Prometheus+Grafana监控宿主机
Prometheus是非常优秀的监控工具,准确的说是一套完整的监控方案。提供了数据收集,存储,处理,加工展示,告警等一系列完整解决方案
关键组件
Prometheus关键组件包括:Prometheus Server,Exporter,可视化组件,Alertmanager四大模块
- Prometheus Server
Prometheus Server负责从Exporter拉取及存储数据,并且提供了一套查询语句(PromQL)供用户使用
- Exporter
Exporter负责收集目标系统的各类性能数据,目标系统可以使host也可以是container容器。并且通过HTTP接口提供给Prometheus Server获取
- Alertmanager
Alertmanager提供了基于监控数据的告警规则,一旦Alertmanager收到告警就会通过预先定义的方式发出告警通知
- 可视化组件
数据的可视化是监控工具至关重要的,Prometheus有自己开发的展示方案,后来被更加优秀的开源产品Grafana替代,Grafana能与Prometheus完美结合提供完美的数据展示能力
实战
1.环境搭建
实例通过prometheus监控两台宿主机,监控host单个层面,也选择适当的DashBoard监控container环境。
本实验将以容器方式运行以下的组件:
(1)Prometheus Server会以容器方式运行在192.168.0.102上
(2)Exporter
-
Node Exporter
负责收集宿主机的硬件以及操作系统的数据,以容器方式运行在宿主机上
-
cAdvisor
负责收集容器数据,以容器方式运行在宿主机上
(3)Grafana:用于展示监控数据
| ip | Node Exporter | cAdvisor | Prometheus Server | Grafana |
|---|---|---|---|---|
| 192.168.0.101 | √ | √ | ||
| 192.168.0.102 | √ | √ | √ | √ |
2.运行Node Exporter
在两个host上执行如下的命令:
docker run -d --name node-exporter -p 9100:9100 \
-v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" \
--restart=always --net="host" \
prom/node-exporter \
--path.procfs /host/proc --path.sysfs /host/sys \
--collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
使用--net="host"目的是为了Node Exporter和Prometheus Server直接通信
运行完上述命令后就可以访问任意ip的:9100来获取收集到的数据了。在浏览器上输入http://192.168.0.101:9100/metrics测试
3.运行cAdvisor
在两个host上运行如下命令启动cAdvisor容器
docker run -v /:/rootfs:ro -v /var/run:/var/run:rw \
-v /sys:/sys:ro -v /var/lib/docker:/var/lib/docker:ro \
-p8080:8080 -t --name cadvisor --net="host" \
google/cadvisor:latest
同样使用--net="host"使cAdvisor与Prometheus Server直接通信
4.运行Prometheus Server
在192.168.0.102主机上执行如下命令启动Prometheus Server
docker run -d -p 9090:9090 \
-v /root/prometheus.yml:/etc/prometheus/prometheus.yml \
--name prometheus --net host \
prom/prometheus
其中prometheus.yml是Prometheus Server的配置文件,如下配置所示,最重要的配置就是最下面的static_config段,它指定了从哪些exporter抓取数据
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090','localhost:8080','localhost:9100','192.168.0.101:9100','192.168.0.101:8080']
打开http://192.168.0.102:9090,点击菜单栏的Status切换到Targets,输出如下:
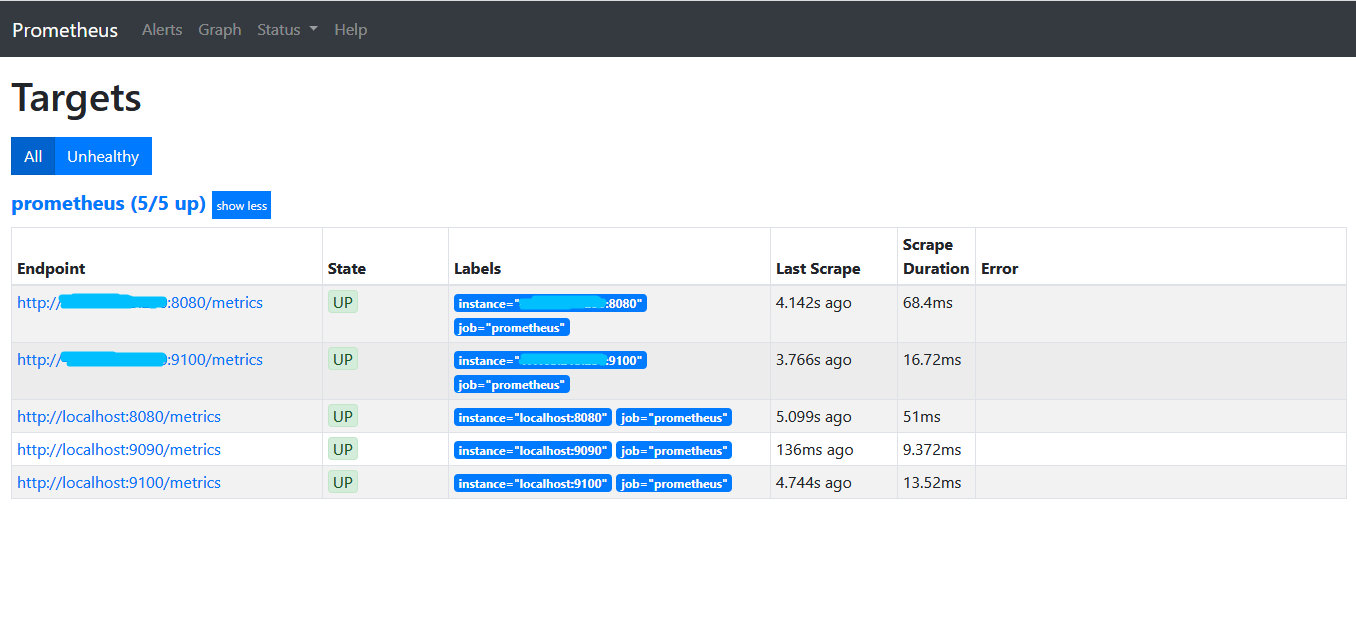
所有State均为UP,表示Prometheus Server正常获取到所有监控数据
5.安装Grafana
在192.168.0.102上执行如下命令运行Grafana
docker run -id -p 3000:3000 \
-e "GF_SERVER_ROOT_URL=http://grafana.server.com" \
-e "GF_SECURITY_ADMIN_PASSWORD=admin@123" \
--net="host" grafana/grafana
这里使用-e"GF_SECURITY_ADMIN_PASSWORD=admin@123"指定Grafana admin用户密码为admin@123
访问http://192.168.0.102:3000进入Grafana界面,Grafana将会引导我们配置Data Source
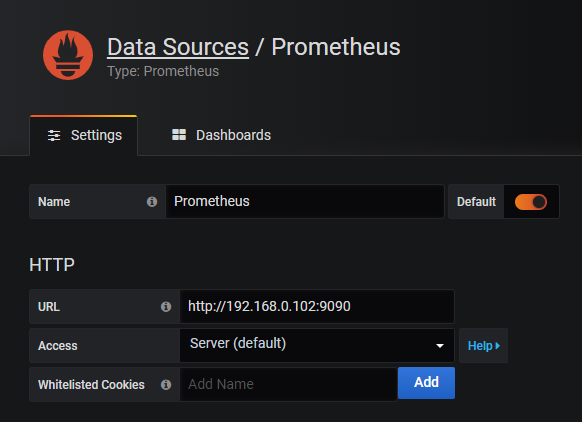
配置完Data Source后需要通过Dashboard展示数据,配置展示数据很困难,可以使用开源社区的力量
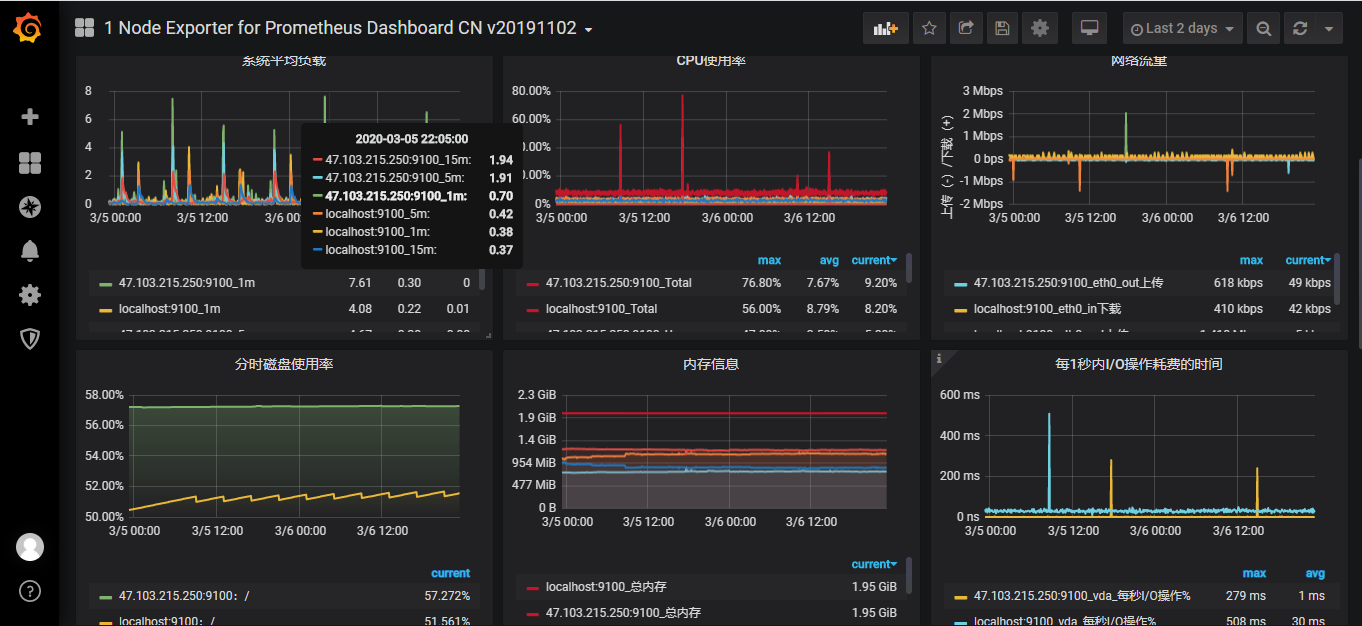
使用现成的Dashboard,下载现成的Dashboard的json文件导入到Grafana就可以展示监控数据了,这里我选择了只监控host的Dashboard

 浙公网安备 33010602011771号
浙公网安备 33010602011771号