数据采集 实验一
1.作业①
1.1作业内容
要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812)的数据。
输出信息:

1.2解题思路
1.2.1获取页面信息
import urllib.request
import re
url ="https://www.shanghairanking.cn/rankings/bcsr/2020/0812"
page=urllib.request.urlopen(url)
html = page.read().decode('utf-8')
使用urllib.request.urlopen发送请求,不设置请求头依然可以正常访问。
page.read()获取该网站的html信息。
.decode('utf-8') 设置编码方式为utf-8。
1.2.2解析页面
在浏览器查看:
可以看到需要爬取的信息都直接写在html文件内,只要使用正则匹配出想要的内容就可以了。
regrank1 ='<div class="ranking" .+\n.+' #正则表达式-排名
regrate ='0ae>\n.+\n +<!' #正则表达式-层次
regname='class="name-cn".+ </a>' #正则表达式—学校名称
regpoint='</div></td><td data-v-68e330ae>\n.+' #正则表达式-总分
rank2020=[] #用于存储排名列表
rates=[] #用于存储前百分数
names=[] #存储学校名称
points=[] #存储总分
编写正则表达式并创建存储的列表
逐一匹配并去除多余的内容:
rank1 = re.findall(regrank1,html)
for i in rank1:
rank2020.append(i[-2:])
rate = re.findall(regrate,html)
for i in rate:
i=i.replace(" ","").replace("\n","")
rates.append(i[4:-2])
name=re.findall(regname,html)
for i in name:
names.append(i[32:-4])
point=re.findall(regpoint,html)
for i in point:
i=i.replace(" ","").replace("\n","")
points.append(i[30:])
1.2.3输出
使用.format来格式化输出的内容:
print("{0:{4}<5}\t{1:{4}<12}\t{2:{4}<9}\t{3:{4}<5}".format("排名","全部层次","学校名称","总分",chr(12288))) #输出
for i in range(len(names)):
print("{0:{4}<5}\t{1:{4}<12}\t{2:{4}<9}\t{3:{4}<5}".format(rank2020[i],rates[i],names[i],points[i],chr(12288)))
结果:
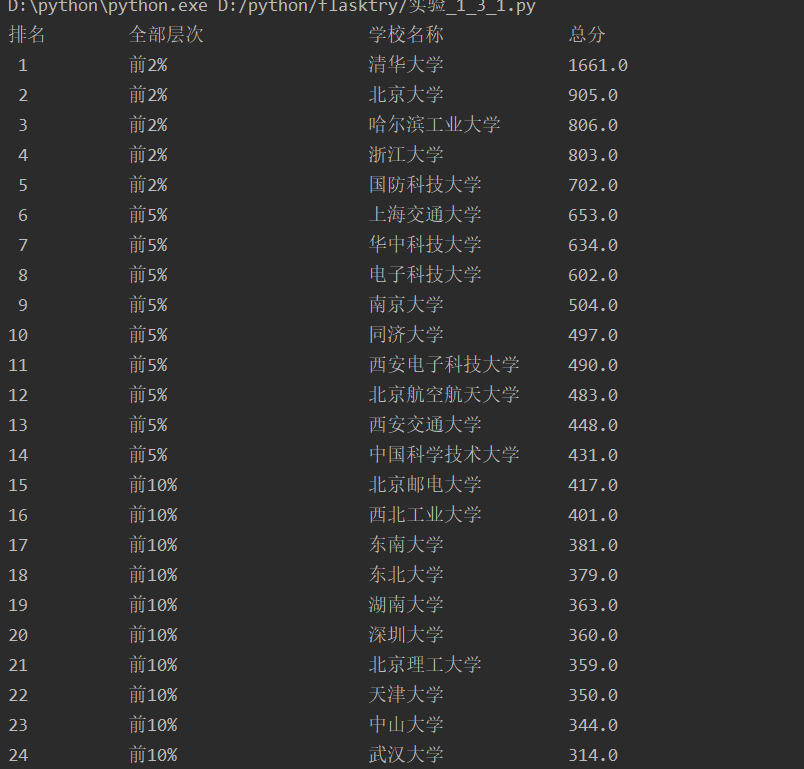
1.3心得体会
1.在输出爬取的内容时,需要使用.format来使输出更加整齐直观,使用中文的空格(chr(12288))可以防止中英文数字等无法对其
2.爬取页面时,可以先将整个页面的html存储到本地以防止短时间内过多访问Ip被封
2.作业②
2.1作业内容
– 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
– 输出信息:

2.2解题思路
2.2.1获取页面信息
首先也是发送请求获取页面信息:
import requests
from bs4 import BeautifulSoup
url = "https://datacenter.mee.gov.cn/aqiweb2/"
reponse = requests.get(url=url)
bs4 = BeautifulSoup(reponse.text, 'lxml')
使用requests发送请求并用BeautifulSoup解析获取的页面信息,此次作业的网站不用设置请求头也可正常爬取。
2.2.2页面信息的处理
在浏览器查看所需爬取的信息:
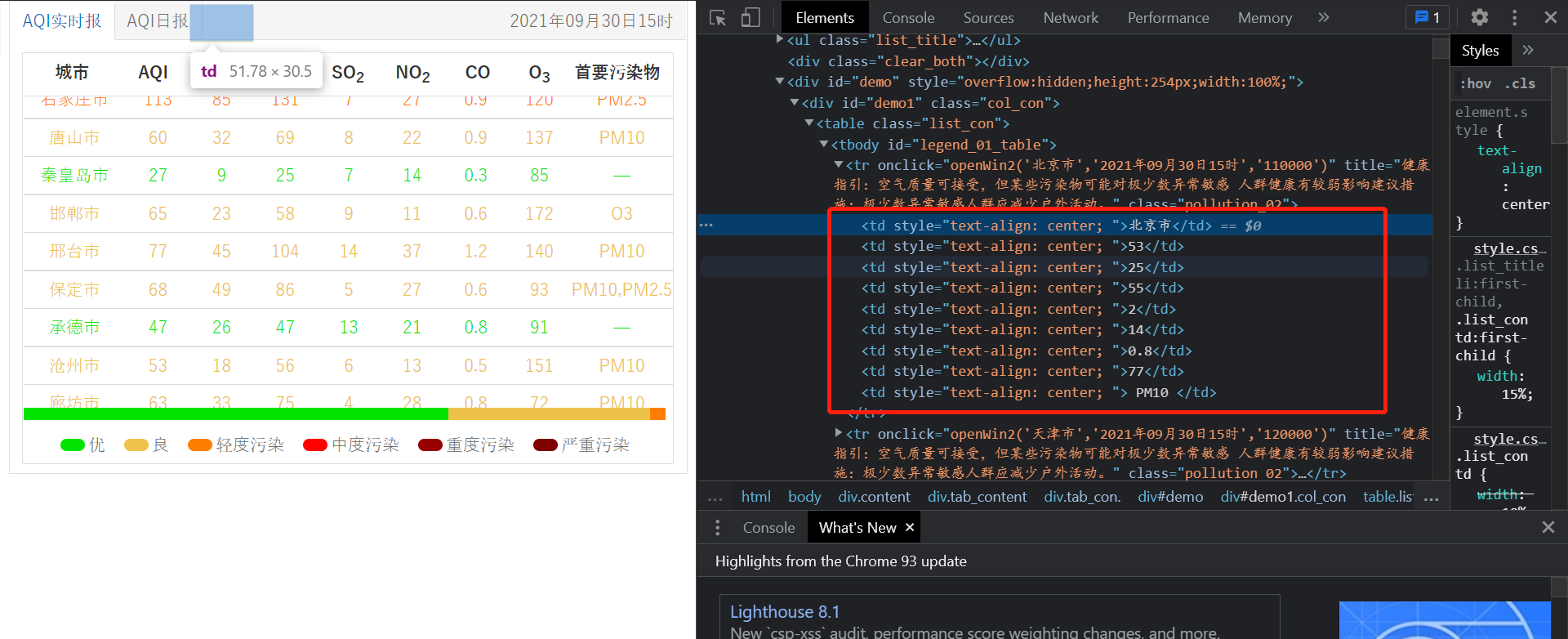
可以看到需要爬取的信息都在td标签的列表中,所以直接查找所有td标签就可以了
pages = bs4.find_all('td')
显示所有查找到的内容可以发现:
所需要的信息是9歌一循环的,我们需要其中的7个信息
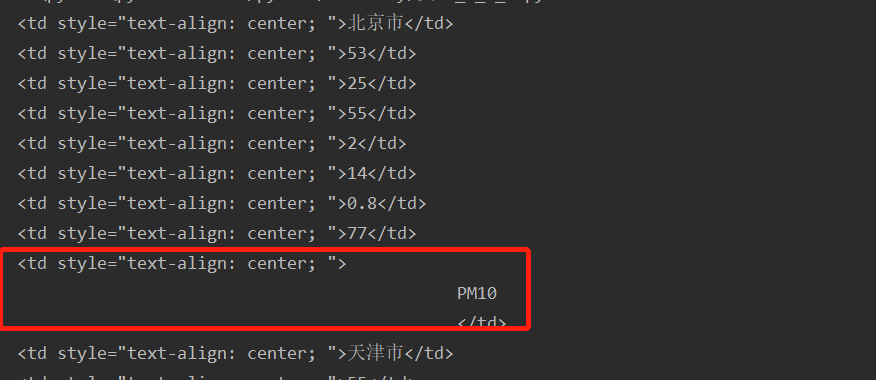
除了需要的信息以外还有一些空格换行等转义符
初次之外要求爬取的是AQI实时报,但是把AQI日报的内容也输出了
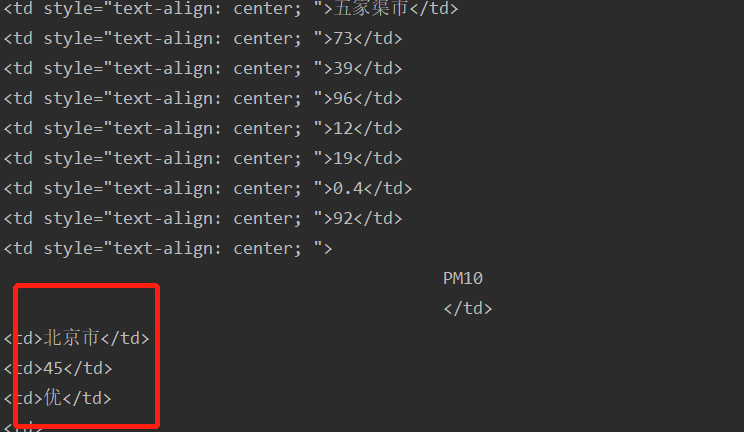

所有我们要去除这部分的信息
先创建了列表citys,sqi,pm25,so2,no2,co,maxs来存储对应的信息
count = 1
mark1 = 0 # 用于标记Aqi实时报是否爬取结束
for i in pages:
text = i.text.replace(" ", "").replace("\n", "").replace("\t", "").replace("\r", "") #替换掉空格换行等符号
switch = count % 9
if switch == 1:
citys.append(text)
if text == "北京市": #用于判断aqi实时报是否结束
mark1 += 1
if mark1 == 2: # aqi是时报爬取结束,接下去是aqi日报,不爬取
break
elif switch == 2: # aqi的值
aqi.append(text)
elif switch == 3: # pm2.5值
pm25.append(text)
elif switch == 5: # so2的值
so2.append(text)
elif switch == 6: # no2
no2.append(text)
elif switch == 7: # co
co.append(text)
elif switch == 0: # 首要污染物
maxs.append(text)
count += 1
同时使用mark1来判断AQI实时报的内容是否读取结束进去AQI日报,第二次出现“北京市”是就结束循环
2.2.3输出
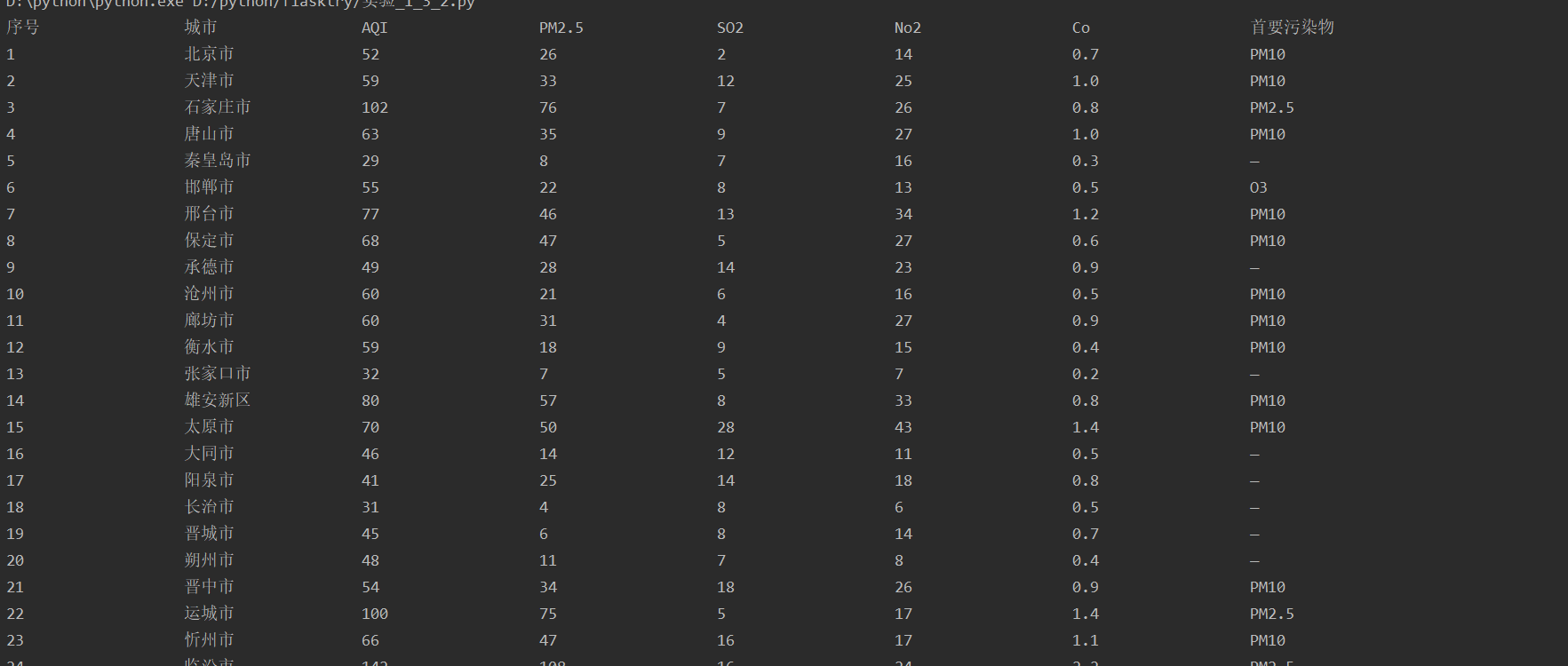
print("{:{opt}<10}\t{:{opt}<10}\t{:{opt}<10}\t{:{opt}<11}\t{:{opt}<10}\t{:{opt}<10}\t{:{opt}<10}\t{:{opt}<10}".format("序号", "城市", "AQI", "PM2.5", "SO2", "No2", "Co", "首要污染物", opt=chr(12288)))
for i in range(len(aqi)):
print("{:{opt}<10}\t{:{opt}<10}\t{:{opt}<10}\t{:{opt}<10}\t{:{opt}<10}\t{:{opt}<10}\t{:{opt}<10}\t{:{opt}<10}".format(i + 1, citys[i], aqi[i], pm25[i], so2[i], no2[i], co[i], maxs[i], opt=chr(12288)))
2.3心得体会
在爬取页面内容时,要主要爬取的信息是否全部为所需要的,防止在其他操作时出现意外状况,如本题的AQI实时报和AQI日报,刚开始将AQI日报的内容也一并存入列表,使输出时出现报错,浪费了不少时间
3.作业③
3.1作业内容
– 要求:使用urllib和requests和re爬取一个给定网页(https://news.fzu.edu.cn/)爬取该网站下的所有图片
– 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
3.2解题思路
3.2.1获取页面信息
题目要求使用urllib和requests,应该是两个用一个就行吧
import requests
import re
import matplotlib.pyplot as plt
import urllib
url ="http://news.fzu.edu.cn/"
reponse = requests.get(url=url) #requests
#reponse = urllib.request.urlopen(url) #urllib
page=reponse.text #requests
# page = reponse.read().decode('utf-8') #urllib
3.2.2解析页面内容
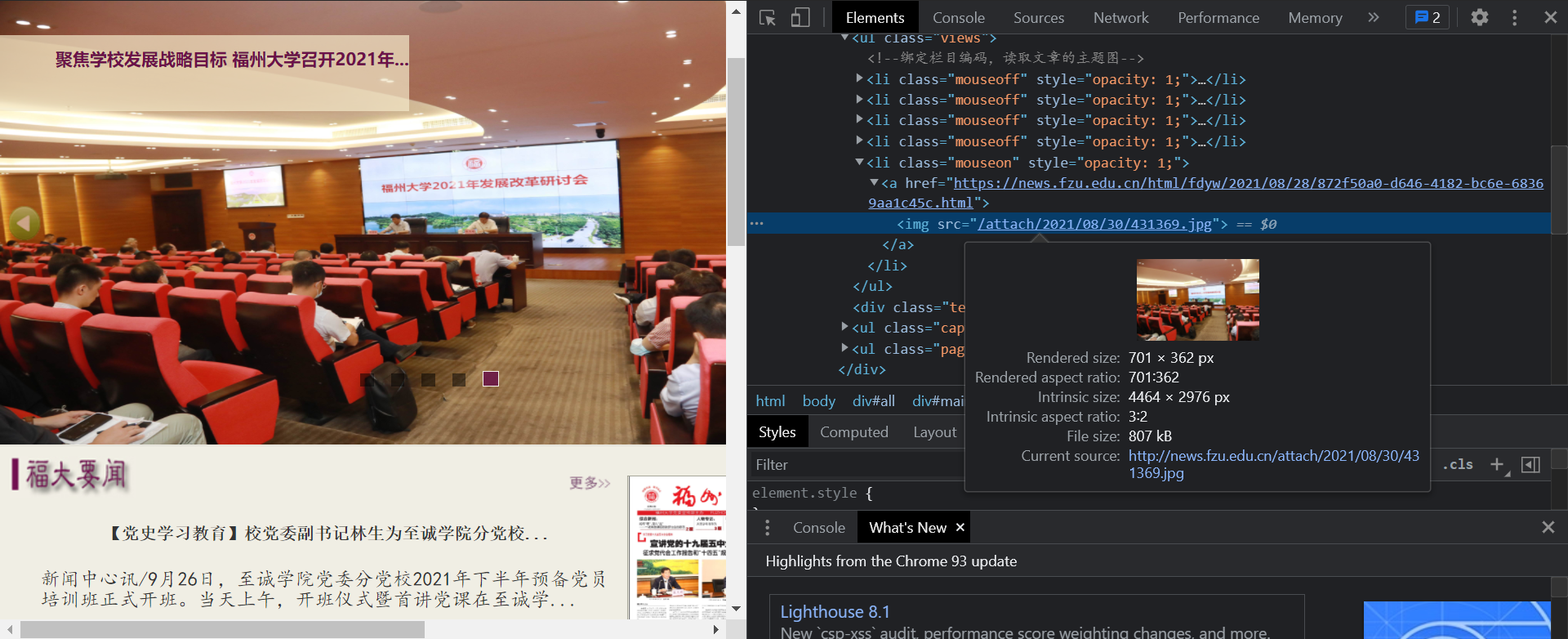
可以看到网页的图片都存储的img标签中,其中有jpg图片和gif图片
3.2.3爬取图片思路
网页中的图片在img标签中以以源地址的形式存储,打开该地址可以看到:

我们需要获取这个地址然后以二进制写入文件中就可以实现下载
reg ="<img src=.+jpg" #查找Jpg格式的图片# reg = "<img src=.+gif" #获取gif格式的图片name = re.findall(reg,page)imgsrcs=[] #存储图片srcfor i in name: imgsrcs.append(url+i[11:])
写入文件:
for i in range(len(imgsrcs)): pic = imgsrcs[i] # 加上https: with open("./imgs/"+str(i)+ '.jpg', 'wb') as imgs: # 将图片写进图片文件 pic2 = requests.get(pic).content # 获取图片链接的二进制 imgs.write(pic2) # 把图片的二进制写进图片文件
结果:

为了直观我还用matplotlib.pyplot将图片显示出来。
3.3心得体会
爬取网页图片时需先获取该图片的源,再通过写文件的方式存储到本地,在使用正则表达式时应该主要原文本中无法直接看到的换行等转义符号,否则可以一直无法匹配出结果。
