖励触发模式。如果所有可能模式中的一个脉冲模式始终如一地先于或触发奖励(甚至几秒钟后),则负责生成该模式的突触有资格在奖励到达时进行修改,并且该模式得到持续强化(已分配信度)。即使网络不知道归于哪个模式,但将来在相同的行为上下文中更有可能生成相同的模式。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号