
数据的修改与删除,字段的高级用法sourse,模型类序列化器,高级用法之SerializerMethodField drf的请求与响应 many=True源码分析,及局部全局钩子源码解析
一、 修改,删除接口
views.py
def put(self, request, id): # 通过id取到对象 res = {'code': 100, 'msg': ''} try: book = models.Book.objects.get(id=id) ser = BookSerializer(instance=book, data=request.data) ser.is_valid(raise_exception=True) ser.save() res['msg'] = '修改成功' res['result'] = ser.data except Exception as e: res['code'] = 101 res['msg'] = str(e) return Response(res) def delete(self,request,id): response = {'code': 100, 'msg': '删除成功'} models.Book.objects.filter(id=id).delete() return Response(response)
serializer.py
class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) title = serializers.CharField(max_length=32,min_length=2) price = serializers.DecimalField(max_digits=5, decimal_places=2) publish = serializers.CharField(max_length=32) def create(self, validated_data): res=models.Book.objects.create(**validated_data) print(res) return res def update(self, book, validated_data): book.title=validated_data.get('title') book.price=validated_data.get('price') book.publish=validated_data.get('publish') book.save() return book
二、高级用法之source修改返回到前端的字段名
1.#source = title 字段名就不能叫title
#source = '字段名' 该字段名必须是表中拥有的,然后赋值给name(自己想要在前端看到的字段名)
name = serializers.CharField(max_length=32,min_length=2,source='title')
2 如果表模型中有方法
#执行表模型中的方法,并且把返回值赋值给xxx,且xxx这个变量名的命名不能与test相同
xxx = serializers.CharField(source='test')
3 source支持跨表操作
addr = serializers.CharField(source='publish.addr')
有时间去看源码
3 模型类序列化器
1 原来用的Serilizer跟表模型没有直接联系,模型类序列化ModelSerilizer,跟表模型有对应关系
2 使用
class BookModelSerializer(serializers.ModelSerializer):
model=models.Book (表模型) #跟那个表模型建立关系
fields=[字段,字段] #序列化的字段,反序列化的字段
fields='__all__' #所有字段都序列化反序列化
exclude=[字段,字段] #排除那些字段(不能跟fields同时使用)
read_only_fields=['price','publish'] #序列化显示的字段
weite_only_fields=['title'] #反序列化需要传入的字段
extra_kwargs = {'title':{'max_length':32,'write_only':True}}
depth = 1 #了解,跨表1查询,最多建议写3
#重写某些字段
publish = serializers.CharField(max_length=32,source='publish.name')
#局部钩子,全局钩子,跟原来完全一样
3 新增,修改
-统统不用重写create和update方法了,在ModelSerializer中重写了create和update
四 高级用法之SerializerMethodField
class BookSerializer(serializers.Serializer):
id = serializers.IntegerField(required=False)
name = serializers.CharField(max_length=32,min_length=2,source='title')
price = serializers.DecimalField(max_digits=5, decimal_places=2)
publish = serializers.SerializerMethodField() #必须与get_字段名一起使用
def get_publish(self,obj): (需要2个参数,第二个参数obj是当前表的对象)
dic={'name':obj.publish.name,'addr':obj.publish.addr}
return dic
class BookModelSerializer(serializers.ModelSerializer): #用ModelSerializer与上面用法相同
class Meta:
model = models.Book
fields = '__all__'
publish = serializers.SerializerMethodField()
def get_publish(self,obj):
dic={'name':obj.publish.name,'addr':obj.publish.addr}
return dic
## 第三中方案,使用序列化类的嵌套(效果与上面一样)
class PublishSerializer(serializers.ModelSerializer):
class Meta:
model = models.Publish
# fields = '__all__'
fields = ['name','addr']
class BookModelSerializer(serializers.ModelSerializer):
publish = PublishSerializer()
class Meta:
model = models.Book
fields = '__all__'
五、drf的请求与响应
#Request -data:前端以post提交的数据都在它中 -FILES: 前端提交的文件 -query_params:就是原来的request.GET -重写了__getattr__ -使用新的request.method其实取得就是原生request.method(通过反射实现) # Response -from rest_framework.response import Response -data:响应的字典 -status:http响应的状态码 -drf提供给你了所有的状态码,以及它的意思 from rest_framework.status import HTTP_201_CREATED -template_name:模板名字(一般不动),了解 -headers:响应头,字典 -content_type:响应的编码方式,了解 # 自己封装一个Response对象 class CommonResponse: def __init__(self): self.code=100 self.msg='' @property def get_dic(self): return self.__dict__ # 自己封装一个response,继承drf的Response # 通过配置,选择默认模板的显示形式(浏览器方式,json方式) -配置文件方式(全局) -如果没有配置,默认有浏览器和json -drf有默认配置文件 from rest_framework.settings import DEFAULTS REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES': ( # 默认响应渲染类 'rest_framework.renderers.JSONRenderer', # json渲染器 'rest_framework.renderers.BrowsableAPIRenderer', # 浏览API渲染器 ) } -在视图类中配置(局部) -粒度更小 -class BookDetail(APIView): renderer_classes=[JSONRenderer,]
六、 many=True源码分析,局部全局钩子
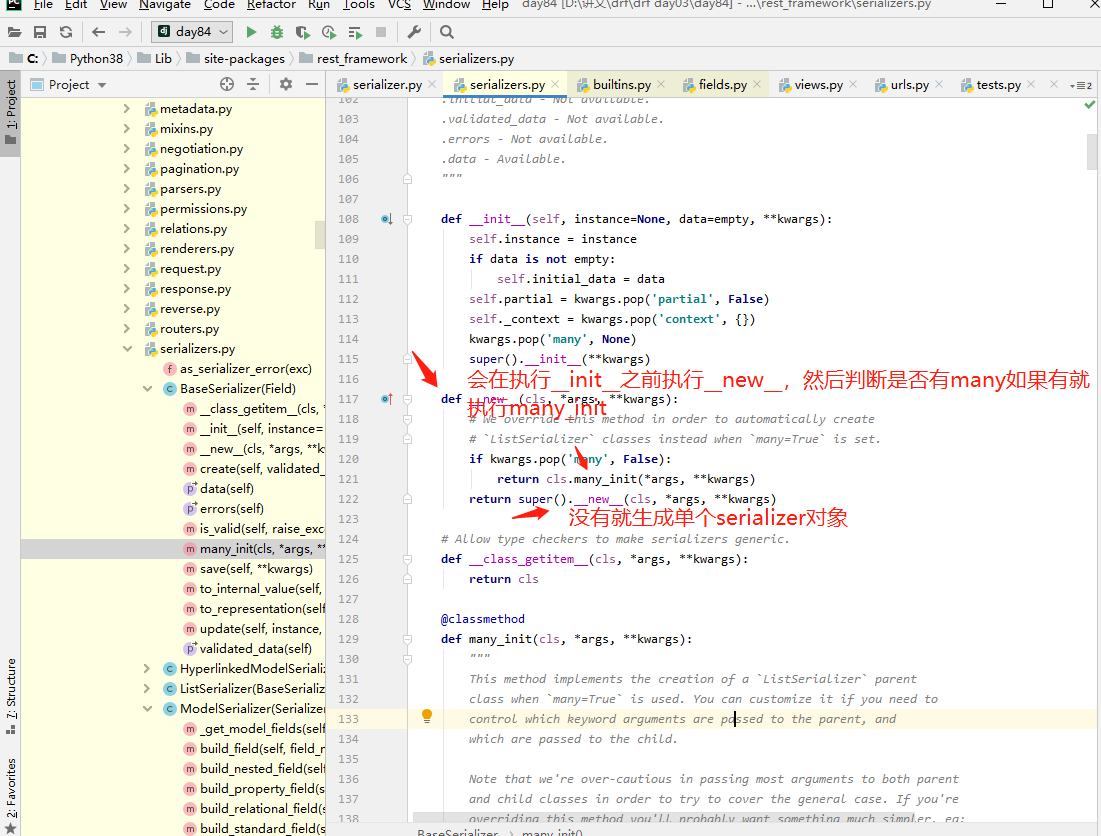
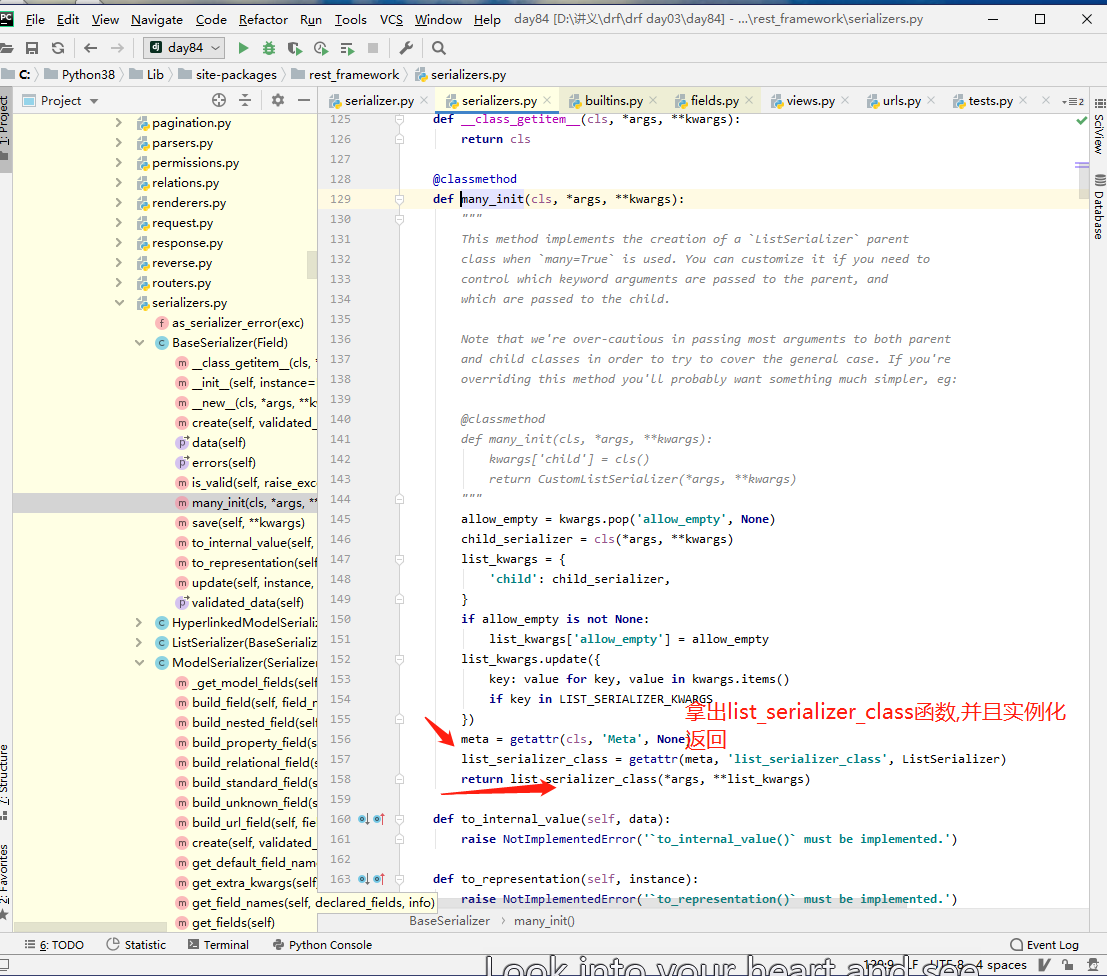
1 many=True -__init__----->一路找到了BaseSerializer---》__new__决定了生成的对象是谁
# __new__如果有many会生成一个类似于列表的对象,列表内放置了多个serializer,没有会生成单个的serializer对象
2 入口是is_valid()---》BaseSerializer--》is_valid---》self._validated_data = self.run_validation(self.initial_data)
-Serializer这个类的:self.run_validation
"""
is_valid可以在BaseSerializer类中找到 在is_valid中有 self._validated_data = self.run_validation(self.initial_data)(可以在Serializer类中找到)
value = self.to_internal_value(data)(data指的是字段的值)在该方法中,通过循环判断是否有局部钩子,如果有进行局部校验,有报错,通过Except接收返回,没有直接返回该字段值。
"""
def run_validation(self, data=empty): value = self.to_internal_value(data) # 局部字段自己的校验和局部钩子校验 try: self.run_validators(value) value = self.validate(value) # 全局钩子的校验 except (ValidationError, DjangoValidationError) as exc: raise ValidationError(detail=as_serializer_error(exc)) return value

 浙公网安备 33010602011771号
浙公网安备 33010602011771号