
HashMap为什么不安全
JDK1.7 中HashMap不安全原因
HashMap 的结构
HashMap 其实就是数组 + 链表组成的。 数组默认长度为 16 ,数组的每个元素存放的是一个链表。
扩容机制
当 HashMap 中元素个数 size 超过数组长度 length * loadFactor 时,就会进行数组扩容。数组 length 默认为16,loadFactor 的默认值为0.75。也就是说,默认情况下,当 hashmap 中元素个数超过 16 * 0.75 = 12 的时候,就把数组的大小扩展为 2 * 16 = 32,即扩大一倍,然后重新计算每个元素在数组中的位置。
1、假设 HashMap 的 length 长度为 2,hash 算法是简单的 key % length。
2、在 HashMap 中分别存放 key = 5,7,3 三条数据,计算出的hash值都是1(哈希冲突)。
3、所以这三条数据都应该落在table[1]这个位置。
4、那么产生哈希冲突的数据怎么同时落在table[1]的位置?
5、table 数组中存放的其实是一个链表,当有哈希冲突的数据,都往链表的表头插入数据。
根据上边说明,得出按顺序存入 key = 5,7,3 三条数据最终形成的哈希表如下:
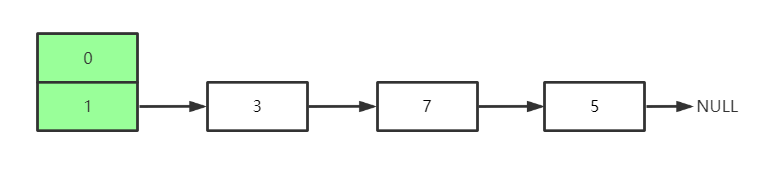
假设 loadFactor = 1,由于元素有3个,所以 HashMap 把数组大小扩展为原来的的一倍,既 2 * 2 = 4。
HashMap 扩容时,会把旧的 table 数据迁移到 newTable 中,代码如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 遍历数组 table
for (Entry<K,V> e : table) {
// 遍历数组中的链表,一直到 e = null 为止
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
// 以下三行是线程不安全的关键
// 将当前entry的next指向新的索引位置。newTable[i]有可能为空,newTable[i]有可能也是个entry链表
e.next = newTable[i];
// entry链覆盖掉newTable[i]。所以entry链表的第一个元素,总是当前entry元素。
newTable[i] = e;
// 当前的entry等于下一个元素
e = next;
}
}
}
根据上边的代码可知,扩容时循环取出每一条数据存入 newTable 中,最终新扩容的哈希表如下

扩容导致不安全
假设现在有两个线程A、B同时对下面这个HashMap进行扩容操作

假设当A扩容时,执行代码到 newTable[i] = e 时被挂起,线程 B 完成了数据迁移
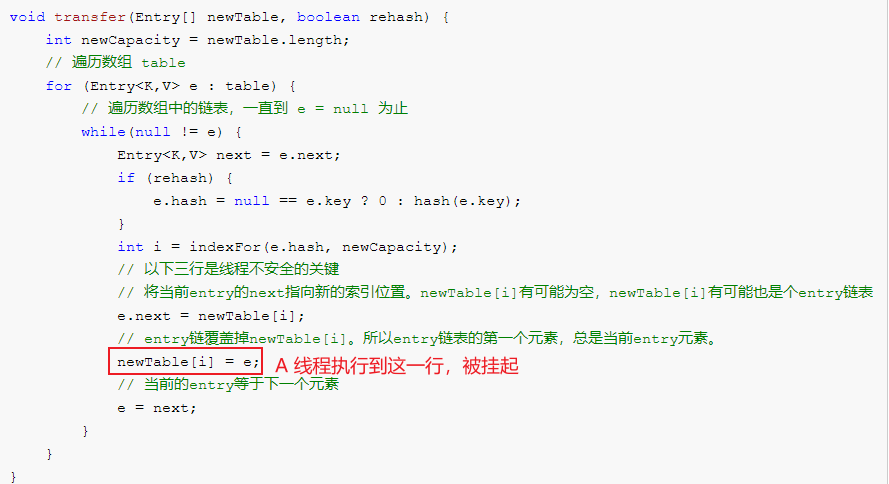
此时线程 A 中的结构为。 e = 3、Entry<K,V> next = e.next = 7、e.next = newTable[i] = null
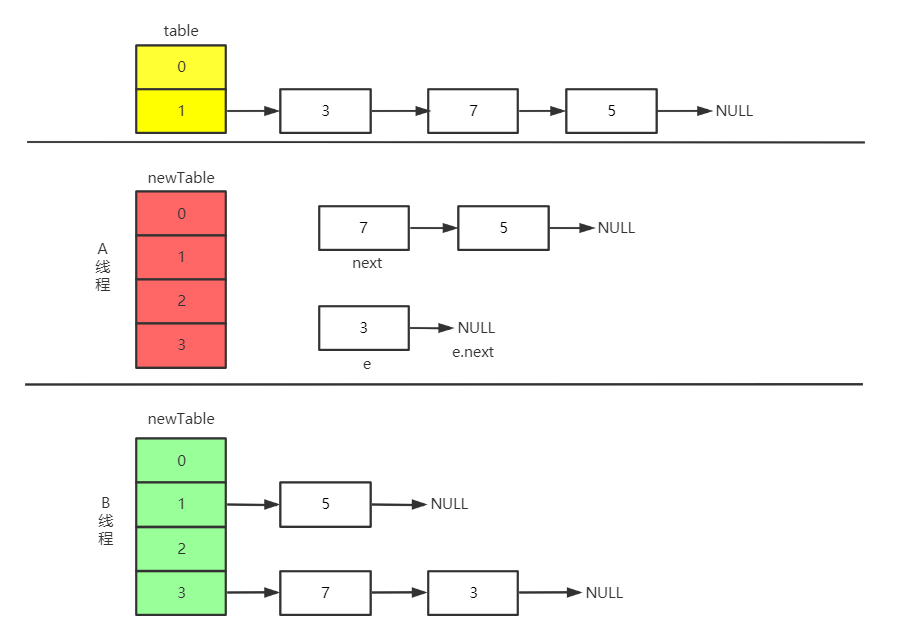
此时 CPU 开始执行 A 线程,newTable[i] = e、e = next。最后得到的结果如下

重点来了。只有newTable是自有的,table是线程共享的,B线程执行完以后,改变了table共享元素的指向,所以轮到 A 执行的时候,就会依赖到 B 线程带来的结果。如下图
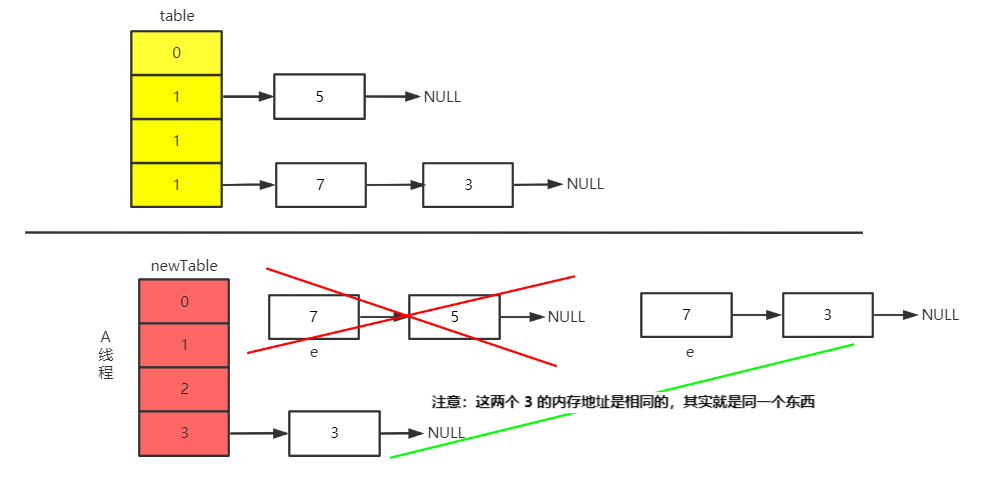
线程 A 继续执行 where 循环,执行代码到 newTable[i] = e 时被挂起。
此时线程 A 中的结构为。 e = 7、Entry<K,V> next = e.next = 3、e.next = newTable[i] = 3
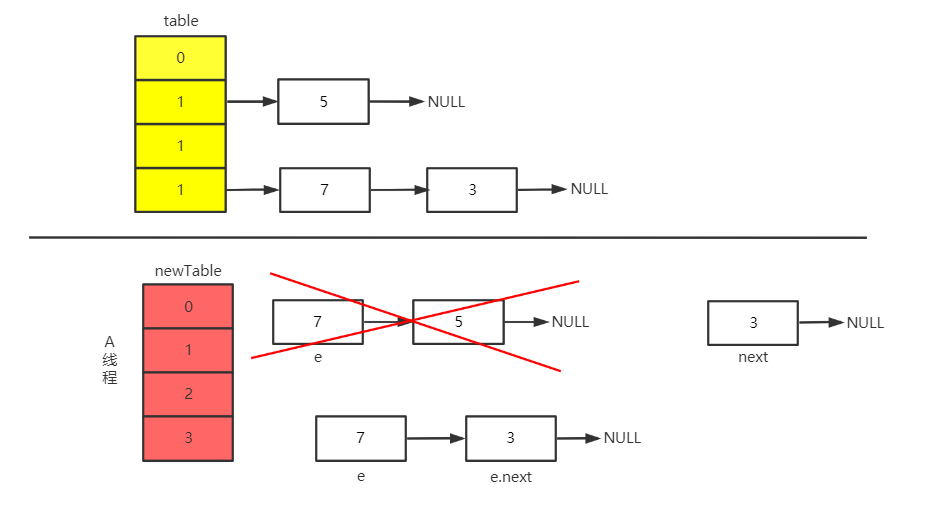
CPU 继续执行 A 线程,newTable[i] = e、e = next。最后得到的结果如下
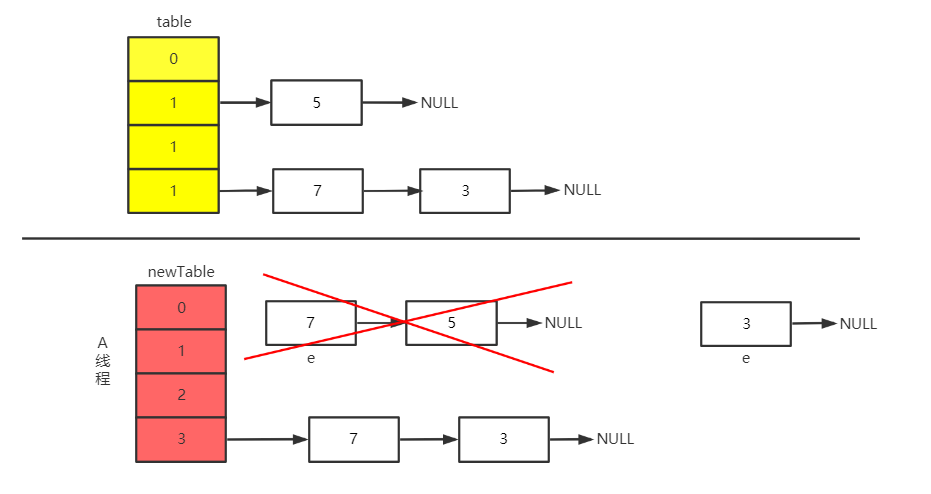
线程 A 继续执行 where 循环,执行代码到 newTable[i] = e 时被挂起。
此时线程 A 中的结构为。 e = 3、Entry<K,V> next = e.next = null、e.next = newTable[i] = 7 -> 3
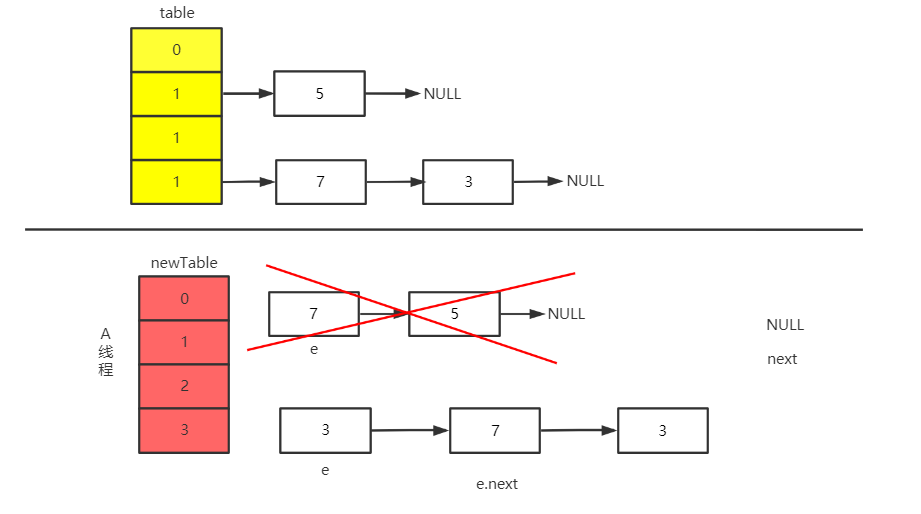
CPU 继续执行 A 线程,newTable[i] = e、e = next。最后得到的结果如下。
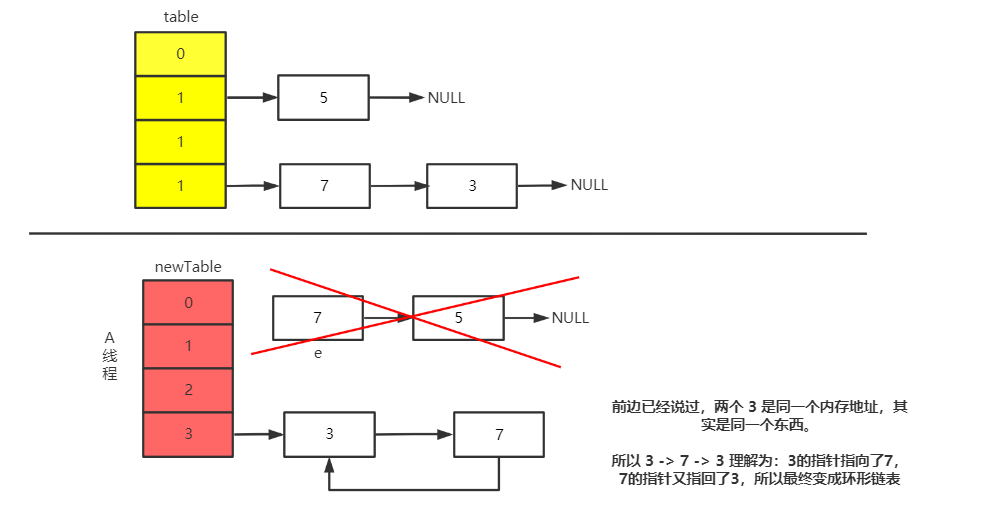
由于两个3是同一个东西,所以最终变成了环形链表。
示例
- 假设我要 get 获取 HashMap 中 key = 11 的值时,此时计算 key 的 hash 值刚好落在 table[3] 的位置上,那就会导致死循环。
- 或者在下一次的扩容时,将 table[3] 中的数据复制到 newTable 时出现死循环,因为 Entry 的 next 节点永远不为空,就会产生死循环获取 Entry。
JDK1.8 中HashMap不安全原因
HashMap 的结构
JDK1.8 中 HashMap 的结构和 JDK1.7 有所不同。
JDK1.7:HashMap 采用数组 + 链表
JDK1.8:HashMap 采用数组 + 链表 + 红黑树
JDK1.8 为什么采用多加个红黑树? 因为JDK1.7中,当 HashMap 中的数据越来越多时,产生 hash 碰撞的数据也会越来越多,这会导致在一条链表中的数据越来越多,从而导致获取数据时间太长。
而JDK1.8会在链表达到一定长度时,会将链表转为红黑树结构,如下图所示

线程不安全原因
先看 jdk 1.8 中的 put 方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有 hash 碰撞则直接插入元素
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
问题主要出现在这里

假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的
1、当线程 A 执行到上边红框代码时,由于时间片耗尽导致被挂起
2、而线程 B 得到时间片后在红框代码处插入了元素,完成了正常的插入
3、然后线程 A 获得时间片,然后直接进行插入
4、这就导致了线程 B 插入的数据被线程 A 覆盖了,从而导致数据缺失
而在尾部的 ++modCount 和 ++size 也会有问题。因为 ++ 操作并不具备原子性,在多线程中必然会导致最终 ++ 的结果 <= 预计中的结果。

总结
HashMap的线程不安全主要体现在下面两个方面:
1.在JDK1.7中,当并发执行扩容操作时会造成环形链,导致 get 数据时出现死循环。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
参考 https://blog.csdn.net/swpu_ocean/article/details/88917958

