
MapReduce
1、MapReduce编程模型:
1) Map阶段
- 输入数据格式的解析,InputFormat
- 输入数据处理,Mapper
- 数据分组(map函数处理以后的结果数据),Partitioner
2) Reduce阶段
- 数据远程拷贝
- 数据按照key排序
- 数据处理,Reduce
- 数据输出格式(Reduce函数处理以后的结果数据),OutputFormat
2、实现map和reduce函数的编写。其主要包括:
- Mapper区域
- Reduce区域
- Client区域


正常情况下开发流程如上图所示,但是在实际开发过程中,这样开发会非常的繁琐,比较慢。写完代码后不知道对错,只能走一遍流程才知道程序哪里出了问题。能不能有一个更好的方法?答案是肯定的,因此我们需要安装Hadoop Eclipse插件并使用Eclipse查看文件系统,安装成功后的效果如下所示。(插件的安装的详细流程请参考本人博客:https://www.cnblogs.com/ltolstar/p/9743506.html)

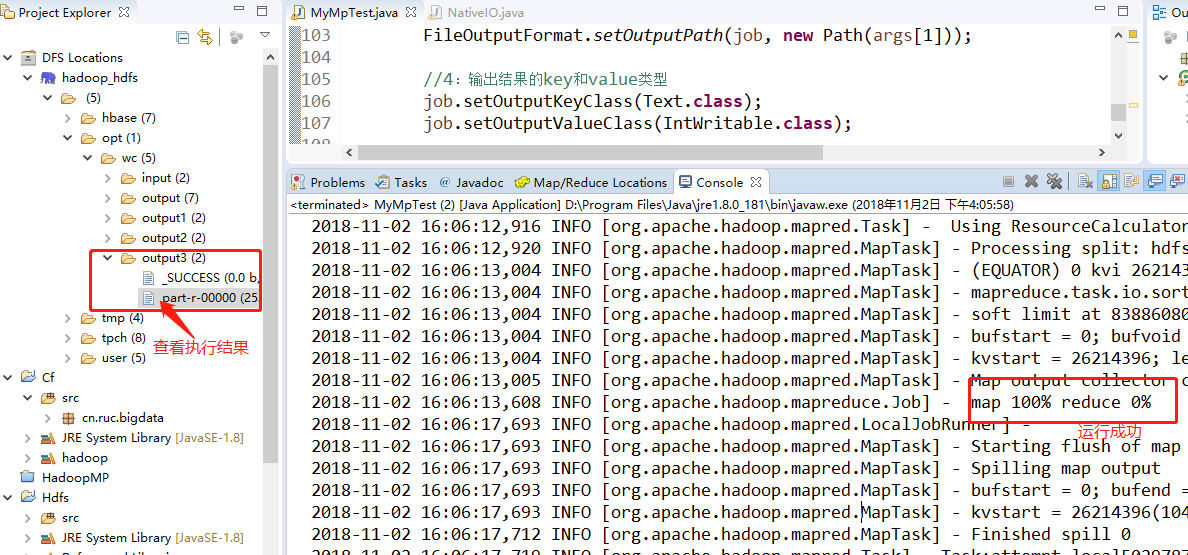
接下来就要创建Map/Reduce工程,进行MapReduce编程。程序完成后直接在Eclipse中即可运行。如果各配置正常,则会直接在控制台输出处理信息。

但是,可能出现以下问题。
第一,如下图所示。这种情况一般是由于hadoop.dll和winutils.exe和当前安装的hadoop的版本不一致所造成的。或者在%HADOOP_HOME%\bin下面根本就没有这两个文件。这时就要在网上根据自己hadoop的版本下载并放在%HADOOP_HOME%\bin目录下,并且将hadoop.dll在C:\Windows\System32下也放一份。如果还不能解决问题,在代码中强制加载hadoop.dll试试。参考:https://blog.csdn.net/weixin_37624828/article/details/83302631

第二,在执行代码的过程中,可能在控制台无法打印进度信息的问题。可以在工程的src文件夹下创建log4j.properties文件。并在文件中编辑如下信息,即可解决问题。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
最后,利用JDBC做了一个操作Hive的工具类。利用eclipse可以进行操作Hive,包括创建数据库,创建表,查询,导入数据,删除表等。详细情况参考代码HiveUtils.java。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号