

System.Collections.Generic代码阅读笔记LinkedList SortedDictionary SortedList SortedSet
代码来自ILSpy分析结果,与实际代码可能有些微出入。手写版http://min.us/mqjnYB
从下面可以看到,LinkedList是双向链表,但是SortedList实际上使用的还是数组。
而SortedDictionary与SortedSet关系非常紧密。
----------------------------------------------------------
----------------------------------------------------------
LinkedList<T> 通过双向链表这种数据结构实现。
关键数据成员:LinkedListNode head;
很显然这是链表的头。每个Node会有Previous以及Next这样的property。
Find()功能通过遍历List实现,所以是O( n )
----------------------------------------------------------
----------------------------------------------------------
Queue<T> 先进先出的队列。
关键数据成员: T[] _array; 毫无疑问,是通过数组来存放数据。
_tail; _head; _size;
有头有尾有大小,基本就是这样。
关键操作Enqueue()入队列 Dequeue()出队列。
----------------------------------------------------------
----------------------------------------------------------
SortedDictionary<T> 键值对字典数据类型,接口是IDictionary<TKey, TValue>。
内部关键数据成员TreeSet< KeyValuePair<TKey, TValue> > _set;
而TreeSet继承了SortedSet,操作基本上都是通过类似这样:第一个值使用Key,第二个值使用Default(TValue) 构造产生,然后调用_set的相关操作。
----------------------------------------------------------
----------------------------------------------------------
SortedList<T> 排序列表
TKey[] keys;
TKey[] values;
_size;
Add(),通过Array.BinarySearch<TKey>找到索引位置,然后进行插入操作。O(log n)。
----------------------------------------------------------
----------------------------------------------------------
另外要说一下,这里面的比较都是使用了IComparer,这实际上使用了设计模式中的策略模式,让用户可以自己定制。默认情况下是使用Comparer<T>.Default.
----------------------------------------------------------
----------------------------------------------------------
SortedSet<T>
关键数据成员:SortedSet<T>.Node root;
插入操作为AddIfNotPresent()这个函数名字已经说明了一切。
内部构造使用的数据结构为红黑树(一种自平衡二叉搜索树),有IsBlack和IsRed,以及Left、Right这些property。
搜索、插入、删除都是O(log n)。
----------------------------------------------------------
另外要注意其中的Reverse()函数,使用了yield return xxx;以及yield break;这两种用法。
----------------------------------------------------------
----------------------------------------------------------
Stack<T>
T[] _array; 后进先出,没啥可说的。
----------------------------------------------------------
HashSet<T>
关键数据成员:
int[] m_buckets;
HashSet<T>.Slot[] m_slots;
----------------------------------------------------------
Slot的定义如下:
internal struct Slot
{
internal int hashCode;
internal T value;
internal int next;
}
搜索或者是插入算法基本上是这个路子:
----------------------------------------------------------
int num = this.InternalGetHashCode(value);
for (int i
= this.m_buckets[num % this.m_buckets.Length] - 1; i >= 0; i
= this.m_slots[i].next)
{
//if (this.m_slots[i].hashCode ==
num && this.m_comparer.Equals(this.m_slots[i].value, value))
…
}
----------------------------------------------------------
这里是搜索,先算出一个哈希值,然后判断在那个桶中,拿到桶里面第一个元素(this.m_slots[i])。
然后通过next这个成员变量来获取下一个索引位置,然后对hash代码以及通过comparer比较。
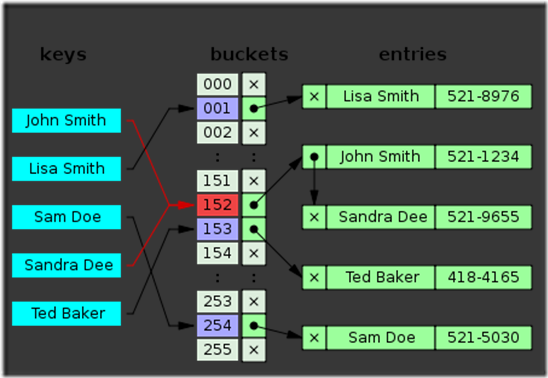
(图片来自http://en.wikipedia.org/wiki/Hash_table)
----------------------------------------------------------
插入操作也差不多,在这里面有一个this.m_freeList(一个int整数)保存了空闲列表位置,
然后把要插入的元素放在这个列表位置,再把m_freelist设置为这个列表位置的next。
因为空间可能不是连续的,所以我们使用的m_freelist这个位置与next未必是紧挨着的关系。
这个空闲列表的next关系维护,是由IncreaseCapacity()函数完成。其实C语言中的malloc函数也可以这样简单实现(当然实际中malloc肯定是复杂的多得多得多)。
----------------------------------------------------------
----------------------------------------------------------
ILSpy是个好东西,最新版本在这里下载http://www.ilspy.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号