
操作系统有意思
操作系统是什么?(不同的视角)
用一篇绝顶体系结构好文来开篇:
https://developer.aliyun.com/article/886483
- 操作系统运行用户程序?
计算机的代码,都是机器码,都由CPU一条一条地执行的,无论是应用程序的代码,还是操作系统的代码,都是机器码,CPU都用一样的方法来执行,这个问题和内核态还是用户态无关。所以,没有“操作系统运行用户程序”的说法。所有的软件指令,都被CPU用一样的方法执行。
- 为什么同是代码,操作系统程序会比一般程序拥有更高的权限?
权限是CPU制造的,CPU只要能保证权限的穿越是单向的,就可以赋予操作系统(的代码)特殊的权限。比如ARM64 CPU启动的时候,(在特定的设计下),工作在权限EL1,这时开始执行的代码就是操作系统的代码了,操作系统执行够了以后,主动把CPU权限降低到EL0(EL1的时候你有权降级,但反过来你就没有权利),这之后执行的代码就在所谓的“用户态"了,由于CPU工作在EL0状态,这些代码的权限就很低,这时如果你执行一个权限比较高的指令(比如访问SCTLR_EL1.A寄存器,又比如x86的int,ARM的SC),CPU就会报错(报错的结果是把权限切换回EL1,并且直接调用操作系统设置好的代码,这样控制权仍是操作系统的),把用户程序的控制权强行取走,赋予给操作系统,这就是为什么操作系统(表现出来)比用户程序拥有更高的权限。
所谓操作系统,用户程序,系统服务,都是我们基于CPU权限人为制造的概念,并非必须存在的客观实体。
- 代码是如何成为操作系统的?
CPU开始加电了,完成内部必要的处理后,就可以从指定的内存地址开始执行代码,这个内存地址称为eset向量,在一些CPU上是固定的,在一些CPU上是可以根据特定的条件变化的(比如把CPU连入电路的时候,给某个引脚加高电平等),但无论如何,反正最终CPU会在某个固定的位置开始执行程序。什么代码放在这里,什么代码就具有最高的执行权限。在DOS+x86的时代,硬件设计者会在这个内存位置上固定焊一个ROM,然后在计算机出厂的时候,固定在这个ROM上烧一段程序,这个程序就称为BIOS,所以,CPU加电后,首先进入的是BIOS程序,然后有BIOS程序根据你是否有磁盘,从磁盘的指定位置上读入代码来执行。所以你要成为操作系统,你就要把你的代码放到磁盘的指定位置,这样这个代码就会具备“操作系统”的控制权。
用户态和内核态
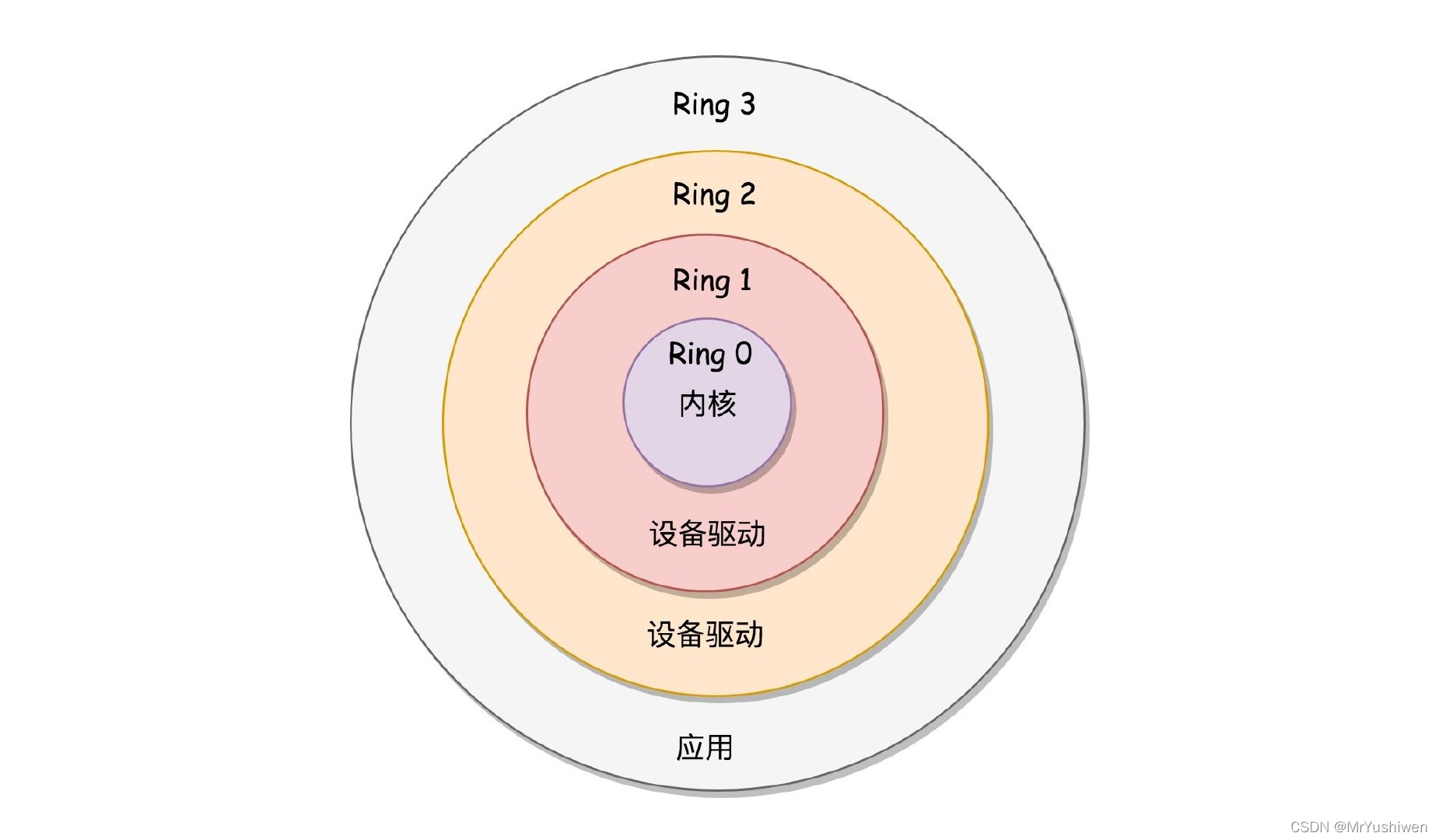
首先我们要知道CPU有四种状态,分别为编号为0(特权最大)到3(特权最小),以及3个受保护的主要资源:内存、I/O端口和执行某些机器指令的能力。
操作系统它基于CPU之上,只用到了CPU的两种状态,一个内核态,一个用户态,内核态运行在CPU的第 0 等级,用户态运行在CPU的第 3 等级。
linux主要是由什么语言写的
Linux操作系统主要包括内核和组件系统。 内核大部分是用C语言写的,但也有部分是用汇编语言写的,因为在对于硬件上,汇编有更好的性能和速度。 而Linux的一些组件系统和附加应用程序大部分用C、C++、Python、perl等语言写的。
众所周知,Linux 是 C 语言的代言人。但是,时代变了,Rust 正在兴起并赢得越来越多人的支持,它开始逐渐扮演 Linux 系统语言的角色。
在今年的 Linux 基金会开源峰会上,Linus Torvalds 提到他希望看到在 Linux Kernel 5.20 中融入 Rust。内核发布周期一般是 9 到 10 周,这意味着我们可能会在 8 月初看到 5.19。然后,如果一切顺利的话,我们将在 10 月下旬或 2022 年 11 月上旬在 5.20 中看到 Rust。而仅在去年,Linus Torvalds 才刚对 Rust 发表过评论,表示自己绝不会推动 Linux 中的 Rust 运动,“Rust 优势的背后肯定存在复杂性,所以我会采取观望的态度,看看这些优势是否真的奏效。”
Rust for Linux要来了,这对我们意味着什么
原文链接: https://www.infoq.cn/article/hrunucgvggwda9jpwajc
操作系统只不过是一个c程序
实践:在 Linux 上用 strace和man指令来理解系统调用,库函数(library routine)
在命令行中输入\(man 2 syscalls可以查看所有的系统调用。你也可以通过\)man 2 read来查看系统调用read()的说明。在这两个命令中的2都表示我们要在2类(系统调用类)中查询 (具体各个类是什么可以通过$man man看到)。
作为linux菜鸟,刚使用linux时,我们都知道可以用man命令来查看linux命令的用法,但是却不知道怎么查看系统调用函数的用法。
方法是: man 2 read 或者是man 3 read。
中间的数字是什么意思呢?是man的分卷号,原来man分成很多部分,分别是:
1 用户命令, 可由任何人启动的。可执行的程序或 shell 命令
2 系统调用, 即由内核提供的函数。系统调用(由内核提供的函数)
3 例程, 即库函数,比如标准C库libc。库调用(在程序的库内的函数)
4 设备, 即/dev目录下的特殊文件。
5 文件格式描述, 例如/etc/passwd。
6 游戏, 不用解释啦!
7 杂项, 例如宏命令包、惯例等。
8 系统管理员工具, 只能由root启动。
9 其他( Linux 特定的), 用来存放内核例行程序的文档。
n 新文档, 可能要移到更适合的领域。
o 老文档, 可能会在一段期限内保留。
l 本地文档, 与本特定系统有关的。
以下是手册的章节编号及其包含的页面类型:
1、可执行程序或者shell命令
2、系统调用(内核可以调用的函数,运行在核心态,内核空间,系统核心可直接呼叫的函数与工具等,通过这个,可以很方便的查到调用某个函数,需要加什么头文件,例如open,write函数)
3、库函数(运行在用户态,用户空间,一些常用的函数与函数库,大部分为c的函数库,例如print,fread)
4、特殊设备(一般是/dev下的各种设备,例如硬盘设备,光盘等)
5、文件格式(说明这个文件中的各个字段的含义,例如/etc/passwd)
6、游戏(保留给游戏使用,由各个游戏自己定义)
7、杂项,例如Linux文件系统,网络协议等,变量说明等
8、系统管路员命令(只有管理员才能使用的命令,例如ifconfig,reboot等)
9、跟kernel内核有关的文件
man 2 kill查看kill命令的系统调用信息
数字:指定从哪本man手册中搜索帮助;
如:man rename 则显示手册1上rename命令的说明
man 2 rename则显示手册2上系统调用rename说明
man -a rename则显示所有的rename的说明
man 2 read
man 2 write
但是
man 2 ping
man 2 traceroute
就不可以,因为她们俩不是系统调用,是shell命令
只能
man 8 ping
man 8 traceroute
https://juejin.cn/post/6844903990883254279
man 3 read
man 3 write
不可以,因为她俩是系统调用而不是库函数
系统调用,shell,glibc和库函数
Linux指令不是系统调用(traceroute),是shell程序
linux shell指令查看指定进程的系统调用:
https://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/strace.html
linux架构:
https://www.cnblogs.com/vamei/archive/2012/09/19/2692452.html
如sys/socket.h这样的c语言库是系统调用吗?
简单来说,软件系统可大概分为 应用层、中间件、操作系统、以及硬件层。
而C标准库处于中间件层次, 操作系统API处于操作系统层。
C标准库是对系统API的封装。
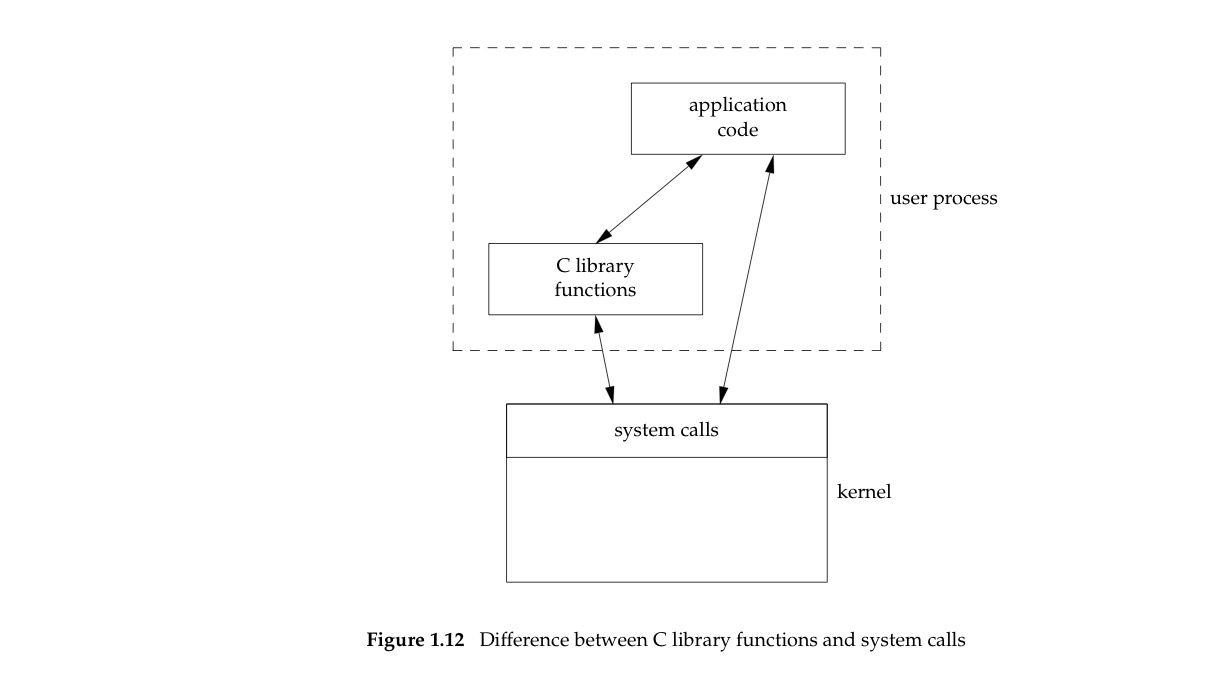
C标准库是在操作系统API上加入独特的算法封装成标准接口的库,使用C标准库可以屏蔽底层实现细节,比如fopen这样的函数,在Windows上通过调用CreateFileEx实现,在linux上通过调用open系统调用实现。不仅是包装,还在上层使用独特的算法提供了用户态缓冲区的功能。
作者:灵剑
链接:https://www.zhihu.com/question/46763480/answer/102676657
题主所说操作系统api,可能是指系统调用。我们通常说来就是open、read、write等等函数,这些man手册第二页中的函数,几乎很多linux C编程的书籍中都会说其是系统调用。
但实际上open、read、write……这些其实是库函数(glibc库函数,不是标准库哈 ,通常是由glibc库中实现的。 不过,我们却也称之为“系统调用”。这是为什么呢?
glibc:
- GNU C库,又名glibc,是GNU计划所实现的C标准库。尽管其名字中带有“C库”,但它现在也直接支持C++(以及间接支持其他编程语言)。它是自由软件基金会(FSF)在20世纪90年代初为他们的GNU操作系统设计的。它为GNU系统,GNU/Linux系统和一些其他的类Unix系统提供了系统核心库。这些库提供了关键的API,包括ISO C11、POSIX.1-2008和BSD所规定的API和一些底层API,包括open、read、write、malloc、printf、getaddrinfo、dlopen、pthread_create、crypt、login、exit等。
原因很简单,系统调用实际可用分为两类:
- 系统调用服务例程(或者叫系统调用函数)
- 系统调用封装函数(或者叫glibc封装函数、系统调用API函数)
严格来讲,系统调用应该是指的内核实现的服务例程。而我们通常所说的open、read、write这些实际上是系统调用服务例程的封装,称之为系统调用的封装函数。它们之间几乎具有一一对应的关系(通常在封装函数前面加上前缀sys_,就是实际的内核服务函数了):
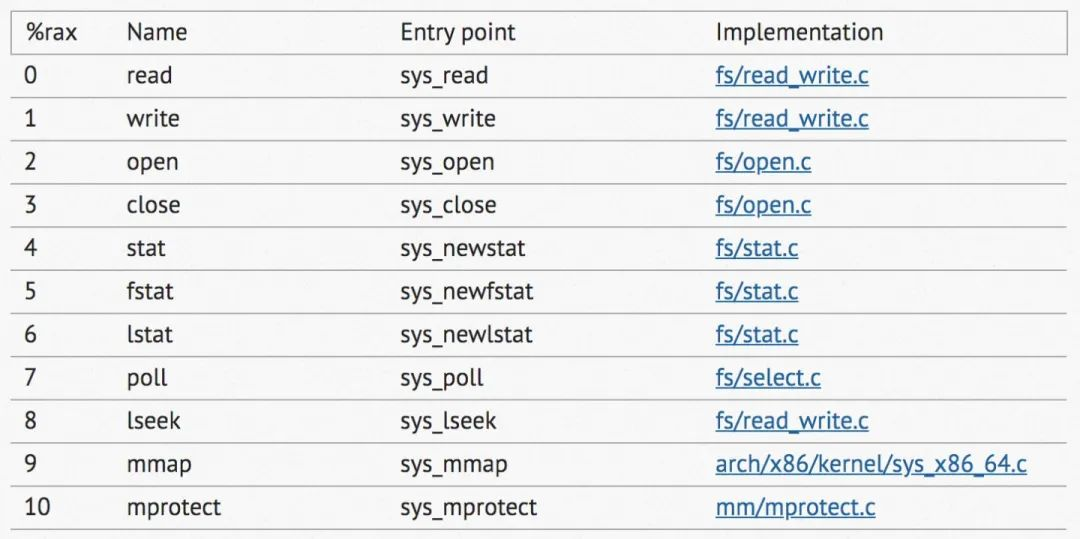
例如open函数实际上是对内核的系统调用函数sys_open的封装。从open到sys_open,并不是普通的C语言中函数调用可以的了,因为它们是运行在不同态之中的。open是用户态,sys_open是内核态。 进程由用户态到内核态的转变是通过软中断来陷入的。
所谓“软中断”就是一条CPU的汇编指令:
- x86架构的软中断:
通常就是128号中断,即为软中断:写作int 0x80; 后来因特尔引入了性能更好的
sysenter指令来完成软中断的工作。
- arm架构的软中断:
就是swi指令
实际上内核的每一个系统调用都有一个系统调用号,即一个数字。在执行软中断的时候,通常是将系统调
用号也作为参数传递过去。内核中有执行系统调用的例程(可能不是C,而是汇编),它通过系统调用号查找系统调用表,然后找到该系统调用(类似函数指针),再去执行它。
实践:运行nginx进程,查看进程pid并用shell指令kill掉这个进程来退出nginx
https://www.cnblogs.com/aimei/p/12859102.html
https://www.myfreax.com/start-stop-restart-nginx/
也可以使用信号机制来控制进程:
中断是什么?为什么ctrl+c可以退出程序?
系统调用是通过中断指令int 0x80来实现的
背景知识
驱动
驱动程序全称设备驱动程序,是添加到操作系统中的特殊程序,其中包含有关硬件设备的信息。此信息能够使计算机与相应的设备进行通信。
中断
触发系统将运行时间由用户态程序交还给内核态的一种方式。
终端
终端
伪终端(pseudo terminal) --> /dev/pts/8
会话
信号
发送给程序的来表示有重要事件发生的软件中断。
系统收到信号后,会把 CPU 时间交由内核态,然后再进行退出程序,挂起,恢复,或自定义操作。
当按下Ctrl-c时发生了什么
根据 setpgrp manual page 的说法,按下 Ctrl-c 后:
终端产生 SIGINT 信号
前台进程组中的所有进程都会接收到 SIGINT 信号然后退出(默认动作)
shell通过调用 waitpid 清理进程表中子进程信息
用户按下Ctrl-C,这个键盘输入产生一个硬件中断。 如果CPU当前正在执行这个进程的代码,则该进程的用户空间代码暂停执行,CPU从用户态切换到内核态处理硬件中断。 终端驱动程序将Ctrl-C解释成一个SIGINT信号,记在该进程的PCB中(也可以说发送了一个SIGINT信号给该进程)。
当某个时刻要从内核返回到该进程的用户空间代码继续执行之前,首先处理PCB中记录的信号,发现有一个SIGINT信号待处理,而这个信号的默认处理动作是终止进程,所以直接终止进程而不再返回它的用户空间代码执行。
注意,Ctrl-C产生的信号只能发给前台进程。一个命令后面加个&可以放到后台运行,这样Shell不必等待进程结束就可以接受新的命令,启动新的进程。Shell可以同时运行一个前台进程和任意多个后台进程,只有前台进程才能接到像Ctrl-C这种控制键产生的信号。前台进程在运行过程中用户随时可能按下Ctrl-C而产生一个信号,也就是说该进程的用户空间代码执行到任何地方都有可能收到SIGINT信号而终止,所以信号相对于进程的控制流程来说是异步(Asynchronous)的。
信号的本质
软中断信号(signal,又简称为信号)用来通知进程发生了异步事件。在软件层次上是对中断机制的一种模拟,在原理上,一个进程收到一个信号与处理器收到一个中断请求可以说是一样的。信号是进程间通信机制中唯一的异步通信机制,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达。进程之间可以互相通过系统调用kill发送软中断信号。内核也可以因为内部事件而给进程发送信号,通知进程发生了某个事件。信号机制除了基本通知功能外,还可以传递附加信息。
信号机制控制nginx进程:
sudo systemctl reload nginx命令将会重新加载Nginx服务。 Nginx也可以由信号直接控制。例如,要重新加载服务,可以运行命令sudo /usr/sbin/nginx -s reload。
https://www.cnblogs.com/aimei/p/12859102.html
进程管理
Windows任务管理器里是进程还是线程?
在任务管理器的进程一栏里,有道词典和有道云笔记就是进程,而在进程下又有着多个执行不同任务的线程。
程序、代码、操作系统、编译器
编译器是操作系统的一部分吗?
这三者的关系,程序语言可以用来写操作系统和编译器,操作系统用来编译器运行,编译器用来编译程序语言,编出来的东西可以是操作系统和编译器。
操作系统如何启动的?
没有操作系统的单片机是如何运行程序的
番外:烧录,刻录是什么?
激光烧掉半导体器件的某些部分
CPU和微处理器架构(指令寄存器,数据寄存器,控制器,运算单元)比操作系统更底层!
操作系统也只不过是一个运行在CPU上的C程序罢了
所谓操作系统,用户程序,系统服务,都是我们基于CPU权限人为制造的概念,并非必须存在的客观实体。
CPU通过自己的汇编指令集,通过汇编语言生成不同的机器码
在最早期的时候,机器是无操作系统的,也无编译器的时代,程序员对照指令码表敲01010101形成一个可执行文件,后来为了简化工作增加可读性,才创造了助记符写程序,也就是汇编语言,这个时候产生了汇编器,再后来才有了更简化易读的高级语言和编译器,汇编器和编译器它们都是与特定处理器的指令集相关的。在无操作系统时代,整体机器的代码就一个大循环处理所有事情。后来由于要处理的事情越来越多了,于是就出现一个处于中层的一个管理协调程序,它就是操作系统。
汇编到机器码的过程并不是“编译”,而更像是”对应“。汇编语言的产生本身就是为了”助记“,举个例子说,假设CPU表示移动立即数到寄存器的opcode是00000000000000000000000000000001,那么让程序员记住mov这三个字母总比记那一串32位指令码要强,但是也就仅仅做到这种对应而已。所以汇编码到机器码的转换过程是不需要设计一个特别复杂的编译器的
汇编,汇编,顾名思义,重点在“编”,只是将指令码的助记符再“汇编”回去。要不然何必叫“汇编”呢?编译重点在“译”
cpu执行指令需要操作系统参与吗
编译器和操作系统到底哪一个更底层?
两者都不底层。底层是CPU指令集、硬件。

先有c语言,后来才有操作系统。c编译器又需要操作系统管理。不同的概念
其实编译器也是一个软件,它运行在操作系统之上,编译器将非低级语言翻译为低级语言。其实本身真正运行的操作系统就是二进制代码(不管在什么情况之下),所以正在运行编译器也是二进制代码
编译器是离不开操作系统的。编译器在编译输入输出必须依赖于相关的操作系统。即编译器更像是操作系统之上的一个应用程序,实际如上图。但是操作系统即使没有编译器照样可以运行,在早期计算机,完全是通过汇编编写的操作系统 ----- 如早期的DOS操作系统。只是后来随着操作系统的越来越复杂化,高级语言在操作系统中占的比重越来越大,如Linux或Unix。
从CPU的底层来看,近代CPU都会有用户态和特权态 ----- 当然不同的CPU叫法不同,通常操作系统一定是特权态,即会获得更为底层操作的有限权,而编译器只是应用态的一个应用程序,不管你是用gcc还是llvm;至于说谁产生了谁,谁就更底层更是一个不严谨的说法:比如我现在正在进行的一个案子,就是将C/C++甚至Python通过转换程序转换成硬件电路,并写入FPGA,那是不是因此,就说我的工具或C/C++甚至Python比硬件电路还低级?
进程管理
进程,线程,协程
进程/线程:操作系统提供的一种并发处理任务的能力。
线程共享进程的资源:比如代码段、堆空间、数据段、打开的文件等
但每个线程有自己的栈空间和寄存器
协程:程序员通过高超的代码能力,在代码执行流程中人为的实现多任务并发,是单个线程内的任务调度技巧。
进程的状态
进程的上下文切换
进程通信
join()
阻塞至队列中所有的元素都被接收和处理完毕。
线程同步
死锁
死锁的原因/产生条件
死锁的解决方法
内存管理
虚拟地址
不同进程中,取到的虚拟地址会一样吗?
有可能一样,因为每个进程有自己的页表,及时虚拟地址一样,不同的页表会实际上会把它们映射到不同的物理地址
块,段,页
虚拟内存
单片机是没有操作系统的,每次写完代码都要借助工具把程序烧录进去,单片机的cpu操作的是内存的物理地址
为什么需要虚拟地址?
因为要避免同时运行多个程序时,同时操作到真实的物理地址会出现数据一致性问题。使用虚拟地址可以隔离进程之间的地址空间。
cpu芯片中的一种硬件mmu(内存管理单元),负责将进程持有的虚拟地址映射为真实的物理地址。现代的mmu的映射方式主要是段页式内存管理
内存分段
什么是分段?
按照数据的不同属性,进程的虚拟地址空间被分成不同的段,比如熟悉的栈空间,堆空间,数据段,代码段等
内存分段下的虚拟地址包括段选择子和段内偏移量。
段选择子内包括了(段号等信息)
段表:段号是段表的索引,段表的对应行存储了,段基地址,段界限等信息。段表存储在主存里,每个进程有自己的段表
好处:解决了虚拟地址到物理地址的映射问题
坏处:内存碎片问题和内存交换效率低的问题
内存碎片问题:外部碎片和内部碎片
内存交换技术用来解决内存碎片问题:把产生碎片的进程写到硬盘上,再写回内存(写回内存的时候紧挨着上一个段,减少碎片)。
但是内存分段经常引起碎片,所以经常要进行内存交换,而内存交换涉及到磁盘io,速度很慢(磁盘比内存慢得多,体现存储器层次),影响性能。
为了解决段式管理段内存碎片和交换效率低的问题,产生了内存分页技术
内存分页
目标:1. 减少内存碎片本身 2. 如果还是因为内存碎片而需要进行内存交换,那也要尽量减少交换的数据量
分页:把整个虚拟和物理地址空间切成一段段固定尺寸的大小。每一段称为一个页,Linux中每一页段大小为4kb
mmu通过页表来把虚拟地址映射为物理地址
缺页异常:
发生缺页异常时,会从用户态进入内核态吗
是的,发生缺页异常时,会从用户态进入内核态。当进程访问某个虚拟页时,如果该虚拟页没有在物理内存中,CPU 会触发一个缺页异常,并将控制权交给操作系统内核。在内核中,操作系统会检查该虚拟页是否在磁盘上,如果在,就将其读入物理内存,并更新页表,然后再将控制权交回给进程,让其继续执行。由于这个过程需要操作系统内核的支持,所以需要从用户态进入内核态。
异常和中断的区别
异常和中断都是计算机系统中的一种事件处理机制,但它们的触发方式和处理流程有所不同,具体区别如下:
触发方式:异常通常是由指令执行过程中出现错误而触发,例如访问非法内存地址、除以零、栈溢出等;而中断通常是由外部设备(例如硬件、IO设备等)向CPU发出中断请求信号而触发。
处理流程:当发生异常时,CPU会暂停当前进程的执行,然后将控制权交给操作系统的异常处理程序,该程序会根据异常的类型进行相应的处理,例如打印错误信息、终止程序执行等。而当发生中断时,CPU会保存当前进程的状态,然后将控制权转移到相应的中断处理程序,该程序会处理中断请求,例如读取硬件设备的数据等,然后将控制权返回到原来的进程继续执行。
时间顺序:异常是在指令执行过程中发生的,而中断是在指令执行之外发生的。
总的来说,异常和中断都是计算机系统中的一种事件处理机制,用于处理系统中发生的各种异常情况。异常通常与当前进程的执行相关,而中断通常与外部设备的操作相关。它们都需要在操作系统中进行相应的处理,以保证系统的安全性和稳定性。
为什么内存分页减少了内存碎片并提高了内存交换的效率?
减少内存碎片: 释放和分配内存的单位很小(页),不会产生段之间那种大的碎片。
提高交换效率:操作的粒度更加小,不需要一次性把整个段都换入换出,需要多少页换多少。
内存分页下的虚拟地址格式:页号+页内偏移量
页表:页号是页表的索引,页表存储在主存里,每个进程有自己的页表
好处:与内存分段相比,内存分页减少了内存碎片并提高了内存交换的效率
坏处:1. 页面太小,页数太多,页表就可能非常大 2. 每次从cpu需要地址就要查内存(DRAM)中的页表,速度可以更快(直接在SRAM里查速度更快)
解决方案:问题1:=>多级页表 问题2:=>TLB快表
多级页表
假设有4GB的虚拟地址空间
多级页表的思路是:先套娃,分成一级页号和二级页号,先确定一级页表然后按需去取对应的二级页表。一级页表很小,所有二级页表之和相当于原来的单级页表(很大)
如果程序只用了500MB空间,不需要对应的二级页表,那根本就不会创建全部的二级页表。
但是如果全部用单级页表,这个大的单级页表就要覆盖到全部4GB地址空间,(多级页表中的一级页表已经覆盖到了全部地址,只是需要二级页表进一步定位),否则计算机系统就不完备(有的地址空间无法找到)。
现代64位系统有4级页表
快表
Translation Lookaside Butter 转址旁路缓存
解决问题:虚拟内存到物理内存的转换速度问题
单个页表的访问本身就速度比不上cpu内部的存储硬件(页表存储在内存中,在存储器层次里低于cpuSRAM:寄存器、缓存等),加了多级页表更是添了很多步骤,让转换速度变慢了。
利用程序的局部性原理(时间局部性和空间局部性),在CPU芯片中添加一个叫做TLB的特殊硬件存储了最近使用的页的(虚拟地址,物理地址关系),TLB在MMU旁边,负责提供缓存。
段页式内存管理
分段+分页,为什么要结合段页式?:段有逻辑意义,方便程序员;页能提高内存利用率和内存交换效率,各自有其优缺点,结合起来可以弥补彼此的不足。
段式内存管理通过将程序划分为逻辑上相互独立的段,提供了更加灵活的内存管理方式。程序员可以根据需要将程序分割成多个段,每个段都有自己的大小和属性,方便管理和保护。但是段式内存管理存在内部碎片问题,即每个段的大小不一定能够被完全利用,造成浪费。
页式内存管理通过将物理内存划分为固定大小的页面,提供了更加高效的内存管理方式。在页式内存管理下,每个进程都拥有自己的页表,可以独立管理自己的虚拟地址空间。但是页式内存管理存在外部碎片问题,即每个进程所需的页面可能不足一页,造成浪费。
结合段式内存管理和页式内存管理可以充分利用两种方式的优点,同时避免它们的缺点。具体来说,可以通过将每个段划分为固定大小的页框,然后将这些页框与物理内存的页面一一对应,实现段页式内存管理。这样,每个进程可以独立管理自己的页表,而每个段可以被完整地利用,避免了内部碎片问题。
结合段式内存管理和页式内存管理的好处是提高了内存的利用率,减少了浪费。坏处是需要更多的内存来存储段表和页表,而且需要进行复杂的地址转换操作,会带来一定的额外开销。
这个体系下的虚拟地址格式:段号+段内页号+页内偏移地址
段表存段号和页表地址
页表存页号和物理页号
拿到地址的三次访问:
- 访问段表,拿到页表起始地址
- 访问页表,得到物理页号
- 结合物理页号和业内偏移地址,得到真实的物理地址
Linux内存管理
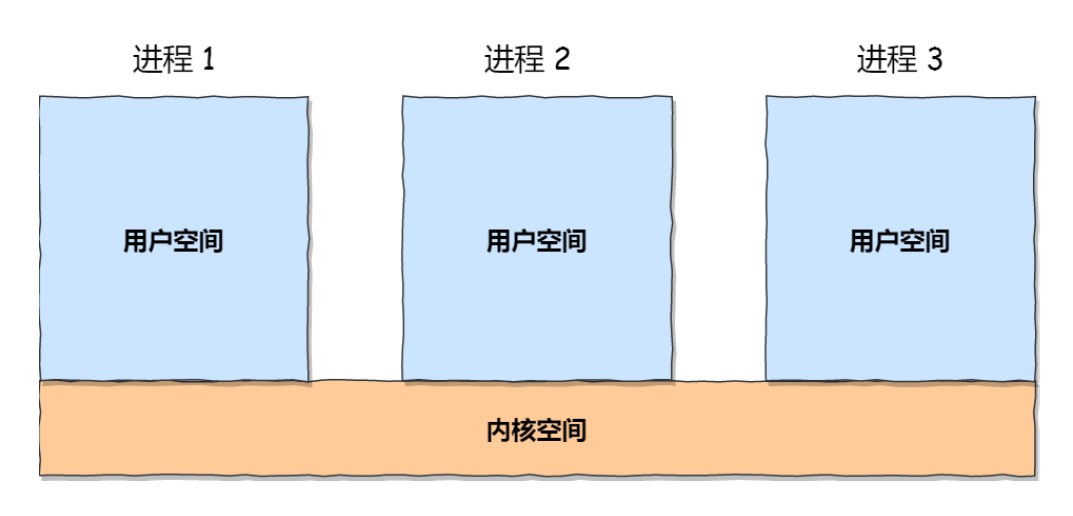
Linux的虚拟地址空间分为用户空间和内核空间
内核空间被所有进程共享(所有进程的内核空间关联着相同的物理内存),每个进程有自己的用户空间。
进程在用户态只能访问自己的用户空间,进程在内核态则可以访问共享的内核空间
用户空间分为不同的段:栈、堆、数据段、代码段等
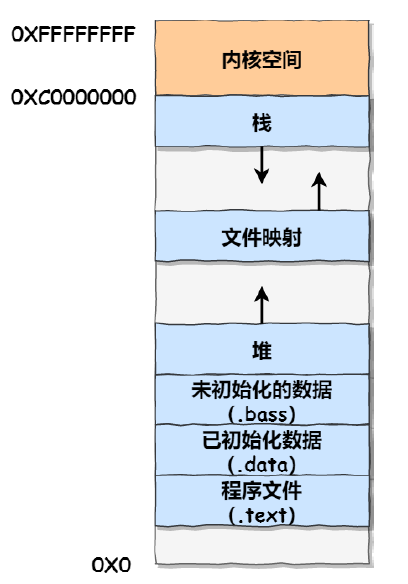
Linux主要采取的是页式内存管理,段式管理只用于访问控制和内存保护(所有段的起始地址都被设置为0)
文件管理
设备管理
DMA
让CPU不必等外部设备的IO,DMA像数据管家,CPU知会它一声,就去忙别的了,DMA把数据拿到以后再用中断叫CPU来处理这些数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号