

1. 初识Kubernetes
What Is K8S
狭义上讲,K8S是一个应用编排器。绝大部分情况下,它被用于 编排 容器化 的云原生微服务应用。具体的,它可以实现:
- 自动化部署应用
- 按需对应用进行扩容或缩容
- 应用自愈(如果应用宕机,会自动重启)
- 实现应用不间断的滚动更新和回滚
- 。。。
名词解释:
容器化:容器化就是将应用或服务封装到容器中进行部署和执行。
云原生应用:开发出来的应用可以无缝的发布到Cloud上,能够使用云基础设施实现:自动化部署、按需缩容扩容、不间断滚动更新等功能,这类应用我们称之为云原生应用(Cloud Native APP)。
- 传统的操作系统比如Linux或Windows对硬件资源(CPU、内存、网络)等进行了抽象,并实现了对这些资源的统一调度和管理。Kubernetes 实现了云资源的统一抽象,并对云上的应用进行统一调度和管理。
- 传统操作系统对硬件进行了抽象,并屏蔽了这些硬件之间的差异,Kubernetes 屏蔽了Cloud的区别(各类公有云、私有云、混合云),可以无差别的对应用进行管理。
使用Kubernetes的开发步骤
- 编写微服务应用
- 将微服务应用打包为容器镜像
- 将容器镜像包装为Kubernetes Pod
- 将Pod部署到Kubernetes集群中
历史
2014年 Google的开发人员基于内部系统Borg和Omega的经验,重新设计和开发出了Kubernetes,并捐赠给CNCF(Cloud Native Computing Foundation)
2016年 Kubernetes 引入了container runtime interface (CRI) ,CRI使得容器运行时层变成了一个可插拔的组件。目前Kubernetes 使用containerd作为默认的容器运行时环境。containerd是由Docker捐赠给CNCF社区的 一个简化版的Docker,但是它实现了CRI,满足了Kubernetes的需求。
2017年Kubernetes 赢下了编排器之争,成为业界事实上的标准。
Kubernetes组成
Kubernetes包含两个部分:控制面(Control Plane)和工作节点(Worker nodes)。
Control Plane
控制面由运行在Kubernetes中的一个或几个节点构成,这些节点运行着一些重要的系统服务。这些系统服务包括:API Server 、Scheduler、Controllers和 Cluster store.
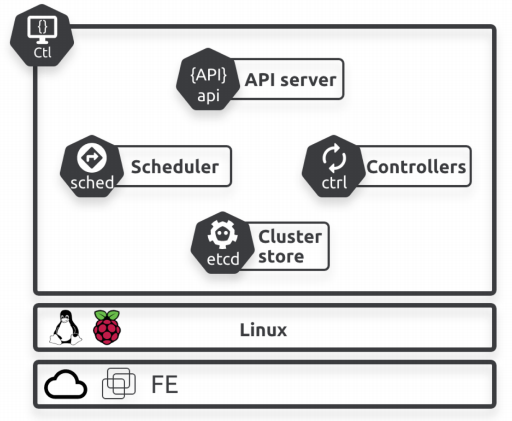
API Server: API Server可以说是Kubernetes的交流中心。所有组件(无论是内部组件还是外部组件)的交流,都必须通过API Server。它通过暴露 RESTful API接收请求来完成其功能。一般情况下,我们通过一个yaml文件(manifests)来描述我们应用的期望状态,比如:应用使用哪个容器镜像,暴露什么端口,需要多少个Pod副本等。然后将这个yaml文件通过指令发送给API Server,API Server对请求进行认证和授权,然后验证yaml内容的有效性,并把它存储到Cluster Store, 并把这些配置调度和应用到工作节点。
Cluster store:Cluster store 是Kubernetes控制面中唯一一个有状态的组件。它存储了所有的配置和整个Kubernetes集群的状态信息。当前Cluster store基于etcd实现,为了实现整个Kubernetes集群的高可用,一般建议至少部署3-5个etcd节点。此外,etcd是CP模型,意味着它不容忍脑裂,也就是说当etcd节点数据状态不一致时,它会停止更新。此时,etcd的集群的数据不会被更新,从而导致Kubernetes的整个集群状态不能更新。此时,Kubernetes的工作节点可以正常服务,但是Kubernetes集群状态将不能更新。
Controllers:Controllers负责持续监听API Server,一旦收到来自API Server的变更通知,它会立即做出响应。Controller的职测是确保集群的当前状态与期望状态一致,一旦不一致就会采取措施,使得集群状态达到期望状态。其执行过程如下:
- 从API Server处获取 集群的期望状态
- 监听集群的当前状态
- 找出期望状态与当前状态的不同
- 采取措施,使集群状态与期望状态一致
Controller有Deployment、DaemonSets and StatefulSets等几种类型,后续会一一介绍。
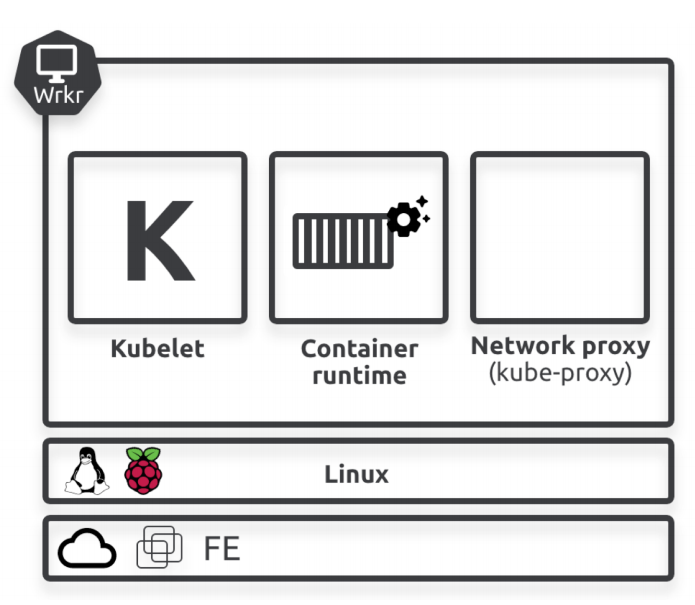
Worker nodes
- 监控API Server 获取分配到该节点的任务
- 执行分配的任务
- 将节点状态及任务的状态报告给Control Plane
Kubernetes DNS
Kubernetes集群内部同时存在着一个DNS服务,该DNS服务的静态IP地址通过硬编码的方式写入到每一个Pod中,这样就可以通过该DNS服务实现自动化的服务注册与发现。Kubernetes的DNS服务是通过CoreDNS实现的。
