Hive存储格式之RCFile详解,RCFile的过去现在和未来
我在整理Hive的存储格式和压缩格式,本来打算一篇发出来,结果其中一小节就有很多内容,于是打算写成Hive存储格式和压缩格式系列。
本节主要讲一下Hive存储格式最早的典型的列式存储格式RCFile。
综述
RCFile(Record Columnar File)文件格式是FaceBook开源的一种Hive的文件存储格式,遵循“首先水平分区,然后垂直分区”的设计理念。首先将数据水平分为几个行组,这样每一行数据就可以保证存储在同一个集群节点,然后对每个行组内数据进行垂直划分,按列存储。
下面通过文件存储结构来引入RCFile的详细介绍。文件存储结构主要有行存储结构,列存储结构和混合存储结构。
1.行存储存储结构
行存储(row-store)结构在传统的一刀切的数据库系统 中占主导地位。使用这种结构,关系记录被组织在一个n元存储模型中。一个记录的所有字段都按它们出现的顺序依次填充。记录被连续地放置在一个磁盘页中。下图给出了一个示例,展示了如何在HDFS块中的行存储结构中放置表。
下图为HDFS block中基于行存储示意图
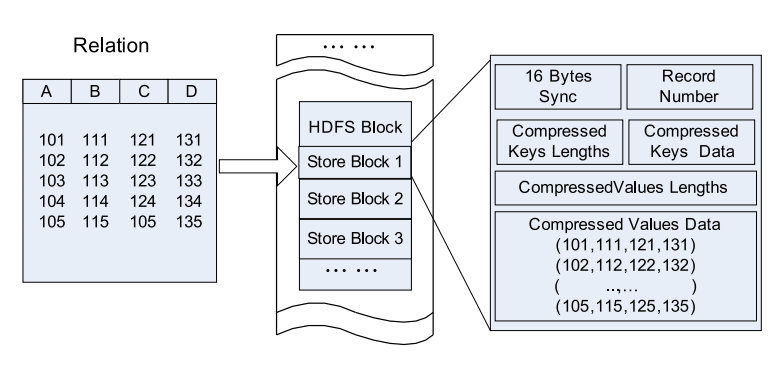
1.1 优点
行存储保证了相同记录的所有字段都在同一个集群节点,具备快速数据加载和动态负载的高适应能力。
1.2 缺点
在当查询仅仅针对所有列中少数几列时,它就不能直接定位到所需列而跳过不需要的列,不太满足快速的查询响应时间的要求。由于混合着不同数据域的列,行存储不易获得一个极高的压缩比。
尽管通过熵编码和利用列相关性的行存储可以有比列存储更好的数据压缩比,但这同样也会因为复杂的数据存储实现导致很高的数据解压缩开销。
2.列式存储存储结构
列式存储(column-group)是基于读取优化的数据仓库系统的面向列的存储模型,在列式存储中,一个关系被垂直划分为几个子集。有两种存储方案。
第一种是每一列放在一个子集中,常见一些实验系统中,我们称之为列存储(column-store)。
第二种是将每个关系的所有列组织成不同的列组,并且通常允许多个列组之间的列重复。Hbase的列簇设计就是一种类似方案,我们称之为列组(column-group)。
也就是说我们通常所说的列式存储其实是列组存储。
如下图,列A和列B存储在同一个列组中,而列C和列D存储在两个独立的列组中。
下图为HDFS block中基于列存储示意图
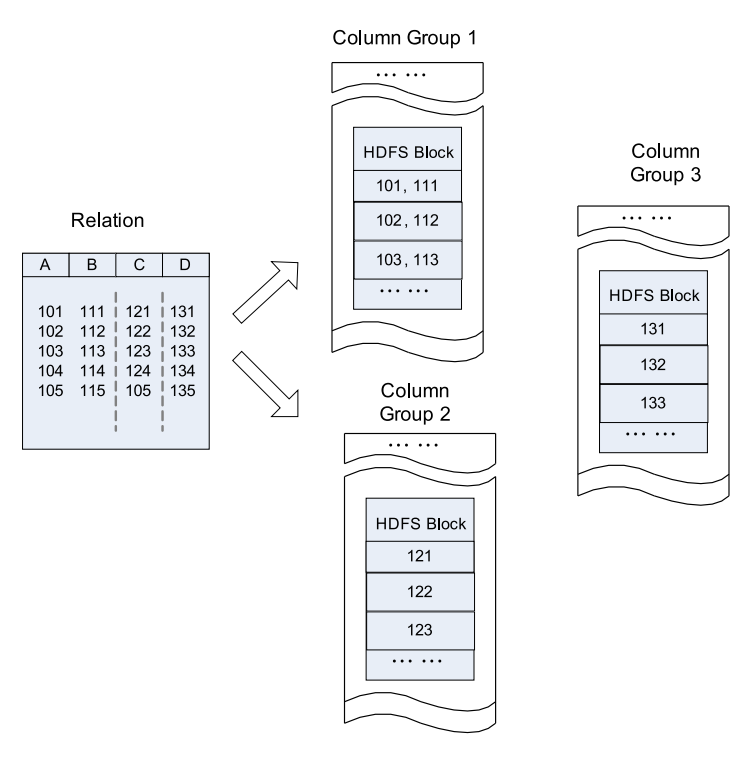
2.1 优点
列式结构使得在查询时能够直接读取需要的列而避免不必要的列的读取。
通过压缩同一数据域内的每个列,可以有一个更好的压缩比。
2.2 缺点
由于元组重构的高开销,不能提供基于Hadoop系统的快速查询处理能力。
缺点详细解释版本:列存储不能保证同一记录中所有的字段都位于同一个集群节点,如上图,一个记录的四个字段存储在三个HDFS块中,它们可能位于不同的节点。因此,查询一条完整的记录将导致多个集群节点之间的网络进行大量的数据传输,必然会慢。集群中过多的网络传输是一个集群增长的瓶颈,如果可能的话应该避免。
列组和物化视图类似(提前加载好查询数据),因此它可以避免记录重构的开销(同一个块中),但是,它不能满足快速适应动态工作负载的要求,除非将所有的查询可能都构建为列组,这会有极高的数据冗余。
关于物化视图,开源数据库postgresql 做了很好的支持,有机会单独开篇讲一讲。
3.RCFile存储思想-混合存储(PAX)
混合存储的核心,先水平分区,再垂直分区。
它采用了一种混合放置结构,旨在提高CPU缓存性能。对于来自不同列多个值的记录,PAX不是将这些字段值放在不同的磁盘页中,而是将它们放在单个磁盘页中,以保存用于记录重构的其他操作。
在每个磁盘页面中,PAX使用页面头来存储一个指向指针,该指针指向一个用来存储属于每个列的所有字段的迷你页面。
3.1 优点
与行存储区一样,PAX对各种动态查询工作负载具有很强的自适应能力。
3.2 缺点
由于PAX主要是为了提高加载数据集的CPU缓存利用率的性能,因此PAX不能直接满足高存储空间利用率和快速查询处理速度的要求,原因有以下三个方面:
-
PAX与数据压缩无关,仅仅提供了一个执行列级数据压缩的可能。而数据压缩对于缓存优化不是必需的,但对于大型数据处理系统非常重要。
-
PAX不能提高I/O性能,因为它不会改变页面的实际内容。这限制了我们实现在大规模增长的数据集上对大量磁盘扫描进行快速查询处理的目标。
-
受传统DBMS引擎中的页面级数据操作的限制,PAX使用一个固定的页面作为数据记录组织的基本单元。通过如此固定的大小,PAX无法有效地存储大型数据处理系统中不同的数据资源类型。
4.RCFile
RCFile应用了PAX中的“首先水平分区,然后垂直分区”的概念。结合了行存储和列存储的优点,从行存储的角度来看,RCFile保证了同一行数据位于同一节点,从列存储的角度来看,RCFile可以利用列级的数据压缩,并跳过不必要的列读取。
那么它是怎么做到的呢?我们且看下文,RCFile的五个特性。
4.1 数据组成
如下图,在每个HDFS块中,RCFile使用行组作为基本单位来组织数据。存储在HDFS块中的所有记录都被划分成了行组。对于一个表,所有的行组大小都相同。一个HDFS块只能有一个或者多个行组。
一个行组由三部分组成,第一部分是行组开头的同步标记,用于指向在一个HDFS块两个连续的行组。第二部分是行组的元数据头,存储此行组中有多少记录,每列有多少字节以及某列中每个字段中有多少字节等信息。第三部分是表数据,实际上是一个列存储区,同一列中所有字段都连续的存储在一起,如下图中,首先存储A列所有数据,然后存储B列所有数据。
HDFS block上RCFile存储示意图
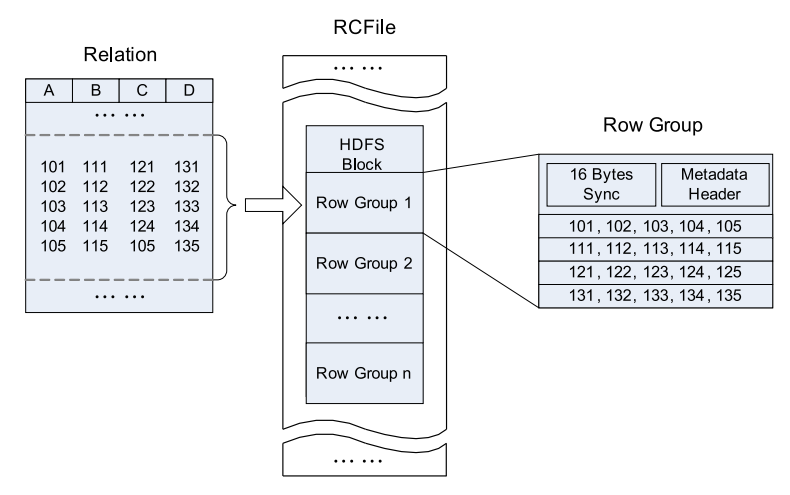
4.2 数据压缩
RCFile在数据压缩上是将每个行组的元数据头部分和表数据部分分别压缩。
元数据头使用RLE算法进行压缩,方便快速查找数据元数据信息。
RLE算法详解,有空写(课本数据结构一书中有介绍)。
表数据部分没有作为一个整体进行压缩,而是将每一列都单独使用Gzip进行压缩,以获得更高的压缩比。
RCFile允许扩展可选择每一列根据不同数据类型和数据分布来使用不同的压缩算法,使其压缩达到最佳,这是RCFile的优化和发展方向。但似乎有点过于笨重。
4.3 数据写入
RCFile存储方式导致了它不支持数据修改,由此Hive使用RCFile存储是不支持数据更新,只支持数据覆盖或者数据追加模式。
4.4 数据读取和懒解压缩
上文提到表数据压缩使用Gzip,Gzip具有高压缩比,但是解压缩也有比较高的开销,那这个是如何避免的呢?
通过只读取给定查询的元数据头和行组中所需要的列(跳过不需要的列)并且结合懒解压缩方式(如果该行列数据没有所需要的字段值,则不解压缩该数据)来获得I/O优势,降低解压缩开销,本质上并没有提升I/O性能,只是少读了。
4.5 行组大小
合适的行组大小能够提升数据读取性能,降低数据存储。显然它由两个因素决定,压缩比和数据读取性能。
大的行组能够提升压缩比,降低表存储,但是可能会损害数据读取性能,小的行组能够提升数据读取性能,但是却损失了存储空间。
RCFile默认设置是4MB,用户可以通过参数调节行组大小。
需要说明的是,RCFile在map阶段从 远端拷贝仍然是拷贝整个数据块,并且拷贝到本地目录后RCFile并不是真正直接跳过不需要的列,并跳到需要读取的列, 而是通过扫描每一个row group的头部定义来实现的,但是在整个HDFS Block 级别的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高。
4.6 Hive使用RCFile示例:
-- 创建RCFile格式表
create table if not exists rcfile_temp(
id int,
name string,
gender int,
remark string
)
row format delimited fields terminated by ','
stored as rcfile;
-- 插入数据(自带压缩格式,就不需要使用压缩参数了)
insert overwrite table rcfile_temp
select * from rcfile_temp;
RCFile还提供了丰富的API,支持开发者进行二次引用,这里就不一一详述了。
下期预告,讲讲和RCFile的优化版ORC File,具体是怎样发扬了RCFile的优点,又是怎样解决了所有列读取的性能问题。
上一篇:什么是hive的静态分区和动态分区,它们又有什么区别呢?hive动态分区详解
按例,我的个人公众号:鲁边社,欢迎关注
鲁边社

后台回复关键字 hive,随机赠送一本鲁边备注版珍藏大数据书籍。
