云计算实验一
实验一 HADOOP实验-HDFS与MAPREDUCE操作
一、实验目的
1、利用虚拟机搭建集群部署hadoop
2、HDFS文件操作以及文件接口编程;
3、MAPREDUCE并行程序开发、发布与调用。
二、实验内容
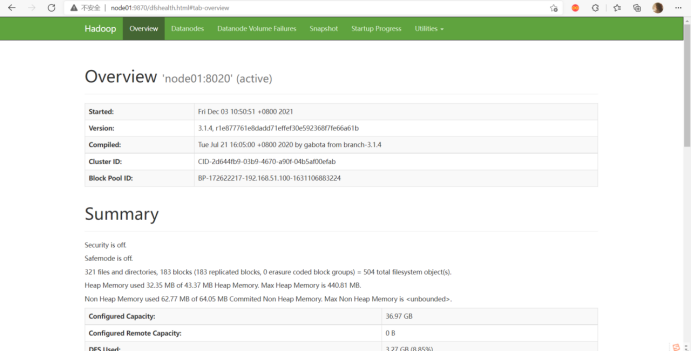
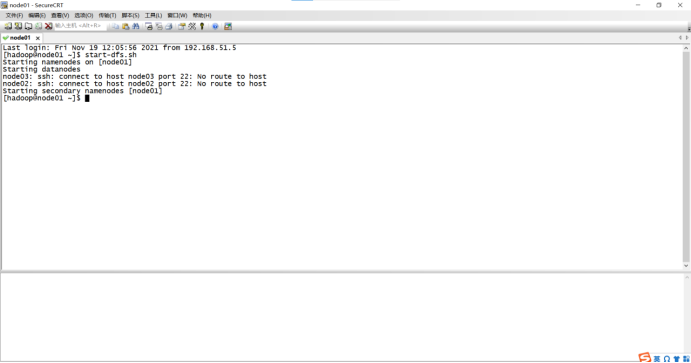
1、虚拟机集群搭建部署hadoop
利用VMware、centOS-7、Xshell(secureCrt)等软件搭建集群部署hadoop,具体操作参照
https://www.bilibili.com/video/BV1Kf4y1z7Nw?p=1
2、HDFS文件操作
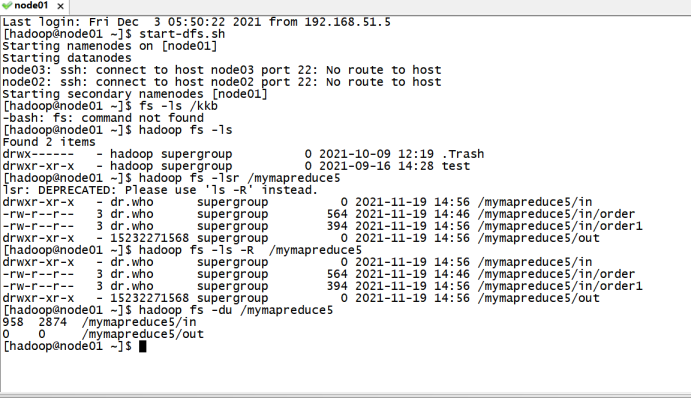
在分布式文件系统上验证HDFS文件命令
2.1 HDFS接口编程
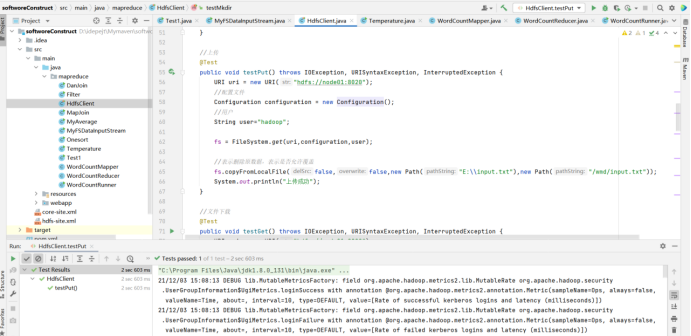
调用HDFS文件接口实现对分布式文件系统中文件的访问,如创建、修改、删除等。
代码:

package mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.After;
import org.junit.Before;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays;
public class HdfsClient {
private FileSystem fs;
@After
public void close() throws IOException {
//关闭资源
fs.close();
}
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException {
//连接的集群地址
URI uri = new URI("hdfs://node01:8020");
//配置文件
Configuration configuration = new Configuration();
//用户
String user="hadoop";
fs = FileSystem.get(uri,configuration,user);
//创建文件
fs.mkdirs(new Path("/std/wmd"));
System.out.println("创建成功");
}
//上传
@Test
public void testPut() throws IOException, URISyntaxException, InterruptedException {
URI uri = new URI("hdfs://node01:8020");
//配置文件
Configuration configuration = new Configuration();
//用户
String user="hadoop";
fs = FileSystem.get(uri,configuration,user);
//表示删除原数据,表示是否允许覆盖
fs.copyFromLocalFile(false,false,new Path("E:\\input.txt"),new Path("/wmd/input.txt"));
System.out.println("上传成功");
}
//文件下载
@Test
public void testGet() throws IOException, URISyntaxException, InterruptedException {
URI uri = new URI("hdfs://node01:8020");
//配置文件
Configuration configuration = new Configuration();
//用户
String user="hadoop";
fs = FileSystem.get(uri,configuration,user);
fs.copyToLocalFile(false,new Path("hdfs://node01/wmd/input.txt"),new Path("D:\\"),true);
System.out.println("下载成功");
}
//文件删除
@Test
public void testRm() throws IOException, URISyntaxException, InterruptedException {
//删除文件
//参数解读:是否递归删除
//fs.delete(new Path("文件名"),false);
//删除非空目录
//fs.delete("",true);
URI uri = new URI("hdfs://node01:8020");
//配置文件
Configuration configuration = new Configuration();
//用户
String user="hadoop";
fs = FileSystem.get(uri,configuration,user);
fs.delete(new Path("hdfs://node01/std"),true);
System.out.println("删除成功");
}
//文件的更名和移动
@Test
public void testMv() throws IOException, URISyntaxException, InterruptedException {
URI uri = new URI("hdfs://node01:8020");
//配置文件
Configuration configuration = new Configuration();
//用户
String user="hadoop";
fs = FileSystem.get(uri,configuration,user);
//同目录下进行更名
fs.rename(new Path("/wmd/wmdym.txt"),new Path("/wmd.txt"));
System.out.println("移动成功");
//目录更名
//fs.rename(new Path("/tiansui"),new Path("/dym"));
}
//获取文件详细信息
@Test
public void fileDetail() throws IOException, URISyntaxException, InterruptedException {
URI uri = new URI("hdfs://node01:8020");
//配置文件
Configuration configuration = new Configuration();
//用户
String user="hadoop";
fs = FileSystem.get(uri,configuration,user);
//获取文件所有信息
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
//遍历文件
while (listFiles.hasNext()) {
//本地文件状态
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("============="+fileStatus.getPath()+"==============");
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
}
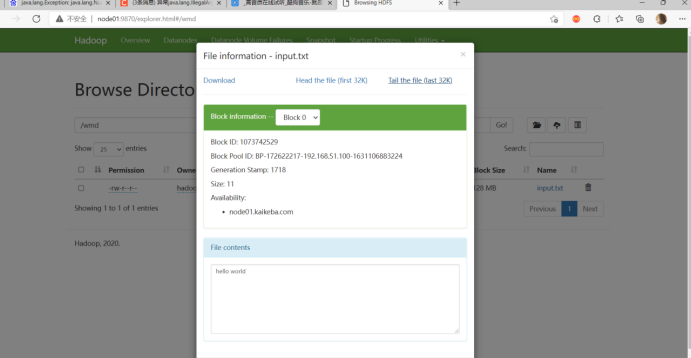
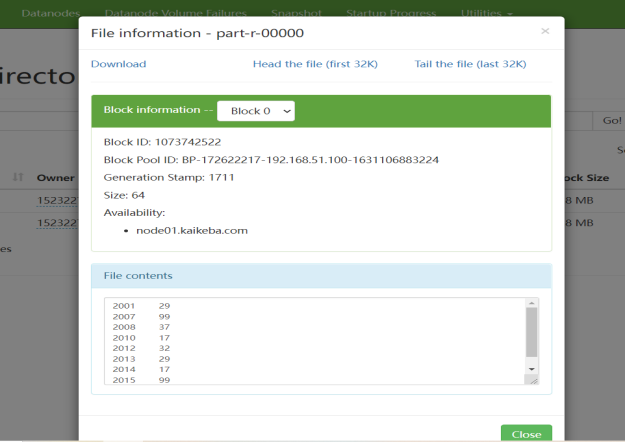
2、MAPREDUCE并行程序开发
3.1 求每年最高气温
代码:
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Temperature {
static class TempMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.print("Before Mapper: " + key + ", " + value);
String line = value.toString();
String year = line.substring(0, 4);
int temperature = Integer.parseInt(line.substring(8));
context.write(new Text(year), new IntWritable(temperature));
System.out.println("======" + "After Mapper:" + new Text(year) + ", " + new IntWritable(temperature));
}
}
static class TempReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
StringBuffer sb = new StringBuffer();
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
sb.append(value).append(", ");
}
System.out.print("Before Reduce: " + key + ", " + sb.toString());
context.write(key, new IntWritable(maxValue));
System.out.println("======" + "After Reduce: " + key + ", " + maxValue);
}
}
public static void main(String[] args) throws Exception {
String dst = "hdfs://node01:8020/wmd/input.txt";
String dstOut = "hdfs://node01:8020/wmd/output";
Configuration hadoopConfig = new Configuration();
hadoopConfig.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
hadoopConfig.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName());
Job job = new Job(hadoopConfig);
// job.setJarByClass(NewMaxTemperature.class);
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
job.setMapperClass(TempMapper.class);
job.setReducerClass(TempReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
System.out.println("Finished");
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号