浅谈创建对象的两种方式
经常使用IDE不容易看出编译和运行的明显区别,因为像eclipse这样的开发工具会自动进行编译。当你创建一个类的时候就编译成一个class文件,在此基础上做的修改保存后又会触发一次编译。所以我们可以借助记事本来看看什么是运行时调用,来体验一下创建对象的两种方式。
首先来看一个例子,有以下的接口和两个实现类:
public interface Fruit {
public void color();
}
public class Apple implements Fruit {
@Override
public void color() {
System.out.println("red");
}
}
public class Banana implements Fruit {
@Override
public void color() {
System.out.println("yello");
}
}1.使用new来创建一个对象。
//存在的Apple类
public class Test {
public static void main(String[] args) {
Fruit f1 = new Apple();
f1.color();
}
}完美运行:

//使用一个不存在的pear类
public class Test {
public static void main(String[] args) {
Fruit f2 = new Pear();
}
}
2.使用反射来创建对象。
//存在的Banana类
public class Test {
public static void main(String[] args) {
try {
Fruit f = (Fruit) Class.forName("Banana").newInstance();
f.color();
} catch (Exception e) {
e.printStackTrace();
}
}
}运行时发现才发现Banana类不存在,所以抛出了异常:
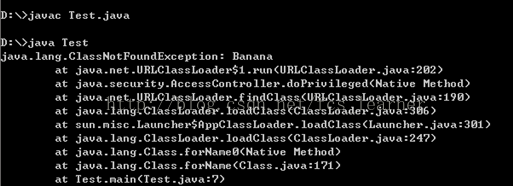
通过查看发现反射不会根据需要去逐个编译类(下面的Banana就没有替我们编译):

这时我们手动编译Banana类,然后再运行Test:

我们再使用反射来调用不存在的pear:
public class Test {
public static void main(String[] args) {
try {
Fruit f = (Fruit) Class.forName("Pear").newInstance();
f.color();
} catch (Exception e) {
e.printStackTrace();
}
}
}同样Test类编译通过,运行时才发现要加载的class文件不存在:
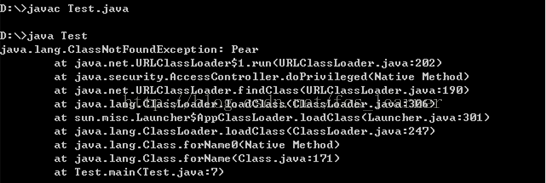
可以看出,使用反射在编译阶段不会报错,说明它是运行时调用。它假设所有的相关类都存在,所以需要捕获找不到类的异常。
使用new对象的方法来创建实例,编译器会根据需要自动为我们编译相关类,并在运行时加载这些类,编译器在编译时打开和检查相关class文件。而对于反射机制来说,class文件在编译时是不可获取的,所以在运行时打开和检查.class文件。
在这里是否会产生疑问:
New一个对象和使用反射的newInstance()究竟有什么区别?
使用new时是一个连贯的动作,加载类并完成后续的操作。而使用newInstance()时必须确保类已经加载,并且类已经链接了(即为静态域分配存储空间,并且如果必须的话将解析这个类创建的对其他类的所有引用)。别看分开了显的麻烦,我们却可以从中获得好处,那就是在Class.forName()上做文章,这里就变得更灵活了。我们可以创建一个接口,然后动态地传入实现了接口的类的全限定名,这时候只要有它的.class文件就可以创建它的对象。这样程序的可扩展性大大增强。比如我们更新一个软件通常就是这种原理,我们必须一开始做好长远的打算,埋下伏笔。在框架中更是大量运用这种方法,因为框架必然强调通用性和可扩展性。
所以说,存在即合理,使用时要结合实际来选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号