数据采集 实验四
1.作业①
1.1作业内容
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;
Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
-
关键词:学生自由选择
-
输出信息:
MySQL数据库存储和输出格式如下:

1.2解题过程
1.2.1网页请求
在浏览器查看当当网查找关键词python可以看到url:

所以只要在scrapy里构造一个get请求就可以了。
同时page_index参数表示页数可以用来进行翻页操作
在start_requests方法中进行:
for i in range(1,4): #进行翻页,这里爬前三页
url = "http://search.dangdang.com/?key=python&act=input&page_index="+str(i)
yield scrapy.Request(url=url, callback=self.parse)
1.2.2网页内容的获取
在浏览器查看网页源码:
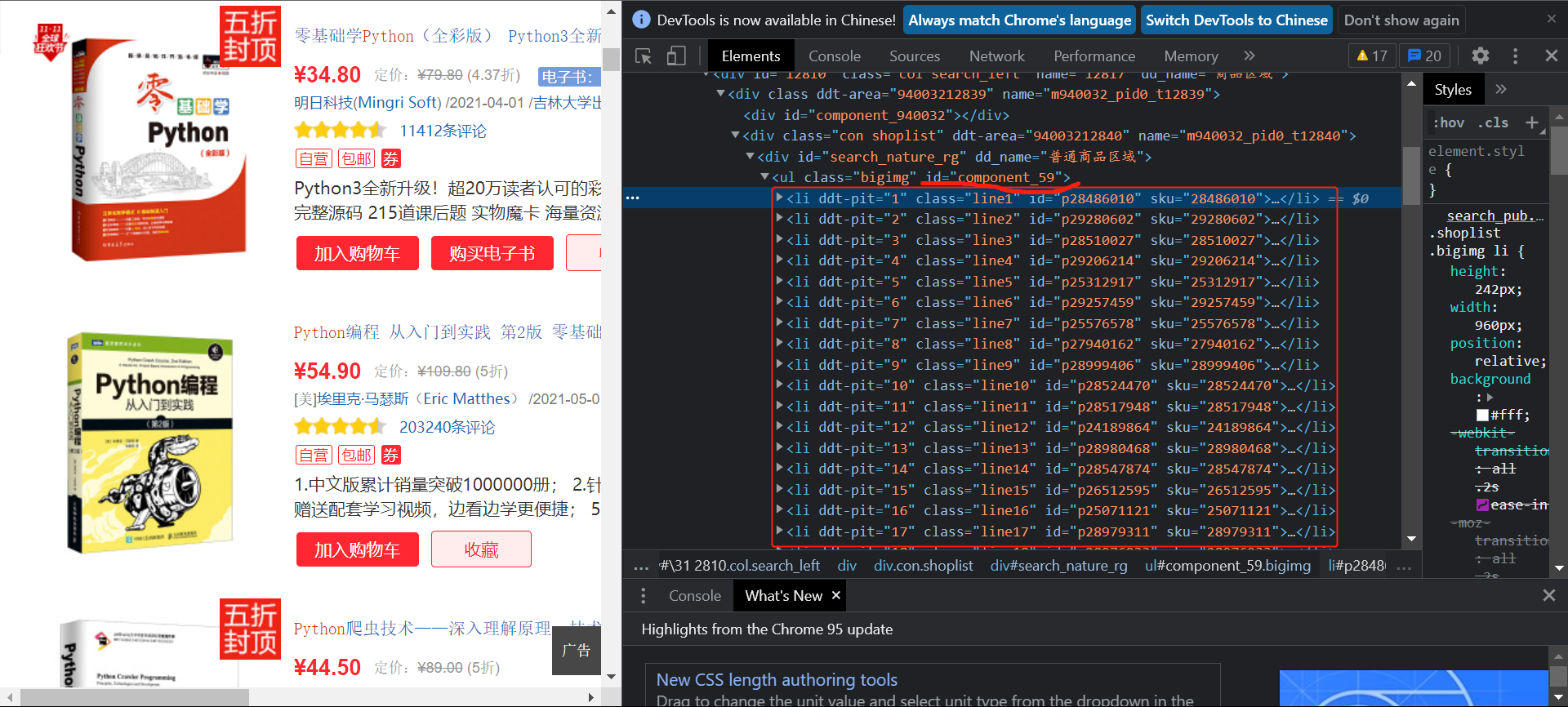
可以看到书本的内容信息都存储在id为component_59的ul标签下的列表所可以先获取整个列表在对列表的内容进行解析:
BookList = selector.xpath('//*[@id="component_59"]/li') #找到书本信息的列表
然后根据内容提取想要的信息:
如提取title信息:
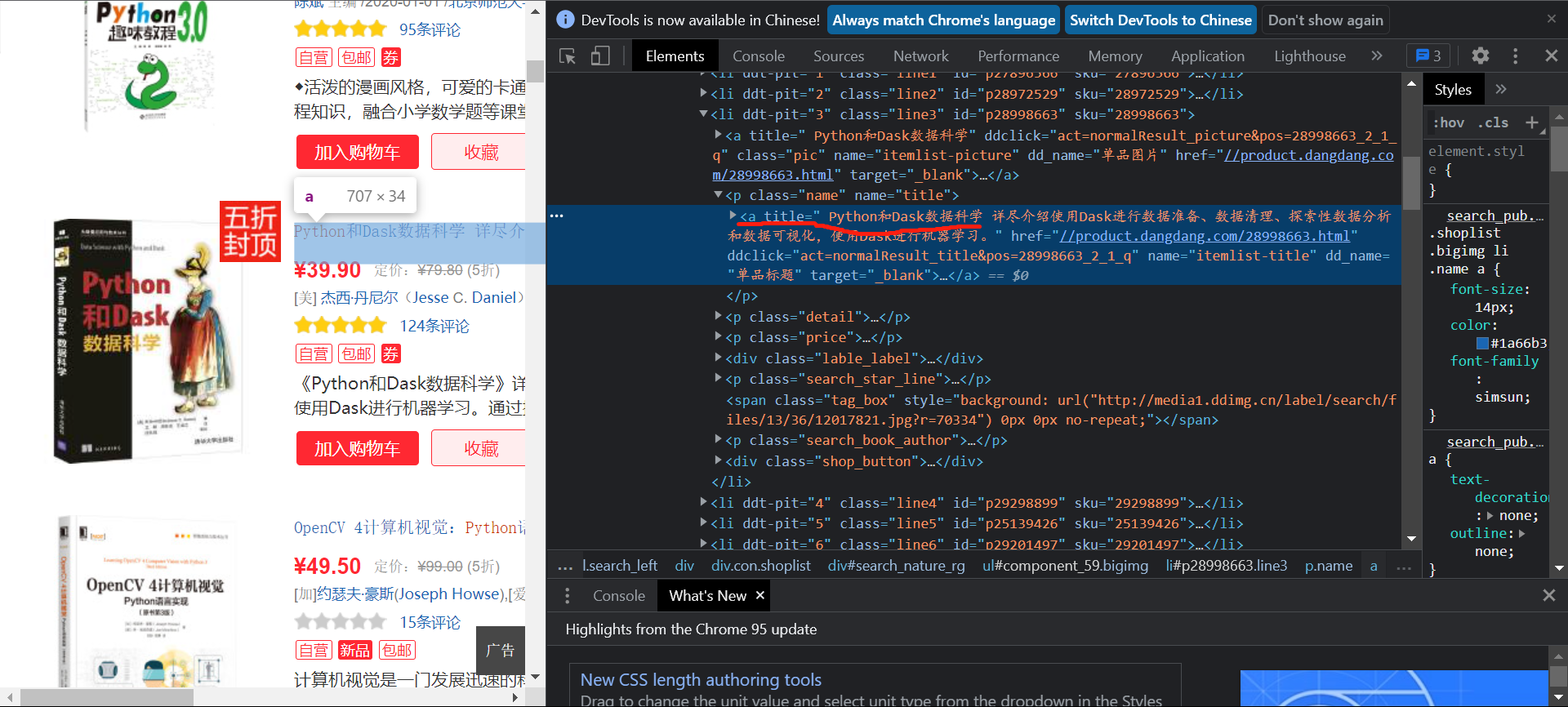
可以看到title的内容存在列表第二个元素下的a标签的title属性值中:
title = book.xpath('./a/@title').extract_first() #书本标题
可以以此来提取书本的title内容,其他值类似。
在获取页面的源码时:
data = response.body.decode('utf-8')
如果这里设置为utf-8这会出现报错:

将utf-8改为gbk后错误解决
1.2.3数据存储
首先在item中定义如下
class Task41Item(scrapy.Item):
title = scrapy.Field()
detail =scrapy.Field()
author =scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
price = scrapy.Field()
id = scrapy.Field()
用于存储相应的数据内容
对mysql的操作放在pipelines中:
创建表为:
create table if not exists exp4_1(
id int(11) NOT NULL AUTO_INCREMENT,
bTitle text(1000) not null,
bAuthor char(70),
bPublisher char(50),
bDate char(30),
bPrice char(50),
bDetail text(2000),
PRIMARY KEY (id))
设置主键id自增。
然后从item中获取相应的数据存储
sql2 = '''INSERT INTO exp4_1(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) VALUES(%s,%s,%s,%s,%s,%s)'''
arg = (item['title'], item['author'], item['publisher'], item['date'], item['price'], item['detail'])
cs1.execute(sql2, arg)
conn.commit()
因为书本的信息有一些为空:
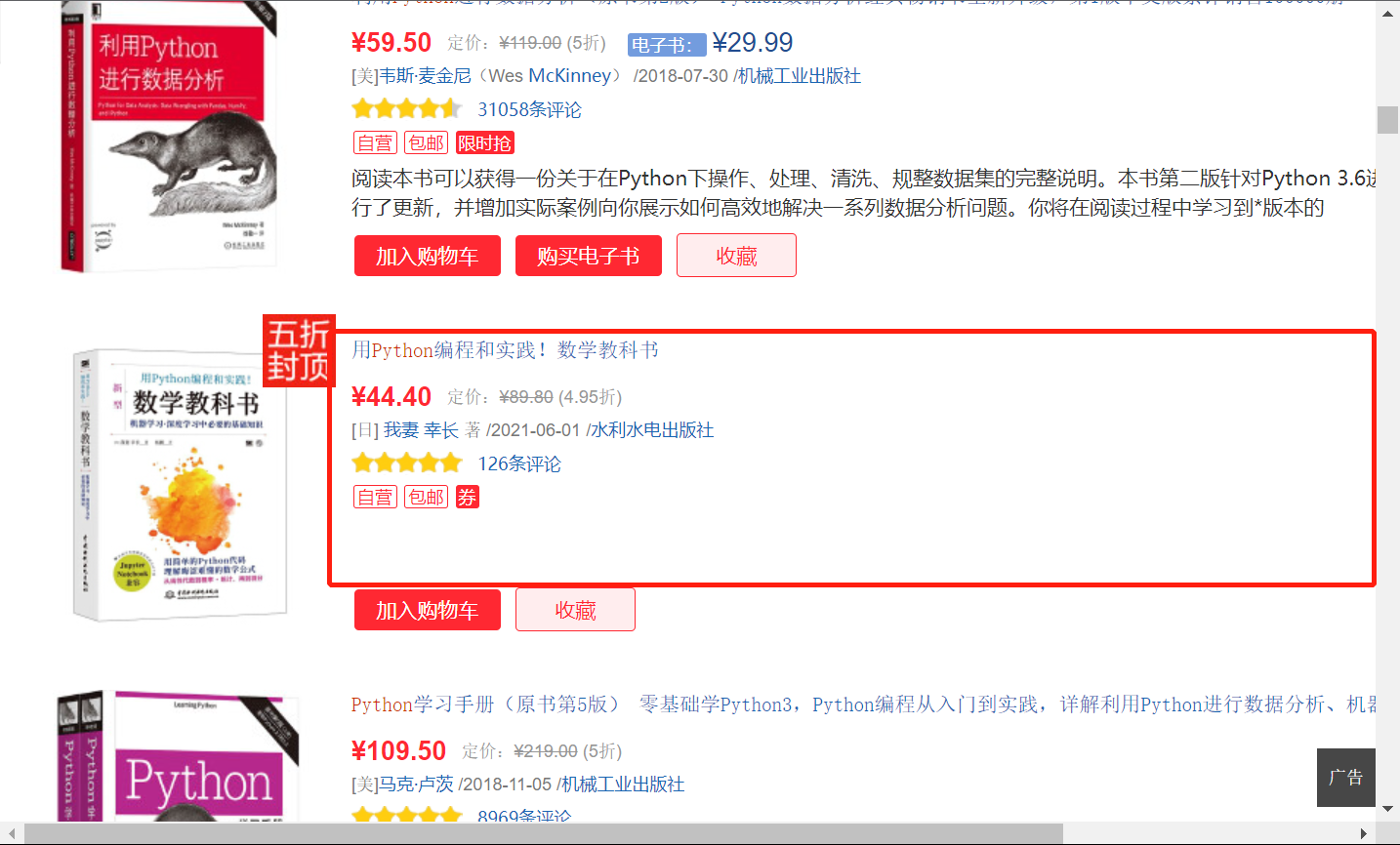
所以在创建表时如果设置了属性值不能为Null,就会发生错误,所以除了title其他属性都没设置。
1.3输出
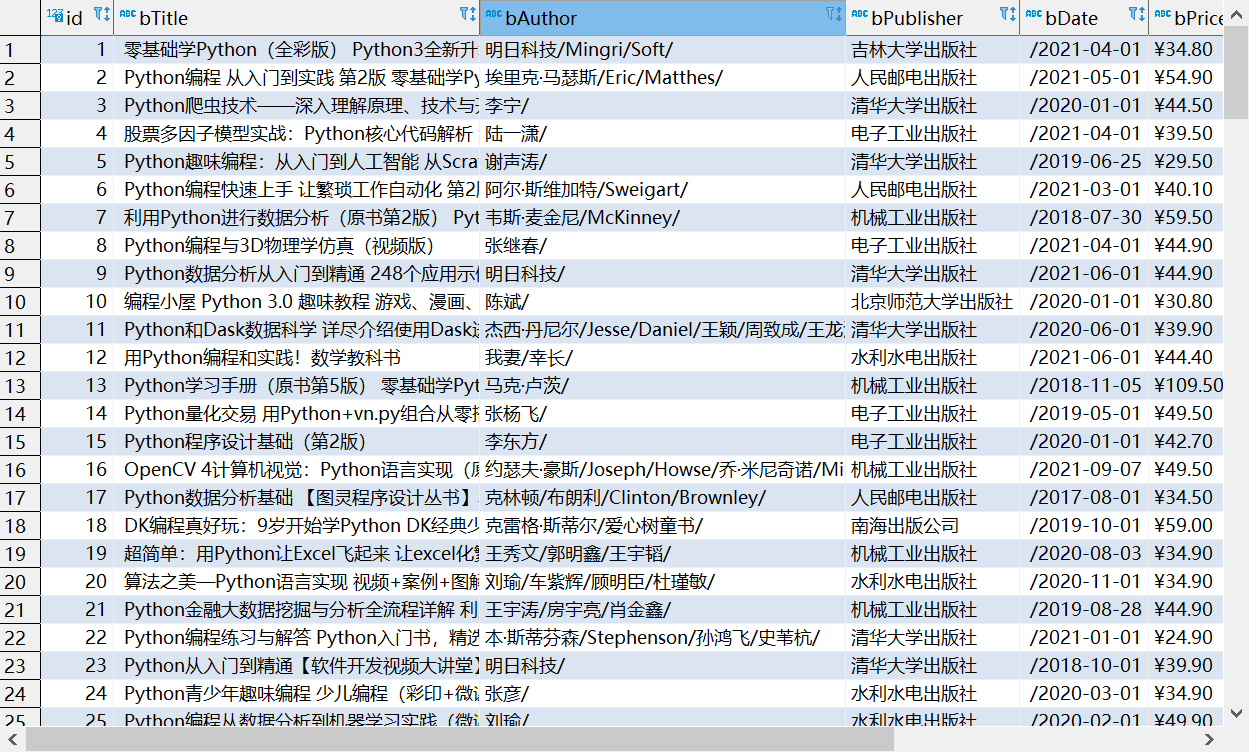

可以看到有一些行的某些信息都是空。
1.4心得体会
通过本次作业巩固了对scrapy爬虫框架的使用,并且意识到在进行mysql数据库操作时需要明确对空值的设置和处理。
2.作业②
1. 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/
-
输出信息:MYSQL数据库存储和输出格式
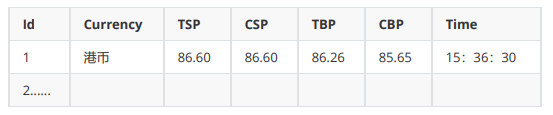
2.2解题过程
2.2.1发起请求
同上题在start_requests中编写发起请求:
yield scrapy.FormRequest(url=self.url, callback=self.parse)
这题不需要携带参数。
2.2.2页面内容的获取
在浏览器查看内容:

可以看到数据都存储在表格中。
如果直接复制网页上的xpath来查找内容:

可以看到无法查找到数据。
将复制的xpath中 的tbody删除后就可以正确查找到数据:
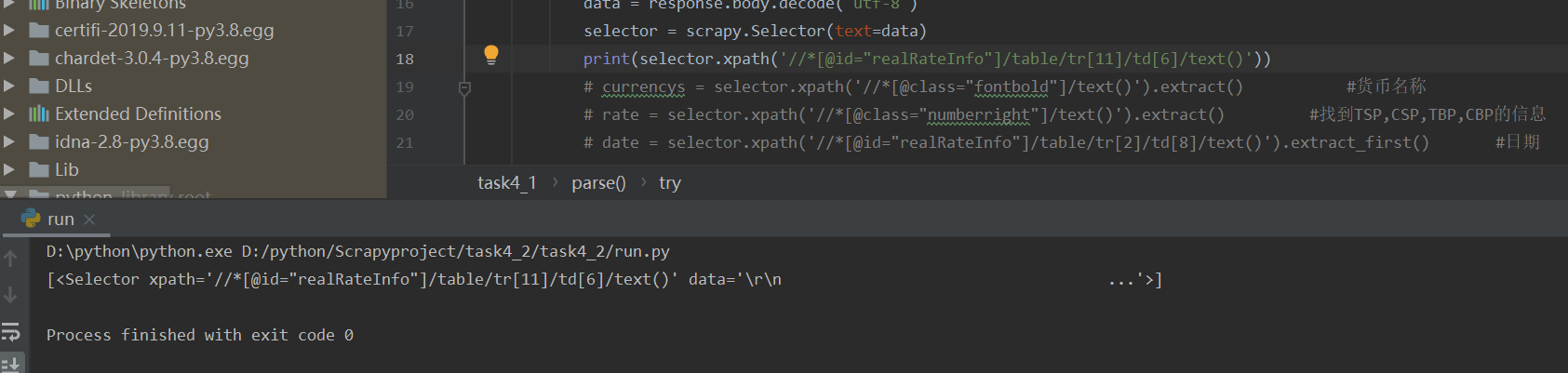
原因是浏览器中看到的tbody并不是编写网页时就有的,而是后期软件添加上去的。
另外同第一题相反,如果编码设置成gbk则会报错:

但是设置成utf-8就可以正常。
在查找数据时我使用的是直接按照class的名称查找,再对查找的数据进行处理。
rate = selector.xpath('//*[@class="numberright"]/text()').extract() #找到TSP,CSP,TBP,CBP的信息
2.2.3数据存储
与上题无答差距。
items:
currency = scrapy.Field()
TSP= scrapy.Field()
CSP= scrapy.Field()
TBP= scrapy.Field()
CBP= scrapy.Field()
date = scrapy.Field()
创建表:
create table if not exists exp4_2(
id int(11) NOT NULL AUTO_INCREMENT,
Currency char(200) not null,
TSP char(70) not null,
CSP char(50) not null,
TBP char(30) not null,
CBP char(50) not null,
Date char(40) not null,
PRIMARY KEY (id))
2.3输出
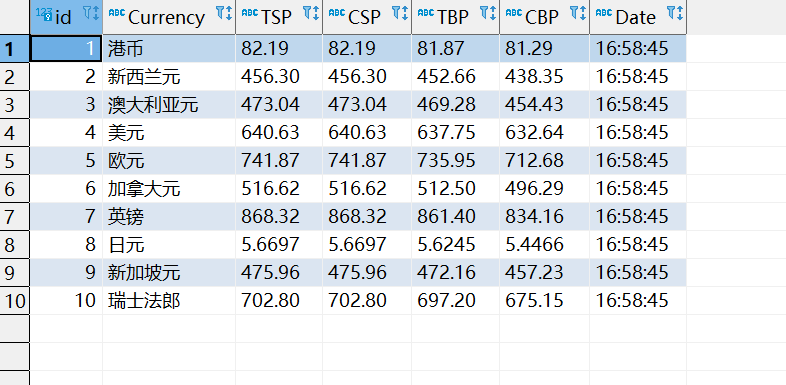
2.4心得体会
通过本次作业巩固了对scrapy爬虫框架的使用,同时发现在浏览器查看的网页源码内容可能与爬取下来的略有区别。需要认真观察处理。
3.作业③
3.1作业内容
.要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
2.候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
3.输出信息:
MySQL数据库存储和输出格式如下,
表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:

3.2解题过程
3.2.1发起请求
使用selenium首先创建一个webdriver然后使用get方法发起请求。
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
chrome_options = Options()
#chrome_options.add_argument('--headless') #设置浏览器不显示
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
3.2.2页面内容的获取
在浏览器查看数据存储的位置:
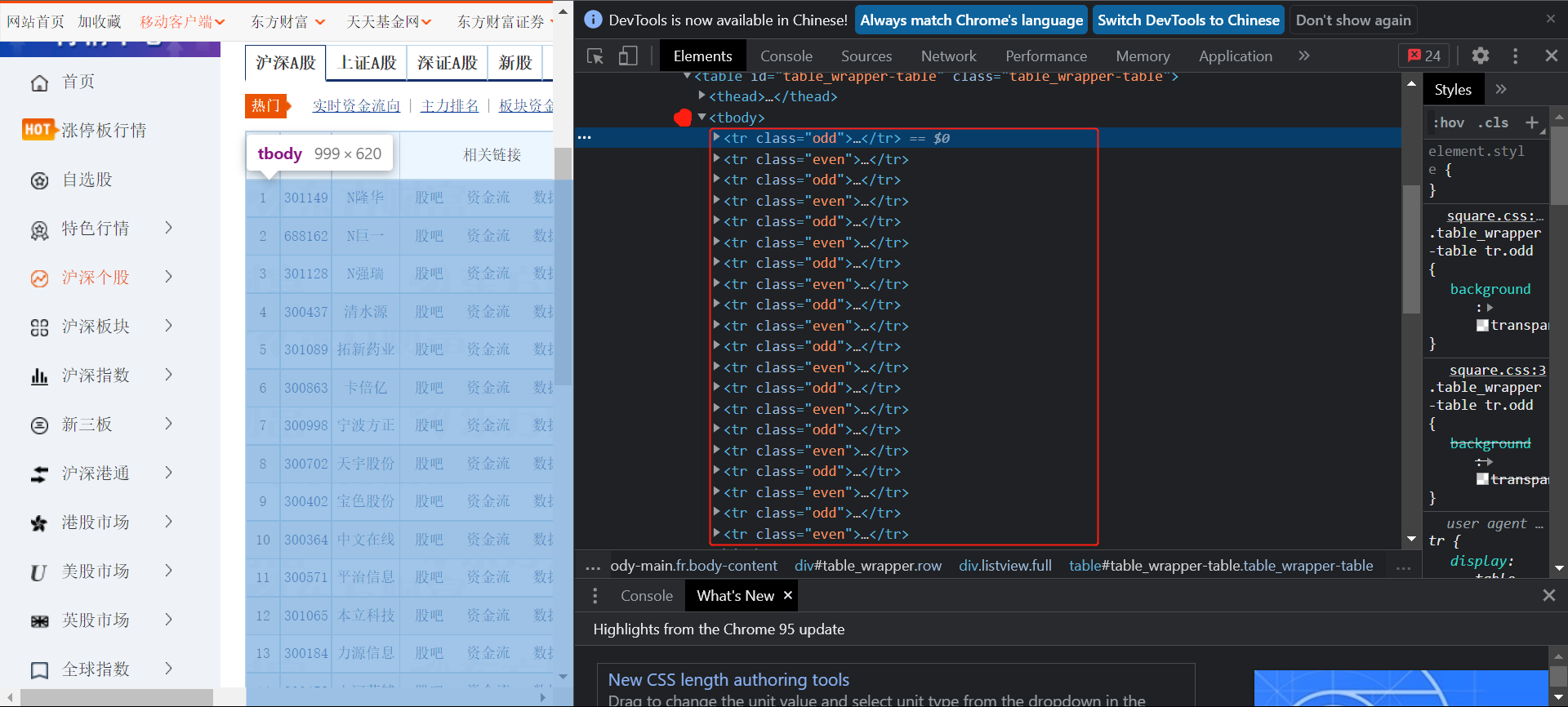
可以看到同第二题的存储方法,尝试通过xpath查找tbody

可以看到网页的内容全部都显示出来了。
然后进行更换板块的操作:
网页查看更换板块的按钮:

然后通过对应的xpath查找然后使用.click()点击进行更换板块:
page2 = driver.find_element_by_xpath('//*[@id="nav_sh_a_board"]/a')
page2.click()
3.2.3数据存储
同前两题使用pymysql链接数据库
创建表:
create table if not exists exp4_3(
id char(100) not null,
Stockcode char(30) not null,
Stock char(50) not null,
newquotation char(50) not null,
RFrate char(30) not null,
RFnum char(50) not null,
Turnover char(50) not null,
Tnum char(30) not null,
amplitude char(50) not null,
highest char(50) not null,
losest char(30) not null,
today char(50) not null,
yesterday char(50) not null,
PRIMARY KEY (id))
'''
对应的数据通过上述内容进行split分割获取,
arg = (name + sqldata[0], sqldata[1], sqldata[2], sqldata[6], sqldata[7], sqldata[8], sqldata[9], sqldata[10],
sqldata[11], sqldata[12], sqldata[13], sqldata[14], sqldata[15])
cs1.execute(sql2, arg)
conn.commit()
同时需要注意的是分割后有一些不需要的内容:
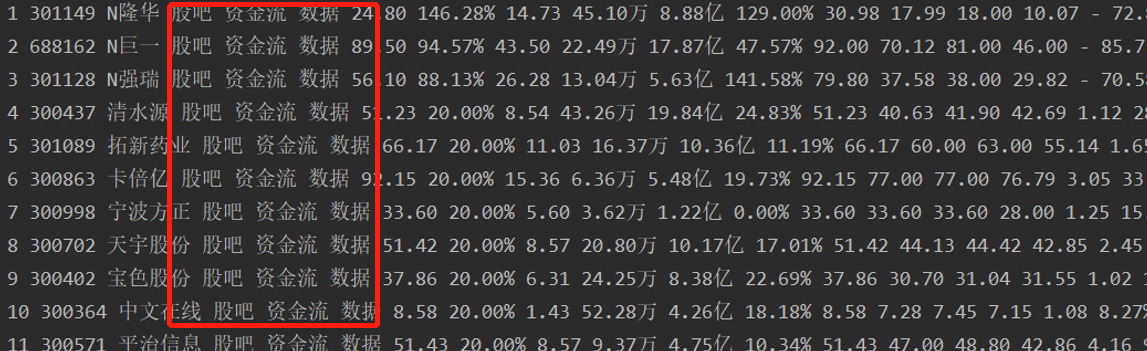
注意去除。
3.3输出
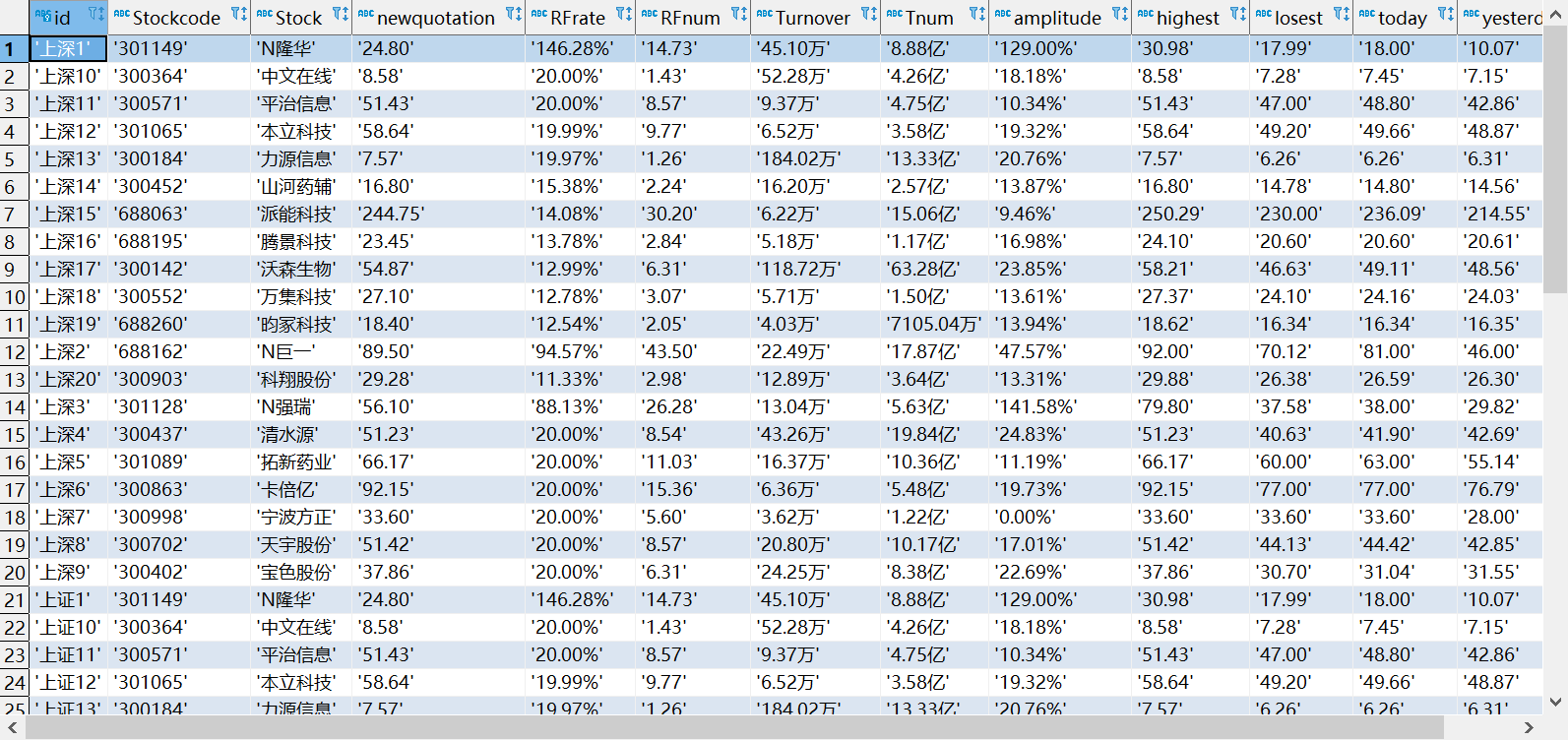
我在主键id前加了每个板块的名称,以免重复。
3.4心得体会
通过这次作业巩固了对selenium的使用和对mysql数据库的使用,同时注意查看爬取信息是否都为需要的有用信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号