

python基础之常用模块
一 time模块
时间表示形式:
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
(1)时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
(2)格式化的时间字符串(Format String):'1988-03-16'
(3)元组(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
# <1> 时间戳 import time print(time.time()) #--------------返回当前时间的时间戳 #1493194473.8422034 # <2> 时间字符串 print(time.strftime("%Y-%m-%d %X")) #2017-04-26 16:14:33 # <3> 时间元组 print(time.localtime()) #东八区时间。 print(time.gmtime()) #标准时间,格林威治时间。 #time.struct_time(tm_year=2017, tm_mon=4, tm_mday=26, tm_hour=16, tm_min=14, tm_sec=33, tm_wday=2, tm_yday=116, tm_isdst=0) #time.struct_time(tm_year=2017, tm_mon=4, tm_mday=26, tm_hour=8, tm_min=14, tm_sec=33, tm_wday=2, tm_yday=116, tm_isdst=0)
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
几种时间形式的转换:
(1)
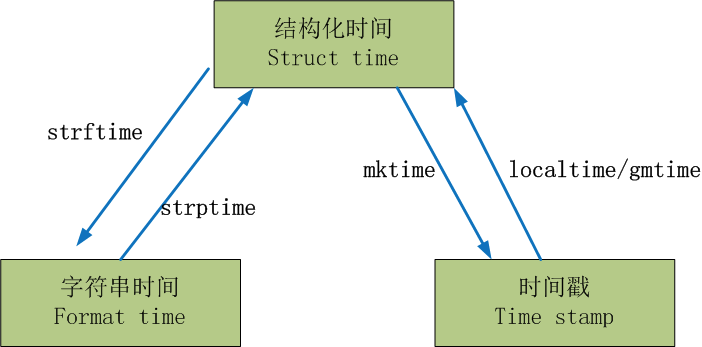
#一 时间戳<---->结构化时间: localtime/gmtime mktime print(time.localtime(3600*24)) print(time.gmtime(3600*24)) print(time.mktime(time.localtime())) #time.struct_time(tm_year=1970, tm_mon=1, tm_mday=2, tm_hour=8, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=2, tm_isdst=0) #time.struct_time(tm_year=1970, tm_mon=1, tm_mday=2, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=2, tm_isdst=0) #1493194973.0 #字符串时间<---->结构化时间: strftime/strptime print(time.strftime("%Y-%m-%d %X",time.localtime())) print(time.strptime("2017-03-16","%Y-%m-%d")) print(time.strftime("%Y-%m-%d",time.localtime(time.time()-24*3600))) #2017-04-26 16:22:53 #time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1) #2017-04-25
(2)

print(time.asctime(time.localtime(312343423))) #Sun Nov 25 10:03:43 1979 print(time.ctime(312343423)) #Sun Nov 25 10:03:43 1979
#--------------------------其他方法 # sleep(secs) # 线程推迟指定的时间运行,单位为秒。
二、random模块
import random print(random.random()) # 大于0且小于1之间的小数 # 0.8871504125977017 print(random.randint(1,5)) # 大于等于1且小于等于5之间的整数 # 2 print(random.randrange(1,3)) # 大于等于1且小于3之间的整数 # 1 print(random.choice([1,'23',[4,5]])) # #1或者23或者[4,5] (choice 选择) # [4, 5] print(random.sample([1,'23',[4,5]],2)) #列表元素任意2个组合 (sample 取样) # [[4, 5], '23'] print(random.uniform(1,3)) #大于1小于3的小数 (uniform 统一的) # 2.407927435974846 item=[1,3,5,7,9] random.shuffle(item) # 打乱次序 (shuffle 洗牌) print(item) random.shuffle(item) print(item)
练习:生产验证码 (validate 验证)


def validate(): s = '' for i in range(5): num=random.randint(0,9) Alf=chr(random.randint(65,90)) #A-Z alf=chr(random.randint(97,122)) #a-z ret=random.choice([str(num),Alf,alf]) s="".join([s,ret]) #和下面的字符相加结果一样 # s+=ret return s print(validate())
三、hashlib
算法介绍:
python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib md5 = hashlib.md5() md5.update('how to use md5 in python hashlib?') print(md5.hexdigest()) 计算结果如下: d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
md5 = hashlib.md5() md5.update('how to use md5 in ') md5.update('python hashlib?') print(md5.hexdigest())
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib sha1 = hashlib.sha1() sha1.update('how to use sha1 in ') sha1.update('python hashlib?') print sha1.hexdigest()
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
摘要算法应用:
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
name | password --------+---------- michael | 123456 bob | abc999 alice | alice2008
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
username | password ---------+--------------------------------- michael | e10adc3949ba59abbe56e057f20f883e bob | 878ef96e86145580c38c87f0410ad153 alice | 99b1c2188db85afee403b1536010c2c9
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
'e10adc3949ba59abbe56e057f20f883e': '123456' '21218cca77804d2ba1922c33e0151105': '888888' '5f4dcc3b5aa765d61d8327deb882cf99': 'password'
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
hashlib.md5("salt".encode("utf8"))
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
注:Ftp中传文件用得校验机制就是hashlib的update原理,传一行校验一次。
import hashlib m =hashlib.md5() l =hashlib.md5() m.update("37142343".encode("utf8")) l.update("37142343".encode("utf8")) print(m.hexdigest()) print(l.hexdigest()) m=hashlib.md5() m.update("luchuan".encode("utf8")) print(m.hexdigest()) #luchuan m.update("luchuan".encode("utf8")) #上面校验的是:luchuanluchuan,之前做过update,之后的update值会相加到一起校验 print(m.hexdigest()) #加盐 n = hashlib.md5("salt".encode('utf8')) n.update(b"luchuan") print(n.hexdigest())
四、os模块
os模块是与操作系统交互的一个接口
''' os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小 '''
import os print(os.getcwd()) #获取当前目录 f=open("test.txt","w") os.chdir(r"C:\Users\Administrator\PycharmProjects\untitled\day32") #切换当前目录 print(os.getcwd()) #获取当前目录 f=open("test2.txt","w") #创建文件 print(os.getcwd()) #获取当前目录 print(os.curdir) #获取当前目录. print(os.pardir) #获取当前目录的父目录 os.makedirs("aaa/bbb") #可生成多层递归目录 os.removedirs("aaa/bbb") #若目录为空,可递归删除目录 print(os.listdir(r"C:\Users\Administrator\PycharmProjects\untitled\day31")) 列出指定目录下的所有文件和子目录 print(os.stat(r"C:\Users\Administrator\PycharmProjects\untitled\day32\b.txt")) 获取文件或目录信息 print("yuan"+os.sep+"image") #指定操作系统的路径分隔符,使程序可跨平台执行 print(os.pathsep) #输出用于分割文件路径的字符串 print(os.name) #输出字符串指示当前使用平台 print(os.system("dir")) #运行命令 print(os.environ) #获取系统环境变量 print(os.path.abspath("test.txt")) #返回path规范化的绝对路径 abs=os.path.abspath("test.txt") print(os.path.basename(abs)) #返回path最后的文件名 print(os.path.dirname(abs)) #返回path的目录 print(os.path.exists("test.txt")) #如果path存在,返回True,否则返回False print(os.path.isfile("test.txt")) #如果path是一个存在的文件,返回True,否则返回False s1=r"C:\Users\Administrator\PycharmProjects\untitled" # r 表示原生字符 s2=r"练习\test.txt" print(s1+os.sep+s2) ret=os.path.join(s1,s2) print(ret) print(os.path.getatime('test.txt')) print(os.path.getmtime('test.txt')) print(os.path.getsize('test.txt'))
五、sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.argv应用:
C:\Users\Administrator\PycharmProjects\untitled\day33>python test.py luchuan 123 ['test.py', 'luchuan', '123'] luchuan 123 ['C:\\Users\\Administrator\\PycharmProjects\\untitled\\day33', 'C:\\Python36\\py thon36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib', 'C:\\Python36', 'C:\\Pyt hon36\\lib\\site-packages']
print(sys.argv) username=sys.argv[1] password=sys.argv[2] print(username) print(password) print(sys.path)
六、logging模块
区别:1、config不能打印到屏幕上 2、logger对象的方式
1、函数式简单配置
import logging logging.debug('debug message') logging.info('info message') logging.warning('warning message') logging.error('error message') logging.critical('critical message')
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
critical : 危险性的
灵活配置日志级别,日志格式,输出位置:
import logging logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', datefmt='%a, %d %b %Y %H:%M:%S', filename='/tmp/test.log', filemode='w') logging.debug('debug message') logging.info('info message') logging.warning('warning message') logging.error('error message') logging.critical('critical message')
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
2、logger对象配置
import logging logger = logging.getLogger() # 创建一个handler,用于写入日志文件 fh = logging.FileHandler('test.log') # 再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) #logger对象可以添加多个fh和ch对象 logger.addHandler(ch) logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message')
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别。
def get_logger(): logger=logging.getLogger() fh=logging.FileHandler("logger2") # 创建一个handler,用于写入日志文件 sh=logging.StreamHandler() # 再创建一个handler,用于输出到控制台 logger.setLevel(logging.DEBUG) fm = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 格式化输出 logger.addHandler(fh) #logger对象可以添加多个fh和ch对象 logger.addHandler(sh) fh.setFormatter(fm) sh.setFormatter(fm) return logger Logger=get_logger() Logger.debug('logger debug message') Logger.info('logger info message') Logger.warning('logger warning message') Logger.error('logger error message') Logger.critical('logger critical 中文')
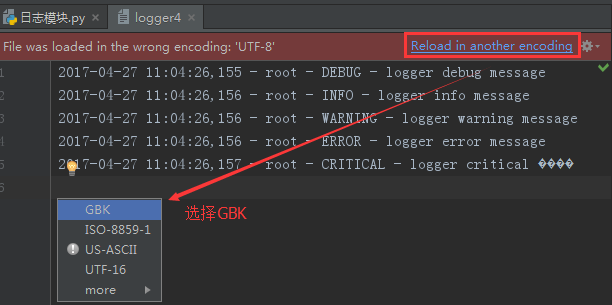
注意:如果输入到文件里有中文字符,需要如下操作:
七、序列号模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
d={"河北":["邯郸","雄安"]}
s=str(d)
print(s)
print(type(s))
with open("data","w") as f:
f.write(s)
with open("data") as f2:
s2=f2.read()
d2=eval(s2)
print(d2["河北"])
#计算
print(eval("12*7+5-3"))
什么是序列化:
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json:
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象一个子集,JSON和Python内置的数据类型对应如下:

import json i=10 s='hello' t=(1,4,6) l=[3,5,7] d={'name':"luchuan"} json_str1=json.dumps(i) json_str2=json.dumps(s) json_str3=json.dumps(t) json_str4=json.dumps(l) json_str5=json.dumps(d) print(json_str1) #'10' print(json_str2) #'"hello"' print(json_str3) #'[1, 4, 6]' print(json_str4) #'[3, 5, 7]' print(json_str5) #'{"name": "luchuan"}'
python在文本中的使用:
#----------------序列化 import json d={'name':"egon"} print(type(d)) #<class'dict'> s=json.dumps(d) #将字典d转为json字符串 print(s) print(type(s)) #<class'str'> f=open("new",'w') f.write(s) #-------------等价于json.dump(s,f) f.close() #----------------反序列化 import json f=open("new") data=f.read() data2=json.loads(data) #等价于data2=json.load(f) print(data2["name"]) #-----------------dump方式 d={'name':"luchuan"} f=open("new2",'w') json.dump(d,f) #------1、转成字符串 2、将json字符串写入f文件 f.close()
import json f=open("new3") data=f.read() #如果文件中是双引号则可以使用打印出来,单引号则不可以,json不认识单引号 #只要是满足json字符串格式得,不管是从文件中读取得还是字符串都可以直接loads #{'info':{"name":"yuan","age":24}} #会报错,不可以 #{"info":{"name":"yuan","age":24}} #满足json字符串的规则 ret=json.loads(data) print(ret["info"])
pickle:
import pickle #--------------------序列化 d={"name":"alvin"} print(type(d)) #<class'dict'> s=pickle.dumps(d) print(s) print(type(s)) #<class'bytes'> f=open("new5","wb") #注意是w是写入str,wb是写入bytes,j是'bytes' f.write(s) #-------------等价于pickle.dump(d,f) f.close() #------------------反序列 import pickle f=open("new5","rb") data=pickle.loads(f.read()) #等价于data=pickle.load(f) print(data["name"])
补充:
import pickle import json import datetime # t=datetime.datetime.now() #时间是数字类型,不能做转换 # d={"data":t} # json.dump(d,open("new4","w")) t=datetime.datetime.now() #时间是数字类型,不能做转换 d={"data":t} pickle.dump(d,open("new4","w"))
json和pickle的区别:
......
八、subprocess模块
subprocess 模块允许您生成新进程,连接到其输入/输出/错误管道,并获取其返回码。
>>> import subprocess >>> res=subprocess.Popen('dir',shell=True,stdout=subprocess.PIPE) >>> res.stdout.read().decode('gbk') >>> res=subprocess.Popen('diraaaa',shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE) >>> res.stderr.read().decode('gbk') "'diraaaa' 不是内部或外部命令,也不是可运行的程序\r\n或批处理文件。\r\n" #第一个参数是命令,第二个参数是以shell方式运行,第三个参数是标准输出,第四个参数是标准错误输出
传统Shell调用函数:
这些操作提供隐式调用系统shell。
subprocess.getstatusoutput(cmd),返回在shell中执行 cmd 的(status, output)。
>>> subprocess.getstatusoutput('ls /bin/ls') (0, '/bin/ls') >>> subprocess.getstatusoutput('cat /bin/junk') (256, 'cat: /bin/junk: No such file or directory') >>> subprocess.getstatusoutput('/bin/junk') (256, 'sh: /bin/junk: not found')
subprocess.getoutput(cmd),返回在shell中执行 cmd 的输出(stdout和stderr)。
像 getstatusoutput(),除了退出状态被忽略,返回值是一个包含命令输出的字符串。
>>> subprocess.getoutput('ls /bin/ls') '/bin/ls'
九、paramiko模块
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内部的远程管理就是使用的paramiko来现实。
1、下载安装
pip3 install paramiko
或
# pycrypto,由于 paramiko 模块内部依赖pycrypto,所以先下载安装pycrypto # 下载安装 pycrypto wget https://files.cnblogs.com/files/wupeiqi/pycrypto-2.6.1.tar.gz tar -xvf pycrypto-2.6.1.tar.gz cd pycrypto-2.6.1 python setup.py build python setup.py install # 进入python环境,导入Crypto检查是否安装成功 # 下载安装 paramiko wget https://files.cnblogs.com/files/wupeiqi/paramiko-1.10.1.tar.gz tar -xvf paramiko-1.10.1.tar.gz cd paramiko-1.10.1 python setup.py build python setup.py install # 进入python环境,导入paramiko检查是否安装成功
2、使用模块
#!/usr/bin/env python #coding:utf-8 import paramiko ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('192.168.1.108', 22, 'alex', '123') stdin, stdout, stderr = ssh.exec_command('df') print stdout.read() ssh.close();
import paramiko private_key_path = '/home/auto/.ssh/id_rsa' key = paramiko.RSAKey.from_private_key_file(private_key_path) ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('主机名 ', 端口, '用户名', key) stdin, stdout, stderr = ssh.exec_command('df') print stdout.read() ssh.close()
import os,sys import paramiko t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',password='123') sftp = paramiko.SFTPClient.from_transport(t) sftp.put('/tmp/test.py','/tmp/test.py') t.close() import os,sys import paramiko t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',password='123') sftp = paramiko.SFTPClient.from_transport(t) sftp.get('/tmp/test.py','/tmp/test2.py') t.close()
import paramiko pravie_key_path = '/home/auto/.ssh/id_rsa' key = paramiko.RSAKey.from_private_key_file(pravie_key_path) t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',pkey=key) sftp = paramiko.SFTPClient.from_transport(t) sftp.put('/tmp/test3.py','/tmp/test3.py') t.close() import paramiko pravie_key_path = '/home/auto/.ssh/id_rsa' key = paramiko.RSAKey.from_private_key_file(pravie_key_path) t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',pkey=key) sftp = paramiko.SFTPClient.from_transport(t) sftp.get('/tmp/test3.py','/tmp/test4.py') t.close()
