【常用】面试题
springmvc 工作原理
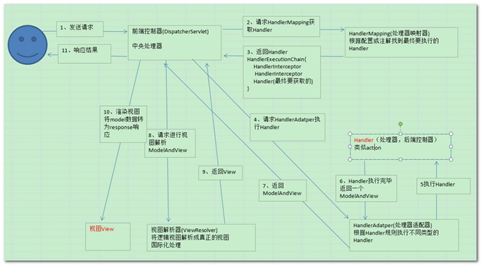
客户端发送请求给web.xml中springmvc的dispatcherServlet;
dispatcherServlet调用handlerMapping处理器映射器;
HandlerMapping通过XML配置、注解查找并返回具体处理器对象以及处理拦截器(如果有则返回)给dispatcherServlet;
dispatcherServlet调用handlerAdapter处理器适配器;
handlerAdapter调用具体的处理器(Controller,也叫后端控制器);
Controller执行完成返回ModelAndView。
HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
ViewReslover解析后返回具体View。
DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
DispatcherServlet响应用户。
组件说明:
以下组件通常使用框架提供实现:
DispatcherServlet:作为前端控制器,整个流程控制的中心,控制其它组件执行,统一调度,降低组件之间的耦合性,提高每个组件的扩展性。
HandlerMapping:通过扩展处理器映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
HandlAdapter:通过扩展处理器适配器,支持更多类型的处理器。
ViewResolver:通过扩展视图解析器,支持更多类型的视图解析,例如:jsp、freemarker、pdf、excel等。
组件:
1、前端控制器DispatcherServlet(不需要工程师开发),由框架提供
作用:接收请求,响应结果,相当于转发器,中央处理器。有了dispatcherServlet减少了其它组件之间的耦合度。
用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性。
2、处理器映射器HandlerMapping(不需要工程师开发),由框架提供
作用:根据请求的url查找Handler
HandlerMapping负责根据用户请求找到Handler即处理器,springmvc提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
3、处理器适配器HandlerAdapter
作用:按照特定规则(HandlerAdapter要求的规则)去执行Handler
通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
4、处理器Handler(需要工程师开发)
注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler
Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。
由于Handler涉及到具体的用户业务请求,所以一般情况需要工程师根据业务需求开发Handler。
5、视图解析器View resolver(不需要工程师开发),由框架提供
作用:进行视图解析,根据逻辑视图名解析成真正的视图(view)
View Resolver负责将处理结果生成View视图,View
Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。 springmvc框架提供了很多的View视图类型,包括:jstlView、freemarkerView、pdfView等。
一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由工程师根据业务需求开发具体的页面。
6、视图View(需要工程师开发jsp...)
View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...)
核心架构的具体流程步骤如下:
1、首先用户发送请求——>DispatcherServlet,前端控制器收到请求后自己不进行处理,而是委托给其他的解析器进行处理,作为统一访问点,进行全局的流程控制;
2、DispatcherServlet——>HandlerMapping, HandlerMapping 将会把请求映射为HandlerExecutionChain
对象(包含一个Handler 处理器(页面控制器)对象、多个HandlerInterceptor
拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
3、DispatcherServlet——>HandlerAdapter,HandlerAdapter 将会把处理器包装为适配器,从而支持多种类型的处理器,即适配器设计模式的应用,从而很容易支持很多类型的处理器;
4、HandlerAdapter——>处理器功能处理方法的调用,HandlerAdapter 将会根据适配的结果调用真正的处理器的功能处理方法,完成功能处理;并返回一个ModelAndView 对象(包含模型数据、逻辑视图名);
5、ModelAndView的逻辑视图名——>
ViewResolver, ViewResolver 将把逻辑视图名解析为具体的View,通过这种策略模式,很容易更换其他视图技术;
6、View——>渲染,View会根据传进来的Model模型数据进行渲染,此处的Model实际是一个Map数据结构,因此很容易支持其他视图技术;
7、返回控制权给DispatcherServlet,由DispatcherServlet返回响应给用户,到此一个流程结束。
下边两个组件通常情况下需要开发:
Handler:处理器,即后端控制器用controller表示。
View:视图,即展示给用户的界面,视图中通常需要标签语言展示模型数据。
在将SpringMVC之前我们先来看一下什么是MVC模式
MVC:MVC是一种设计模式
MVC的原理图:

分析:
M-Model 模型(完成业务逻辑:有javaBean构成,service+dao+entity)
V-View 视图(做界面的展示 jsp,html……)
C-Controller 控制器(接收请求—>调用模型—>根据结果派发页面)
springMVC是什么:
springMVC是一个MVC的开源框架,springMVC=struts2+spring,springMVC就相当于是Struts2加上sring的整合,但是这里有一个疑惑就是,springMVC和spring是什么样的关系呢?这个在百度百科上有一个很好的解释:意思是说,springMVC是spring的一个后续产品,其实就是spring在原有基础上,又提供了web应用的MVC模块,可以简单的把springMVC理解为是spring的一个模块(类似AOP,IOC这样的模块),网络上经常会说springMVC和spring无缝集成,其实springMVC就是spring的一个子模块,所以根本不需要同spring进行整合。
SpringMVC的原理图:
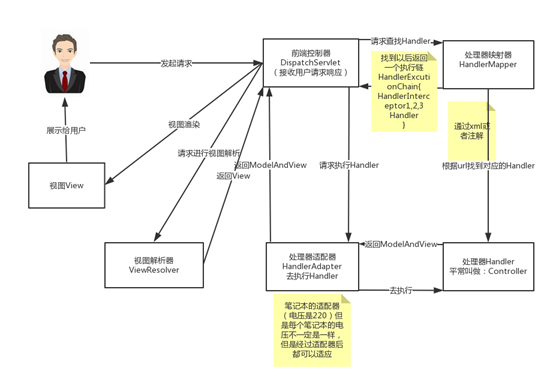
看到这个图大家可能会有很多的疑惑,现在我们来看一下这个图的步骤:(可以对比MVC的原理图进行理解)
第一步:用户发起请求到前端控制器(DispatcherServlet)
第二步:前端控制器请求处理器映射器(HandlerMappering)去查找处理器(Handle):通过xml配置或者注解进行查找
第三步:找到以后处理器映射器(HandlerMappering)像前端控制器返回执行链(HandlerExecutionChain)
第四步:前端控制器(DispatcherServlet)调用处理器适配器(HandlerAdapter)去执行处理器(Handler)
第五步:处理器适配器去执行Handler
第六步:Handler执行完给处理器适配器返回ModelAndView
第七步:处理器适配器向前端控制器返回ModelAndView
第八步:前端控制器请求视图解析器(ViewResolver)去进行视图解析
第九步:视图解析器像前端控制器返回View
第十步:前端控制器对视图进行渲染
第十一步:前端控制器向用户响应结果
看到这些步骤我相信大家很感觉非常的乱,这是正常的,但是这里主要是要大家理解springMVC中的几个组件:
前端控制器(DispatcherServlet):接收请求,响应结果,相当于电脑的CPU。
处理器映射器(HandlerMapping):根据URL去查找处理器
处理器(Handler):(需要程序员去写代码处理逻辑的)
处理器适配器(HandlerAdapter):会把处理器包装成适配器,这样就可以支持多种类型的处理器,类比笔记本的适配器(适配器模式的应用)
视图解析器(ViewResovler):进行视图解析,多返回的字符串,进行处理,可以解析成对应的页面
数据库中事物
本篇讲诉数据库中事务的四大特性(ACID),并且将会详细地说明事务的隔离级别。
如果一个数据库声称支持事务的操作,那么该数据库必须要具备以下四个特性:
⑴ 原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,这和前面两篇博客介绍事务的功能是一样的概念,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
⑵ 一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
⑶ 隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
关于事务的隔离性数据库提供了多种隔离级别,稍后会介绍到。
⑷ 持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
以上介绍完事务的四大特性(简称ACID),现在重点来说明下事务的隔离性,当多个线程都开启事务操作数据库中的数据时,数据库系统要能进行隔离操作,以保证各个线程获取数据的准确性,在介绍数据库提供的各种隔离级别之前,我们先看看如果不考虑事务的隔离性,会发生的几种问题:
1,脏读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,这时一个并发的事务来访问该数据,就会造成两个事务得到的数据不一致。例如:用户A向用户B转账100元,对应SQL命令如下
update account set money=money+100 where name=’B’; (此时A通知B)
update account set money=money - 100 where name=’A’;
当只执行第一条SQL时,A通知B查看账户,B发现确实钱已到账(此时即发生了脏读),而之后无论第二条SQL是否执行,只要该事务不提交,则所有操作都将回滚,那么当B以后再次查看账户时就会发现钱其实并没有转。
2,不可重复读
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且提交事务给数据库,事务T1再次读取该数据就得到了不同的结果,发送了不可重复读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
在某些情况下,不可重复读并不是问题,比如我们多次查询某个数据当然以最后查询得到的结果为主。但在另一些情况下就有可能发生问题,例如对于同一个数据A和B依次查询就可能不同,A和B就可能打起来了……
3,虚读(幻读)
幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
现在来看看MySQL数据库为我们提供的四种隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读)。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);而在Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
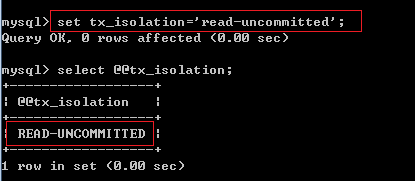
在MySQL数据库中查看当前事务的隔离级别:
select @@tx_isolation;
在MySQL数据库中设置事务的隔离 级别:
set [glogal | session] transaction isolation level 隔离级别名称;
set tx_isolation=’隔离级别名称;’
例1:查看当前事务的隔离级别:

例2:将事务的隔离级别设置为Read uncommitted级别:

或:
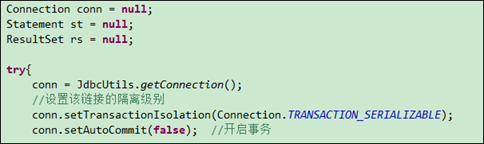
记住:设置数据库的隔离级别一定要是在开启事务之前!
如果是使用JDBC对数据库的事务设置隔离级别的话,也应该是在调用Connection对象的setAutoCommit(false)方法之前。调用Connection对象的setTransactionIsolation(level)即可设置当前链接的隔离级别,至于参数level,可以使用Connection对象的字段:

在JDBC中设置隔离级别的部分代码:
后记:隔离级别的设置只对当前链接有效。对于使用MySQL命令窗口而言,一个窗口就相当于一个链接,当前窗口设置的隔离级别只对当前窗口中的事务有效;对于JDBC操作数据库来说,一个Connection对象相当于一个链接,而对于Connection对象设置的隔离级别只对该Connection对象有效,与其他链接Connection对象无关。
参考博客:
http://www.zhihu.com/question/23989904
http://dev.mysql.com/doc/refman/5.6/en/set-transaction.html
http://www.cnblogs.com/xdp-gacl/p/3984001.html
线程的基本概念、线程的基本状态以及状态之间的关系
什么是线程
一个线程是进程的一个顺序执行流。同类的多个线程共享一块内存空间和一组系统资源,线程本身有一个供程序执行时的堆栈。线程在切换时负荷小,因此,线程也被称为轻负荷进程。一个进程中可以包含多个线程。
进程与线程的区别
一个进程至少有一个线程。线程的划分尺度小于进程,使得多线程程序的并发性高。另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
线程在执行过程中与进程的区别在于每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用来实现进程的调度和管理以及资源分配。
并发原理
多个线程或进程”同时”运行只是我们感官上的一种表现。事实上进程和线程是并发运行的,OS的线程调度机制将时间划分为很多时间片段(时间片),尽可能均匀分配给正在运行的程序,获取CPU时间片的线程或进程得以被执行,其他则等待。而CPU则在这些进程或线程上来回切换运行。微观上所有进程和线程是走走停停的,宏观上都在运行,这种都运行的现象叫并发,但是不是绝对意义上的“同时发生。
线程状态

1.新建
用new语句创建的线程对象处于新建状态,此时它和其他java对象一样,仅被分配了内存。
2.等待
当线程在new之后,并且在调用start方法前,线程处于等待状态。
3.就绪
当一个线程对象创建后,其他线程调用它的start()方法,该线程就进入就绪状态。处于这个状态的线程位于Java虚拟机的可运行池中,等待cpu的使用权。
4.运行状态
处于这个状态的线程占用CPU,执行程序代码。在并发运行环境中,如果计算机只有一个CPU,那么任何时刻只会有一个线程处于这个状态。
只有处于就绪状态的线程才有机会转到运行状态。
5.阻塞状态
阻塞状态是指线程因为某些原因放弃CPU,暂时停止运行。当线程处于阻塞状态时,Java虚拟机不会给线程分配CPU,直到线程重新进入就绪状态,它才会有机会获得运行状态。
阻塞状态分为三种:
1、等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。
2、同步阻塞:运行的线程在获取对象同步锁时,若该同步锁被别的线程占用,则JVM会把线程放入锁池中。
3、其他阻塞:运行的线程执行Sleep()方法,或者发出I/O请求时,JVM会把线程设为阻塞状态。当Sleep()状态超时、或者I/O处理完毕时,线程重新转入就绪状态。
6.死亡状态
当线程执行完run()方法中的代码,或者遇到了未捕获的异常,就会退出run()方法,此时就进入死亡状态,该线程结束生命周期。
Spring监听器和spingmvc dispatcher配置关系
关于SpringMVC,Web.xml监听器是否必须
我们首先来看两个配置:
<!-- Spring MVC配置 -->
<!-- ====================================== -->
<servlet>
<servlet-name>spring</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<!-- 可以自定义servlet.xml配置文件的位置和名称,默认为WEB-INF目录下,名称为[<servlet-name>]-servlet.xml,如spring-servlet.xml
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/spring-servlet.xml</param-value> 默认
</init-param>
-->
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>spring</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
<!-- Spring配置 -->
<!-- ====================================== -->
<listener>
<listenerclass>
org.springframework.web.context.ContextLoaderListener
</listener-class>
</listener>
<!-- 指定Spring Bean的配置文件所在目录。默认配置在WEB-INF目录下 -->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:config/applicationContext.xml</param-value>
</context-param>
在项目中不配置Spring配置,spring一样可以管理项目的bean当然是在springMVC配置里面扫描或维护了bean的关联
为什么我们又建议配置spring监听器?
我们看配置里面加载spring.xml文件的两个标签,前者是在servlet里面用的 <init-param> 初始化标签,我们在spring的 DispatcherServlet源码中可以看到以下代码:
HttpServletBean类中(此类被DispatcherServlet所继承)
Enumeration en = config.getInitParameterNames();
while
(en.hasMoreElements()) {
String property = (String) en.nextElement();
Object value = config.getInitParameter(property);
addPropertyValue(new PropertyValue(property, value));
if
(missingProps != null) {
missingProps.remove(property);
}
}
学过servlet的应该会明白了把就是在servlet初始化时调用,比如你在前者把spring标签故意写错,启动项目不会报错,只有在访问servlet时才会报错。因为此时才加载spring配置文件。但是后者监听器如果故意在配置文件中出现检查式错误,那么启动服务器时就会报错。因为监听器在服务器启动的时候也被启动此时也就开始加载spring配置文件。
注解驱动
<mvc:annotation-driven>会自动注册RequestMappingHandlerMapping与RequestMappingHandlerAdapter两个Bean,这是Spring MVC为@Controller分发请求所必需的,并且提供了数据绑定支持,@NumberFormatannotation支持,@DateTimeFormat支持,@Valid支持读写XML的支持(JAXB)和读写JSON的支持(默认Jackson)等功能。
使用该注解后的springmvc-config.xml:
<!-- spring 可以自动去扫描 base-package下面的包或子包下面的Java文件,如果扫描到有Spring的相关
注解的类,则把这些类注册为Spring的bean -->
<context:component-scan base-package="org.fkit.controller"/>
<!--设置配置方案 -->
<mvc:annotation-driven/>
<!--使用默认的Servlet来响应静态文件-->
<mvc:default-servlet-handler/>
<!-- 视图解析器 -->
<bean
class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<!-- 前缀 -->
<property name="prefix">
<value>/WEB-INF/content/</value>
</property>
<!-- 后缀 -->
<property name="suffix">
<value>.jsp</value>
</property>
</bean>
解释2
<mvc:annotation-driven /> 说明:
是一种简写形式,可以让初学者快速成应用默认的配置方案,会默认注册 DefaultAnnotationHandleMapping以及AnnotionMethodHandleAdapter 这两个 Bean, 这两个 Bean ,前者对应类级别, 后者对应到方法级别;
上在面的 DefaultAnnotationHandlerMapping和AnnotationMethodHandlerAdapter 是 Spring 为 @Controller 分发请求所必需的。
annotation-driven 扫描指定包中类上的注解,常用的注解有:
复制代码
@Controller 声明Action组件
@Service 声明Service组件 @Service("myMovieLister")
@Repository 声明Dao组件
@Component 泛指组件, 当不好归类时.
@RequestMapping("/menu") 请求映射
@Resource 用于注入,( j2ee提供的 ) 默认按名称装配,@Resource(name="beanName")
@Autowired 用于注入,(srping提供的) 默认按类型装配
@Transactional( rollbackFor={Exception.class}) 事务管理
@ResponseBody
@Scope("prototype") 设定bean的作用域
MySql5.6性能优化
今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显。关于数据库的性能,这并不只是DBA才需要担心的事,而这更是我们程序员需要去关注的事情。当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能。这里,我们不会讲过多的SQL语句的优化,而只是针对MySQL这一Web应用最多的数据库。希望下面的这些优化技巧对你有用。
1. 为查询缓存优化你的查询
大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的。因为,我们某些查询语句会让MySQL不使用缓存。请看下面的示例:
|
1 2 3 4 5 6 |
|
上面两条SQL语句的差别就是 CURDATE() ,MySQL的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而开启缓存。
2. EXPLAIN 你的 SELECT 查询
使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。
EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
挑一个你的SELECT语句(推荐挑选那个最复杂的,有多表联接的),把关键字EXPLAIN加到前面。你可以使用phpmyadmin来做这个事。然后,你会看到一张表格。下面的这个示例中,我们忘记加上了group_id索引,并且有表联接:
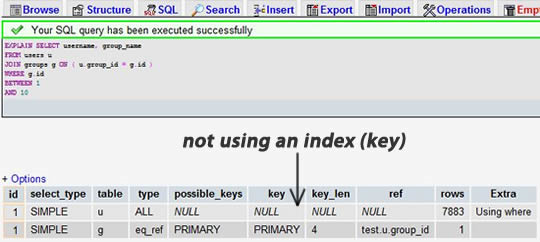
当我们为 group_id 字段加上索引后:

我们可以看到,前一个结果显示搜索了 7883 行,而后一个只是搜索了两个表的 9 和 16 行。查看rows列可以让我们找到潜在的性能问题。
3. 当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1)
|
1 2 3 4 5 6 7 8 9 10 11 |
|
4. 为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。

从上图你可以看到那个搜索字串 “last_name LIKE ‘a%'”,一个是建了索引,一个是没有索引,性能差了4倍左右。
另外,你应该也需要知道什么样的搜索是不能使用正常的索引的。例如,当你需要在一篇大的文章中搜索一个词时,如: “WHERE post_content LIKE ‘%apple%'”,索引可能是没有意义的。你可能需要使用MySQL全文索引 或是自己做一个索引(比如说:搜索关键词或是Tag什么的)
5. 在Join表的时候使用相当类型的例,并将其索引
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)
|
1 2 3 4 5 6 |
|
6. 千万不要 ORDER BY RAND()
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你确不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
下面的示例是随机挑一条记录
|
1 2 3 4 5 6 7 8 9 |
|
7. 避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。
所以,你应该养成一个需要什么就取什么的好的习惯。
|
1 2 3 4 5 6 7 8 9 |
|
8. 永远为每张表设置一个ID
我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的ID来构造你的数据结构。
而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区……
在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比如:有一个“学生表”有学生的ID,有一个“课程表”有课程ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生ID和课程ID叫“外键”其共同组成主键。
9. 使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
MySQL也有一个“建议”(见第十条)告诉你怎么去重新组织你的表结构。当你有一个 VARCHAR 字段时,这个建议会告诉你把其改成 ENUM 类型。使用 PROCEDURE ANALYSE() 你可以得到相关的建议。
10. 从 PROCEDURE ANALYSE() 取得建议
PROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。
例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成 MEDIUMINT 。或是你使用了一个 VARCHAR 字段,因为数据不多,你可能会得到一个让你把它改成 ENUM 的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。
在phpmyadmin里,你可以在查看表时,点击 “Propose table structure” 来查看这些建议
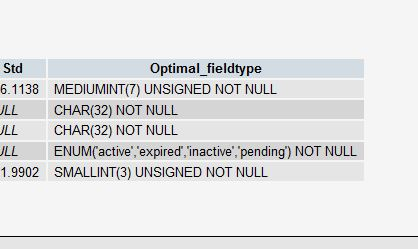
一定要注意,这些只是建议,只有当你的表里的数据越来越多时,这些建议才会变得准确。一定要记住,你才是最终做决定的人。
11. 尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!)
不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
下面摘自MySQL自己的文档:
“NULL columns require additional space in the row to record whether their values are NULL. For MyISAM tables, each NULL column takes one bit extra, rounded up to the nearest byte.”
12. Prepared Statements
Prepared Statements很像存储过程,是一种运行在后台的SQL语句集合,我们可以从使用 prepared statements 获得很多好处,无论是性能问题还是安全问题。
Prepared Statements 可以检查一些你绑定好的变量,这样可以保护你的程序不会受到“SQL注入式”攻击。当然,你也可以手动地检查你的这些变量,然而,手动的检查容易出问题,而且很经常会被程序员忘了。当我们使用一些framework或是ORM的时候,这样的问题会好一些。
在性能方面,当一个相同的查询被使用多次的时候,这会为你带来可观的性能优势。你可以给这些Prepared Statements定义一些参数,而MySQL只会解析一次。
虽然最新版本的MySQL在传输Prepared Statements是使用二进制形势,所以这会使得网络传输非常有效率。
当然,也有一些情况下,我们需要避免使用Prepared Statements,因为其不支持查询缓存。但据说版本5.1后支持了。
在PHP中要使用prepared statements,你可以查看其使用手册:mysqli 扩展 或是使用数据库抽象层,如: PDO.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
13. 无缓冲的查询
正常的情况下,当你在当你在你的脚本中执行一个SQL语句的时候,你的程序会停在那里直到没这个SQL语句返回,然后你的程序再往下继续执行。你可以使用无缓冲查询来改变这个行为。
关于这个事情,在PHP的文档中有一个非常不错的说明: mysql_unbuffered_query() 函数:
“mysql_unbuffered_query() sends the SQL query query to MySQL without automatically fetching and buffering the result rows as mysql_query() does. This saves a considerable amount of memory with SQL queries that produce large result sets, and you can start working on the result set immediately after the first row has been retrieved as you don’t have to wait until the complete SQL query has been performed.”
上面那句话翻译过来是说,mysql_unbuffered_query() 发送一个SQL语句到MySQL而并不像mysql_query()一样去自动fethch和缓存结果。这会相当节约很多可观的内存,尤其是那些会产生大量结果的查询语句,并且,你不需要等到所有的结果都返回,只需要第一行数据返回的时候,你就可以开始马上开始工作于查询结果了。
然而,这会有一些限制。因为你要么把所有行都读走,或是你要在进行下一次的查询前调用 mysql_free_result() 清除结果。而且, mysql_num_rows() 或 mysql_data_seek() 将无法使用。所以,是否使用无缓冲的查询你需要仔细考虑。
14. 把IP地址存成 UNSIGNED INT
很多程序员都会创建一个 VARCHAR(15) 字段来存放字符串形式的IP而不是整形的IP。如果你用整形来存放,只需要4个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当你需要使用这样的WHERE条件:IP between ip1 and ip2。
我们必需要使用UNSIGNED INT,因为 IP地址会使用整个32位的无符号整形。
而你的查询,你可以使用 INET_ATON() 来把一个字符串IP转成一个整形,并使用 INET_NTOA() 把一个整形转成一个字符串IP。在PHP中,也有这样的函数 ip2long() 和 long2ip()。
|
1 |
|
15. 固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
使用“垂直分割”技术(见下一条),你可以分割你的表成为两个一个是定长的,一个则是不定长的。
16. 垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。(以前,在银行做过项目,见过一张表有100多个字段,很恐怖)
示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改写这个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有好的性能。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。
17. 拆分大的 DELETE 或 INSERT 语句
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊WEB服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。下面是一个示例:
|
1 2 3 4 5 6 7 8 9 10 |
|
18. 越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
参看 MySQL 的文档 Storage Requirements 查看所有的数据类型。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009年11月06日),一个简单的ALTER TABLE语句花了3个多小时,因为里面有一千六百万条数据。
19. 选择正确的存储引擎
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。酷壳以前文章《MySQL: InnoDB 还是 MyISAM?》讨论和这个事情。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
下面是MySQL的手册
target=”_blank”MyISAM Storage Engine
20. 使用一个对象关系映射器(Object Relational Mapper)
使用 ORM (Object Relational Mapper),你能够获得可靠的性能增涨。一个ORM可以做的所有事情,也能被手动的编写出来。但是,这需要一个高级专家。
ORM 的最重要的是“Lazy Loading”,也就是说,只有在需要的去取值的时候才会去真正的去做。但你也需要小心这种机制的副作用,因为这很有可能会因为要去创建很多很多小的查询反而会降低性能。
ORM 还可以把你的SQL语句打包成一个事务,这会比单独执行他们快得多得多。
目前,个人最喜欢的PHP的ORM是:Doctrine。
21. 小心“永久链接”
“永久链接”的目的是用来减少重新创建MySQL链接的次数。当一个链接被创建了,它会永远处在连接的状态,就算是数据库操作已经结束了。而且,自从我们的Apache开始重用它的子进程后——也就是说,下一次的HTTP请求会重用Apache的子进程,并重用相同的 MySQL 链接。
在理论上来说,这听起来非常的不错。但是从个人经验(也是大多数人的)上来说,这个功能制造出来的麻烦事更多。因为,你只有有限的链接数,内存问题,文件句柄数,等等。
而且,Apache 运行在极端并行的环境中,会创建很多很多的了进程。这就是为什么这种“永久链接”的机制工作地不好的原因。在你决定要使用“永久链接”之前,你需要好好地考虑一下你的整个系统的架构。
JVM运行原理及调优
1.JVM简析:
作为一名Java使用者,掌握JVM的体系结构也是很有必要的。
说起Java,我们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成:Java编程语言、Java类文件格式、Java虚拟机和Java应用程序接口(Java API)。它们的关系如下图所示:
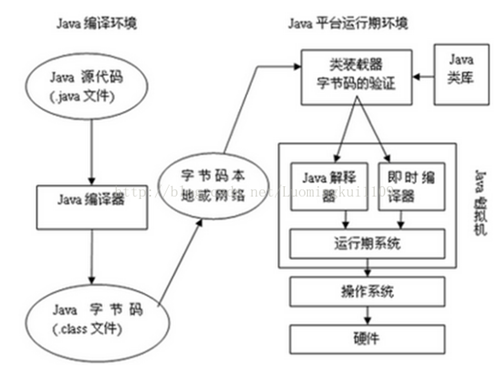
Java平台由Java虚拟机和Java应用程序接口搭建,Java语言则是进入这个平台的通道,用Java语言编写并编译的程序可以运行在这个平台上。这个平台的结构如下图所示: 运行期环境代表着Java平台,开发人员编写Java代码(.java文件),然后将之编译成字节码(.class文件),再然后字节码被装入内存,一旦字节码进入虚拟机,它就会被解释器解释执行,或者是被即时代码发生器有选择的转换成机器码执行。
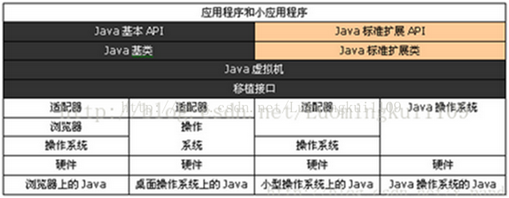
JVM在它的生存周期中有一个明确的任务,那就是运行Java程序,因此当Java程序启动的时候,就产生JVM的一个实例;当程序运行结束的时候,该实例也跟着消失了。 在Java平台的结构中, 可以看出,Java虚拟机(JVM) 处在核心的位置,是程序与底层操作系统和硬件无关的关键。它的下方是移植接口,移植接口由两部分组成:适配器和Java操作系统, 其中依赖于平台的部分称为适配器;JVM 通过移植接口在具体的平台和操作系统上实现;在JVM 的上方是Java的基本类库和扩展类库以及它们的API, 利用Java API编写的应用程序(application) 和小程序(Java applet) 可以在任何Java平台上运行而无需考虑底层平台, 就是因为有Java虚拟机(JVM)实现了程序与操作系统的分离,从而实现了Java 的平台无关性。
下面我们从JVM的基本概念和运过程程这两个方面入手来对它进行深入的研究。
2.JVM基本概念
(1) 基本概念:
JVM是可运行Java代码的假想计算机 ,包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆 和 一个存储方法域。JVM是运行在操作系统之上的,它与硬件没有直接的交互。
(2) 运行过程:
我们都知道Java源文件,通过编译器,能够生产相应的.Class文件,也就是字节码文件,而字节码文件又通过Java虚拟机中的解释器,编译成特定机器上的机器码 。
也就是如下:
① Java源文件—->编译器—->字节码文件
② 字节码文件—->JVM—->机器码
每一种平台的解释器是不同的,但是实现的虚拟机是相同的,这也就是Java为什么能够跨平台的原因了 ,当一个程序从开始运行,这时虚拟机就开始实例化了,多个程序启动就会存在多个虚拟机实例。程序退出或者关闭,则虚拟机实例消亡,多个虚拟机实例之间数据不能共享。
(3) 三种JVM:
① Sun公司的HotSpot;
② BEA公司的JRockit;
③ IBM公司的J9 JVM;
在JDK1.7及其以前我们所使用的都是Sun公司的HotSpot,但由于Sun公司和BEA公司都被oracle收购,jdk1.8将采用Sun公司的HotSpot和BEA公司的JRockit两个JVM中精华形成jdk1.8的JVM。
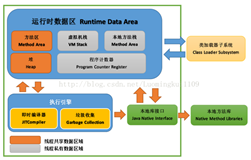
3.JVM的体系结构
|

|
(1) Class Loader类加载器
负责加载 .class文件,class文件在文件开头有特定的文件标示,并且ClassLoader负责class文件的加载等,至于它是否可以运行,则由Execution Engine决定。
① 定位和导入二进制class文件
② 验证导入类的正确性
③ 为类分配初始化内存
④ 帮助解析符号引用.
(2) Native Interface本地接口:
本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序,Java诞生的时候C/C++横行的时候,要想立足,必须有调用C/C++程序,于是就在内存中专门开辟了一块区域处理标记为native的代码,它的具体作法是Native Method Stack中登记native方法,在Execution Engine执行时加载native libraies。
目前该方法使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机,或者Java系统管理生产设备,在企业级应用中已经比较少见。
因为现在的异构领域间的通信很发达,比如可以使用Socket通信,也可以使用Web Service等。
(3) Execution Engine 执行引擎:执行包在装载类的方法中的指令,也就是方法。
(4) Runtime data area 运行数据区:
虚拟机内存或者Jvm内存,冲整个计算机内存中开辟一块内存存储Jvm需要用到的对象,变量等,运行区数据有分很多小区,分别为:方法区,虚拟机栈,本地方法栈,堆,程序计数器。
4.JVM数据运行区详解(栈管运行,堆管存储):
说明:JVM调优主要就是优化 Heap堆 和 Method Area 方法区。

(1) Native Method Stack本地方法栈
它的具体做法是Native Method Stack中登记native方法,在Execution Engine执行时加载native libraies。
(2) PC Register程序计数器
每个线程都有一个程序计算器,就是一个指针,指向方法区中的方法字节码(下一个将要执行的指令代码),由执行引擎读取下一条指令,是一个非常小的内存空间,几乎可以忽略不记。
(3) Method Area方法区
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法如构造函数,接口代码也在此定义。简单说,所有定义的方法的信息都保存在该区域,此区域属于共享区间。
静态变量+常量+类信息+运行时常量池存在方法区中,实例变量存在堆内存中。
(4) Stack 栈
① 栈是什么
栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,它的生命期是跟随线程的生命期,线程结束栈内存也就释放,对于栈来说不存在垃圾回收问题,只要线程一结束该栈就Over,生命周期和线程一致,是线程私有的。
基本类型的变量和对象的引用变量都是在函数的栈内存中分配。
② 栈存储什么?
栈帧中主要保存3类数据:
本地变量(Local Variables):输入参数和输出参数以及方法内的变量;
栈操作(Operand Stack):记录出栈、入栈的操作;
栈帧数据(Frame Data):包括类文件、方法等等。
③ 栈运行原理
栈中的数据都是以栈帧(Stack Frame)的格式存在,栈帧是一个内存区块,是一个数据集,是一个有关方法和运行期数据的数据集,当一个方法A被调用时就产生了一个栈帧F1,并被压入到栈中,A方法又调用了B方法,于是产生栈帧F2也被压入栈,B方法又调用了C方法,于是产生栈帧F3也被压入栈…… 依次执行完毕后,先弹出后进......F3栈帧,再弹出F2栈帧,再弹出F1栈帧。
遵循“先进后出”/“后进先出”原则。
(5) Heap 堆
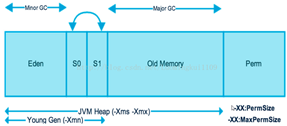
堆这块区域是JVM中最大的,应用的对象和数据都是存在这个区域,这块区域也是线程共享的,也是 gc 主要的回收区,一个 JVM 实例只存在一个堆类存,堆内存的大小是可以调节的。类加载器读取了类文件后,需要把类、方法、常变量放到堆内存中,以方便执行器执行,堆内存分为三部分:

① 新生区
新生区是类的诞生、成长、消亡的区域,一个类在这里产生,应用,最后被垃圾回收器收集,结束生命。新生区又分为两部分:伊甸区(Eden space)和幸存者区(Survivor pace),所有的类都是在伊甸区被new出来的。幸存区有两个:0区(Survivor 0 space)和1区(Survivor 1 space)。当伊甸园的空间用完时,程序又需要创建对象,JVM的垃圾回收器将对伊甸园进行垃圾回收(Minor GC),将伊甸园中的剩余对象移动到幸存0区。若幸存0区也满了,再对该区进行垃圾回收,然后移动到1区。那如果1去也满了呢?再移动到养老区。若养老区也满了,那么这个时候将产生Major GC(FullGCC),进行养老区的内存清理。若养老区执行Full GC 之后发现依然无法进行对象的保存,就会产生OOM异常“OutOfMemoryError”。
如果出现java.lang.OutOfMemoryError: Java heap space异常,说明Java虚拟机的堆内存不够。原因有二:
a.Java虚拟机的堆内存设置不够,可以通过参数-Xms、-Xmx来调整。
b.代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)。
② 养老区
养老区用于保存从新生区筛选出来的 JAVA 对象,一般池对象都在这个区域活跃。
③ 永久区
永久存储区是一个常驻内存区域,用于存放JDK自身所携带的 Class,Interface 的元数据,也就是说它存储的是运行环境必须的类信息,被装载进此区域的数据是不会被垃圾回收器回收掉的,关闭 JVM 才会释放此区域所占用的内存。
如果出现java.lang.OutOfMemoryError: PermGen space,说明是Java虚拟机对永久代Perm内存设置不够。原因有二:
a. 程序启动需要加载大量的第三方jar包。例如:在一个Tomcat下部署了太多的应用。
b. 大量动态反射生成的类不断被加载,最终导致Perm区被占满。
说明:
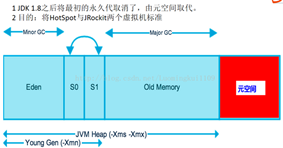
Jdk1.6及之前:常量池分配在永久代 。
Jdk1.7:有,但已经逐步“去永久代” 。
Jdk1.8及之后:无(java.lang.OutOfMemoryError: PermGen space,这种错误将不会出现在JDK1.8中)。
|
|
说明:方法区和堆内存的异议:
实际而言,方法区和堆一样,是各个线程共享的内存区域,它用于存储虚拟机加载的:类信息+普通常量+静态常量+编译器编译后的代码等等,虽然JVM规范将方法区描述为堆的一个逻辑部分,但它却还有一个别名叫做Non-Heap(非堆),目的就是要和堆分开。
对于HotSpot虚拟机,很多开发者习惯将方法区称之为“永久代(Parmanent Gen)”,但严格本质上说两者不同,或者说使用永久代来实现方法区而已,永久代是方法区的一个实现,jdk1.7的版本中,已经将原本放在永久代的字符串常量池移走。
常量池(Constant Pool)是方法区的一部分,Class文件除了有类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池,这部分内容将在类加载后进入方法区的运行时常量池中存放。
5.堆内存调优简介

代码测试:
[java] view plain copy
1. <span style="font-family:'Microsoft YaHei';font-size:14px;">public class JVMTest {
2. public static void main(String[] args){
3. long maxMemory = Runtime.getRuntime().maxMemory();//返回Java虚拟机试图使用的最大内存量。
4. Long totalMemory = Runtime. getRuntime().totalMemory();//返回Java虚拟机中的内存总量。
5. System.out.println("MAX_MEMORY ="+maxMemory +"(字节)、"+(maxMemory/(double)1024/1024) + "MB");
6. System.out.println("TOTAL_ MEMORY = "+totalMemory +"(字节)"+(totalMemory/(double)1024/1024) + "MB");
7. }
8. }</span>
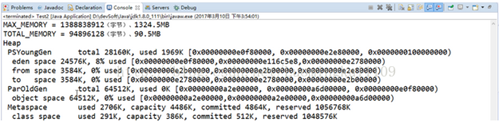
说明:在Run as ->Run Configurations中输入"-XX:+PrintGCDetails"可以查看堆内存运行原理图:
(1) 在jdk1.7中:

(2) 在jdk1.8中:
6.通过参数设置自动触发垃圾回收:
public class JVMTest {
public static void main(String[] args){
long maxMemory = Runtime.getRuntime().maxMemory();//返回Java虚拟机试图使用的最大内存量。
Long totalMemory = Runtime. getRuntime().totalMemory();//返回Java虚拟机中的内存总量。
System.out.println("MAX_MEMORY ="+maxMemory +"(字节)、"+(maxMemory/(double)1024/1024) + "MB");
System.out.println("TOTAL_ MEMORY = "+totalMemory +"(字节)"+(totalMemory/(double)1024/1024) + "MB");
String str = "www.baidu.com";
while(true){
str += str + new Random().nextInt(88888888) + new Random().nextInt(99999999);
}
}
}
在Run as ->Run Configurations中输入设置“-Xmx8m –Xms8m –xx:+PrintGCDetails”可以参看垃圾回收机制原理:

调优
堆大小设置
JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
典型设置:
java -Xmx3550m
-Xms3550m -Xmn2g -Xss128k
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
java
-Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4
-XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxPermSize=16m:设置持久代大小为16m。
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
回收器选择
JVM给了三种选择:串行收集器、并行收集器、并发收集器,但是串行收集器只适用于小数据量的情况,所以这里的选择主要针对并行收集器和并发收集器。默认情况下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行判断。
吞吐量优先的并行收集器
如上文所述,并行收集器主要以到达一定的吞吐量为目标,适用于科学技术和后台处理等。
典型配置:
java
-Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC
-XX:ParallelGCThreads=20
-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
java
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC
-XX:ParallelGCThreads=20 -XX:+UseParallelOldGC
-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集。
java
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
java
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC
-XX:MaxGCPauseMillis=100 -XX:+UseAdaptiveSizePolicy
-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
响应时间优先的并发收集器
如上文所述,并发收集器主要是保证系统的响应时间,减少垃圾收集时的停顿时间。适用于应用服务器、电信领域等。
典型配置:
java
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC:设置年老代为并发收集。测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此时年轻代大小最好用-Xmn设置。
-XX:+UseParNewGC:设置年轻代为并行收集。可与CMS收集同时使用。JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值。
java
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
辅助信息
JVM提供了大量命令行参数,打印信息,供调试使用。主要有以下一些:
-XX:+PrintGC
输出形式:[GC 118250K->113543K(130112K), 0.0094143
secs]
[Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails
输出形式:[GC [DefNew: 8614K->781K(9088K),
0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs]
[GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
-XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用
输出形式:11.851: [GC 98328K->93620K(130112K),
0.0082960 secs]
-XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用
输出形式:Application time: 0.5291524 seconds
-XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用
输出形式:Total time for which application threads were
stopped: 0.0468229 seconds
-XX:PrintHeapAtGC:打印GC前后的详细堆栈信息
输出形式:
34.702: [GC {Heap before gc invocations=7:
def new generation total 55296K, used 52568K [0x1ebd0000,
0x227d0000, 0x227d0000)
eden space 49152K, 99% used [0x1ebd0000, 0x21bce430,
0x21bd0000)
from space 6144K, 55% used [0x221d0000, 0x22527e10,
0x227d0000)
to space 6144K, 0% used [0x21bd0000, 0x21bd0000,
0x221d0000)
tenured generation total 69632K, used 2696K [0x227d0000,
0x26bd0000, 0x26bd0000)
the space 69632K, 3% used [0x227d0000, 0x22a720f8,
0x22a72200, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000,
0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8,
0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00,
0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060,
0x2b972200, 0x2bfd0000)
34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs]
55264K->6615K(124928K)Heap after gc invocations=8:
def new generation total 55296K, used 3433K [0x1ebd0000,
0x227d0000, 0x227d0000)
eden space 49152K, 0% used [0x1ebd0000, 0x1ebd0000,
0x21bd0000)
from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
to space 6144K, 0% used [0x221d0000, 0x221d0000,
0x227d0000)
tenured generation total 69632K, used 3182K [0x227d0000,
0x26bd0000, 0x26bd0000)
the space 69632K, 4% used [0x227d0000, 0x22aeb958,
0x22aeba00, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000,
0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8,
0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0,
0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060,
0x2b972200, 0x2bfd0000)
}
, 0.0757599 secs]
-Xloggc:filename:与上面几个配合使用,把相关日志信息记录到文件以便分析。
常见配置汇总
堆设置
-Xms:初始堆大小
-Xmx:最大堆大小
-XX:NewSize=n:设置年轻代大小
-XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:MaxPermSize=n:设置持久代大小
收集器设置
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseParalledlOldGC:设置并行年老代收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
垃圾回收统计信息
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
并行收集器设置
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
四、调优总结
年轻代大小选择
响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。
吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
年老代大小选择
响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得:
并发垃圾收集信息
持久代并发收集次数
传统GC信息
花在年轻代和年老代回收上的时间比例
减少年轻代和年老代花费的时间,一般会提高应用的效率
吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
较小堆引起的碎片问题
因为年老代的并发收集器使用标记、清除算法,所以不会对堆进行压缩。当收集器回收时,他会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间较小时,运行一段时间以后,就会出现“碎片”,如果并发收集器找不到足够的空间,那么并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出现“碎片”,可能需要进行如下配置:
-XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。
-XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
Redis缓存相关
1. Redis缓存数据持久化的几种方式(RDB和AOF)
2. Redis缓存缓存穿透,缓存击穿,缓存雪崩解决方案
缓存穿透方案:对一个一定不存在数据的key也进行缓存过期时间设置短一些
缓存击穿方案:对一个热点快要过期的key 并发访问可以使用互斥锁(mutex key)、提前使用互斥锁(mutex key)、永远不过期、资源保护(netflix的hystrix)
缓存雪崩方案:设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩可以设置时间时加一个随机值,过期时间的重复率就会降低
分布式事务一致性
两种机制补偿机制和消息机制
列如:银行转账怎么样保证事务一致性
日志分析系统
ELK是一款日志分析系统,它是Logstash+ElasticSearch+Kibana的技术组合,它可以通过logstash收集各个微服务日志,并通过Kibana进行可视化展示,而且还可以对大量日志信息通过ElasticSearch进行全文检索
搭建高可用和高并发系统
先介绍两个概念:高并发和高可用。
高并发>即在单位时间内的并发请求数非常高,因此对网站的吞吐能力和处理能力比较高。例如12306,淘宝等。
高可用>即对网站的稳定性要求比较高,比如不允许停止服务,某台机器出问题后不影响网站的正常访问等。
解决方法:
高并发nginx + redis集群 + 分布式 + 数据库读写分离
高可用 分布式 +微服务 +zookeeper
数据库每日有上亿级数据你们数据库怎么做的
水平分片 垂直分块 详细百度
一个接口有两个实现类,动态装载某一个实现是使用了哪种设计模式,代理模式和装饰模式举例应用场景
单例模式代码实现
线程相关
1.线程提交时公平队列和非公平队列的区别
2.线程同步happen before 的规则
https://blog.csdn.net/ns_code/article/details/17348313
3. 线程中wait 和 notify的方法
4. Java中锁的相关内容
5. 工程中微服务如何保证事物的一致性,同步对象在微服务中怎么用,几个工程都需要访问和修改同一个对象(java后台 和数据库两方面实现)
逻辑题
listA 和listb 分别包含 a,b,c 和 a,c 实现取交集,并集,差集几种方式
HashMap原理
现在我们一步一步来分析put源码。
对key做null检查。如果key是null,会被存储到table[0],因为null的hash值总是0。
key的hashcode()方法会被调用,然后计算hash值。hash值用来找到存储Entry对象的数组的索引。有时候hash函数可能写的很不好,所以JDK的设计者添加了另一个叫做hash()的方法,它接收刚才计算的hash值作为参数。如果你想了解更多关于hash()函数的东西,可以参考:hashmap中的hash和indexFor方法
indexFor(hash,table.length)用来计算在table数组中存储Entry对象的精确的索引。
在我们的例子中已经看到,如果两个key有相同的hash值(也叫冲突),他们会以链表的形式来存储。所以,这里我们就迭代链表。
· 如果在刚才计算出来的索引位置没有元素,直接把Entry对象放在那个索引上。
· 如果索引上有元素,然后会进行迭代,一直到Entry->next是null。当前的Entry对象变成链表的下一个节点。
· 如果我们再次放入同样的key会怎样呢?逻辑上,它应该替换老的value。事实上,它确实是这么做的。在迭代的过程中,会调用equals()方法来检查key的相等性(key.equals(k)),如果这个方法返回true,它就会用当前Entry的value来替换之前的value。
get源码
当你理解了hashmap的put的工作原理,理解get的工作原理就非常简单了。当你传递一个key从hashmap总获取value的时候:
对key进行null检查。如果key是null,table[0]这个位置的元素将被返回。
key的hashcode()方法被调用,然后计算hash值。
indexFor(hash,table.length)用来计算要获取的Entry对象在table数组中的精确的位置,使用刚才计算的hash值。
在获取了table数组的索引之后,会迭代链表,调用equals()方法检查key的相等性,如果equals()方法返回true,get方法返回Entry对象的value,否则,返回null。
要牢记以下关键点:
· HashMap有一个叫做Entry的内部类,它用来存储key-value对。
· 上面的Entry对象是存储在一个叫做table的Entry数组中。
· table的索引在逻辑上叫做“桶”(bucket),它存储了链表的第一个元素。
· key的hashcode()方法用来找到Entry对象所在的桶。
· 如果两个key有相同的hash值,他们会被放在table数组的同一个桶里面。
· key的equals()方法用来确保key的唯一性。
· value对象的equals()和hashcode()方法根本一点用也没有。
Statement, PreparedStatement和CallableStatement的区别
Statement用于执行不带参数的简单SQL语句,并返回它所生成的结果,每次执行SQL豫剧时,数据库都要编译该SQL语句。
Satatement stmt = conn.getStatement();
stmt.executeUpdate("insert into client values("aa","aaa")");
PreparedStatement表示预编译的SQL语句的对象,用于执行带参数的预编译的SQL语句。
CallableStatement则提供了用来调用数据库中存储过程的接口,如果有输出参数要注册,说明是输出参数。
虽然Statement对象与PreparedStatement对象能够完成相同的功能,但是相比之下,PreparedStatement具有以下优点:
1.效率更高。
在使用PreparedStatement对象执行SQL命令时,命令会被数据库进行编译和解析,并放到命令缓冲区,然后,每当执行同一个PreparedStatement对象时,由于在缓存区中可以发现预编译的命令,虽然它会被再解析一次,但是不会被再一次编译,是可以重复使用的,能够有效提高系统性能,因此,如果要执行插入,更新,删除等操作,最好使用PreparedSatement。鉴于此,PreparedStatement适用于存在大量用户的企业级应用软件中。
2.代码可读性和可维护性更好。
下两种方法分别使用Statement和PreparedStatement来执行SQL语句,显然方法二具有更好的可读性。
方法1:
stmt.executeUpdate("insert into t(col1,xol2) values('"+var2+"','"+var2+"')");
方法2:
perstmt = con.prepareStatement("insert into tb_name(col1,col2) values(?,?)");
perstmt.setString(1,var1);
perstmt.setString(2,var2);
3.安全性更好。
使用PreparedStatement能够预防SQL注入攻击,所谓SQL注入,指的是通过把SQL命令插入到Web表单提交或者输入域名或者页面请求的查询字符串,最终达到欺骗服务器,达到执行恶意SQL命令的目的。注入只对SQL语句的编译过程有破坏作用,而执行阶段只是把输入串作为数据处理,不再需要对SQL语句进行解析,因此也就避免了类似select * from user where name='aa' and password='bb' or 1=1的sql注入问题的发生。
CallableStatement由prepareCall()方法所创建,它为所有的DBMS(Database Management System)提供了一种以标准形式调用已存储过程的方法。它从PreparedStatement中继承了用于处理输入参数的方法,而且还增加了调用数据库中的存储过程和函数以及设置输出类型参数的功能。
SQL中inner join、outer join和cross join的区别
2016年07月11日 15:34:34 阅读数:49634更多
个人分类: 数据库
版权声明:欢迎转载,注明出处就好!如果不喜欢请留言说明原因再踩!谢谢,我也可以知道原因,不断进步!! https://blog.csdn.net/Scythe666/article/details/51881235
缺省情况下是inner join,开发中使用的left join和right join属于outer join,另外outer join还包括full join.下面我通过图标让大家认识它们的区别。
现有两张表,Table A 是左边的表。Table B 是右边的表。其各有四条记录,其中有两条记录name是相同的:
1.INNER JOIN 产生的结果是AB的交集
SELECT * FROM TableA INNER
JOIN TableB ON TableA.name = TableB.name
2.LEFT [OUTER] JOIN 产生表A的完全集,而B表中匹配的则有值,没有匹配的则以null值取代。
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name =
TableB.name
3.RIGHT [OUTER] JOIN 产生表B的完全集,而A表中匹配的则有值,没有匹配的则以null值取代。
SELECT * FROM TableA RIGHT OUTER JOIN TableB ON TableA.name = TableB.name
图标如left join类似。
4.FULL [OUTER] JOIN 产生A和B的并集。对于没有匹配的记录,则会以null做为值。
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name
你可以通过is NULL将没有匹配的值找出来:
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name =
TableB.name
WHERE TableA.id IS null OR TableB.id IS null
5. CROSS
JOIN 把表A和表B的数据进行一个N*M的组合,即笛卡尔积。如本例会产生4*4=16条记录,在开发过程中我们肯定是要过滤数据,所以这种很少用。
SELECT * FROM TableA CROSS JOIN TableB
相信大家对inner join、outer join和cross
join的区别一目了然了。
Java相关
Java GC机制(重要程度:★★★★★)
主要从三个方面回答:GC是针对什么对象进行回收(可达性分析法),什么时候开始GC(当新生代满了会进行Minor GC,升到老年代的对象大于老年代剩余空间时会进行Major GC),GC做什么(新生代采用复制算法,老年代采用标记-清除或标记-整理算法),感觉回答这些就差不多了,也可以补充一下可以调优的参数(-XX:newRatio,-Xms,-Xmx等等)。详细的可以看我另一篇博客(Java中的垃圾回收机制)。
如何线程安全的使用HashMap(重要程度:★★★★★)
作为Java程序员还是经常和HashMap打交道的,所以HashMap的一些原理还是搞搞清除比较好。这个问题感觉主要就是问HashMap,HashTable,ConcurrentHashMap,sychronizedMap的原理和区别。具体的可以看我另一篇博客(如何线程安全的使用HashMap)。
HashMap是如何解决冲突的(重要程度:★★★★☆)
其实就是链接法,将索引值相同的元素存放到一个单链表里。但为了解决在频繁冲突时HashMap性能降低的问题,Java 8中做了一个小优化,在冲突的元素个数超过设定的值(默认为8)时,会使用平衡树来替代链表存储冲突的元素。具体的可以看我另一篇博客(Java 8中HashMap和LinkedHashMap如何解决冲突)。
Java创建对象有哪几种(重要程度:★★★★☆)
这个问题还算好回答,大概有四种—new、工厂模式、反射和克隆,不过这个问题有可能衍生出关于设计模式,反射,深克隆,浅克隆等一系列问题。。。要做好准备~
参考资料:
设计模式Java版
Java反射详解
深克隆与浅克隆的区别
注解(重要程度:★★★☆☆)
如果简历中有提到过曾自定义过注解,还是了解清楚比较好。主要是了解在自定义注解时需要使用的两个主要的元注解@Retention和@Target。@Retention用来声明注解的保留策略,有CLASS,RUNTIME,SOURCE三种,分别表示注解保存在类文件,JVM运行时刻和源代码中。@Target用来声明注解可以被添加到哪些类型的元素上,如类型,方法和域等。
参考资料:
Java注解
异常(重要程度:★★★☆☆)
一道笔试题,代码如下,问返回值是什么。
|
1 2 3 4 5 6 7 8 9 10 11 |
|
主要的考点就是catch中的return在finally之后执行
但是会将return的值放到一个地方存起来,所以finally中的ret=2会执行,但返回值是1。
参考资料:
深入理解Java异常处理机制
Java异常处理
悲观锁和乐观锁区别,乐观锁适用于什么情况(重要程度:★★★★☆)
悲观锁,就是总觉得有刁民想害朕,每次访问数据的时候都觉得会有别人修改它,所以每次拿数据时都会上锁,确保在自己使用的过程中不会被他人访问。乐观锁就是很单纯,心态好,所以每次拿数据的时候都不会上锁,只是在更新数据的时候去判断该数据是否被别人修改过。
大多数的关系数据库写入操作都是基于悲观锁,缺点在于如果持有锁的客户端运行的很慢,那么等待解锁的客户端被阻塞的时间就越长。Redis的事务是基于乐观锁的机制,不会在执行WATCH命令时对数据进行加锁,只是会在数据已经被其他客户端抢先修改了的情况下,通知执行WATCH命令的客户端。乐观锁适用于读多写少的情况,因为在写操作比较频繁的时候,会不断地retry,从而降低性能。
参考资料:
关于悲观锁和乐观锁的区别
乐观锁和悲观锁
单例模式找错误(重要程度:★★★★☆)
错误是没有将构造函数私有化,单例还是比较简单的,把它的饿汉式和懒汉式的两种实现方式看明白了就可以了。
单例模式
__
Spring相关
关于Spring的问题主要就是围绕着Ioc和AOP,它们真是Spring的核心啊。
Spring Bean的生命周期(重要程度:★★★★★)
就不写我那么low的回答了,直接看参考资料吧。
参考资料:
Spring
Bean的生命周期
Top 10 Spring Interview Questions Answers J2EE
Spring中用到的设计模式(重要程度:★★★★★)
工厂模式:IOC容器
代理模式:AOP
策略模式:在spring采取动态代理时,根据代理的类有无实现接口有JDK和CGLIB两种代理方式,就是采用策略模式实现的
单例模式:默认情况下spring中的bean只存在一个实例
只知道这四个。。。。
参考资料:
Design Patterns Used in Java Spring Framework
讲一讲Spring IoC和AOP(重要程度:★★★★★)
IoC的核心是依赖反转,将创建对象和对象之间的依赖管理交给IoC容器来做,完成对象之间的解耦。
AOP主要是利用代理模式,把许多接口都要用的又和接口本身主要的业务逻辑无关的部分抽出来,写成一个切面,单独维护,比如权限验证。这样可以使接口符合“单一职责原则”,只关注主要的业务逻辑,也提高了代码的重用性。
AOP的应用场景(重要程度:★★★★☆)
权限,日志,处理异常,事务等等,个人理解就是把许多接口都要用的又和接口本身主要的业务逻辑无关的部分抽出来,写成一个切面,单独维护,比如权限验证。这样可以使接口符合“单一职责原则”,只关注主要的业务逻辑,也提高了代码的重用性。
Spring中编码统一要如何做(重要程度:★★★☆☆)
配置一个拦截器就行了
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
数据库相关
Mysql索引的内部结构(重要程度:★★★★☆)
B+树,三层,真实的数据存储在叶子节点
参考资料:
MySQL索引原理及慢查询优化
如果一个SQL执行时间比较长怎么办(重要程度:★★★★☆)
可以利用pt-query-digest等工具分析慢查询日志,也可以用explain查看SQL的执行计划。具体可看我的另一篇博客MySQL调优
如果一张表中有上千万条数据应该怎么做分页(重要程度:★★★☆☆)
肯定不能直接limit,offset,主要就是要想办法避免在数据量大时扫描过多的记录。具体可看我的另一篇博客【译】优化MySQL中的分页
什么样的列适合加索引,如果一个列的值只有1和2,那么它适合加索引么(重要程度:★★★☆☆)
- 在where从句,group by从句,order by从句,on从句中出现的列
- 索引的字段越小越好
- 在建立联合索引时,离散度大的列放大联合索引的前面
只有1和2不适合建索引
Redis相关
Redis提供哪几种数据结构(重要程度:★★★★★)
一共有5种,字符串,散列,列表,集合,有序集合。
参考资料:
Redis中文官网
Redis支持集群么,从哪个版本开始支持集群的(重要程度:★★☆☆☆)
支持集群,从3.0版本开始。当然面试时我也没记住版本。。。
Redis集群中,如何将一个对象映射到对应的缓存服务器(重要程度:★★★★☆)
一般就是hash%N,就是用对象的hash值对缓存服务器的个数取余
接上个问题,缓存集群中如果新增一台服务器,怎么才能不影响大部分缓存数据的命中?(重要程度:★★★★☆)
其实就是一致性Hash算法。以前有看过,可惜面试的时候脑袋就空了,只记得一个环,果然还是要实践啊。
参考资料:
Consistent
Hashing
五分钟理解一致性哈希算法(consistent hashing)
项目中具体是怎样使用Redis的(重要程度:★★★★☆)
根据实际情况回答吧。。。。我是主要做权限控制时用到了Redis,将用户Id和权限Code拼接在一起作为一个key,放到Redis的集合中,在验证某一用户是否有指定权限时,只需验证集合中是否有用户Id和权限Code拼接的key即可
算法相关
判断一个数字是否为快乐数字(重要程度:★☆☆☆☆)
leetcode第202题
链接
给定一个乱序数组和一个目标数字 找到和为这个数字的两个数字 时间复杂度是多少(重要程度:★☆☆☆☆)
leetcode第一题
链接
如何判断一个链表有没有环(重要程度:★☆☆☆☆)
用快慢指针
删除字符串中的空格 只留一个(重要程度:★☆☆☆☆)
这个比较简单。。。。
二叉树层序遍历(重要程度:★★☆☆☆)
利用队列就可以了
地铁票价是如何计算的(重要程度:★★☆☆☆)
不知道正确答案,感觉是图的最短路径算法相关的。
Elasticsearch相关
为什么要用Elasticsearch(重要程度:★★★★☆)
其实对Es的了解还是比较少的,因为没做多久就去写坑爹代理商了。个人觉得项目中用Es的原因一是可以做分词,二是Es中采用的是倒排索引所以性能比较好,三是Es是个分布式的搜索服务,对各个节点的配置还是很简单方便的
Elasticsearch中的数据来源是什么,如何做同步(重要程度:★★★★☆)
数据是来自其他部门的数据库,会在一开始写python脚本做全量更新,之后利用RabbitMQ做增量更新,就是数据更改之后,数据提供方将更改的数据插入到指定消息队列,由对应的消费者索引到Es中
接上个问题,利用消息队列是会对对方代码造成侵入的,还有没有别的方式(重要程度:★★★☆☆)
还可以读MySQL的binlog
发散思维的题
以下题都是没有正确答案的,不知道是想考思维,还是压力面试,就只写题目,不写回答了。。。
画一下心中房树人的关系(重要程度:★☆☆☆☆)
给你一块地建房如何规划(重要程度:★☆☆☆☆)
估计二号线有几辆车在运行(重要程度:★☆☆☆☆)
其他
Thrift通信协议(重要程度:★★★☆☆)
这个问题被问了两遍,然而现在还是不知道。。。什么东西都不能停留在只会用的阶段啊~
git相关(重要程度:★★★★★)
一些git相关的问题,比如如何做分支管理(git flow),rebase和merge的区别(merge操作会生成一个新的节点)等等。。。
如何学习一门新技术(重要程度:★★★☆☆)
google+官网+stackoverflow+github
比较爱逛的网站和爱看的书(重要程度:★★★☆☆)
根据实际情况回答吧。。。
了不了解微服务(重要程度:★★☆☆☆)
简单了解过。。。
参考资料:
基于微服务的软件架构模式
针对简历中的项目问一些问题(重要程度:★★★★★)
就是根据简历上的项目问一些东西,比如权限控制是怎么做的,有没有碰到过比较难解决的问题之类的,不具体列举了,只要简历上的内容是真实的基本都没啥问题
为什么要离职(重要程度:★★★★★)
被问了n遍,挺不好回答的一个问题,毕竟不算实习期工作还没满一年,这个时候跳槽很容易让人觉得不安稳。。。。
对公司还有什么问题(重要程度:★★★★★)
基本每轮面试结束都会问的一个问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号