
(03)索引
1. 概念
索引底层存储用的B+树
一张表中有2个索引,那就会有2个B+树。(索引就是B+树存储的,可以理解为索引就是B+树)
什么是B+树?参考连接
https://cloud.tencent.com/developer/article/1681803
特殊情况:mysql的 memery 存储引擎使用的是hash表存储,而不是B+树。InnoDB、MyISAM
的索引结构是 B+树索引
注意:使用索引时,尽可能的使用长度较小的列
2. 索引分类
2.1. 主键索引
建表时,mysql会自动为主键创建索引。主键索引属于特殊的唯一索引,不能为空值,且每张表只能有一个主键索引
2.2. 唯一索引
ALTER TABLE table_name ADD UNIQUE (column)
唯一索引允许空值,一张表中可以有多个唯一索引
1.主键一定是唯一性索引,唯一性索引并不一定就是主键;
2.一个表中可以有多个唯一性索引,但只能有一个主键;
3.主键列不允许空值,而唯一性索引列允许空值;
2.3. 组合索引
ALTER TABLE table_name ADD INDEX index_name (column1,column2,...)
使用组合索引时,需要注意组合索引的顺序
2.3.1. 案例
建立组合索引(a,b,c)
ALTER TABLE table_name ADD INDEX index_name (a,b,c)
执行上边sql语句,相当于建立了a、ab、abc三个索引。
一个索引顶三个索引是好事。如果不使用联合索引,而是单独建立3个索引,那么每多一个索引都会增加写操作的开销和磁盘空间的开销
会存在覆盖索引(什么是覆盖索引,下边会讲)。有如下sql
select a,b,c from table where a=1and b = 2。
那么MySQL可以直接通过遍历索引取得数据,而无需回表查询(什么是回表,下边会讲),这减少了很多的随机io操作
组合索引匹配越多,筛选数据越快。
假设一张表中,有1000w条数据,a=1的数据占10%,b=2的数据占10%,c=3的数据占10%
不使用联合索引,把a,b,c拆分为3个单独索引,有如下sql
select * from table where a = 1 and b =2 and c = 3。
检索次数为1000W*10%=100w ,然后再回表从100w条数据中找到符合b=2 and c= 3的数据。
使用联合索引,(a,b,c)为一个整体。有如下sql
select * from table where a = 1 and b =2 and c = 3。
检索次数为1000w *10% *10% *10%=1w
2.4. 前缀索引
前缀索引,就是把一个很长的字符串,取前 length 个字符当索引,难点在于这个 length 值取多少合适
当索引列是很长的字符串,对该列创建索引对查询效率提升不是很大,因为索引的B+树会很大。
可以对很长的列创建前缀索引,语法如下
ALTER TABLE table_name ADD KEY(column_name(length));
前缀索引的长度length怎么设置合适?
可以通过 COUNT(DISTINCT LEFT(column_name(length))) / COUNT(*) 来推测长度
select
count(distinct left(str1, 4)) / count(*),
count(distinct left(str1, 5)) / count(*),
count(distinct left(str1, 6)) / count(*),
count(distinct left(str1, 7)) / count(*),
count(distinct left(str1, 8)) / count(*),
count(distinct left(str1, 9)) / count(*),
count(distinct left(str1, 10)) / count(*)
from t_data;
计算结果如下
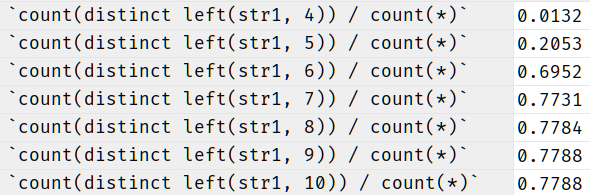
- 根据上边计算结果,长度越大,求出结果越接近1,越接近1则代表该长度越合适
- 但是,并不是长度越大越好,长度大代表索引的B+树大,会导致查询效率不高
- 所以,在选取长度时,可以选取结果增长不是很大的长度
由上边结果可看出,最合适的长度是 7 或 8 。
因为长度为 4 ~ 6 时结果变动很大, 7 ~ 10 时结果趋向平稳,所以长度在 7 或 8 最合适
3. 聚簇索引/二级索引/非聚簇索引
聚簇索引/二级索引/非聚簇索引 不是单独的索引类型,而是一种数据存储方式
3.1. 聚簇索引
InnoDB主键id索引类型为聚簇索引
聚簇索引就是把InnoDB引擎表的主键构造一颗B+树,同时叶子节点(最底层节点)中存放的就是整张表的行记录数据。
说白了聚簇索引的叶子节点存放的是主键值+数据行
假设user表id为主键,数据库类型为InnoDB,那么建表时MySql会自动为主键id创建聚簇索引,如下图
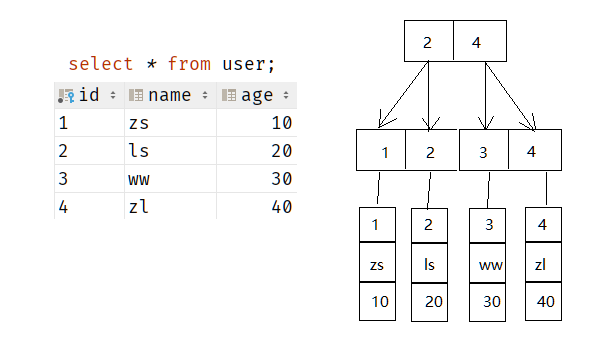
3.2. 二级索引
聚簇索引的叶子节点存放的是主键值+数据行,二级索引的叶子节点存放的是索引值+主键值
如果我手动创建一个普通索引
ALTER TABLE user ADD INDEX in_name (name)
那么name这个索引的数据结构如下图
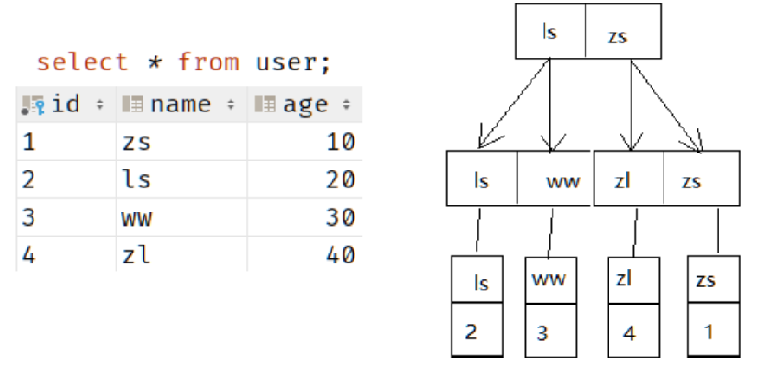
3.3. 非聚簇索引
MyISAM主键id索引类型为非聚簇索引
非聚簇索引就是把MyISAM引擎表的主键构造一颗B+树,非聚簇索引将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置。
说白了非聚簇索引的叶子节点存放的是主键值+数据行所在地址
假设user表id为主键,数据库类型为MyISAM,那么建表时MySql会自动为主键id创建非聚簇索引,如下图
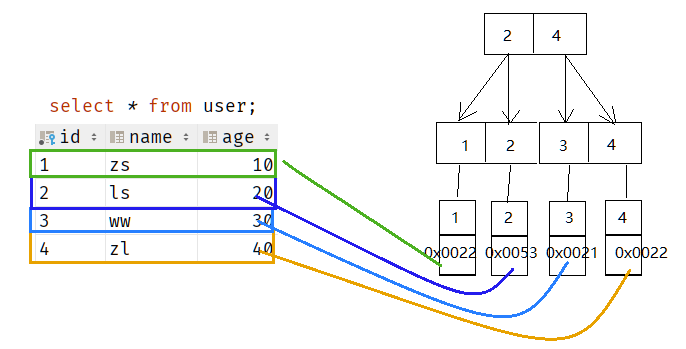
4. 常见名词
4.1. 回表
假设user表有id,name,age三个字段,id为主键,name为普通索引(二级索引)。当执行
select id,name,age from user where name = 'xx'
时,由于name索引的B+树子节点存储的是索引值+主键值(找不到age字段),那么就会根据主键id再去执行聚簇索引匹配到age字段,这种方式就称为回表(只有建普通索引才存在回表的情况)
4.2. 覆盖索引
如果把上边的回表sql改为
select id,name from user where name = 'xx'
,由于name索引存储的是索引值+主键值,而此时查询结果也只有索引值+主键值,不需要去聚簇索引重新查询数据,这种方式就称为索引覆盖
4.3. 最左匹配
假设user表有id,a,b,c四个字段,(a,b,c)是联合索引
那么只有以下3种情况会走索引
explain select * from user where a = '1';
explain select * from user where a = '1' and b = '2';
explain select * from user where a = '1' and b = '2' and c='3';
不会走索引
explain select * from user where b = '2';
explain select * from user where c = '3';
explain select * from user where b = '2' and c = '3';
因为跳过了a条件,无法形成最左匹配
只走一半的索引
explain select * from user where a = '1' and c = '3'
a='1' 符合最左匹配,所以a='1'会走索引。但是c='3'是跳过了b,所以c='3'是在a='1'的结果中再进行筛选的,所以c='3'没有走索引
explain select * from user where a = '1' and b > '3' and c = '4'
a='1'符合最左匹配,所以a='1'走索引。b是范围查询,b>'3'走索引。由于b是范围查询,导致b之后的所有条件都不走索引,所以c='4'不走索引
4.4. 索引下推
假设user表有id,name,sex三个字段,(name,sex)是联合索引
假设数据为:
| id | name | sex |
|---|---|---|
| 1 | 张三 | 男 |
| 2 | 张四 | 女 |
执行sql为
select * from user where name like '张%' and sex='男'
没有索引下推时
索引先根据name最左匹配到主键(忽略sex),找到id分别为1、2两条数据,然后再根据两个id去匹配主键索引(聚簇索引),导致匹配了2次
有索引下推时
索引先根据name最左匹配到主键,再匹配sex,找到id为1的数据,然后再根据一个id去匹配主键索引,只需要匹配1次就得到结果
5. 索引匹配方式
有如下表结构
create table staffs(
id int primary key not null,
name varchar(24),
age varchar(24) ,
pos varchar(24),
crtime timestamp
);
alter table staffs add index(name, age, pos);
5.1. 全值匹配
索引中所有列匹配
explain select * from staffs where name='' and age='' and pos='';
name走索引,age走索引,pos走索引。
5.2. 匹配最左前缀
只匹配最左几列
explain select * from staffs where name='' and age = '';
name走索引,age走索引。
explain select * from staffs where age = '' and name='';
name走索引,age走索引。sql优化器会自动把name排在前边
explain select * from staffs where age = '' and pos='';
age不走索引,pos不走索引。不符合最左前缀匹配
5.3. 匹配列前缀
匹配某列值开头部分
explain select * from staffs where name like 'a%';
name走索引
explain select * from staffs where name like '%a';
name不走索引。模糊查询%放在前边导致不走索引。把索引当做B+树来看待,开头是%导致不知道怎么去遍历索引,于是MySQL索性就全表扫描
5.4. 匹配范围值
查找一个范围数据
explain select * from staffs where name > 'a';
name走索引
explain select * from staffs where name > 'a' and age='13'
name走索引,age不走索引。因为范围查询之后的所有条件,都会索引失效
5.5. 精确匹配某一列,并范围匹配另一列
精确匹配某一列,并范围匹配另一列
explain select * from staffs where name = 'a' and age > '3';
name走索引,age走索引。如果age之后有pos='xx',则pos不走索引。因为范围查询之后的所有条件,都会索引失效。
5.6. 只访问索引的查询
只访问索引的查询
explain select name,age,pos from staffs where name = 'a';
name走索引,同时索引覆盖。查询时只查索引的列,其他列都不查询,本质上就是索引覆盖。
如果组合索引是(name,age),则该语句不满足索引覆盖,因为查询出来的pos不属于组合索引
6. crc32 的使用
crc32可以把一个很长的字符串,转为int类型
使用方式如select crc32('我是很长的字符串')查询结果为 468066450
案例:假设有很长的url存到了MySQL中,我要利用这个字段去精确查询某行记录,怎么创建索引更好?
- 创建索引首先要明白,索引列的数据越小越好
- 很明显url这个字段不适合当索引,因为有的url特别长
- 为了解决url过长问题,可以新增一个列crc32Url,用来存储url的crc32结果(md5也同理,都是为了把长的字符串变小)
- 然后再对 crc32Url 这个字段做索引,这样速度比直接用url做索引快很多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号