3. Pod详解
Pod的功能
首先我们知道,要想在Kubernetes中部署一个容器,我们必须将其封装到Pod中再进行部署。为什么Kubernetes不直接使用容器,非要引入Pod这样一个概念来对容器进行封装呢?原因看上去好像一句废话一下:容器满足不了Kubernetes的需求。其实Pod在容器之上做了一系列的功能,来满足Kubernetes的需求,主要有增强容器的功能,辅助调度和共享资源三个方面。
增强容器
Pod通过以下一些配置增强了容器的功能:
-
Labels and annotations:通过标签Pod可以很方便的与Kubernetes中的其他资源对象进行协作。通过annotations可以引进新特性或与第三方组件进行集成。
-
Restart policies:可以指定Pod 及容器的重启策略。
-
Probes:通过探测(启动探测、就绪探测、活动探测等)可以获取Pod中容器或应用的状态,进而实现Pod的自动扩容缩容、滚动更新,self-healing等高级调度功能。
-
Affinity and anti-affinity rules:通过亲和性和反亲和性规则可以影响Kubernetes在调度中的决策,从而影响Pod部署到哪个节点。
-
Termination control:通过Termination control,可以实现Pod中容器和应用的优雅关闭。
-
Security policies:通过安全策略能够实现一些安全功能。
-
Resource requests and limits:通过资源需求和限制相关的配置,能够分配和限制Pod能够使用的资源,如CPU/Memory等。
下图表明一个Pod可以封装一个或多个容器,并提供了更多的功能:
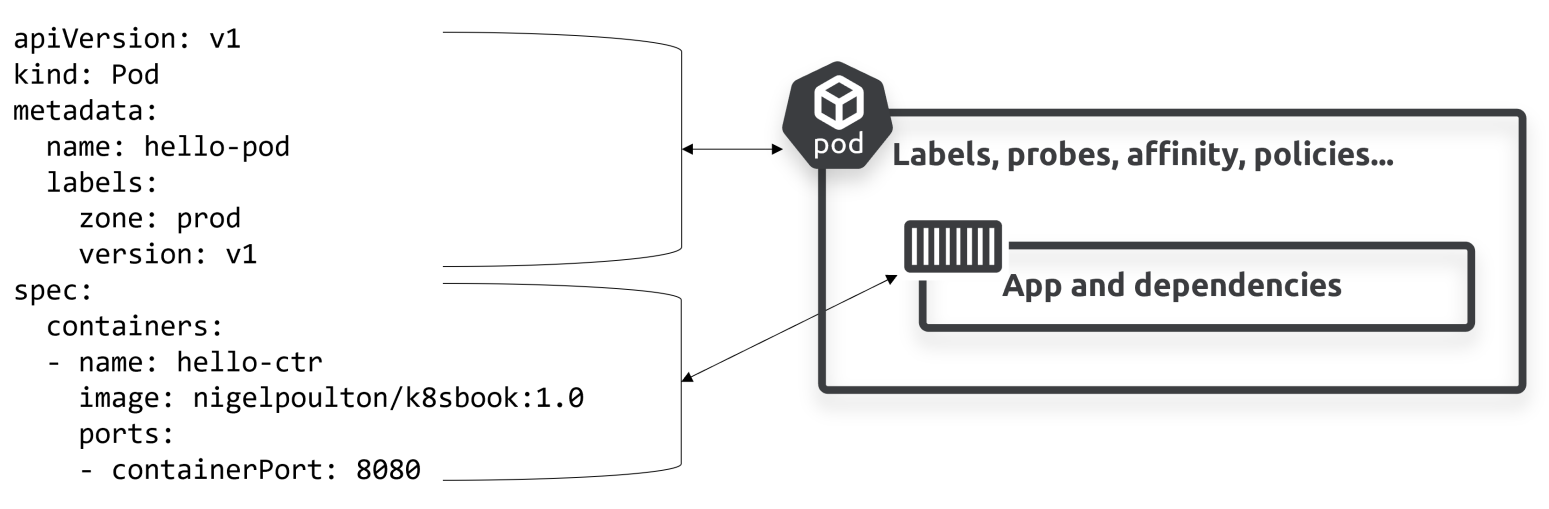
辅助调度
Pod是调度的基本单元。Kubernetes能够确保Pod中的容器和应用调度到同一个worker node上,这也就保证了Pod中的所有应用都在同一个机房的同一个Region和Zone。
上文提到的Labels,Affinity and anti-affinity rules和Resource requests and limits也能够让用户很细的粒度控制Kubernetes的调度。
资源共享
Pod能够为在它内部的所有容器提供统一的共享的运行时环境,包括:
- 共享的文件系统
- 共享的网络
- 共享的内存和存储
这意味着,Pod中的所有容器和应用共享一个IP地址,可以通过共享存储来同步文件或共享数据。
Pod的生命周期
当我们定义好一个Pod的YAML文件并提交给API Server后,API Server会先把这些配置信息存储到 Cluster store(etcd)中,这些信息可以称之为 Pod的 desired state. 配置信息保存好之后,API Server 通过 Scheduler 将Pod调度到一个worker node 上。一旦Pod被调度到worker node 上,Pod的状态就变为 pending状态。worker node 上的kubelet开始拉取镜像,启动Pod中的容器(这期间一直是pending状态),直到所有容器都启动成功,Pod则进入 running状态。一旦Pod中的所有容器都正常执行完毕,正常退出,Pod就进入success状态。如果Pod中的容器执行过程中发生了意外退出或者启动没有成功,Pod则进入failed状态。Pod的状态流转如下图所示:

Pod的部署
Pod可以通过kubelet客户端直接部署,也可以通过controller间接部署。
通过kubelet直接部署的Pod我们称之为static Pod.这类Pod不具备self-healing、自动扩容缩容及滚动更新等高级调度功能,因为这些功能是由controller提供的。static Pod是由kubelet客户端进行管理的,它只能够监控Pod, 如果Pod down掉,它只能在当前节点上对Pod进行简单的重启,不能向controller一样,将Pod调度到其他worker node上启动。
通过controller间接部署的Pod具有self-healing、自动扩容缩容及滚动更新等高级调度功能。当一个Pod节点挂掉后,controller检测到以后,会立即在其他的worker node上启动一个同样的Pod。理解这一点非常重要,这也是我们需要将 应用程序的状态信息保存到Pod外部的重要原因。
Controller的类型
kubernetes提供了多种controller。Deployments, StatefulSets 和 DaemonSets 适合long-lived Pods. Jobs and CronJobs适合short-lived Pods.
Multi-container Pod
Pod中可以有一个或者多个容器。当多个容器在同一个Pod中时,这些容器是以Pod为基本单元,作为一个整体进行管理的。特别是在横向扩展时,Pod中的容器会一起扩容。不过,一般情况下,我们不会将多个容器放到同一个Pod中,除非这些容器是紧密联系在一起的。当我们在设计微服务时,通常会使用单一职责原则或者关注点分离原则,应用这些原则使得我们的微服务功能简单、体积小、易于重用并且能过快速迭代。但有些服务或功能之间联系非常紧密,我们又希望他们能够部署在一个Pod中。将多个容器放到同一个Pod中,使得容器能够保持单一职责原则,并能够将多个联系紧密的容器放到一起管理。Kubernetes为我们预定义了一些多容器部署的模式:
- Sidecar Pattern 边车模式
- Adaptor Pattern 适配器模式
- Ambassador Pattern 外交官模式或代理模式
- Init Pattern 初始化模式
Pod原理
从原理上讲,Pod其实是一个逻辑概念,对应于Linux系统的Namespace和Cgroups. 每个Pod的内部都有一个infra容器,它使用特殊的镜像:k8s.gcr.io/pause,这是使用汇编写的永远处于'暂停'状态的容器。 从这个角度看,可以认为Pod是容器的容器.Pod中的容器共享Pod的系统资源,这些系统资源其实就是操作系统内核的namespace.这些namespace包括:
- net namespace: 包括 IP 地址,端口范围,路由表
- pid namespace: 隔离的进程树
- mnt namespace:文件系统及存储
- UTS namespace:主机名
- IPC namespace:Unix domain socket 和 共享内存
另一个方面,Pod使用操作系统的Control Groups 来管理CPU、内存及IOPS等资源。Pod可以指定自己的cgroups limits,每个容器也可以指定自己的cgroups limits,从而限制Pod和容器对资源的访问。
Pod与网络
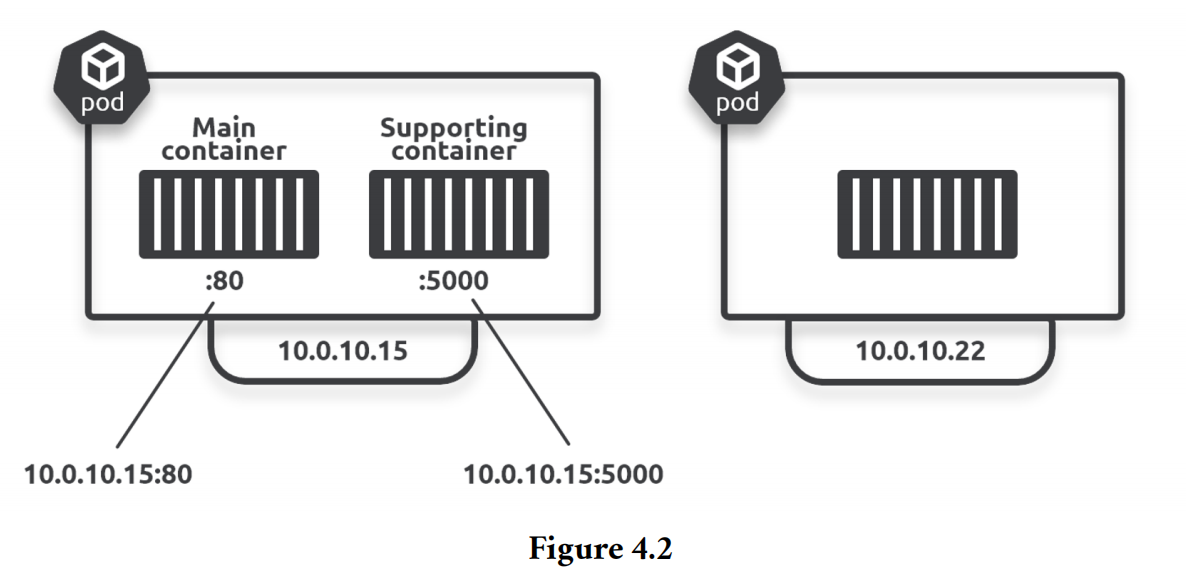
每一个Pod都有一个独立的network namespace. 这意味着每一个Pod都有独立的IP地址,端口号范围以及自己的路由表。如果Pod中有多个容器,这些容器共享这个Pod的IP地址,款口号范围及路由表。Pod内部的各个容器通过localhost即可互相访问,两个独立的Pod的相互访问则是通过Pod的IP地址实现。如下图:Main Container和Supporting Container之间可以通过localhost进行访问,右侧的Pod对左侧Pod中的容器的访问,则是通过左侧Pod的IP地址和其内部的容器的端口号进行访问。
kubernetes集群中有个虚拟网络,叫Pod network, 所有Pod的IP地址在Pod network中都是可达的。如下图所示,Pod network构建于物理网络之上:
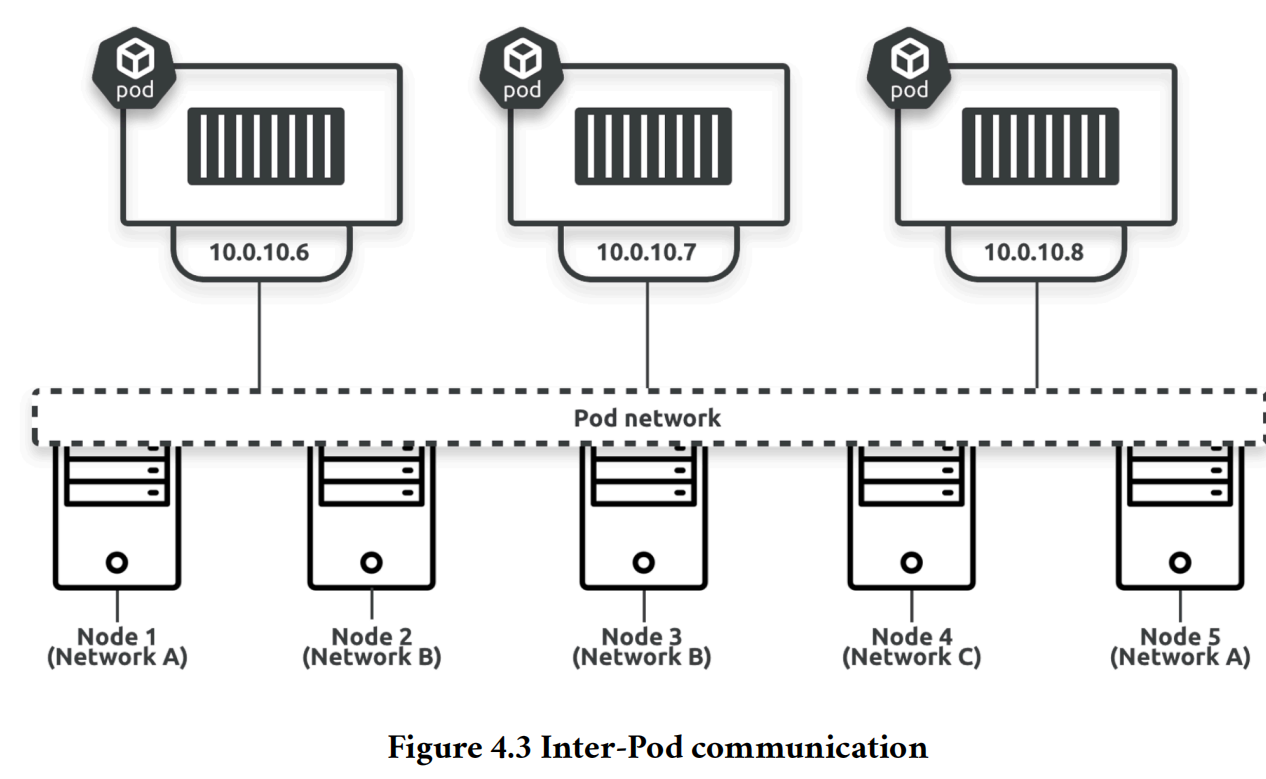
各个物理网络(A、B、C)之间通过路由器相连,可以互相访问,Pod 网络是构建在这几个物理网络之上的虚拟网络。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号