
(04)SQL执行顺序 & 查询优化
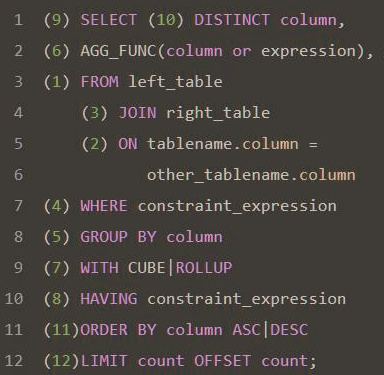
1. SQL 执行顺序
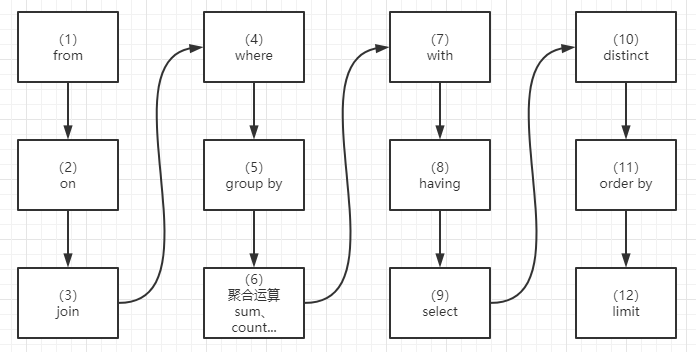
2. 查询优化
2.1. 优化关联条件
- 确保on上有索引,存在联合索引时,要考虑索引的顺序
- 确保order by / group by 时,只涉及到一张表的列
2.2. 优化子查询
尽可能使用关联代替子查询
2.3. 优化union
除非需要过滤序重复数据,否则推荐使用 union all。 union执行时mysql会给临时表加上distinct关键字,影响效率
2.4. 优化limit分页
当表中数据很多并且使用分页查询时,查询越靠后的页数,查询时间也会越长。
因为mysql查询时,是从前往后查询的,查询的数据越靠后,所需的时间也就越长。
举个例子,对下边的 sql 进行优化,假设表中有500w条数据。
select * from t_data limit 10000, 5;
2.4.1. 优化前
查询结果如下如 select * from t_data limit 10000, 5;
执行计划如下 explain select * from t_data limit 10000, 5;
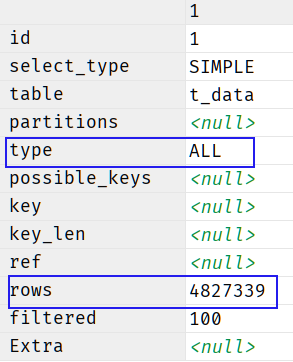
看执行计划,type=all使用了全表扫描,同时检索了480w条数据,效率很低
2.4.2. 优化后
优化思路:
- 尽可能使用覆盖索引、聚簇索引,而不是查询所有列
- 增加个子查询,子查询只要查id字段,因为id是聚簇索引,只查询id字段是会走索引的,速度很快。然后再根据查询出来的id进行查找其他字段数据。
优化后的 sql 如下
select a.* from t_data a
inner join (
select id from t_data order by id limit 10000, 5
) b on a.id = b.id;
为什么子查询要加group by id?因为我在测试的时候,select id from t_data limit 10000, 5 与 select * from t_data limit 10000, 5 查询到的id是不同的。当加了group by id 之后,查询结果就相同了

执行计划如下
explain select a.* from t_data a
inner join (
select id from t_data order by id limit 10000, 5
) b on a.id = b.id;
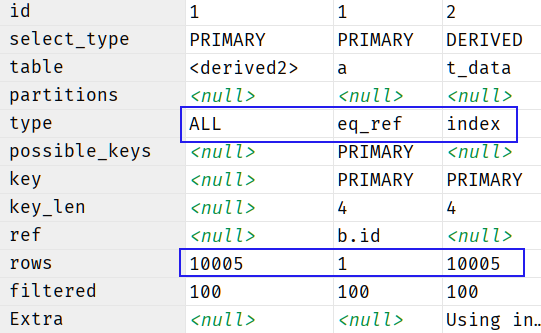
分析行计划:
- id = 2 的数据 type 为 index ,说明走了索引,速度提升。
- 右边两条数据的 key 为 primary ,说明使用的索引是主键。
- 三条数据 rows 一共才检索了 2w 条数据,效率明显提升。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)