
Hbase学习笔记,你想知道的Hbase
1、 什么是Hbase?
HBase是一个构建在HDFS之上的、分布式的、面向列的开源数据库,不同于一般的关系数据库,它是一个适合于非结构化海量数据存储的数据库,是由Google Bigtable的开源实现,它主要用于存储海量数据,是Hadoop生态系统中的重要一员。Hbase可以使用shell、web、api等多种方式访问,适合高读写(insert)的场景,HQL查询语言,NoSQL的典型代表产品。
2、 Hbase逻辑模型
- l 以表的形式存放数据
- l 表由行与列组成,每个列属于某个列族,由行和列确定的存储单元称为元素
- l 每个元素保存了同一份数据的多个版本,由时间戳来标识区分
|
行健 |
时间戳 |
列族contents |
列族anchor |
列族mime |
|
“com.cnn.www” |
t9 |
|
anchor.cnnsi.com= “CNN” |
|
|
t8 |
|
anchor: my.look.ca= “CNN.com” |
|
|
|
t6 |
contents:html= “<html>…” |
|
mime: type= “text/html” |
|
|
t5 |
contents:html= “<html>…” |
|
|
|
|
t3 |
contents:html= “<html>…” |
|
|
- 行健:行健是数据行在表里的唯一标识,并作为检索记录的主键,访问表里的行只有三种方式,1、通过单个行键访问2、给定行键的范围访问3、全表扫描。行键可以是最大长度不超过64KB的任意字符串,并按照字典序存储。对于经常要一起读取的行,要对行键值精心设计,以便它们能放在一起存储。
- 列族与列:1、列表示为<列族>:<限定符> 2、Hbase在磁盘上按照列族存储数据,这种列式数据库的设计非常适合于数据分析的情形。3、列族里的元素最好具有相同的读写方式(例如等长的字符串),以提高性能。
- 时间戳:1、对应每次数据操作的时间,可由系统自动生成,也可以由用户显式的赋值。2、Hbase支持两种数据版本回收方式:1)每个数据单元,只存储指定个数的最新版本 2)保存指定时间长度的版本(例如7天)。
-
- 常见的客户端时间查询:“某个时刻起的最新数据”或“给我全部版本的数据”
- 元素由行键,列族:限定符,时间戳唯一决定
- 元素以字节码形式存放,没有类型之分
3、 Hbase的物理模型
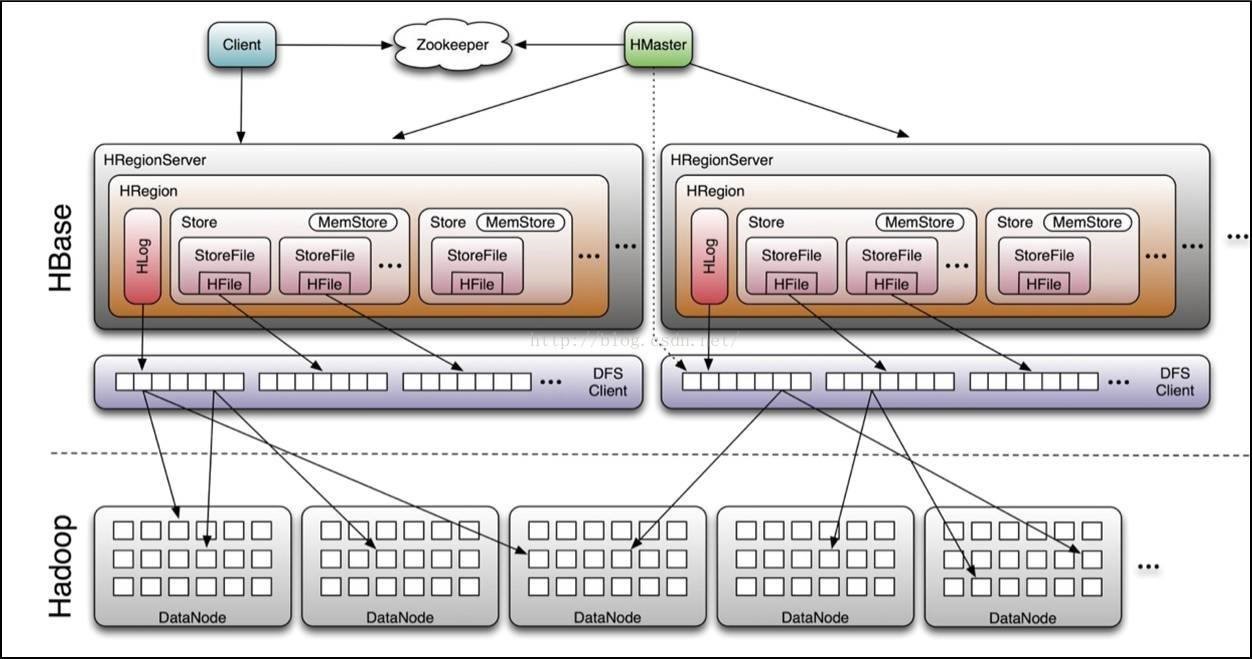
Region和Region服务器
- 表在行方向上,按照行键范围划分成若干的Region
- 每个表最初只有一个region,当记录数增加到超过某个阈值时,开始分裂成两个region
- 物理上所有数据存放在HDFS,由Region服务器提供region的管理
- 一台物理节点只能跑一个HRegionServer
- 一个Hregionserver可以管理多个Region实例
- 一个Region实例包括Hlog日志和存放数据的Store
- Hmaster作为总控节点
- Zookeeper负责调度
HLog
- 用于灾难恢复
- 预写式日志,记录所有更新操作,操作先记录进日志,数据才会写入
-Root-和.META.表
- HBase中有两张特殊的Table,-ROOT-和.META.
- .META.:记录了用户表的Region信息,.META.可以有多个regoin
- -ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
- Zookeeper中记录了-ROOT-表的location
Memstore和storefile
- 一个region由多个store组成,每个store包含一个列族的所有数据
- Store包括位于把内存的memstore和位于硬盘的storefile
- 写操作先写入memstore,当memstore中的数据量达到某个阈值,Hregionserver会启动flashcache进程写入storefile,每次写入形成单独一个storefile
- 当storefile文件的数量增长到一定阈值后,系统会进行合并,在合并过程中会进行版本合并和删除工作,形成更大的storefile
- 当storefile大小超过一定阈值后,会把当前的region分割为两个,并由Hmaster分配到相应的region服务器,实现负载均衡
- 客户端检索数据时,先在memstore找,找不到再找storefile
Hbase和Oracle
- 索引不同造成行为的差异
- Hbase适合大量插入同时又有读的情况
- Hbase的瓶颈是硬盘传输速度,Oracle的瓶颈是硬盘寻道时间
- Hbase很适合寻找按照时间排序top n的场景
4、 Hbase实战
进入/opt/cloudera/parcels/CDH/lib/hbase/bin下,使用命令hbase shell启动hbase。这是发现提示错误JAVA_HOME is not set。因此要进行配置,使用命令vi /conf/hbase-env.sh,添加export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64保存退出。再次执行hbase shell,执行成功。



利用shell命令进行简单的管理和操作:
1) 利用status命令查询数据库状态

2) 利用version命令查看数据库版本

3) 创建表 create ‘member’, ‘member_id’, ‘address’, ‘info’; 其中member表示表名,‘member_id’, ‘address’, ‘info’表示列族的名字。

4) 利用命令list列出所有的表,还可以用describe ‘member’

5) 对表的结构进行改动,删除列族:alter、disable、enable命令。在修改表结构之前,必须先使用命令disable ‘member’将表进行离线,再进行删除,删除过后再设置enable ‘member’。

6) 删除表,首先使用命令disable ‘member’将表进行离线disable 掉,再使用命令drop ‘member’进行表的删除。

7) 使用命令exists ‘member’查询一个表是否存在

8) 判断表是否enable或disable,使用命令is_enabled ‘member’和命令 is_disabled ‘member’,表之前进行删除了,后面不进行演示了,可以根据例子自行练习。
9) 插入记录使用命令,其中‘member’当然表示表名;‘scutshuxue’表示行健;‘info’表示列族名; 每一个put系统都会自动建立一个时间戳,当然这个时间戳也可以自己指定。其中,更新一条记录其实跟插入数据是一样的,做的是数据的覆盖。
put 'member', 'scutshuxue', 'info:age', '24' put ‘member’, 'scutshuxue', 'info:birthday', '1987-06-17' put 'member', 'scutshuxue', 'info:company', 'alibaba' ……
10) 获取一个行健的所有数据,使用命令 get ‘member’, ‘scutshuxue’;也可以获取一个行健中,某一个列族的所有数据使用命令 get ‘member’, ‘scutshuxue’, ‘info’; 还可以获取一个行健,一个列族中一个列的所有数据使用命令 get ‘member’, ‘scutshuxue’, ‘info:age’
11) 全表扫描,使用命令 scan ‘member’
12) 删除指定行健的字段,使用命令 delete ‘member’, ‘scutshuxue’, ‘info:age’ 删除整行,使用命令deleteall ‘表明’, ‘行健’
13) 查询表中有多少行,使用命令 count ‘member’
15) 要清空表的话,使用命令 truncate ‘member’,其原理是先删除表,再进行重建
5、 什么情况下我们可以使用Hbase?
- 成熟的数据分析主题,查询模式已经确立并且不轻易改变
- 传统的关系型数据库已经无法承受负荷,高速插入,大量读取
- 适合海量的,但同时也是简单的操作(例如key-value)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号