在集群上运行python编写的spark应用程序时遇到的一些问题…
1、 如何将编写的应用程序提交给spark进行处理
首先,在Windows或Linux下编写程序。其次,将编写好的应用程序上传至服务器(自己定义好存放的文件目录)。最后,将程序提交给spark进行处理。如果程序没有问题,一些依赖的包已经安装,配置没有问题,那么程序即可以正常运行。

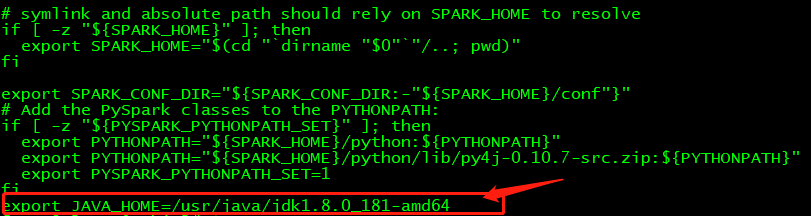
2、 在程序运行过程中可能存在的问题一,JAVA_HOME is not set
错误提示很清楚,JAVA_HOME没有设置,接下来进行设置。进入/opt/cloudera/parcels/SPARK2/lib/spark2/sbin(结合自己spark的安装路径),找到文件spark-config.sh,使用命令vi spark-config.sh打开文件,在文件最后添加export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64(结合自己jdk的安装路径设置)

3、 在程序运行过程中可能存在的问题二,No module named ‘***’
错误提示很清楚,这时我们将该模块进行安装即可。使用命令 pip/pip3 install ‘***’(本人更新了pip,根据自己情况)。还可能提示不存在命令pip,我们需要使用yum -y install pip即可。

4、运行spark程序时,发现端口被占用
如果发现端口被占用,则首先使用命令netstat -tln | grep 4040,查找被占用的端口。其次,使用命令lsof -i:4040查看被占用端口的PID。最后,使用命令kill -9 PID杀掉该进程。再次运行解决该问题。
netstat -tln | grep 4040
lsof -i:4040
kill -9 PID
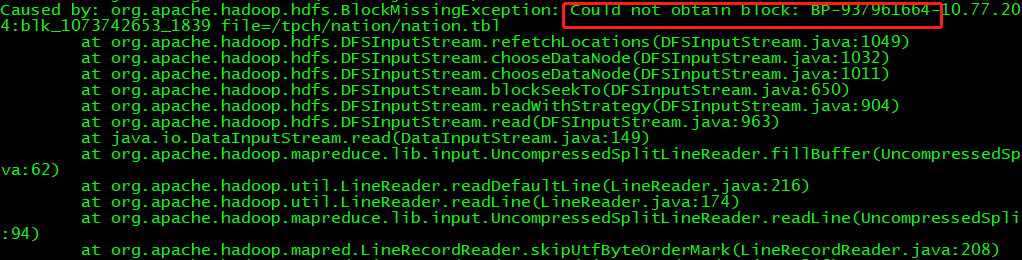
5、pyspark启动时,报错 Could not obtain block
使用jps查看NameNode、DataNode都正常、Spark、HDFS、Hive等也正常,但是还是出现此类问题,这时不妨查看一下防火墙吧,关闭防火墙即可。具体做法请看:https://www.cnblogs.com/ltolstar/p/9775821.html
参考博文:https://blog.csdn.net/u013451157/article/details/78943072
未完待续......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号