




一、大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
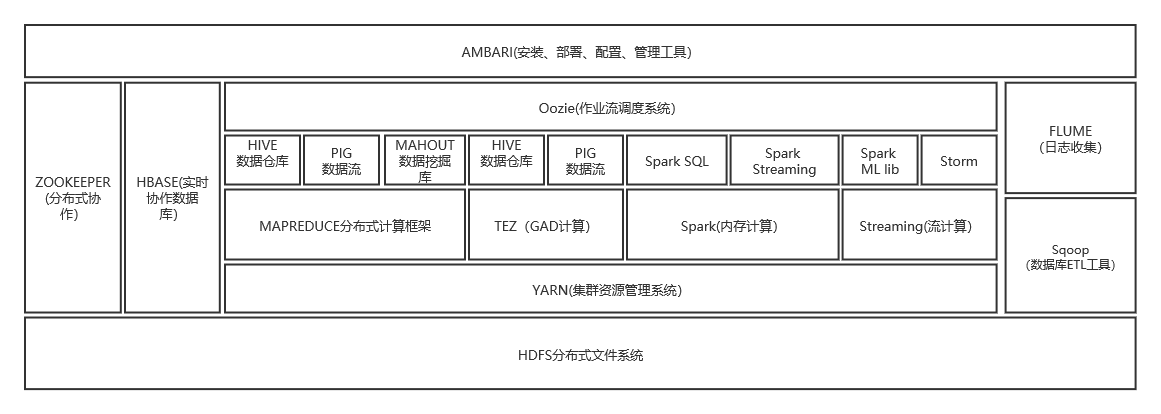
(1)HDFS(hadoop分布式文件系统)
是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。
- client:切分文件,访问HDFS,与namenode交互,获取文件位置信息,与DataNode交互,读取和写入数据。
- namenode:master节点,在hadoop1.x中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户 端请求。
- DataNode:slave节点,存储实际的数据,汇报存储信息给namenode。
- secondary namenode:辅助namenode,分担其工作量:定期合并fsimage和fsedits,推送给namenode;紧急情况下和辅助恢复namenode,但其并非namenode的热备。
(2)mapreduce(分布式计算框架)
mapreduce是一种计算模型,用于处理大数据量的计算。其中map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
- jobtracker:master节点,只有一个,管理所有作业,任务/作业的监控,错误处理等,将任务分解成一系列任务,并分派给tasktracker。
- tacktracker:slave节点,运行 map task和reducetask;并与jobtracker交互,汇报任务状态。
- map task:解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入到本地磁盘(如果为map—only作业,则直接写入HDFS)。
- reduce task:从map 它深刻地执行结果中,远程读取输入数据,对数据进行排序,将数据分组传递给用户编写的reduce函数执行。
(3)hive(基于hadoop的数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
(4)hbase(分布式列存数据库)
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。和传统关系型数据库不同,hbase采用了bigtable的数据模型:增强了稀疏排序映射表(key/value)。其中,键由行关键字,列关键字和时间戳构成,hbase提供了对大规模数据的随机,实时读写访问,同时,hbase中保存的数据可以使用mapreduce来处理,它将数据存储和并行计算完美结合在一起。
HBase中的存储包括HMaster、HRegionSever、HRegion、HLog、Store、MemStore、StoreFile、HFile等。
HBase中的每张表都通过键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
(5)zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
(6)sqoop(数据同步工具)
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
- sqoop1 import原理:从传统数据库获取元数据信息(schema、table、field、field type),把导入功能转换为只有Map的Mapreduce作业,在mapreduce中有很多map,每个map读一片数据,进而并行的完成数据的拷贝。
- sqoop1 export原理:获取导出表的schema、meta信息,和Hadoop中的字段match;多个map only作业同时运行,完成hdfs中数据导出到关系型数据库中。
(7)pig(基于hadoop的数据流系统)
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。通常用于离线分析。
(8)mahout(数据挖掘算法库)
mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。mahout现在已经包含了聚类,分类,推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法是,mahout还包含了数据的输入/输出工具,与其他存储系统(如数据库,mongoDB或Cassandra)集成等数据挖掘支持架构。
(9)flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
(10)Spark
Spark 是专为大规模数据处理而设计的快速通用的计算引擎,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
(11)资源管理器(YARN和mesos)
随着互联网的高速发展,基于数据 密集型应用 的计算框架不断出现,从支持离线处理的mapreduce,到支持在线处理的storm,从迭代式计算框架到 流式处理框架s4,...,在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方法如下:网页建索引采用mapreduce框架,自然语言处理/数据挖掘采用spark,对性能要求到的数据挖掘算法用mpi等。公司一般将所有的这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样便诞生了资源统一管理与调度平台,典型的代表是mesos和yarn。
YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度。
YARN的基本思想是将MR1中JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。
该框架主要有ResourceManager,Applicationmatser,nodemanager。
- ResourceManager主要负责所有的应用程序的资源分配,
- ApplicationMaster主要负责每个作业的任务调度,也就是说每一个作业对应一个 ApplicationMaster。
- Nodemanager是接收Resourcemanager 和ApplicationMaster的命令来实现资源的分配执行体。
其主要工作过程如下:ResourceManager在接收到client的作业提交请求之后,会分配一个Conbiner,这里需要说明一下的是Resoucemanager分配资源是以Conbiner为单位分配的。第一个被分配的Conbiner会启动Applicationmaster,它主要负责作业的调度。Applicationmanager启动之后则会直接跟NodeManager通信。 需要注意的是,在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
2.对比Hadoop与Spark的优缺点。
Hadoop和Spark均是大数据框架,都提供了一些执行常见大数据任务的工具。但它们所执行的任务并不相同,彼此也并不排斥。虽然在特定的情况下,Spark据称要比Hadoop快100倍,但它本身没有一个分布式存储系统。而分布式存储是如今许多大数据项目的基础。它可以将PB级的数据集存储在几乎无限数量的普通计算机的硬盘上,并提供了良好的可扩展性,只需要随着数据集的增大增加硬盘。因此,Spark需要一个第三方的分布式存储。也正是因为这个原因,许多大数据项目都将Spark安装在Hadoop之上。这样,Spark的高级分析应用程序就可以使用存储在HDFS中的数据了。
对于Hadoop而言,其优势在于:
- 可靠性: Hadoop将数据存储在多个备份,Hadoop提供高吞吐量来访问应用程序的数据。
- 高扩展性: Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性: Hadoop以并行的方式工作,通过并行处理加快处理速度。
- 高容错性: Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本: Hadoop能够部署在低廉的(low-cost)硬件上。
而对于Spark而言,其优势在于:
- 计算速度快: 与Hadoop相比,Spark真正的优势在于速度。Hadoop的MapReduce系统会在每次操作之后将所有数据写回到物理存储介质上。而spark从磁盘中读取数据,把中间数据放到内存中,完成所有必须的分析处理,将结果写回集群,所以spark更快。
- Spark 提供了大量的库: 包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。
- 支持多种资源管理器: Spark 支持 Hadoop YARN,及其自带的独立集群管理器
- 操作简单: 高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
3.如何实现Hadoop与Spark的统一部署?
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署,由Yarn进行资源调度和管理,计算资源按需伸缩,不需要负载应用混搭,提高集群利用率,共享底层存储,避免数据跨集群迁移,实现Hadoop和spark的统一部署。

