


scrapy框架day01
scrapy框架介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的用法即可。
scrapy安装
Windows: # 跟步骤走即可
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted # 下载你当前python的版本
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install pywin32
e. pip3 install scrapy
完成上步骤后
创建项目 scrapy startproject 项目名
目录结构 : 如图
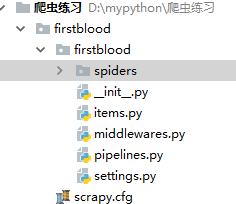
文件介绍
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据持久化处理
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫解析规则
创建爬虫应用 cd到项目目录 执行 scrapy genspider 程序名(py名字) 爬取的网页(url)
(例如:scrapy genspider qiubai www.qiushibaike.com)
创建完成后 会在如图生成文件

创建后修改settings.py中的配置:如图

USER_AGENT : 身份伪装
ROBOTSTXT_OBEY : 遵从协议 (False) 不遵从 默认Ture
修改完成后 执行 scrapy crawl qiubai(py名) --nolog(不打印日志) 运行程序
在spiders目录下创建的项目(爬虫文件)

练习使用 : 将糗百首页中段子的内容和标题进行爬取

输出 : 

输出 : 
如何取出文本:
 可以使用这两种方法取出data的文本
可以使用这两种方法取出data的文本
如何持久化保存: 使用管道 piplines.py 定义数据类型 items
1.将数据封装到 item中

2.使用yield将items中的对象交给piplines管道进行保存

3.settings中配置管道
 放开 300优先级从小到大!!!
放开 300优先级从小到大!!!
配置piplines 写入文件

执行爬虫:


如何保存在数据库中
在piplinse.py中 写类
Mysql : 使用pymysql模块
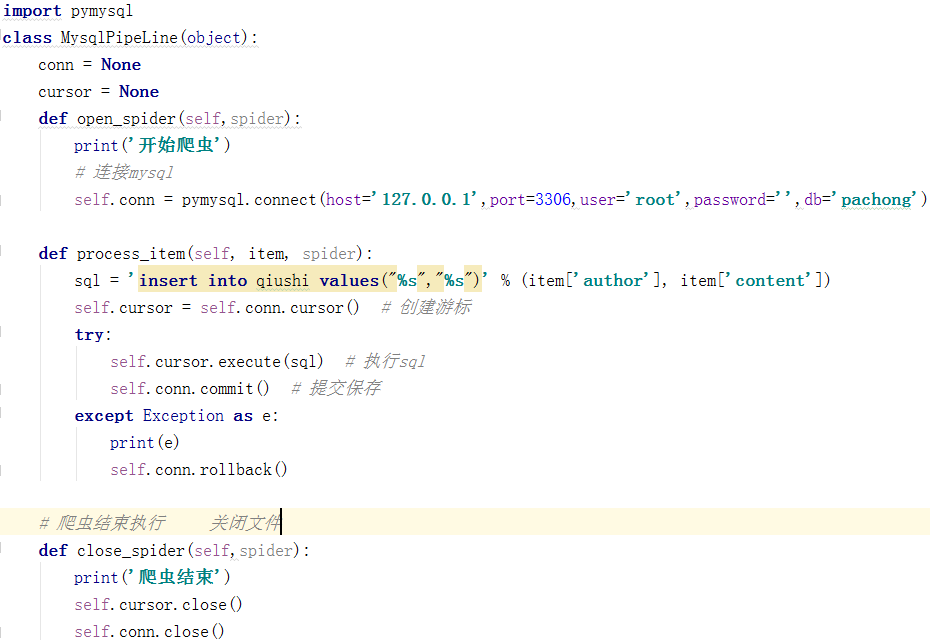
一定要把类配置到下图

