Hive存储格式之ORC File详解,什么是ORC File
概述
本文基于上一篇文章 Hive存储格式之RCFile详解,RCFile的过去现在未来 撰写,读过上一篇文章,则更好理解以下内容。
2013年,HortonWorks在RCFile的基础上开发出了ORC File(Optimied Row Columnar),在2015年成为Apache的顶级项目。以下简称ORC。
RCFile在被Facebook开源后,作为Hive之中典型的列存储模型被广泛使用,相比于之前的存储格式有很大的优势,但是同样RCFile仍然有值得改进的地方。
ORC 做了相关优化,在Hive的使用中有更好的表现,它支持复杂数据类型、ACID支持及内置索引支持,非常适合海量数据的存储。
ORC并不是一个单纯的列式存储格式,它也遵循了先水平分区,再垂直分区的理念,采用混合存储结构。
除了Hive,目前也被Spark SQL,Flink,Presto,Impala等查询引擎支持。
我上一篇中提及RCFile的两个优化方向:
- 不同数据类型的列使用不同的压缩方案(Facebook论文指出的优化方向-未做)
- 全局检索性能查,提供更合理快速的检索功能
ORC相对于RCFile提供了更优的解决方案:
- 列数据的类型感知:与RCFile之前未对列数据都统一为BLOB(binary large object-二进制大对象)数据不同,ORC可以感知列的数据类型,做出更为合理的数据压缩选择。
- 嵌套数据类型支持:ORC可以在列数据之中插入Struct,Union,List,Map等数据,让数据操作更加灵活,也更加适合非结构化数据的存储与处理。
- 谓词下推:这个算是RCFile原先功能的补强,在元数据层面增加了很多内容,来利用谓词下推加速处理的过程。ORC自己称之为轻量级索引,其实就是一些相较于RCFile更为详细的统计数据。
- 文件可切分:文件可切分,在Hive中使用ORC作为表的文件存储格式,不仅可以节省HDFS的存储资源,查询任务的输入数据量减少,使用的MapTask也就减少了。
- 内存管理:提供了一个memory manager来管理内存使用情况。
接下来我们通过以下几部分来完整的理解一下什么是ORC。
文件存储结构
ORC文件是以二进制的方式存储的,不可以直接读取,但由于ORC的自描述特性,其读写不依赖于 Hive Metastore 或任何其他外部元数据。本身存储了文件数据、数据类型及编码信息。因为文件是自包含的,所以读取ORC文件数据无需考虑用户使用环境。
由于ORC的元数据使用Protocol Buffers序列化,添加新字段不会破坏原有的数据结构。
如下图所示,ORC引入了三个新的组件。
-
Stripe
-
File Footer
-
PostScript
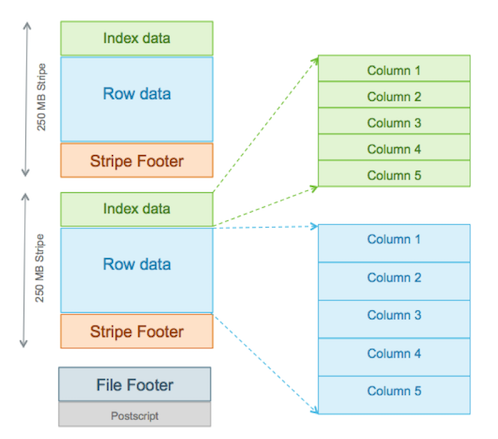
Stripe
ORC的主体由多个Stripe(也成为条带)组成,类似于RCFile中的行组,但是其远远大于行组的4MB,最大可达到250M大小,更大的Stripe使ORC的数据读取更加高效。
每个Stripe彼此独立,这个很好理解,因为每行数据彼此独立,而每行数据不会在多个Stripe中。
在Hive中每个Stripe通常由不同的任务处理。列存储格式的定义特征是每一列的数据是分开存储的,从文件中读取数据的速度应该与读取的列数成正比。
Stripe又包含三个部分:Index Data、Row Data和Stripe Footer。索引和数据部分都按列划分,因此只需要读取所需列的数据。
Index Data
索引数据部分,存储每列的统计数据。Index Data在Stripe的最前面,因为它们只在使用谓词下推或寻找指定行时加载。(这里主要利用索引功能实现的,具体见下文条带级别索引)
Row Data
实际存储数据的单元,利用列存储原理,对不同列可以实现不同的压缩方案,所有的列数据可以组成行数据。
Stripe Footer
存储了每个列的编码,数据流目录与位置。
message StripeFooter {
// the location of each stream
repeated Stream streams = 1;
// the encoding of each column
repeated ColumnEncoding columns = 2;
optional string writerTimezone = 3;
// one for each column encryption variant
repeated StripeEncryptionVariant encryption = 4;
}
两个补充名词
在数据存储和解析的过程中还使用到了两个比较抽象的名词描述,分别为Row Group和Stream,这里单独说明一下。
Row Group
这里的Row Group和RCFile里的行组不是同一个概念,RCFile的行组对标的是ORC中的Stripe。
Row Group是虚拟的(下文有详细介绍),Row Group Index是索引(index)的最小单位,一个Index Data中包含多个行组。默认值为 10000 个值。每一个Row Group Index中有多少条记录在文件的Footer中存储。
Stream
本节以上部分是Stripe的逻辑结构,具体数据存储还有更细粒度的单位存在,那就是Stream。在ORC文件中,每一列都存储在多个Stream中,这些Stream在文件中彼此相邻存储。Stream保存了用户真正关心的业务数据内容。
这也是ORC列式存储的根本所在:正如开头的架构图一样,一个大文件由各Stripe分割,每个Stripe负责多个行组,在一个Stripe负责的这多行范围内,各列的数据内容以Stream的形式按列存储。为了描述每个Stream,ORC以字节为单位存储Stream的类型、列ID和Stream的大小。每个Stream中存储内容的详细信息取决于列的类型和编码。也就是说,在一个Stripe中的每一列都可能有多个表示不同信息的Stream,存储内容如下所示:
message Stream {
enum Kind {
// boolean stream of whether the next value is non-null
PRESENT = 0;
// the primary data stream
DATA = 1;
// the length of each value for variable length data
LENGTH = 2;
// the dictionary blob
DICTIONARY_DATA = 3;
// deprecated prior to Hive 0.11
// It was used to store the number of instances of each value in the
// dictionary
DICTIONARY_COUNT = 4;
// a secondary data stream
SECONDARY = 5;
// the index for seeking to particular row groups
ROW_INDEX = 6;
// original bloom filters used before ORC-101
BLOOM_FILTER = 7;
// bloom filters that consistently use utf8
BLOOM_FILTER_UTF8 = 8;
// Virtual stream kinds to allocate space for encrypted index and data.
ENCRYPTED_INDEX = 9;
ENCRYPTED_DATA = 10;
// stripe statistics streams
STRIPE_STATISTICS = 100;
// A virtual stream kind that is used for setting the encryption IV.
FILE_STATISTICS = 101;
}
required Kind kind = 1;
// the column id
optional uint32 column = 2;
// the number of bytes in the file
optional uint64 length = 3;
}
这些不同类型的Stream会分布在ORC文件里的不同部分,每个Stream的数据会根据该列的类型使用特定的压缩算法保存。主要有以下几种(Kind)。首先是下面这5种Stream,出现在各Stripe的Row Data位置,即文章开头架构图的蓝色部分:
- PRESENT:几乎每一列都会使用该Stream,按位标记该值是否为NULL
- DATA:记录数据内容本身。
- LENGTH:记录每个成员的长度,这个是针对string类型的列或者子列才有的。
- DICTIONARY_DATA:对string类型数据采用字典编码以后的内容(该列所有去重值)。
- SECONDARY:和DATA搭配,存储Decimal、timestamp类型的小数部分或者纳秒数部分等。
下面两种Stream出现在Index Data中。
- ROW_INDEX:保存Stripe中每个row group的统计信息和每个row group起始位置信息。
- BLOOM_FILTER:用于记录当前列在该Stripe中每一个row group的布隆过滤器信息,用于谓词下推跳过不用读取的行组。
File Footer
文件页脚包含文件主体的布局,类型架构信息,行数和每个列的统计信息。通过它们可以筛选出需要读取列的数据。
条纹信息
文件的主体被分成stripe。每个stripe都是自包含的,可以仅使用其自己的字节以及文件的页脚和后记来读取。每个stripe包含整行,因此行永远不会跨越stripe边界。
它包含了每一个stripe的长度和偏移量,该文件的schema信息(将schema树按照schema中的编号保存在数组中,如下图)、整个文件的统计信息以及每一个stripe的行数。
列统计
列统计的目标是,对于每一列,记录总数并根据类型记录其他有用字段。对于大多数原始类型,它记录了最小值和最大值;对于数字类型,多了一个总和记录。列统计信息还通过设置 hasNull 标志记录行组内是否有任何空值。ORC 的谓词下推使用 hasNull 标志来更好地支持“IS NULL”查询。
对于整数类型(tinyint、smallint、int、bigint),列统计信息包括最小值、最大值和总和。如果计算的总和存储大于数据本身,则不会记录总和。
message IntegerStatistics {
optional sint64 minimum = 1;
optional sint64 maximum = 2;
optional sint64 sum = 3;
}
对于浮点类型(float、double),列统计信息包括最小值、最大值和总和。如果总和溢出双倍,则不记录总和。
对于字符串,记录最小值、最大值和所有值的长度之和。
对于布尔值,统计信息包括假值和真值的计数。
对于小数,存储最小值、最大值和总和。
日期列将最小值和最大值记录为自 UNIX 纪元(UTC 时间为 1970 年 1 月 1 日)以来的天数。
时间戳列将最小值和最大值记录为自 UNIX 纪元 (1/1/1970 00:00:00) 以来的毫秒数。在 ORC-135 之前,包括本地时区偏移量,它们存储为minimum和 maximum. 在 ORC-135 之后,时间戳调整为 UTC,然后再转换为毫秒并存储在minimumUtc和maximumUtc中。
message TimestampStatistics {
// min,max values saved as milliseconds since epoch
optional sint64 minimum = 1;
optional sint64 maximum = 2;
// min,max values saved as milliseconds since UNIX epoch
optional sint64 minimumUtc = 3;
optional sint64 maximumUtc = 4;
}
二进制列存储所有值的总字节数。
元数据
元数据(Metadata)包括用户元数据和文件元数据,用户元数据通常作为秘钥使用,这里不做阐述了。
文件元数据部分包含条带级别粒度的列统计信息。这些统计信息可以根据每个条带的谓词下推过滤数据。
类型信息
ORC文件中的所有行具有相同的架构,定义的类型是如同下图的嵌套模式,其中复合类型在其下具有子列。

等效的Hive DDL是:
create table orc_temp(
myInt int,
myMap map<string,struct<myStirng:string,myDouble:double>>,
myTime timestamp
)
类型树通过前序遍历被展平到一个列表中,其中每个类型都被分配了下一个id。
复杂数据类型
对于复杂数据类型,比如Map,ORC文件会将一个复杂数据类型字段解析成多个子字段。下表中列举了ORC文件中对于复杂数据类型的解析:
| 数据类型 | 子列 |
|---|---|
| Array | 一个包含所有数组元素的单个子列 |
| Map | 两个子列,一个key子列,一个value子列 |
| Struct | 每一个属性对应一个子列 |
| Union | 每一个属性对应一个子列 |
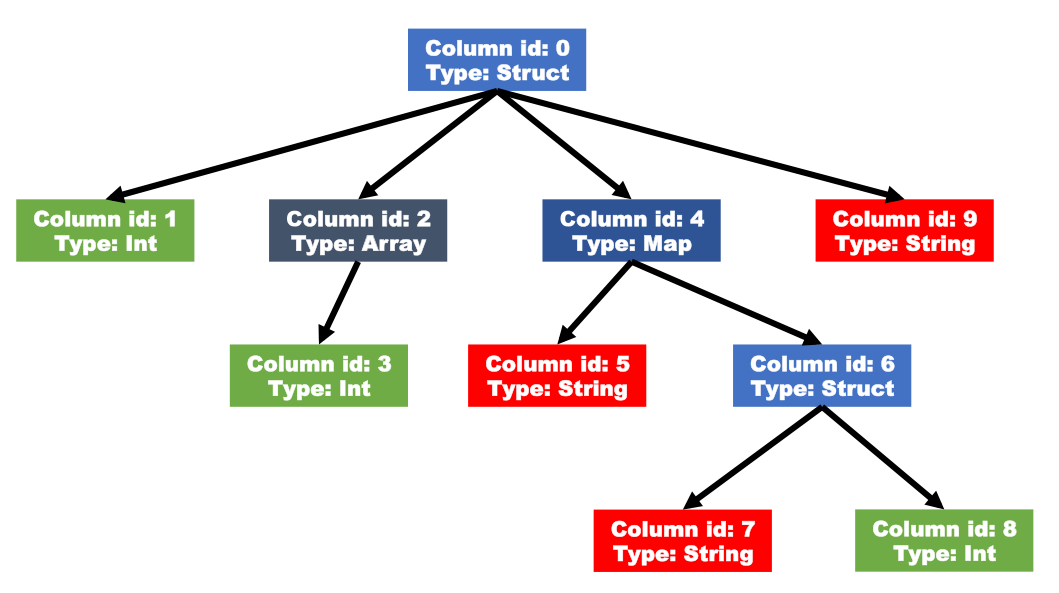
等效的DDL
CREATE TABLE tbl (
col1 Int,
col2 Array<Int>,
col4 Map<String,
Struct<col7:String,col8:Int>
>,
col9 String
)
Postscript
文件的最后一个字节保存着PostScript的长度,它的长度不会超过256字节,PostScript提供了解释文件其余部分的必要信息,包括文件的 Footer 和 Metadata 部分的长度、文件的版本以及使用的一般压缩类型(例如 none、zlib 或 snappy)、文件内部每个压缩块的最大长度(每次分配内存的大小)以及一些版本信息。
数据读取
orc文件结构对数据的查找和索引本质上是三层过滤结合位置指针来实现的:文件级、Stripe级、Row级。这样可以把最终实际要扫描读取的数据减少到部分Stripe的部分Row,不用全扫整个文件。也就是先从文件末尾往前读文件元数据,再跳着读Stripe元数据,最终读需要的Stripe中的部分数据。
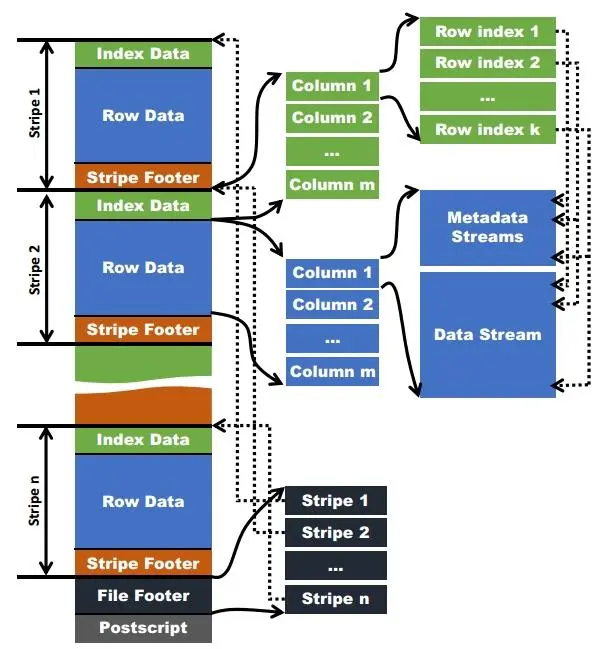
位置指针
在读取ORC文件时,读取器需要知道两种位置,才能执行有效的数据读取操作。
首先,由于条带中的一列具有多个逻辑索引组(Row Group Index),因此ORC文件的读取器需要知道元数据流和数据流中每个索引组的起点。在上图中,指向元数据流和数据流的圆虚线表示这种位置指针。
其次,一个ORC文件可以包含多个Stripe,而这个ORC文件的一个HDFS块可以包含多个Stripe。为了有效地定位Stripe的起点,需要定位Stripe的位置指针。这些指针存储在ORC文件的文件页脚中(圆角虚线指向上图中条纹的起点)。
三层过滤
文件级
在ORC文件的末尾(文件页脚)会记录文件级别的统计信息,会记录整个文件中每列的统计信息。这些信息主要用于查询的优化,也可以为一些简单的聚合查询比如max, min, sum输出结果。
Stripe级
ORC文件会保存每个字段Stripe级别的统计信息,每个条带中的每列的值的统计信息,ORC reader使用这些统计信息来确定对于一个查询语句来说,需要读入哪些Stripe中的记录。例如,如果查询要查找年龄超过 100 岁的人,则 SARG 将为“年龄 > 100”,并且只会读取年龄超过 100 岁的条带。
Row 级
为了进一步的避免读入不必要的数据,在逻辑上将一个column的index(Index Data部分)以一个给定的值(默认为10000,可由参数配置)分割为多个index组(Row Group Index),存储统计信息和行组索引开始的位置。
Hive查询引擎会将where条件中的约束传递给ORC reader,这些reader根据组级别的统计信息,过滤掉不必要的数据。如果该值设置的太小,就会保存更多的统计信息,用户需要根据自己数据的特点权衡一个合理的值。
关于虚拟的Row Group,这10000个值的Row group Index映射到数据里,就是一个个的Row Group。反向看起来好像是Row Group的存在产生了Row group Index。但实际上Row Group是不存在的。为了便于理解,有些文章里也会说在Stripe之下还会有一个Row Group的存在。
数据读取
看了以上三级文件结构,就能很好的理解整个ORC的数据读取流程了。
读取文件元数据:读取 ORC 文件是从尾部开始的。第一次读取16KB的大小,尽量的将Postscript和Footer数据都读入内存。
读取Stripe元数据:处理Stripe时首先从Footer中获取每一个Stripe的起始位置和长度、每一个Stripe的Footer数据(元数据,记录了index和data的的长度)。在初始化阶段获取所有的元数据以后,会得到一个指定读取哪些列的编号构成的Boolean数组。如果不指定则读取所有的列。
读取Row Group级元数据:接下来通过传递SearchArgument参数指定过滤条件,根据元数据首先读取每个stripe中的index信息,而后根据index中的统计信息以及SearchArgument参数读取的row group编号,获取到所要读取数据范围包含了哪些row group,在对应的row group中读取需要的数据。
读取数据处理:经过这两层的过滤,需要读取的数据只是整个Stripe多个小段的区间,而后ORC会尽量合并多个离散的区间尽量减少I/O次数。下一步再根据Index中保存的下一个row group的位置信息开始该Stripe中的下一个需要读取的row group中进行数据读取。

使用ORC文件格式时,用户可使用HDFS的每个block存储ORC文件的一个stripe。对于一个ORC文件来讲,stripe的大小通常须要设置得比HDFS的block小,若是不这样的话,一个stripe就会分别在HDFS的多个block上,当读取这种数据时就会发生远程读数据的行为。若是设置stripe的只保存在一个block上的话,若是当前block上的剩余空间不足以存储下一个strpie,ORC的writer接下来会将数据打散保存在block剩余的空间上,直到这个block存满为止。这样,下一个stripe又会从下一个block开始存储。
因为ORC中使用了更加精确的索引信息,使得在读取数据时能够指定从任意一行开始读取,更细粒度的统计信息使得读取ORC文件跳过整个row group,ORC默认会对任何一块数据和索引信息使用ZLIB压缩(可更改),所以ORC文件占用的存储空间也更小。
索引
ORC文件在Row级过滤中使用的索引具体分为两种。行组索引和布隆过滤器。后者为支持更好的使用谓词下推过滤数据。布隆过滤器流与行组索引交错。这种布局便于在单次读取操作中同时读取布隆过滤器流和行索引流。

行组索引
行组索引(Row Group Index)由每个原始列的 ROW_INDEX 流组成,每个原始列被行组索引覆盖。行组可调节,默认为 10,000 行。存储列的每个流的位置以及该行组的统计信息。
索引流被放置在条带的前面,因为在默认的流式传输情况下,它们不需要被读取。它们仅在使用谓词下推或读者寻找特定行时加载。
message RowIndexEntry {
repeated uint64 positions = 1 [packed=true];
optional ColumnStatistics statistics = 2;
}
message RowIndex {
repeated RowIndexEntry entry = 1;
}
对于具有多个流的列,每个流中的位置序列是连接的。
因为字典是随机访问的,即使只读取部分条带,也必须读取整个字典。
布隆过滤器
从 Hive 1.2.0 开始,Bloom Filters 被添加到 ORC 索引中。谓词下推可以利用布隆过滤器更好地修剪不满足过滤条件的行组。布隆过滤器索引由通过“orc.bloom.filter.columns”表属性指定的每一列的 BLOOM_FILTER 流组成。
布隆过滤器的具体使用参见上篇--什么是谓词下推篇中的列式存储中的谓词下推(RF算法)。
事务支持
在 Hive 中以原子方式向表中添加数据的唯一方法是添加新分区。更新或删除分区中的数据需要删除旧分区并将其与新数据一起添加回来,并且不可能以原子方式进行。
为了数据可靠性得到保证,需要实现保证原子性、一致性、隔离性和持久性的 ACID 事务。ORC支持 ACID 事务,支持流式摄取到 Hive 表中,查询要么看到所有事务,要么看不到任何事务。
HDFS 是一次写入文件系统,而 ORC 是一次写入文件格式,不支持编辑文件。
Hive在 ORC File基础上,基于“base file+delta file”的模型实现了对ACID的支持,即数据首先被写入一个 base file中,之后的修改数据被写入一个 delta file,Hive将定期合并这两个文件。
但需要注意的是, Hive ORC ACID并不是为OLTP场景设计的,它能较好地支持一个事务中更新上百万(甚至更多)条记录,但难以应对一小时内上百万个事务的场景。
压缩
ORC文件使用了一个两级压缩方案。流首先由特定于流类型的数据编码方案进行编码。然后,可以使用一个可选的通用数据压缩方案(zlib 或 snappy)来进一步压缩该流。
上文提到对于一个列,它被存储在一个或多个流中。根据流的类型,我们可以将流分为四种基本类型。根据其类型,每个流有自己的数据编码方案。下面介绍了这四种流的类型。
- 字节流:一个字节流基本上存储一个字节序列,它不编码数据。
- 运行长度字节流:一个运行长度字节流存储一个字节序列。对于一个相同的字节序列,它存储重复的字节和出现的情况。
- 整数流:一个整数流存储一个整数序列。它可以用运行长度编码和增量编码来编码这些整数。整数子序列的特定编码方案是根据其模式确定的。
- 比特流:一个位字段流用于存储一个布尔值的序列。在这个流中,一个位表示一个布尔值。在底层,位字段流由运行长度字节流支持。
对于Int列,将使用一个比特流和一个整数流。比特流用于记录一个值是否为空。整数流用于记录此Int列的整数值。
对于二进制数据,ORC 使用三个流 ,比特流、字节流 和 整数流,它们存储每个值的长度。
对于字符串列,ORC写入器将首先检查使用字典编码是否可以有效地通过评估字典中不同条目的数量与编码值的数量的比率是否大于可配置的阈值(默认阈值为0.8)来有效地存储数据。
如果小于0.8,ORC写入器将使用字典编码方案,该列将存储在一个比特流、一个字节流和两个整数流中。与Int列一样,比特流也用于记录一个值是否为空。字节流用于存储字典。一个整数流用于存储字典中每个词条的长度。第二个整数流用于存储此列的值。
如果字典中不同条目目的数量与编码值的数量大于阈值,ORC编写器将知道有许多不同的值,使用字典编码不能有效地存储数据。因此,它将自动存储此列,而不需要进行字典编码。ORC写入器将使用字节流来存储此字符串列的值,并使用整数流来存储每个值的长度,而不是将字典和将值存储为对字典的索引。
在ORC文件中,可以进一步对ORC文件使用通用的编解码器压缩流(ZLIB、Snappy)。对于一个流,通用编解码器将这个流压缩为多个小压缩单元。压缩单元的默认大小为256KB。
ORC存储格式支持三种通用压缩格式,NONE,ZLIB和snappy压缩,默认为ZLIB压缩,即不设置压缩格式则为ZLIB压缩格式,可以通过"orc.compress"="NONE"来设置其余两种压缩格式。
关于以上四种类型的编码详解,感兴趣的人可以去ORC官网具体查看。
内存管理
当ORC文件的写入器写入数据时,它会缓冲内存中的整个Stripe。因此,ORC写入器的内存占用是Stripe的大小。由于Stripe的默认大小很大,当有许多用户同时写入多个映射或减少任务中的ORC文件时(例如,当用户使用动态分区,并且分区列有许多不同的值时),此任务可能会耗尽内存。为了绑定这些并发写入器的内存消耗,ORC文件中提供了一个内存管理器。在“映射”或“减少”任务中,内存管理器会设置一个阈值,以限制此任务中的写入者可以使用的最大内存量。然后,每个新写入器都以其Stripe大小(已设置的Stripe大小)注册到此内存管理器。
当写入器使用的内存总量(设置的Stripe大小总数)超过内存阈值时,内存管理器将以内存阈值与注册的Stripe大小总数的比值缩小这些写入器中使用的实际Stripe大小。当写入器关闭时,内存管理器将从注册的Stripe大小中减去此写入器的注册Stripe大小。如果注册的总条带大小低于阈值,则所有写入器的实际条带大小将被设置为其原始条带大小。使用这种控制机制,来约束任务中ORC文件的活动写入器的内存。
Hive中使用ORC
Hive使用
在建Hive表的时候指定文件的存储格式。
CREATE TABLE ... STORED AS ORC
ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC
SET hive.default.fileformat=Orc
示例
-- 建表
create table lubian_orc(
id int,
name string,
extra string
) comment 'orc格式测试表'
stored as orc;
-- 写入数据
insert overwrite table lubian_orc
select id,name,extra from lubian_text
大多情况下,还是建议在Hive中将文本文件转成ORC格式(以上),使用程序生成ORC文件,例如Java,属于特殊需求场景,感兴趣可以在orc官网找对应api做一些测试。
Hive参数设置
所有关于ORCFile的参数都是在Hive QL语句的TBLPROPERTIES字段里面出现
| 参数名 | 默认值 | 说明 |
|---|---|---|
| hive.exec.orc.memory.pool | 0.5 | 每个写入任务使用内存最大比例 |
| hive.exec.orc.default.stripe.size | 256M | stripe的默认大小 |
| hive.exec.orc.default.block.size | 25610241024 | orc文件在文件系统中的默认block大小,从hive-0.14开始 |
| hive.exec.orc.dictionary.key.size.threshold | 0.8 | String类型字段使用字典编码的阈值,大于该阈值,不使用字典编码 |
| hive.exec.orc.default.row.index.stride | 10000 | stripe中的分组大小 |
| hive.exec.orc.default.compress | ZLIB | ORC文件的默认压缩方式 |
| hive.exec.orc.skip.corrupt.data | false | 遇到错误数据的处理方式,false直接抛出异常,true则跳过该记录 |
更多参数参考官网
以上,就是关于ORC文件格式的详细说明了,如果觉得不错,点个赞再走吧。
按例,欢迎点击此处关注我的个人公众号,交流更多知识。
后台回复关键字 hive,随机赠送一本鲁边备注版珍藏大数据书籍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号