python3-字符编码
tips:
一直被字符编发困扰,研究了一下,搞清楚了几个概念,也明白了之前的一些疑问,现在做个简单记录,可做参考,不适合系统学习字符编码。
ascii:占一个字节,英文字母及数字
Unicode:两个字节,万国码
utf-8:可变字节
字节码:一般每个字节都用十六进制来表示的,如“我爱你”用’utf-8‘转成字节码为:b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0'
字节码转二进制:把每个字节的十六进制转成二进制就好了(转码都是一一对应的,要一个一个转,没必要)
在python3中,默认内存中为Unicode编码。
字符串转字节码:用encode,指定’utf-8'字符集。
字节码转字符串:用decode,也指定’utf-8'字符集。
注意:当英文转成字节码时,b''后面还是英文,当中文转成字节码时,b''后面显示十六进制的字节码。
a='love'
a=a.encode('utf-8')
a
b'love'
b='爱'
b=b.encode('utf-8')
b
b'\xe7\x88\xb1'
b=b.decode('utf-8')
b
'爱'
encode就像加密,decode就像解密,应用的时候一定注意,用什么加密就用什么解密,所以同一字符串用不同字符集转成的字节码也不同。
补充:
1、python3内存中默认为unicode编码
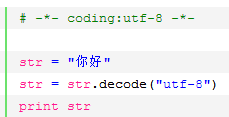
2、python2默认为ascii编码,所以如果定义a='汉字',直接打印会报错,改成如下图,指定字符集,打印前decode
3、查整数对应的unicode字符,查汉字对应的整数
python2有unichr(),python3默认就是unicode,所以不用unichr()方法
>>> chr(28879)'烏'>>> ord('一')19968
4、因为默认就是unicode,unicode是有汉字的,所以直接定义为汉字,打印也不会报错。
不过看到的虽然是汉字,如果要写到文档中不进行utf-8转码的话,打开文档会乱码。(好像默认进行utf-8转码)

5、字符串前面的 u
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。在Python3中,所有的字符串都是Unicode字符串,所以字符串前面不需要加u也是unicode存储
字符串前面的 r
原始字符串,转移符等无效
6、bytes类型和string类型
bytes是比特流,也就是字节码,2进制串,我们通常表示为16进制
string是字符串
encode()是字符串的方法,decode()是bytes类型的方法,指定字符集后相互转换
>>> b='啊'.encode('utf8')>>> bb'\xe5\x95\x8a'>>> type(b)<class 'bytes'>
7、我们看到的任何字(汉字韩语日语)都有它的编码方式,windows默认为gbk,linux默认为utf-8,python默认为unicode,一个文档以什么编码方式存,就以什么方式打开。
8、同一个汉字,用不同字符集编码的字节码都不同
>>> '哈'.encode('unicode-escape')b'\\u54c8'>>> '哈'.encode('utf-8')b'\xe5\x93\x88'>>> '哈'.encode('gbk')b'\xb9\xfe'


 浙公网安备 33010602011771号
浙公网安备 33010602011771号