
一、进程理论
1.程序 和 进程
程序 就是一堆代码文件,是指令和数据的集合,可以作为目标文件保存在磁盘中,或者作为段存放在内存地址空间中。(静态)
进程 就是一个程序运行的过程,是操作系统进行资源分配和保护的基本单位。(动态)
进程是资源分配的最小单位
1个程序可以对应多个进程,但1个进程只能对应1个程序。进程和程序的关系犹如演出和剧本的关系。
2.并发、并行、串行
串行:多个任务依次运行、一个进程运行完毕,再运行下一个
并行:多个任务是真正意义上一起运行,只有多个CPU才能并行的概念,
并发:多个任务看起来是同时运行的,本质上还是一个个地运行

3.同步 - 异步 / 阻塞 - 非阻塞
同步(慢):
发起一个请求,直到请求返回结果之后,才进行下一步操作。
就像运行一段代码,自上而下一行一行运行,只有上一行代码执行完毕,才能执行下一行代码。
简单来说,同步就是:必须一件事一件事的做,等前一件做完了,才能做下一件事。
异步(快):
发起一个请求后,不管这个请求有没有返回结果,直接可以进行下一步操作。
一般情况下,有一个回调操作。
简单来说,异步就是:可以多件事同时做。
阻塞(慢):
遇到了IO操作,CPU会被操作系统切换到其他进程。
调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
简单来说,阻塞就是:需要买奶茶和冰淇淋,买奶茶的时候奶茶制作过程中只能等,然后买完奶茶再去买冰淇淋。
非阻塞(快):
没有IO操作,一直在运行。
在不能立刻得到结果之前,该调用不会阻塞当前线程。
简单来说,非阻塞就是:需要买奶茶和冰淇淋,买奶茶的时候等的时间去买冰淇淋。
最佳状态:异步 + 非阻塞
拓展:
同步框架:Flask、Django3.0之前
异步框架:Tornado、Sanic、FastAPI
例子:
背景:妈妈出门了,小明想要看电视,但是妈妈让小明烧水。
1.小明烧水,在一旁等待,时不时看一下水有没有烧开。 —— 同步阻塞
2.小明烧水,等待的时间偷偷去看会儿电视,看电视的时候时不时来看一下水有没有烧开。 —— 同步非阻塞
3.小明买了一个水开了之后会响的水壶来烧水,烧水时在一旁等着,不用时不时看水有木有烧开。 —— 异步阻塞
4.小明用那个会响的水壶烧水,然后去看电视,等水开了之后发出响声,再去开。 —— 异步非阻塞
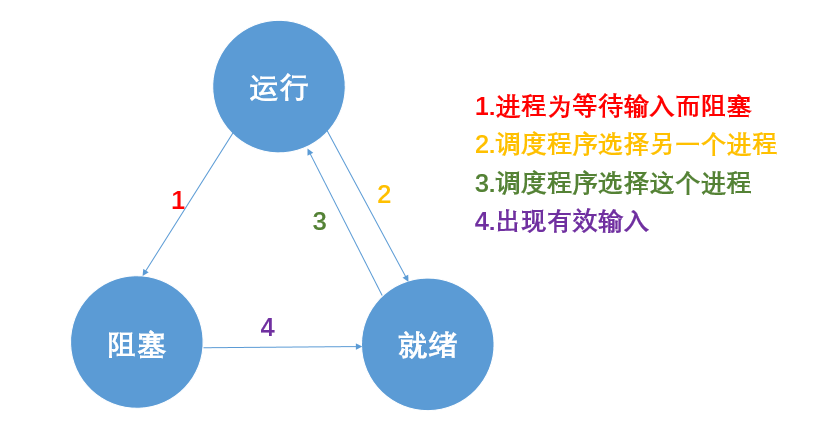
4.进程运行的三种状态
打开一个应用程序,该进程会进入
就绪态,获取CPU资源后,执行程序代码,进入运行态,出现了读写文件with open(...)的IO操作的时候,会进入阻塞态,CPU资源就会被操作系统分配到其他进程。
运行态(Running)(非阻塞):进程已获CPU,正在执行。单处理机系统中,处于执行状态的进程只一个;多处理机系统中,有多个处于执行状态的进程。
就绪态(Ready)(非阻塞):进程已获得除CPU外的所有必要资源,只等待CPU时的状态。一个系统会将多个处于就绪状态的进程排成一个就绪队列。
阻塞态(Blocked)(阻塞):正在执行的进程由于某种原因(文件读写等IO操作)而暂时无法继续执行,便放弃处理机而处于暂停状态,即进程执行受阻。(这种状态又称等待状态或封锁状态)
就绪 → 运行
处于就绪状态的进程,当进程调度程序为之分配了处理器后,该进程便由就绪状态转变成运行状态。
运行 → 就绪
处于执行状态的进程在其执行过程中,因分配给它的一个时间片已用完而不得不让出处理机,于是进程从运行状态转变成就绪状态。
运行 → 阻塞
正在执行的进程因等待某种事件(文件读写等IO操作)发生而无法继续执行时,便从运行状态变成阻塞状态。
阻塞 → 就绪
处于阻塞状态的进程,若其等待的事件已经发生,于是进程由阻塞状态转变为就绪状态。
优化程序效率的核心法则
降低IO操作(硬盘IO、网络IO)
数据获取优先级:
内存 > 本地硬盘 > 网络IO
5.提交任务的2种方式
同步调用:一个任务必须要执行完毕才能执行另一个任务
异步调用:一个任务在执行过程中,可以执行另一个任务
二:进程的使用
1.进程的创建
Windows:CreateProcess
Linux:Fork
2.进程的终止
1.正常退出(自愿;程序执行完毕后,终止,资源被回收)
2.出错退出(自愿;python3 test.py但是test.py不存在)
3.严重错误(非自愿;执行非法指令)
4.被其他进程杀死(非自愿;被操作系统杀死taskkill /F /PID 3333)
三:join方法
0.试试就逝世
import time from multiprocessing import Process def task(n): print('%s run' % n) time.sleep(10000) if __name__ == '__main__': for i in range(10000): p = Process(target=task, args=(1,)) p.start() print('主进程')
1.单个父进程 + 单个子进程
import os import time from multiprocessing import Process def task(n): print(f'task[{os.getpid()}] is running') time.sleep(n) print(f'task[{os.getpid()}] is done') if __name__ == '__main__': # p = Process(target=task, args=(5,)) # args中为元组/列表 p = Process(target=task, kwargs={'n': 5}) # kwargs中为字典 p.start() # 在向发操作系统发送启动子进程的信号,属于IO操作,速度慢 print(f'主进程[{os.getpid()}]') # 主进程[15188] # task[86956] is running # task[86956] is done
2.单个父进程 + 多个子进程 方式1
import os import time from multiprocessing import Process def task(n, name): print(f'task[{name}] is running [{os.getpid()}]') time.sleep(n) print(f'task[{name}] is done [{os.getpid()}]') if __name__ == '__main__': p1 = Process(target=task, args=(2, 'p1')) p2 = Process(target=task, args=(2, 'p2')) p3 = Process(target=task, args=(2, 'p3')) p1.start() # 在向发操作系统发送启动子进程的信号,属于IO操作,速度慢 p2.start() # 在向发操作系统发送启动子进程的信号,属于IO操作,速度慢 p3.start() # 在向发操作系统发送启动子进程的信号,属于IO操作,速度慢 print(f'主进程[{os.getpid()}]') # 主进程[79800] # task[p1] is running [17320] # task[p3] is running [66276] # task[p2] is running [36784] # task[p1] is done [17320] # task[p3] is done [66276] # task[p2] is done [36784]
3.单个父进程 + 多个子进程 方式2
import os import time from multiprocessing import Process class Myprocess(Process): def __init__(self, tag): super().__init__() self.tag = tag def run(self) -> None: # 表示run函数的返回值为空,无返回值 print(f'task[{self.tag}] is running [{os.getpid()}]') time.sleep(3) print(f'task[{self.tag}] is done [{os.getpid()}]') if __name__ == '__main__': p1 = Myprocess('进程1') p2 = Myprocess('进程2') p3 = Myprocess('进程3') p1.start() # 相当于:p1.run,但是p1.run是同步的,所以这里用p1.start p2.start() # p2.run p3.start() # p3.run print(f'主进程[{os.getpid()}]')
并发编程 - 进程
一:进程理论
1.程序 和 进程
程序 就是一堆代码文件,是指令和数据的集合,可以作为目标文件保存在磁盘中,或者作为段存放在内存地址空间中。(静态)
进程 就是一个程序运行的过程,是操作系统进行资源分配和保护的基本单位。(动态)
进程是资源分配的最小单位
1个程序可以对应多个进程,但1个进程只能对应1个程序。进程和程序的关系犹如演出和剧本的关系。
2.并发、并行、串行
串行:多个任务依次运行、一个进程运行完毕,再运行下一个
并行:多个任务是真正意义上一起运行,只有多个CPU才能并行的概念,
并发:多个任务看起来是同时运行的,本质上还是一个个地运行
3.同步 - 异步 / 阻塞 - 非阻塞
同步(慢):
发起一个请求,直到请求返回结果之后,才进行下一步操作。
就像运行一段代码,自上而下一行一行运行,只有上一行代码执行完毕,才能执行下一行代码。
简单来说,同步就是:必须一件事一件事的做,等前一件做完了,才能做下一件事。
异步(快):
发起一个请求后,不管这个请求有没有返回结果,直接可以进行下一步操作。
一般情况下,有一个回调操作。
简单来说,异步就是:可以多件事同时做。
阻塞(慢):
遇到了IO操作,CPU会被操作系统切换到其他进程。
调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
简单来说,阻塞就是:需要买奶茶和冰淇淋,买奶茶的时候奶茶制作过程中只能等,然后买完奶茶再去买冰淇淋。
非阻塞(快):
没有IO操作,一直在运行。
在不能立刻得到结果之前,该调用不会阻塞当前线程。
简单来说,非阻塞就是:需要买奶茶和冰淇淋,买奶茶的时候等的时间去买冰淇淋。
最佳状态:异步 + 非阻塞
拓展:
同步框架:Flask、Django3.0之前
异步框架:Tornado、Sanic、FastAPI
例子:
背景:妈妈出门了,小明想要看电视,但是妈妈让小明烧水。
1.小明烧水,在一旁等待,时不时看一下水有没有烧开。 —— 同步阻塞
2.小明烧水,等待的时间偷偷去看会儿电视,看电视的时候时不时来看一下水有没有烧开。 —— 同步非阻塞
3.小明买了一个水开了之后会响的水壶来烧水,烧水时在一旁等着,不用时不时看水有木有烧开。 —— 异步阻塞
4.小明用那个会响的水壶烧水,然后去看电视,等水开了之后发出响声,再去开。 —— 异步非阻塞
4.进程运行的三种状态
打开一个应用程序,该进程会进入
就绪态,获取CPU资源后,执行程序代码,进入运行态,出现了读写文件with open(...)的IO操作的时候,会进入阻塞态,CPU资源就会被操作系统分配到其他进程。
运行态(Running)(非阻塞):进程已获CPU,正在执行。单处理机系统中,处于执行状态的进程只一个;多处理机系统中,有多个处于执行状态的进程。
就绪态(Ready)(非阻塞):进程已获得除CPU外的所有必要资源,只等待CPU时的状态。一个系统会将多个处于就绪状态的进程排成一个就绪队列。
阻塞态(Blocked)(阻塞):正在执行的进程由于某种原因(文件读写等IO操作)而暂时无法继续执行,便放弃处理机而处于暂停状态,即进程执行受阻。(这种状态又称等待状态或封锁状态)
就绪 → 运行
处于就绪状态的进程,当进程调度程序为之分配了处理器后,该进程便由就绪状态转变成运行状态。
运行 → 就绪
处于执行状态的进程在其执行过程中,因分配给它的一个时间片已用完而不得不让出处理机,于是进程从运行状态转变成就绪状态。
运行 → 阻塞
正在执行的进程因等待某种事件(文件读写等IO操作)发生而无法继续执行时,便从运行状态变成阻塞状态。
阻塞 → 就绪
处于阻塞状态的进程,若其等待的事件已经发生,于是进程由阻塞状态转变为就绪状态。
优化程序效率的核心法则
降低IO操作(硬盘IO、网络IO)
数据获取优先级:
内存 > 本地硬盘 > 网络IO
5.提交任务的2种方式
同步调用:一个任务必须要执行完毕才能执行另一个任务
异步调用:一个任务在执行过程中,可以执行另一个任务
二:进程的使用
1.进程的创建
Windows:CreateProcess
Linux:Fork
2.进程的终止
1.正常退出(自愿;程序执行完毕后,终止,资源被回收)
2.出错退出(自愿;python3 test.py但是test.py不存在)
3.严重错误(非自愿;执行非法指令)
4.被其他进程杀死(非自愿;被操作系统杀死taskkill /F /PID 3333)
三:join方法
0.试试就逝世
1.单个父进程 + 单个子进程
2.单个父进程 + 多个子进程 方式1
3.单个父进程 + 多个子进程 方式2
4.进程之间的数据是隔离的
因为:开启1个进程,就是开启了1个Python解释器。
Windows下要开进程,需要在main函数下
import os import time from multiprocessing import Process age = 18 def task(n, name): global age # 局部修改全局 age = 99 print(f'task[{name}] is running [{os.getpid()}]') time.sleep(n) print(f'task[{name}] is done [{os.getpid()}]') print(f'子进程的age:{age}') if __name__ == '__main__': p1 = Process(target=task, args=(1, 'p1')) p1.start() print(f'主进程[{os.getpid()}]') print(f'主进程的age:{age}') # 主进程[2680] # 主进程的age:18 # task[p1] is running [45116] # task[p1] is done [45116] # 子进程的age:99
5.join - 让子进程的开启者 等p1开启并运行完毕后 再运行
import os import time from multiprocessing import Process def task(n, name): print(f'task[{name}] is running [{os.getpid()}]') time.sleep(n) print(f'task[{name}] is done [{os.getpid()}]') if __name__ == '__main__': p1 = Process(target=task, args=(2, 'p1')) p1.start() # 在向发操作系统发送启动子进程的信号,属于IO操作,速度慢 p1.join() # join让子进程执行完成 print(f'主进程[{os.getpid()}]') # task[p1] is running [47164] # task[p1] is done [47164] # 主进程[44356]
不用join - 不等待 耗时0.几秒
import os import time from multiprocessing import Process def task(n, name): print(f'task[{name}] is running [{os.getpid()}]') time.sleep(n) print(f'task[{name}] is done [{os.getpid()}]') if __name__ == '__main__': ctime = time.time() p1 = Process(target=task, args=(1, 'p1')) p2 = Process(target=task, args=(2, 'p1')) p1.start() p2.start() # p1.join() # p2.join() print(f'主进程[{os.getpid()}]') print(time.time() - ctime) # 不用join # 主进程[59116] # 0.020940065383911133 # task[p1] is running [89420] # task[p1] is running [91328] # task[p1] is done [89420] # task[p1] is done [91328]
只用p1.join - 等待p1执行完毕再执行主进程
import os import time from multiprocessing import Process def task(n, name): print(f'task[{name}] is running [{os.getpid()}]') time.sleep(n) print(f'task[{name}] is done [{os.getpid()}]') if __name__ == '__main__': ctime = time.time() p1 = Process(target=task, args=(1, 'p1')) p2 = Process(target=task, args=(2, 'p2')) p1.start() p2.start() p1.join() # p2.join() print(f'主进程[{os.getpid()}]') print(time.time() - ctime) # 只用p1.join # task[p1] is running [61892] # task[p2] is running [38660] # task[p1] is done [61892] # 主进程[47172] # 1.1537489891052246 # task[p2] is done [38660]
只用p2.join - 等待p2执行完毕再执行主进程
import os import time from multiprocessing import Process def task(n, name): print(f'task[{name}] is running [{os.getpid()}]') time.sleep(n) print(f'task[{name}] is done [{os.getpid()}]') if __name__ == '__main__': ctime = time.time() p1 = Process(target=task, args=(1, 'p1')) p2 = Process(target=task, args=(2, 'p2')) p1.start() p2.start() # p1.join() p2.join() print(f'主进程[{os.getpid()}]') print(time.time() - ctime) # 只用p2.join # task[p1] is running [56056] # task[p2] is running [47384] # task[p1] is done [56056] # task[p2] is done [47384] # 主进程[3424] # 2.159543514251709
同时p1.join和p2.join - 时间取决于最长的那个
import os import time from multiprocessing import Process def task(n, name): print(f'task[{name}] is running [{os.getpid()}]') time.sleep(n) print(f'task[{name}] is done [{os.getpid()}]') if __name__ == '__main__': ctime = time.time() p1 = Process(target=task, args=(1, 'p1')) p2 = Process(target=task, args=(2, 'p2')) p1.start() p2.start() p1.join() p2.join() print(f'主进程[{os.getpid()}]') print(time.time() - ctime) # p1.join + p2.join # task[p1] is running [56056] # task[p2] is running [47384] # task[p1] is done [56056] # task[p2] is done [47384] # 主进程[3424] # 2.159543514251709
6.join - 运行多个子进程 - 串行
import os import time from multiprocessing import Process def task(n, name): print(f'task[{name}] is running [{os.getpid()}]') time.sleep(n) print(f'task[{name}] is done [{os.getpid()}]') if __name__ == '__main__': p1 = Process(target=task, args=(2, 'p1')) p2 = Process(target=task, args=(3, 'p2')) p3 = Process(target=task, args=(4, 'p3')) start = time.time() p1.start() p1.join() p2.start() p2.join() p3.start() p3.join() print(f'主进程[{os.getpid()}]') print('耗时:', time.time() - start) # task[p1] is running [72452] # task[p1] is done [72452] # task[p2] is running [31540] # task[p2] is done [31540] # task[p3] is running [62568] # task[p3] is done [62568] # 主进程[11548] # 耗时: 9.440884351730347
7.join - 运行多个子进程 - 并发
import os import time from multiprocessing import Process def task(n, name): print(f'task[{name}] is running [{os.getpid()}]') time.sleep(n) print(f'task[{name}] is done [{os.getpid()}]') if __name__ == '__main__': p1 = Process(target=task, args=(2, 'p1')) p2 = Process(target=task, args=(3, 'p2')) p3 = Process(target=task, args=(4, 'p3')) start = time.time() p1.start() p2.start() p3.start() p1.join() # 此时,p1、p2、p3的join顺序已经不重要了 p2.join() p3.join() print(f'主进程[{os.getpid()}]') print('耗时:', time.time() - start) # task[p2] is running [47248] # task[p3] is running [46152] # task[p1] is running [43612] # task[p1] is done [43612] # task[p2] is done [47248] # task[p3] is done [46152] # 主进程[3776] # 耗时: 4.173335313796997
四:进程调度
想要多个进程交替运行,就需要操作系统来调度CPU的时间片
1.先来先服务(FCFS)(First Come First Serve)
先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。
FCFS算法比较有利于长作业(进程),而不利于短作业(进程)。
由此可知,本算法适合于CPU繁忙型作业,而不利于I/O繁忙型的作业(进程)。
2.短作业优先
短作业(进程)优先调度算法(SJ/PF)是指对短作业或短进程优先调度的算法,该算法既可用于作业调度,也可用于进程调度。
但其对长作业不利;不能保证紧迫性作业(进程)被及时处理;作业的长短只是被估算出来的。
3.时间片轮转
时间片轮转(Round Robin,RR)法的基本思路是让每个进程在就绪队列中的等待时间与享受服务的时间成比例。
在时间片轮转法中,需要将CPU的处理时间分成固定大小的时间片,例如,几十毫秒至几百毫秒。
如果一个进程在被调度选中之后用完了系统规定的时间片,但又未完成要求的任务,则它自行释放自己所占有的CPU而排到就绪队列的末尾,等待下一次调度。
同时,进程调度程序又去调度当前就绪队列中的第一个进程。
4.多级反馈队列
前面介绍的各种用作进程调度的算法都有一定的局限性。
如短进程优先的调度算法,仅照顾了短进程而忽略了长进程,而且如果并未指明进程的长度,则短进程优先和基于进程长度的抢占式调度算法都将无法使用。
而多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。
五:僵尸进程 与 孤儿进程
1.僵尸进程
进程结束之后,还有数据没回收。
子进程结束后,父进程未将子进程资源回收,该子进程就编程了僵尸进程。
2.孤儿进程
主进程结束了,子进程还没结束。
父进程结束了,子进程未结束,该子进程变成了孤儿进程。
该子进程就会被专门的进程接管。
六:进程对象 及 其他方法
1.每一个进程 都会有自己的ID号,这个ID叫做PID
每个程序都可以有多个进程
2.Windows中查看进程
tasklist |findstr python
3.Linux、Mac中查看进程
ps aux |grep
4.进程对象:
p = Process(target = task, ) 或者是在进程内部:current_process()
5.查看当前进程的ID:
p.pid、os.getpid()或者current_process().pid
6.获取父进程ID号:
os.getppid(),子进程中获取父进程ID号,等于父进程的ID号
7.查看当前进程是否存活:
p.is_alive()或者current_process().is_alive()
8.主进程的父进程
是pycharm,pycharm的父进程是系统(centos6中是init,centos7及以后是system)
9.关闭进程:
p.terminate(),只能在主进程中关闭子进程
七:守护进程
主进程结束之后,守护进程也随它而去,不会变成孤儿进程
进程名.daemon = True一定要加在进程名.start()之前
import os import time from multiprocessing import Process def task(): print(f'子进程开始,ID为:{os.getpid()}') time.sleep(100) print('子进程结束') if __name__ == '__main__': p = Process(target=task,) # 守护进程:主进程一旦结束,子进程也结束 p.daemon = True # 一定要加在启动之前,将p进程设置为主进程的守护进程 p.start() time.sleep(1) print('主进程') print(f'主进程ID:{os.getpid()}') # 子进程开始,ID为:17324 # 主进程 # 主进程ID:66772
问题:
1.主进程的父进程是谁?
pycharm
2.主进程开了很多子进程,每个都需要设置守护进程吗?
根据需求来设置,如果需要,就设置:p.deamon = True
八:互斥锁
多个进程操作同一份数据的时候,会出现数据错乱的问题
针对上述问题,解决方式就是加锁处理:将并行变成串行,牺牲效率但是保证了数据的安全
json字符串转换网站:json.cn
多个人同时抢锁,只有一个人可以拿到,必须释放,其他人才能拿到。
例子:
10个人抢票,票只有1张,10个人可以同时查票,但是能买到票的只有1个,这个人买到票之后,其他的人就没票可以买了
ticket.txt
{"ticket_count": 1}
mylock.py
import json import time import random from multiprocessing import Process, Lock # 查票 def search(): # 打开文件,读出ticket_couont with open('ticket.txt', mode='r', encoding='UTF-8') as f: dic = json.load(f) # print(dic['ticket']) print(f'剩余票量:{dic.get("ticket_count")}') # 买票 def buy(): with open('ticket.txt', mode='r', encoding='UTF-8') as f: dic = json.load(f) time.sleep(random.randint(1, 3)) # 模拟网络延迟 if dic.get('ticket_count') > 0: # # 余票大于0,能够买票 dic['ticket_count'] -= 1 # 保存到文件中 with open('ticket.txt', mode='w', encoding='UTF-8') as f: json.dump(dic, f) print('买票成功!') else: print('余票不足,买票失败!') # 写一个函数,先查票,再买票 def task(mutex): search() # 买票过程 需要加锁 # 买前加锁 # mutex.acquire() # buy() # 10个进程,编程了串行 # # 买后释放锁 # mutex.release() with mutex: buy() if __name__ == '__main__': # 锁的创建 应该设置在主进程中 mutex = Lock() # 创建一把锁 # 模拟10个人查票+买票(开10个进程) for i in range(10): t = Process(target=task, args=(mutex,)) t.start()
了解:
分布式锁、悲观锁、乐观锁
九:队列介绍
队列可以并发的派多个线程,对排列的线程处理,并且每个需要处理线程只需要将请求的数据放入队列容器的内存中,线程不需要等待,当排列完毕处理完数据后,线程在准时来取数据即可。
请求数据的线程只与这个队列容器存在关系,处理数据的线程down掉不会影响到请求数据的线程,队列会派给其他线程处理这分数据,它实现了解耦,提高效率。
队列内会有一个有顺序的容器,列表与这个容器是有区别的,列表中数据虽然是排列的,但数据被取走后还会保留,而队列中这个容器的数据被取后将不会保留。
当必须在多个线程之间安全地交换信息时,队列在线程编程中特别有用。
1.作用
解耦:使程序直接实现松耦合,修改一个函数,不会有串联关系。
提高处理效率:FIFO = 先进先出,LIFO = 后入先出。
2.队列的各个参数
from multiprocessing.queues import Queue Queue.Queue(maxsize=0) # FIFO, 如果maxsize小于1就表示队列长度无限 Queue.LifoQueue(maxsize=0) # LIFO, 如果maxsize小于1就表示队列长度无限 Queue.qsize() # 返回队列的大小 Queue.empty() # 如果队列为空,返回True,反之False Queue.full() # 如果队列满了,返回True,反之False Queue.get([block[, timeout]]) # 读队列,取出数据 ,没有数据将会等待timeout等待时间 Queue.put(item, [block[, timeout]]) # 写队列,放入数据,timeout等待时间 Queue.queue.clear() # 清空队列 class queue.PriorityQueue(maxsize=0) # 存储数据时可设置优先级的队列,优先级设置数越小等级越高 Queue.get(timeout=1) # 如果1秒后没取到数据就退出 Queue.get_nowait() # 取数据,如果没数据抛queue.Empty异常 Queue.task_done() # 后续调用告诉队列,任务的处理是完整的。
3.实例
from multiprocessing import Queue # 实例化得到要给的对象 q = Queue(5) # 默认很大,可以放很多,写了个5,只能放5个 # 往管道中放值 q.put(1) q.put('xxq') q.put(18) q.put(18) q.put(18) # 从管道中取值 # print(q.get()) # print(q.get()) # print(q.get(timeout=0.1)) # 等0.1s还没有值,就结束 # print(q.get_nowait()) # 不等了,有就是有,没有就是没有 print(q.empty()) # 看一下队列是不是空的 False print(q.full()) # 看一下队列是不是满的 True
并发编程 - 进程
一:进程理论
1.程序 和 进程
程序 就是一堆代码文件,是指令和数据的集合,可以作为目标文件保存在磁盘中,或者作为段存放在内存地址空间中。(静态)
进程 就是一个程序运行的过程,是操作系统进行资源分配和保护的基本单位。(动态)
进程是资源分配的最小单位
1个程序可以对应多个进程,但1个进程只能对应1个程序。进程和程序的关系犹如演出和剧本的关系。
2.并发、并行、串行
串行:多个任务依次运行、一个进程运行完毕,再运行下一个
并行:多个任务是真正意义上一起运行,只有多个CPU才能并行的概念,
并发:多个任务看起来是同时运行的,本质上还是一个个地运行
3.同步 - 异步 / 阻塞 - 非阻塞
同步(慢):
发起一个请求,直到请求返回结果之后,才进行下一步操作。
就像运行一段代码,自上而下一行一行运行,只有上一行代码执行完毕,才能执行下一行代码。
简单来说,同步就是:必须一件事一件事的做,等前一件做完了,才能做下一件事。
异步(快):
发起一个请求后,不管这个请求有没有返回结果,直接可以进行下一步操作。
一般情况下,有一个回调操作。
简单来说,异步就是:可以多件事同时做。
阻塞(慢):
遇到了IO操作,CPU会被操作系统切换到其他进程。
调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
简单来说,阻塞就是:需要买奶茶和冰淇淋,买奶茶的时候奶茶制作过程中只能等,然后买完奶茶再去买冰淇淋。
非阻塞(快):
没有IO操作,一直在运行。
在不能立刻得到结果之前,该调用不会阻塞当前线程。
简单来说,非阻塞就是:需要买奶茶和冰淇淋,买奶茶的时候等的时间去买冰淇淋。
最佳状态:异步 + 非阻塞
拓展:
同步框架:Flask、Django3.0之前
异步框架:Tornado、Sanic、FastAPI
例子:
背景:妈妈出门了,小明想要看电视,但是妈妈让小明烧水。
1.小明烧水,在一旁等待,时不时看一下水有没有烧开。 —— 同步阻塞
2.小明烧水,等待的时间偷偷去看会儿电视,看电视的时候时不时来看一下水有没有烧开。 —— 同步非阻塞
3.小明买了一个水开了之后会响的水壶来烧水,烧水时在一旁等着,不用时不时看水有木有烧开。 —— 异步阻塞
4.小明用那个会响的水壶烧水,然后去看电视,等水开了之后发出响声,再去开。 —— 异步非阻塞
4.进程运行的三种状态
打开一个应用程序,该进程会进入
就绪态,获取CPU资源后,执行程序代码,进入运行态,出现了读写文件with open(...)的IO操作的时候,会进入阻塞态,CPU资源就会被操作系统分配到其他进程。
运行态(Running)(非阻塞):进程已获CPU,正在执行。单处理机系统中,处于执行状态的进程只一个;多处理机系统中,有多个处于执行状态的进程。
就绪态(Ready)(非阻塞):进程已获得除CPU外的所有必要资源,只等待CPU时的状态。一个系统会将多个处于就绪状态的进程排成一个就绪队列。
阻塞态(Blocked)(阻塞):正在执行的进程由于某种原因(文件读写等IO操作)而暂时无法继续执行,便放弃处理机而处于暂停状态,即进程执行受阻。(这种状态又称等待状态或封锁状态)
就绪 → 运行
处于就绪状态的进程,当进程调度程序为之分配了处理器后,该进程便由就绪状态转变成运行状态。
运行 → 就绪
处于执行状态的进程在其执行过程中,因分配给它的一个时间片已用完而不得不让出处理机,于是进程从运行状态转变成就绪状态。
运行 → 阻塞
正在执行的进程因等待某种事件(文件读写等IO操作)发生而无法继续执行时,便从运行状态变成阻塞状态。
阻塞 → 就绪
处于阻塞状态的进程,若其等待的事件已经发生,于是进程由阻塞状态转变为就绪状态。
优化程序效率的核心法则
降低IO操作(硬盘IO、网络IO)
数据获取优先级:
内存 > 本地硬盘 > 网络IO
5.提交任务的2种方式
同步调用:一个任务必须要执行完毕才能执行另一个任务
异步调用:一个任务在执行过程中,可以执行另一个任务
二:进程的使用
1.进程的创建
Windows:CreateProcess
Linux:Fork
2.进程的终止
1.正常退出(自愿;程序执行完毕后,终止,资源被回收)
2.出错退出(自愿;python3 test.py但是test.py不存在)
3.严重错误(非自愿;执行非法指令)
4.被其他进程杀死(非自愿;被操作系统杀死taskkill /F /PID 3333)
三:join方法
0.试试就逝世
1.单个父进程 + 单个子进程
2.单个父进程 + 多个子进程 方式1
3.单个父进程 + 多个子进程 方式2
4.进程之间的数据是隔离的
因为:开启1个进程,就是开启了1个Python解释器。
Windows下要开进程,需要在main函数下
5.join - 让子进程的开启者 等p1开启并运行完毕后 再运行
不用join - 不等待 耗时0.几秒
只用p1.join - 等待p1执行完毕再执行主进程
只用p2.join - 等待p2执行完毕再执行主进程
同时p1.join和p2.join - 时间取决于最长的那个
6.join - 运行多个子进程 - 串行
7.join - 运行多个子进程 - 并发
四:进程调度
想要多个进程交替运行,就需要操作系统来调度CPU的时间片
1.先来先服务(FCFS)(First Come First Serve)
先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。
FCFS算法比较有利于长作业(进程),而不利于短作业(进程)。
由此可知,本算法适合于CPU繁忙型作业,而不利于I/O繁忙型的作业(进程)。
2.短作业优先
短作业(进程)优先调度算法(SJ/PF)是指对短作业或短进程优先调度的算法,该算法既可用于作业调度,也可用于进程调度。
但其对长作业不利;不能保证紧迫性作业(进程)被及时处理;作业的长短只是被估算出来的。
3.时间片轮转
时间片轮转(Round Robin,RR)法的基本思路是让每个进程在就绪队列中的等待时间与享受服务的时间成比例。
在时间片轮转法中,需要将CPU的处理时间分成固定大小的时间片,例如,几十毫秒至几百毫秒。
如果一个进程在被调度选中之后用完了系统规定的时间片,但又未完成要求的任务,则它自行释放自己所占有的CPU而排到就绪队列的末尾,等待下一次调度。
同时,进程调度程序又去调度当前就绪队列中的第一个进程。
4.多级反馈队列
前面介绍的各种用作进程调度的算法都有一定的局限性。
如短进程优先的调度算法,仅照顾了短进程而忽略了长进程,而且如果并未指明进程的长度,则短进程优先和基于进程长度的抢占式调度算法都将无法使用。
而多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。
五:僵尸进程 与 孤儿进程
1.僵尸进程
进程结束之后,还有数据没回收。
子进程结束后,父进程未将子进程资源回收,该子进程就编程了僵尸进程。
2.孤儿进程
主进程结束了,子进程还没结束。
父进程结束了,子进程未结束,该子进程变成了孤儿进程。
该子进程就会被专门的进程接管。
六:进程对象 及 其他方法
1.每一个进程 都会有自己的ID号,这个ID叫做PID
每个程序都可以有多个进程
2.Windows中查看进程
3.Linux、Mac中查看进程
4.进程对象:
p = Process(target = task, ) 或者是在进程内部:current_process()
5.查看当前进程的ID:
p.pid、os.getpid()或者current_process().pid
6.获取父进程ID号:
os.getppid(),子进程中获取父进程ID号,等于父进程的ID号
7.查看当前进程是否存活:
p.is_alive()或者current_process().is_alive()
8.主进程的父进程
是pycharm,pycharm的父进程是系统(centos6中是init,centos7及以后是system)
9.关闭进程:
p.terminate(),只能在主进程中关闭子进程
七:守护进程
主进程结束之后,守护进程也随它而去,不会变成孤儿进程
进程名.daemon = True一定要加在进程名.start()之前
问题:
1.主进程的父进程是谁?
pycharm
2.主进程开了很多子进程,每个都需要设置守护进程吗?
根据需求来设置,如果需要,就设置:p.deamon = True
八:互斥锁
多个进程操作同一份数据的时候,会出现数据错乱的问题
针对上述问题,解决方式就是加锁处理:将并行变成串行,牺牲效率但是保证了数据的安全
json字符串转换网站:json.cn
多个人同时抢锁,只有一个人可以拿到,必须释放,其他人才能拿到。
例子:
10个人抢票,票只有1张,10个人可以同时查票,但是能买到票的只有1个,这个人买到票之后,其他的人就没票可以买了
ticket.txt
{"ticket_count": 1}mylock.py
了解:
分布式锁、悲观锁、乐观锁
九:队列介绍
队列可以并发的派多个线程,对排列的线程处理,并且每个需要处理线程只需要将请求的数据放入队列容器的内存中,线程不需要等待,当排列完毕处理完数据后,线程在准时来取数据即可。
请求数据的线程只与这个队列容器存在关系,处理数据的线程down掉不会影响到请求数据的线程,队列会派给其他线程处理这分数据,它实现了解耦,提高效率。
队列内会有一个有顺序的容器,列表与这个容器是有区别的,列表中数据虽然是排列的,但数据被取走后还会保留,而队列中这个容器的数据被取后将不会保留。
当必须在多个线程之间安全地交换信息时,队列在线程编程中特别有用。
1.作用
解耦:使程序直接实现松耦合,修改一个函数,不会有串联关系。
提高处理效率:FIFO = 先进先出,LIFO = 后入先出。
2.队列的各个参数
3.实例
4.总结
q = Queue(队列大小) # 放值 q.put('xxq') q.put_nowait(asd) # 队列满了,放不进去就不放了,报错 # 取值 q.get() # 从队列头部取出一个值 q.get_nowait() # 从队列头部取值,没有就报错 # 队列是否为空,是否满 print(q.empty()) # 看一下队列是不是空的 print(q.full()) # 看一下队列是不是满的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号