Understanding dopamine and reinforcement learning: The dopamine reward prediction error hypothesis
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
在中脑多巴胺能神经元的研究中取得了许多最新进展。要了解这些进步以及它们之间的相互关系,需要对作为解释框架并指导正在进行的实验探究的计算模型有深刻的理解。现在,理论和实验的这种相互交织非常清楚地表明,中脑多巴胺神经元的阶段性活动为突触改变提供了一个整体机制。这些突触改变反过来又为特定类别的强化学习机制提供了机械基础,而强化学习机制现在似乎已成为人类和动物行为的基础。这篇综述既描述了该结论的关键经验性发现,也描述了得出此结论的奇妙的理论进展。
当今可获得的理论和数据表明,中脑多巴胺神经元的相位活动编码了用于指导整个额叶皮质和基底神经节学习的奖励预测误差。现在认为这些多巴胺能神经元的活动表明受试者对当前和未来事件的价值的估计是有误差的,并表明该误差的严重程度。这是一种组合信号,大多数从事多巴胺研究的学者认为,这种信号可以定量地调节突触强度,直到受试者对当前和未来事件的价值估计准确地被编码在额叶皮层和基底神经节中。尽管较大的神经科学界仍存在一些困惑,但很少有数据与此假设不符。这篇回顾简要概述了行为学,解剖学,生理学和生物物理数据之间的解释性协同作用,这些协同作用是由最近的计算进展所建立的。有关此假设的更详细处理,请参阅Niv and Montague(1)或Dayan and Abbot(2)。
Features of Midbrain Dopamine Neurons
三组分泌多巴胺的神经元沿着影响许多区域(3)大脑活动的远距离轨迹发送轴突:腹侧被盖区(VTA)的A8和A10组以及黑质致密部(SNc)的A9组 。这些神经元在发现时注意到的两个显著特征是它们的非常大的细胞体和非常长且复杂的轴突轴,其中包括专门将递质释放到细胞外空间的末端,以及伴随突触的多巴胺,通过突触可以实现极为广泛的解剖学分布(4)。正如Cajal(5)首先指出的那样,轴突轴的长度和复杂性通常与细胞体紧密相关。需要大的细胞体来支持大的末端区域,而多巴胺能细胞体则尽可能地大。因此,中脑多巴胺能系统以尽可能少的神经元数量实现其信号的最大可能分布。
A9簇连接到尾状和壳状核,而A8和A10轴突与腹侧纹状体和额叶皮层区域(6, 7)接触。但是,似乎三个细胞组(8-10)混合在一起。在从切片准备到灵长类动物清醒的条件下,对这些细胞的经典研究表明,这些组的响应模式均具有同质性。尽管在慢性研究中可能很难知道实际上是从多巴胺神经元记录下来的(11),但在VTA和SNc核心的所有看起来像多巴胺神经元的细胞似乎都以相同的方式响应。甚至这些神经元的轴突的结构也支持这样的观念,即在整个巨型细胞群体中,活动是同质的。在该系统中,相邻神经元的轴突彼此电耦合(12, 13)。建模研究表明,这种耦合使单个神经元更难以单独发放,从而在整个群体中强制高度同步并因此紧密关联发放(14)。
最后要注意的是,这些神经元会产生长达2–3ms的非典型持续时间动作电位。这是相关的,因为它对这些神经元可以产生的最大发放率设置了非常低的限制(15)。
从许多研究中得出的想法是,多巴胺神经元在结构上非常适合用作专门的低带宽通道,以将相同的信息广播到基底神经节和额叶皮层的大区域。细胞体的大小很大,细胞是电耦合的,它们以低发放率将多巴胺均匀分布在巨大的神经支配区域——所有这些不寻常的事情意味着它们不能对大脑的其余部分说太多,但是它们所说的必须被广泛听到。但是,还应该注意,发布位置的专业化可以很好地过滤此通用消息,使其适合不同类别的接受者。 Zhang et al.(16)最近显示了背侧和腹侧纹状体中多巴胺水平的时程之间的差异,这可能反映了这些区域之间释放和再摄取的功能专业化。
Dopaminergic Targets: Frontal Cortex and Basal Ganglia
同样重要的是要认识到,多巴胺神经元被嵌入在一个大型且描述清楚的回路中。在皮质水平上,多巴胺神经元发出的信号在整个中央沟前的整个区域都会传递,而对顶叶,颞叶和枕叶皮质则几乎不发送任何信息(6)。但是,多巴胺神经支配的额叶皮质的输出也有另一个共同点。额叶皮层的许多主要长距离输出都以地形学的方式传递至基底神经节复合体的两个主要输入核,即尾状核和壳状核(17)。这两个区域还接受中脑多巴胺能神经元的密集神经支配。
在结构上,尾状和壳状核(以及壳状核的腹侧大部分,称为腹侧纹状体)在发育过程中主要是一个单个的原子核,通过辐射冠纤维的侵入(2, 6, 18)主要投射到两个输出核,苍白球和黑质网状体。这些核随后提供两个基本输出。这些输出中的第一个也是最大的,是通过丘脑继电器将信息返回到额叶皮层。有趣的是,这种返回皮层的中继保持了强大的地形学排序(19, 20)。与计划骨骼肌运动有关的皮质内侧和后部将其输出发送到壳状核的特定子区域,后者通过苍白球将信号发送回皮质的同一区域和腹外侧丘脑。这些连接在一起形成了一组长反馈回路,这些回路似乎是串行互连的(9),并最终通过大规模额叶基底神经节系统的骨骼肌和眼球运动控制路径产生行为输出。
基底神经节的输出的第二主要类别针对中脑多巴胺神经元本身,并且还形成反馈回路。这些输出传递给多巴胺细胞的树突,在这里它们与来自脑干的输入结合,这些输入可能携带有关当前正在使用的奖励信号(21)。这样,发送到皮层和基底神经节的分布广泛的多巴胺信号可能反映了皮层和诸如舌头等部位的输出的某种组合。然后,组合的信号当然会由多巴胺神经元在整个基底神经节和额叶皮层中传播。
Theory of Reinforcement Learning
From Pavlov to Rescorla and Wagner. 然而,了解多巴胺神经元的功能作用不仅需要了解脑电路。它还需要了解多巴胺神经元似乎参与其中的计算算法的类别。Pavlov(22)在他对垂涎的狗所做的著名实验中观察到,如果一个人敲响铃铛并随响铃一起喂食,则在铃响后,狗就会变得容易流涎。这个过程是由条件刺激引起的非条件反应,是建立心理学学习理论的核心经验规律之一。Pavlov(22)假设出现这种行为规律性是因为根据经验,看到食物与唾液腺的激活之间已经存在解剖学联系。
当Bush和Mosteller(23,24)提出Pavlov(22)的狗在连续试验中表达唾液反应的可能性时,可以通过一个迭代方程来计算(公式1),这个非常笼统的想法首先通过数学形式化:
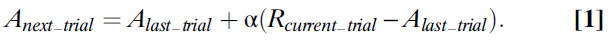
在此等式中,Anext_trial是下一次尝试中流涎的概率(或更正式地说,铃铛与流涎之间连接的关联强度)。为了计算Anext_trial,需要从上一次试验中的A值开始,然后根据最近一次试验中动物的经验对其进行更正。该更正或误差项是动物实际经历的东西(在这种情况下,肉粉的奖励被表示为Rcurrent_trial)与它所期望的东西(简单地说,先前试验中的A)之差。获得的结果与期望的结果之差乘以α,即从0到1的数字,称为学习率。当α=1时,A总是立即更新,因此从上一次试验开始等于R。当α=0.5时,仅校正了一半的误差,并且A的值半步收敛到R。当α值较小时(约为0.1),则A仅非常缓慢地增加到R的值 。
Bush和Mosteller(23, 24)等式的作用是计算先前试验中先前奖励的均值。在这个均值中,最近的奖励影响最大,而过去的奖励影响很小。如果举一个具体的例子,α=0.5,则该等式将获得最近的奖励,将其用于计算误差项,并将该项乘以0.5。因此,A的新值的一半是根据最近的观察结果构建的。这意味着以前所有误差项的总和(过去所有试验中的误差项)必须计入估计的另一半。如果查看较早的一半估算价值,则该一半价值的一半来自一次试验之前观察到的结果(因此,总估算值的0.25),而一半(估算值的0.25)来自之前所有试验的总和。迭代等式反映了先前奖励的加权总和。当学习率(α)为0.5时,有效执行的加权规则为(等式2):
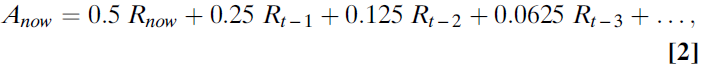 式子为一个指数级数,权重下降的速度由α控制。
式子为一个指数级数,权重下降的速度由α控制。
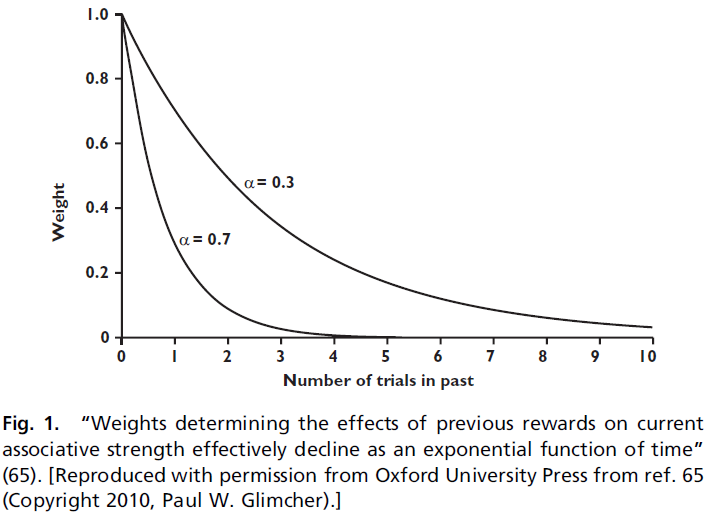
当α较高时,指数函数会迅速下降,并将所有权重都放在动物的最新经历上。当α较低时,它缓慢下降并平均许多观测值,如图1所示。
Bush和Mosteller(23,24)等式至关重要,因为它是这种基于迭代误差的迭代规则首次用于强化学习。此外,它构成了解决该问题的所有现代方法的基础。这通常被经典条件的Rescorla-Wagner模型(25)所掩盖。 Rescorla–Wagner模型是Bush和Mosteller方法(23, 24)的重要扩展,用于研究两个信号预测同一事件时关联强度的变化。他们的发现非常有影响力,以至于基本的Bush和Mosteller规则现在经常被神经生物学家错误地归因于Rescorla和Wagner。
Learning Value Instead of Associations. 下一个重要的观点是,这些早期的心理学理论是关于经典条件刺激与条件自动响应之间的关联强度的。这些模型是关于学习的,而不是关于价值和选择的概念,这些概念在关于多巴胺功能的当前讨论中占主导地位。但是,在动态编程,计算机科学和经济学领域,这些基本等式很容易被扩展到包含更明确的价值观念。考虑一种动物,它试图了解按下操纵杆的价值,该操纵杆产生概率为0.5的四粒食物。返回Bush和Mosteller(23, 24)(或Rescorla–Wagner)(25)等式(等式3):
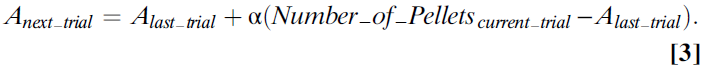
因为在所有试验的一半中,动物得到了奖励,而在另一半试验中,动物没有得到奖励,并且由于所有奖励的价值均为4,因此我们确切地知道了此等式将做什么。如果α值为1,则A会在0到4之间上下反弹;如果α无限小,则A将收敛为2。令人吃惊的是,按动操纵杆的长期平均价值或预期价值为2。因此,在不变的环境中,当α较小时,该等式收敛到动作的期望价值(等式4):

当前,Bush和Mosteller(23, 24)等式构成了大多数人如何思考学习价值的核心。该等式为我们提供了学习期望价值的方法。如果我们面对一个稳定的环境并且有很多时间,我们甚至可以证明该等式可以保证收敛到期望价值(26)。
Sutton and Barto: Temporal Difference Model. 到目前为止,关于强化学习的故事主要是来自心理学的故事,主要集中在联想学习上。在1990年代,计算机科学家Sutton和Barto(26)开始认真思考这些既有理论,并注意到它们存在两个关键问题后,这个故事就突然改变了:
- 这些理论都将时间视为通常称为试验的固定时期。在Bush和Mosteller(23, 24)中,试验一次又一次地通过,而行动价值的更新仅在两次试验之间发生。在现实世界中,时间更加连续。试验中的不同事件可能意味着不同的事物,或者可能表明有关价值的不同事物。
- 第二个关键问题是,这些理论仅以基本的方式处理了如何将顺序信号(例如,tone紧接着铃铛)与后来出现的正值或负值联系起来。该理论擅长了解tone或操纵杆可以预测奖励,但并不擅长了解完美地预测操纵杆外观的灯光意味着以后的操纵杆外观不会告诉您任何新鲜事物。
为了解决这些问题,Sutton和Barto(26)开发了后来被称为时序差分(TD)学习的方法。该模型已在其他地方(26)进行了详细介绍。在这里,我们回顾了他们所取得的最重要的进展,这些进展对于理解多巴胺至关重要。
Sutton和Barto(26)首先争论说,从本质上讲,Bush和Mosteller(23, 24)方法提出了学习系统试图错误解决的问题。Bush和Mosteller(23, 24)等式学习先前事件的价值。Sutton和Barto(26)认为学习系统的目标应该是预测未来事件的价值。当然,预测必须基于以前的经验,因此,这两个想法是紧密相关的。但是,TD学习的设计目标明确:预测未来的价值。
这是一个重要的区别,因为它改变了人们如何思考这些强化学习模型核心的奖励预测误差。在Bush和Mosteller(23, 24)这类模型中,奖励预测误差是过去奖励的加权平均价值与刚刚经历的奖励之差。当这些相同的时候,就没有误差,那么系统也就不会学习。相比之下,Sutton和Barto(26)则认为奖励预测误差项应被视为对所有未来奖励的理性期望与任何信息(无论是实际奖励还是即时奖励的信号)之差,这导致期望值的修改。例如,如果我们预测在接下来的10分钟内每1分钟收到一份奖励,并且视觉信号表明,我们将在11分钟内每1分钟获得一次奖励,而不是10次奖励。然后当视觉信号到达时预测误差就存在,而不是在11分钟后最终(到那时,完全可以预期的)奖励实际到达时的出现。这是TD类型与Bush和Mosteller(23, 24)类型的模型之间的主要区别。
为了实现目标,即建立既可以处理更连续的时间概念,又可以对未来奖励进行理性(或接近理性)期望的理论,Sutton和Barto(26)从简单的基于试验的时间表示形式转变为新的时间表示形式,即一系列离散时刻从现在延伸到无限的未来。然后,他们将学习想象为一个过程,它不仅发生在每个试验的结尾,而且发生在每个离散时刻。
要了解他们是如何做到的,请考虑一个简单的TD学习版本,其中每个试验都可以认为是由20个时刻组成。TD模型试图完成的工作是对这20个时刻中的每个时刻可以预期的奖励进行预测。这些预测的总和是我们对奖励的总期望。我们可以将这20个时刻的期望表示为20个学习价值的集合,其中20个时刻中每一个时刻各一个。这是TD类型与Bush和Mosteller(23, 24)类型的模型之间的第一个关键区别。第二个差异在于如何生成这20个预测。在TD中,每个时刻的预测不仅表明该时刻所期望的奖励,而且还表明每个后续时刻可用的(折扣)奖励的总和。
要了解这一临界点,请考虑在20个时刻的试验中,将估计价值V1附加到第一个时刻。该变量需要对当前期望的任何奖励价值进行编码,将在下一时刻期望的任何奖励价值按折扣因子递减,将下一时刻的价值进一步按折扣因子递减,依此类推。形式上,第一个时刻的价值函数为(等式5):
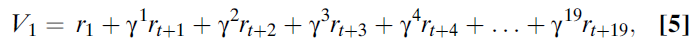
其中折扣因子γ反映了一个事实,即我们每个人都希望越早收到奖励而不是越晚收到奖励(从中获得更多效用);γ的大小取决于个体和环境。由于这是一个强化学习系统,因此在每次滴答时建立r的这些估计,它也会自动考虑概率。这意味着此处显示的r值是在该时刻上实际观察到的预期奖励或平均奖励。因此,两种事件可能会导致正预测误差:收到意外的奖励或收到信息,使人们可以预测之后的(之前是意外的)奖励。
为了使这一重要特征清晰可见,请考虑一种情况,即动物坐了20个时刻,并在任何不可预测的时刻,可能会以0.01的概率发送奖励。每当发送奖励时,它几乎是完全不可预测的,这在发送奖励时会导致较大的预测误差。这必然导致该时刻的价值增加。然而,在随后的试验中,通常情况是没有收到任何奖励(因为概率很低),因此,在随后的试验中,该时刻的价值会反复减小。如果学习率较低,则此增量和减量过程的结果是该时刻的价值将不断波动,然后接近于零,并且在每个不可预测的奖励之后,我们将观察到较大的奖励预测误差信号。在这种情况下,这个假想的试验中所有的20个时刻都是如此。
接下来,考虑当我们在前10个时刻中的任何一个时刻发出tone,然后在10个时刻之后给出奖励时,会发生什么情况。第一次发生这种情况时,tone不会传达有关未来奖励的信息,也不会期望获得任何奖励,因此,我们没有预测误差来推动学习。相反,在获得奖励时,会发生预测误差,从而推动那一刻的学习。但是,TD的目标为:当tone不足为奇时,在发出tone的10个时刻后发送的奖励不会产生任何预测误差。为什么后来的奖励不足为奇?这是由于tone导致的。因此,TD的目标是将预测误差从奖励转移到tone。
TD通过将获得的每个奖励不仅归因于当前时刻的价值函数,而且还归因于先前的一些时刻(正是模型的自由参数有多少个)来实现此目标。这样,随着时间的流逝,与奖励相关的价值的意外增加实际上会及时反向传播到tone。它之所以停止在这里仅仅是因为在预测未来回报的tone之前没有任何东西。如果在该tone之前有固定的灯光,则预测将反向传播到该较早的灯光。正是通过这种方式,TD使用刺激和经验奖励的方式来建立对未来奖励的期望。
Theory and Physiology of Dopamine
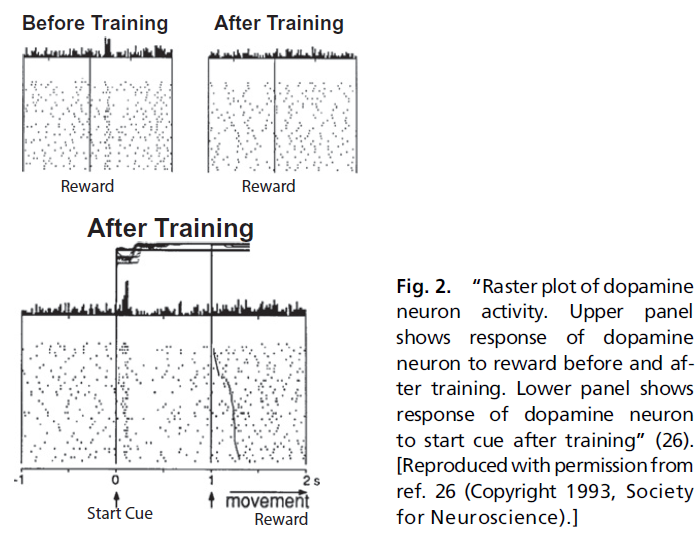
在了解多巴胺的解剖学和强化学习理论的基础上,考虑以下Schultz et al. (27)的经典实验。一只口渴的猴子坐在两个控制杆之前。猴子已经过训练,可以执行简单的指示选择任务。在中心位置的开始信号灯亮起后,猴子伸出手并按下左控制杆但不按下右控制杆,将获得苹果汁奖励。当动物反复执行此任务时,Schultz et al.(27)记录中脑多巴胺神经元的活动。有趣的是,在此过程的早期阶段,猴子的行为有些不规律,并且当出现开始信号时,神经元保持沉默,但每当猴子收到果汁奖励时,神经元就会做出强烈响应。但是,随着猴子继续执行任务,神经元的行为和活动都会系统地改变。猴子开始将选择集中在产生奖励的控制杆上,并且在这种情况下,神经元对果汁奖励的响应消失了。如图2所示。
然而,与此同时,每当开始信号灯被照亮时,神经元就开始响应。当Schultz et al.(27)首先观察到这些响应,他们假设“多巴胺神经元在学习和认知行为的注意力和动机的调节与脉冲活动的瞬时变化有关”(27)。
该报告发表后不久,Montague et al.(28, 29)开始研究参与学习的蜜蜂中章鱼胺神经元的活动。他们假设这些昆虫中这些多巴胺相关神经元的活动编码了某种奖励预测误差(28, 29)。当他们意识到Schultz et al.(27)的结果时,他们意识到这不仅是Bush和Mosteller(23, 24)类型的模型定义的奖励预测误差(RPE),而且还完全是TD类型的模型预测的RPE信号。回想一下,只要受试者的预期奖励发生变化,TD模型就会生成RPE。对于TD类型的模型,这意味着,在不可预测的视觉信号用于预测奖励之后,意外的视觉信号会告诉你世界比你预期的要好。此处的关键见解是,视觉信号之后动作电位的早期爆发是向Montague et al.(28,29)建议Schultz et al.(27)正在研究TD类型的系统的原因。
随后,这两个小组合作(26)检查了灵长类中脑多巴胺神经元的活动,该活动完全与Pavlov(22)最初研究的那种条件相同。在那个实验中,口渴的猴子在两种情况之一下安静地坐着。在第一种情况下,在无法预料的时间里向猴子的嘴里注入果汁。他们发现,在这些情况下,一旦注入了无法预料的果汁,神经元就会立即以一连串的动作电位来响应。在第二种情况下,同一只猴子一边坐着,一边施加视觉刺激,然后注入果汁。这是第一次发生在猴子身上,神经元的响应仍然像以前一样:在果汁注入后,神经元产生了一连串的动作电位,但在先前的视觉刺激后却保持沉默。但是,随着重复,发生了两件事。首先,神经元对果汁的响应强度不断下降,直到经过数十次试验后响应消失。其次,在完全相同的时间过程中,多巴胺神经元开始对视觉刺激作出响应。随着对奖励本身的响应减弱,对视觉刺激的响应也随之增加。他们观察到的是两类响应,一类是对奖励的响应,另一种是对tone的响应,但是这两种响应都是Montague et al.(28,29)一直在探索的TD模型所预测的。
Two Dopamine Responses and One Theory. 关于这一点,存在很多混淆,因此,我们暂停片刻以澄清这个重要问题。许多只熟悉Bush和Mosteller(23, 24)类型的模型(如Rescorla–Wagner模型)(25)的科学家查看了这些数据(或其他类似的数据),并被这两种不同的响应所打动——一个是奖励发放(仅在时间段开始时发生),另一个是仅发生在时间段后期的视觉信号。Bush和Mosteller(23, 24)算法仅预测与奖励本身同步的响应,因此,这些学者经常得出结论,多巴胺神经元在做两种不同的事情,其中只有一项是理论上可以预测的。但是,如果考虑TD类型的模型(在研究这些神经元之前已有十多年的定义),那么这种说法是错误的。Sutton和Barto(31)在1980年代初的见解是,强化学习系统应该在任何东西改变对即时奖励的期望时,使用奖励预测误差信号来驱动学习。在猴子得知某个tone表明即将获得奖励之后,那么在意外的时间听到该tone就如同一个意外的奖励本身一样,是一个正的奖励预测误差。这里的重点是,在上面描述的Schultz et al.(27,30)实验中观察到的早期和晚期爆发在TD类型的模型中实际上是一样的。这意味着在这些试验中无需假设多巴胺神经元在做两件事:它们似乎只是以理论上预测很好的方式编码了奖励预测误差。
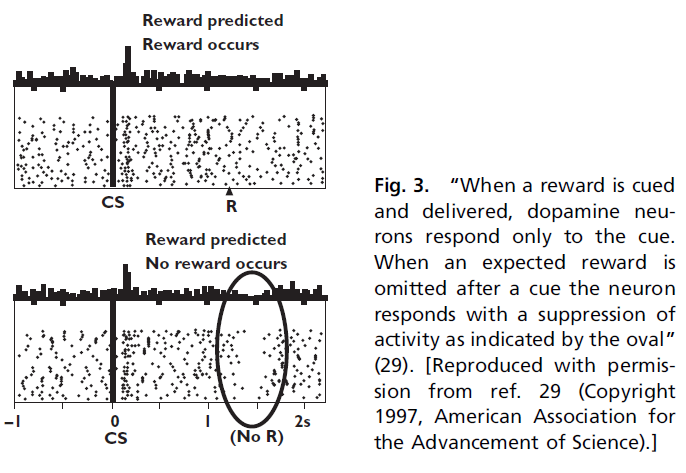
Negative Reward Prediction Errors. 在上述同一篇论文中,Schultz et al.(30)还研究了当期望的奖励被略去并且动物经历负的预测误差时会发生什么。为了检验这一点,首先对猴子进行了训练,使其在如上所述的视觉信号之后能够预期得到奖励,然后在罕见的试验中,它们只是在试验结束时就略去了水奖励。在这些条件下,Schultz et al.(30)发现神经元对被略去的奖励做出响应,其发放率从基准线下降(图3)。
Montague et al.(28, 29)意识到,从TD类型(在本例中为Bush和Mosteller(23, 24)类型)的观点来看,奖励预测误差是有道理的。在这种情况下,意外的视觉信号可以预测出奖励。神经元响应此预测误差而产生动作电位爆发。然后,略去了预期的奖励。这产生了负预测误差,并且实际上,神经元在略去的奖励之后做出响应,降低了发放率。但是,这种神经元响应的一个有趣的特征是神经元响应没有很大的降低。出现意外的奖励可能会将发放率从基准线(3-5Hz)提高到20或30Hz。略去相同的奖励会短暂地将发放率降低到0Hz,但是总频率仅降低3-5Hz。
如果假设在TD类型的模型中基准之上和之下的发放率与奖励预测误差线性相关,则必须得出结论,灵长类动物的估值受负预测误差的影响要小于正预测误差的影响, 但是我们知道,灵长类动物对低于预期的损失比对高于预期的收益更为敏感(32-35)。因此,Schultz(27, 30)发现正预测误差对多巴胺发放率的影响大于负预测误差,这表明该发放率与实际学习之间的关系在零点上是强非线性的,或者多巴胺与专门针对负分量的第二个系统协同编码正负预测误差。后者的可能性首先由Daw et al.(36)提出,他特别提出两个系统可以一起工作来编码预测误差,一个用于编码正误差,另一个用于编码负误差。
TD Models and Dopamine Firing Rates. 但是,TD类型的模型不止简单地预测,有些神经元必须对正预测误差做出正响应,而对负预测误差做出负响应。这些迭代计算还告诉我们这些神经元如何在其奖励预测中合并最近的奖励。系统通过计算来递归估计价值(等式6):
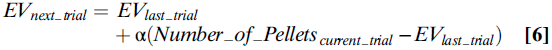
上式在数学上等同于说,使用等式(7)的指数加权函数对价值进行平均计算:
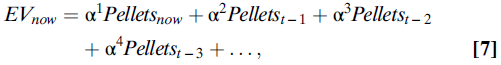
其中,α是学习率,是介于0和1之间的数字。例如,如果α的值为0.5,则(等式8):
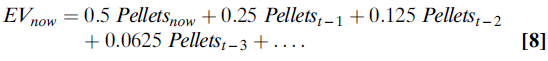
如果多巴胺神经元确实编码了RPE,则它们会编码预期和获得的奖励之差。在简单的条件或选择任务中,这意味着它们编码类似(等式9):
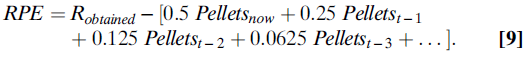
Sutton和Barto(26)提出的TD模型几乎没有告诉我们在任何特定条件下(这里,它被任意设置为0.5)应该取的α值,但是我们确实知道,权重衰减率对于任何固定环境,上述等式的括号部分应呈指数下降。我们还知道其他一些东西:当预期奖励等于获得奖励时,则预测误差应等于零。这意味着Robtained的实际价值应精确等于等式括号中的指数下降权重之和。
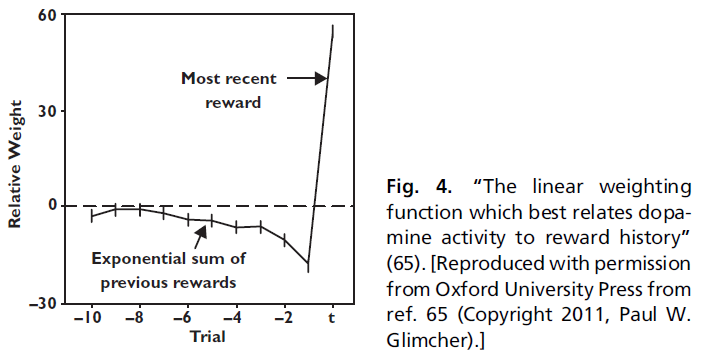
Bayer和Glimcher(37)通过记录猴子参与学习和选择任务时的多巴胺神经元记录了这些预测。在他们的实验中,猴子必须精确地计时,以便在试验中做出响应,以获得奖励。一个特定的响应时间将产生最大的奖励,但是最好的时间会在大型试验中意外地转移(具有近似平坦的风险函数)。在每次试验中,猴子都可以累积先前试验的信息来做出奖励预测。然后,猴子做出了动作并获得了奖励。两者之差应该是奖励预测误差,因此应与多巴胺的发放率相关。
为了检验该预测,Bayer和Glimcher(37)在给予猴子的奖励历史与多巴胺神经元的发放率之间进行了线性回归。线性回归确定加权函数,该函数以最能预测多巴胺发放率的方式结合有关这些先前奖励的信息。如果多巴胺神经元是一个迭代计算的奖励预测误差系统,则在当前试验中增加奖励会提高发放率。在此之前增加试验的奖励会降低发放率,并且权重呈指数下降。最后,回归应该表明旧权重的总和应等于当前奖励所对应的权重(符号相反)。实际上,这正是Bayer和Glimcher(37)发现的结果(图4)。
多巴胺发放率可以很好地描述为计算先前奖励的指数加权总和,然后从该价值中减去最近奖励的大小。此外,他们发现,正如预测的那样,指数权重下降的积分等于归因于最近奖励的权重。重要的是要注意,回归并不需要任何方式。该分析可能会得出任何可能的加权函数,但是观察到的加权函数正是TD模型所预测的。
然而,Bayer和Glimcher(37)所做的第二个观察是,正负预测误差(与奖励相对)的加权函数完全不同。相对而言,多巴胺神经元似乎对负预测误差不敏感。虽然Bayer et al.(15)后来证明,由于具有足够复杂的非线性,可以从多巴胺发放率中提取正负奖励预测误差,它们的数据再次提高了负预测误差可能与另一个未识别系统一起编码的可能性。
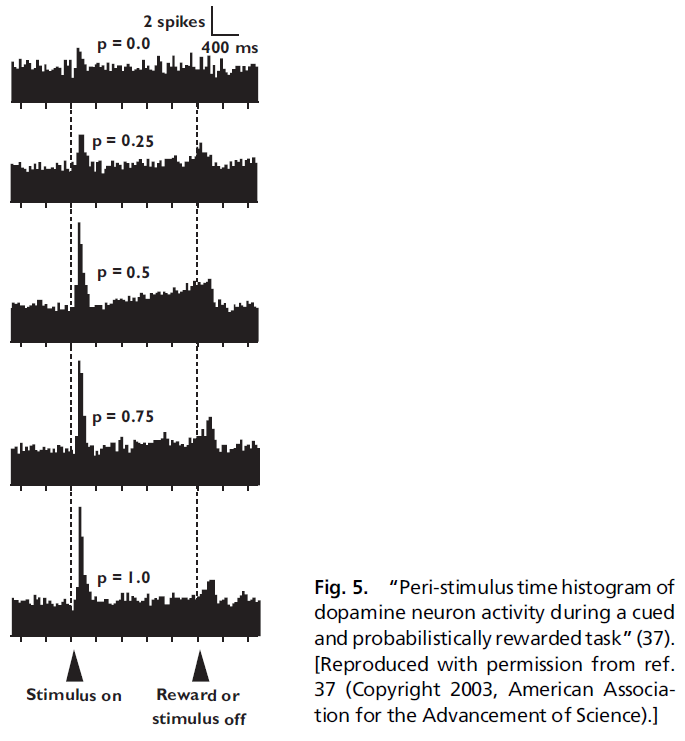
Dopamine Neurons and Probability of Reward. 根据这些观察,Schultz et al.(27, 30)观察到TD模型很好地描述了多巴胺神经元的另一个有趣特征。在广泛阅读的论文中,Fiorillo et al.(38)表明,经典调节任务中的多巴胺神经元似乎在信号和奖励之间的活动呈斜坡状,只要奖励是概率发放的,如图5所示。
回想一下,TD类型的模型实质上是将奖励的责任及时地反向传播。这就是对意外奖励的响应通过时间改变附加到预测那些较晚奖励的早期刺激上。当然,该理论预测正负预测误差都应以相同的方式及时反向传播。
现在,考虑到这一点,请考虑当猴子看到视觉信号并在tone的1s后以0.5的概率获得1mL水奖励时发生的情况。因此,tone的均值为0.5mL。在所有试验的一半中,猴子得到奖励(正预测误差为0.5)。在所有试验的另一半中,猴子没有得到奖励(负预测误差为0.5)。可以想象这两个信号会在试验时间内向视觉信号的方向反传。在许多试验中取均值,可以期望看到这两个传播信号相互抵消。但是,如果多巴胺神经元对正预测误差的响应比负预测误差强(37),会发生什么?在这种情况下,TD类型的模型将预测:平均多巴胺能活动将显示出更大的正预测误差以斜坡的形式在时间上反向传播,这正是Schultz et al.(27, 30)观察到的。
对斜坡的这种观察引起了很大争议,并引起了很多混淆。Schultz et al.(27, 30)对斜坡谈了两件事:斜坡的大小和形状带有关于先前奖励历史的信息,这是一个特征,表明神经元以一种理论上无法预测的方式编码不确定性。这些观察中的第一个无疑是正确的。仅当我们假设正负预测误差被编码为彼此的精确镜像时,第二种情况才成立。取而代之的是,如Bayer和Glimcher(37)的数据所示,在多巴胺神经元中对正负预测误差进行差分编码,则不止需要根据现有理论来预测斜坡。这是Niv et al.(39)首先提出的观点。
Axiomatic Approaches. 我们如何确定多巴胺神经元编码奖励预测误差?当然,在各种条件下,多巴胺神经元的平均发放率符合TD模型的预测,但是正如TD类型取代了Bush和Mosteller(23, 24)类型一样,我们有充分的理由相信未来的模型将改善TD的预测。因此,有没有一种方法可以说得出结论,多巴胺神经元的活动符合强化学习的必要性和充分性的某些绝对标准?为了开始回答这个问题,Caplin和Dean(40)使用了一套标准的经济工具来研究多巴胺。Caplin和Dean(40)询问是否存在一种紧凑的,可测试的,数学公理的方法来陈述当前的多巴胺假设。
经过仔细研究,Caplin和Dean(40)能够证明,整个基于奖励预测误差的模型可以简化为三个紧凑且可测试的数学表达式,称为公理——这是所有基于奖励预测误差的模型都必须具备的通用数学特征,包括它们的特定功能:
- 一致奖金次序。当获得特定奖励的概率固定并且这些奖励的大小不同时,无论获得奖励的环境条件如何,通过神经活动获得的奖励结果的次序(例如,该奖励会产生更多的活动,而不管有多少活动)必须相同。
- 一致彩票次序。当奖励固定且获得特定奖励的概率不同时,对于在给定概率集合下可能发生的所有奖励结果,按神经活动进行奖励的次序(例如,奖励结果产生更多的活动)应该相同。
- 无惊奇等价。Caplin和Dean(41)确定的必要性和充分性的最终标准是,RPE信号必须对所有完全预测的结果(无论好坏)做出相同的响应,在这种情况下奖励预测误差为零。
Caplin和Dean(40, 41)指出,任何RPE系统,无论是Bush和Mosteller(23, 24)类型还是TD类型的模型,都必须满足这三个公理标准。他们表明,说一个观察到的系统违反了这些公理中的一个或多个,就等于说它在原则上不能用作奖励预测误差系统。相反,他们表明,对于任何遵循这三个规则的系统,无疑可以使用奖励预测误差模型类别的至少一个成员来准确地描述神经元活动。因此,Caplin和Dean(40, 41)对所有RPE模型的类别进行公理化的重要意义在于,它提供了一种清晰的方法来检验整个假设类别。
在随后的实验中,Caplin et al.(42)通过建立一套货币彩票并让人类受试者以真实货币来玩彩票,对接受强多巴胺能输入的区域的大脑激活(用功能性MRI测量)的公理进行了实证测试。在那些实验中,受试者在每次试验中赢取或输掉5美元,并且系统地操纵了获胜或失败的概率。公理表明,在这些条件下,对于奖励预测误差编码系统,将发生三件事:
- 赢取$5一定要比输掉$5带来更多的活动,而不管概率是多少(根据一致奖金次序)。
- 越确定你会获胜,获胜的神经激活就必须越低,反之,越确定你会失败,失败的活动就必须越高(根据一致彩票次序)。
- 如果你确定结果是获胜还是失败,无论你是赢取还是输掉5美元,神经活动应该是相同的(根据无惊奇等价)。
他们发现,脑岛的激活违反了奖励预测误差理论的前两个公理。这明确表明,在他们研究的条件下,脑岛内血氧水平依赖性(BOLD)活动原则上不能作为学习的RPE信号。相反,腹侧纹状体的活动服从所有三个公理,因此满足用作RPE系统的必要性和充分性的标准。最后,内侧前额叶皮层和杏仁核的活动产生了中间结果。这些区域的激活似乎微弱地违反了其中一项公理,从而提出了这样一种可能性,即未来的这些领域的理论必须考虑到,RPE要么不存在,要么只是激活模式的一部分。
Caplin et al.(42)的论文很重要,因为从实际意义上讲,它是多巴胺激活的某些区域(尤其是腹侧纹状体)可以用作TD模型所假定类型的奖励预测误差编码器的最终证明。现在可以完全驳回有关这种激活仅看起来像RPE信号的说法。腹侧纹状体显示的活动模式对于RPE系统而言既必要又充分。这并不意味着它必须是这样一个系统,而是使我们越来越接近该结论。
Cellular Mechanisms of Reinforcement Learning
在1940年代和1950年代,Hebb(43)率先提出基于突触强度的局部激活模式的改变可能有助于解释条件反射在生物物理水平上的作用。当他们在兔子海马体中显示出长期增强作用(LTP)时,Bliss和Lomo(44)成功地将这两套概念联系起来。随后的生物物理研究表明,改变突触强度的其他几种机制与Hebb的理论建议(43)以及Bliss和Lomo的生物物理机制(44)都密切相关。Wickens(45)以及Wickens和Kotter(46)在我们的讨论中提出了最相关的建议,这通常被称为三因素规则。Wickens(45)以及Wickens和Kotter(46)提出的是,每当突触前和突触后活动与多巴胺同时发生时,突触就会增强,而在没有多巴胺的情况下发生突触前和突触后活动时,这些相同的突触也会减弱。确实,目前在生物物理水平上对多巴胺可以改变突触强度的许多步骤的理解不断增加(47)。
为什么这对于强化学习模型很重要?动物遇到较大的正奖励预测误差:他刚刚获得了意外的奖励。TD模型告诉我们,在这种情况下,我们希望增加归因于刚刚发生的所有动作或感觉的价值。在这种情况下,我们知道多巴胺神经元在整个额叶-基底神经节环中释放多巴胺,并且以高度同质的方式释放多巴胺。三因素规则意味着,任何因参与多巴胺受体而活跃的神经元(例如,移动操纵杆)都会使其主动突触增强。 因此,只要出现正预测误差并且多巴胺在额叶皮质和基底神经节中释放,则额叶-基底神经节环中任何已经活跃的部分的突触都会增强。
要了解这在行为中如何发挥作用,请考虑背侧纹状体的神经元形成进入人外空间的所有可能运动的映射。每次我们进行这些运动之一时,与该运动相关的神经元都会在短时间内活动,并且该运动在运动完成后仍会持续(48, 49)。如果有任何运动后出现正预测误差,则整个地形图将暂时嵌入多巴胺携带到该区域的全局预测误差信号中。这些事件的组合会产生什么?仅在那些与最近产生的运动相关的神经元中,它将使突触强度永久增加。反复暴露于多巴胺后,该突触将编码什么?它将对运动的期望值(或更准确地说,是主观期望值)进行编码。
这里要理解的关键是,基本上这个故事中的所有内容都是对神经系统特性的预先观察。我们知道,纹状体中的神经元按照TD模型(的资格迹)的要求在运动后是活跃的。我们知道,整个额皮质-基底神经节循环都会传播一揽子多巴胺能预测误差。我们知道,多巴胺与基础活动相关时会在这些区域产生类似LTP的现象。实际上,我们甚至知道,经过调节后,在这些区域中由突触驱动的动作电位率会编码动作的主观价值(48-51)。因此,所有这些生物物理组件都存在,并且它们以可以实现TD类型的学习模型的配置形式存在。
我们甚至可以开始看到如何产生由多巴胺神经元编码的预测误差信号。我们知道,纹状体中的神经元以其发放率编码学习到的动作价值。我们知道,这些神经元将输出发送到多巴胺能核——奖励预测。我们还知道,多巴胺能神经元从感觉区域接收到相当直接的输入,这些感觉区域可以检测并编码消耗的奖励的大小。例如,由舌头编码的糖溶液的特性具有几乎直接的途径,这些信号可以通过这些途径到达多巴胺能核。假设这是真的,在多巴胺神经元处构建预测误差信号,仅需要兴奋性和抑制性突触考虑多巴胺神经元本身或它们的直接前因的预测与实际奖励之差。
Summary and Conclusion
多巴胺奖励预测误差模型的基本大纲似乎与生物学水平和行为数据都非常吻合。这个假设似乎以简洁的方式很好地描述了各种各样的行为和生理现象。此方法的目的是传达该对齐方式的关键特征,该特征已通过严格的计算理论进行了调解。重要的是要注意,但是,确实有许多观察结果对现有的多巴胺奖励预测误差模型提出了关键挑战。这些挑战中的大多数都在Dayan和Niv(52)中进行了综述。(*)确实,奖励预测误差假设几乎完全集中在多巴胺神经元的相位响应上。毫无疑问,这些神经元的tonic活动也是重要的临床和生理特征(55),刚刚开始受到计算机的重视(56, 57)。
Matsumoto和Hikosaka(58)的工作提出了另一个值得特别关注的最新挑战,他们最近记录了SNc腹侧部分中明显没有编码奖励预测误差的神经元的存在。他们假设这些神经元形成了第二个生理上不同的多巴胺神经元群体,这些神经元扮演着某些替代的功能角色。尽管尚未确定这些神经元是否确实使用多巴胺作为其神经递质(这很困难)(11),但这一观察结果可能表明存在第二组多巴胺神经元,其活动超出了当前理论的范围。
以类似的方式,Ungless et al.(59)表明,在麻醉的啮齿动物中,VTA中的一些多巴胺神经元对厌恶刺激有正响应。当然,对于预测非常厌恶事件的动物,仅发生轻微厌恶事件将是正预测误差。尽管很难知道麻醉大鼠的神经系统会做出什么样的预测,但是观察到一些多巴胺神经元对厌恶刺激有响应,这对现有理论提出了另一个重要挑战,需要进一步研究。
尽管存在这些挑战,但多巴胺奖励预测误差已被证明非常可靠。Caplin et al.(42)从理论上证明,腹侧纹状体中与多巴胺相关的信号可以用这类模型准确地描述。Montague et al.(29)表明,TD类型(26)的模型很好地描述了多巴胺活动的广泛特征。像Bayer和Glimcher(37)所做的更详细的分析表明,多巴胺发放率与模型的关键结构特征之间存在定量一致性。在人类中的工作(60, 61)表明,该物种模型的一般特征也很好地说明了多巴胺能靶区域的活动。在大鼠身上的类似研究也揭示了在该物种的中脑多巴胺神经元中存在类似奖励预测误差的信号(62)。此外,现在也已经确定了大型强化学习回路的许多组成部分,其中多巴胺神经元据认为已嵌入其中(48-51, 63-65)。尽管使用新数据在将来的某个时刻发现现有的科学模型总是不正确的,但毫无疑问,多巴胺神经元的定量和计算研究是当代综合神经科学的重要成就。
(*)重要的是要承认,这些神经元的功能存在其他观点。Berridge(53)认为,多巴胺神经元起着与此处所描述的被称为刺激显著性的神经元密切相关的作用。Redgrave和Gurney(54)认为多巴胺在与注意力有关的过程中起着核心作用。

