Hive学习笔记,你想知道的Hive
1、 什么是Hive(蜂巢)?
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。Hive是基于HDFS之上的数据仓库,也就是说Hive中的数据最终都是以文件的形式保存到HDFS,下表为其对应关系。而Hive的元信息(e.g.,表名、列名、列的类型等)主要存放在哪?Hive的官方文档中推荐使用的是MySQL数据库。
|
Hive |
HDFS |
|
表 |
目录 |
|
数据 |
文件 |
|
分区 |
目录 |
Hive还是一个翻译器,Hive是一个数据处理引擎,也就是在上一层执行的SQL语句,会有hive的引擎(Hive Driver)转换成MapReduce的程序去操作HDFS上的数据。

2、 和传统型数据库的区别
|
|
Hive |
RDBMS |
|
查询语言 |
HQL |
SQL |
|
数据存储 |
HDFS |
Raw Device or Local FS |
|
执行 |
MapReduce |
Executor |
|
执行延迟 |
高 |
低 |
|
处理数据规模 |
大 |
小 |
|
索引 |
0.8版本后加入位图索引 |
有复杂的索引 |
3、 为什么使用Hive?
a) 直接使用hadoop所面临的问题
- 公司人员学习成本高
- 由于项目周期要求太短
- 如果使用MapReduce实现复杂查询逻辑开发难度太大
b) 操作接口采用类SQL语法,提供快速开发的能力,避免了去写MapReduce,减少开发人员的学习成本,hive扩展功能很方便(自定义函数)。
4、 Hive的特性
a) 可扩展:Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
b) 延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
c) 容错:良好的容错性,节点出现问题SQL仍可完成执行
5、 Hive的应用实践
以基于CDH的Hive为例,进入目录/opt/cloudera/parcels/CDH/lib/hive/bin,输入hive命令,进入hive数据库,即可以进行相关操作了。

然而,我们会发现界面非常不友好、不直观,而hive给我们提供了一个服务端,对比感受一下效果,那么怎么利用Hive给我们提供的服务端,进行相关操作呢?请看如下步骤。


首先,在bin目录下有一个hiveserver2,然后开启服务端./hiveserver2或hive --service hiveserver2
其次,再连接一下服务器进入hive的bin目录下,会发现有一个beeline,用beeline的方式进行连接./beeline
最后,使用!connect jdbc:hive2://slaver0:10000 命令进行连接,连接成功即可进行操作数据库。

怎么向Hive建立的表中导入数据?
首先,我们准备一个文本数据(先简单介绍数据导入流程)
其次,我们要创建一个Hive的表,在创建的时候跟普通的数据库表的创建方式有所不同,如下图所示。在建表时可以建立1、内部表(类似MySQL中的表,下图所示)2、为了提高查询效率可以建立分区表(Hive特有的),具体建立方法如代码所示;3、桶表;4、外部表;5、为了简化查询也可以建立视图。查看创建表的信息用 desc demo1; 如果查看表的详细信息则用desc formatted demo1;
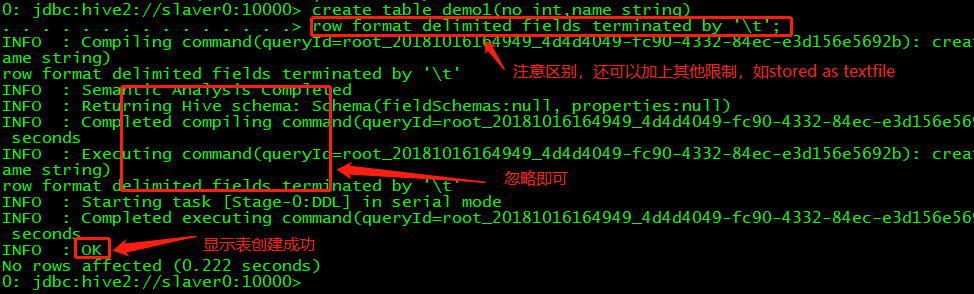
创建分区表
hive> create table demo1 > ( no int, > name string > ) partitioned by (no int) > row format delimited fields terminated by '\t';
向分区表中导入数据也略有不同
load data local inpath '/root/bigdata1016.china' into table demo2 partition(country='china');
修改表,添加分区
alter table demo2 add partition(country='american');
修改表,删除分区
alter table demo2 drop partition(country='japan');
查看分区
show partition demo2
创建外部表,通过location指定表存放的位置 > create external table exdemo(id int, name string) >row format delimited fields terminated by '\t' >stored as textfile >location '/test';
创建桶
在创建分桶表之前,要设置一些参数,如下
> set hive.enforce.bucketing = true;
> set mapreduce.job.reduces=4 (分几个桶设置几个)
> set hive.enforce.bucketing; 查看是否设置成功
> create table demo_buck(id int, name string) > clustered by (id) > sorted by(id) > into 4 buckets
> row format delimited fields terminated by ',';
desc extended demo_buck;
将一个表中的数据查询出来插入另一个表 > insert into table demo_buck > select id,name from demo1 distribute by (id) sort by (id);
然后,进行数据的导入
本地数据:load data local inpath '/root/bigdata1016' into table demo;
HDFS:load data inpath '/HDFS的目录/bigdata1016 ' into table demo;
最后,进行查看数据是否添加成功!
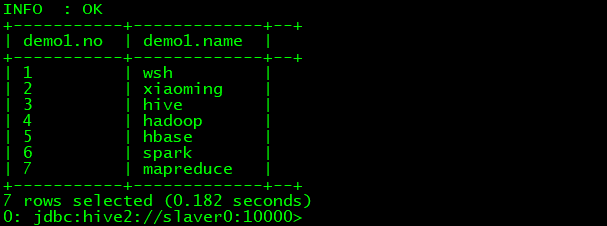
6、 对表中数据的操作
Hive相较于传统的数据库不仅具有存储数据的功能,还可以进行数据的处理。那么怎么进行数据的处理呢?
例如对刚才的表利用HQL进行一个简单的处理,select count(1) from demo1; 得到表中有多少条记录。这样就可以使用简单的HQL语句来实现MapReduce的功能(基本可是实现绝大部分的MapReduce程序,但是对于少部分逻辑比较复杂的程序还是不行的)
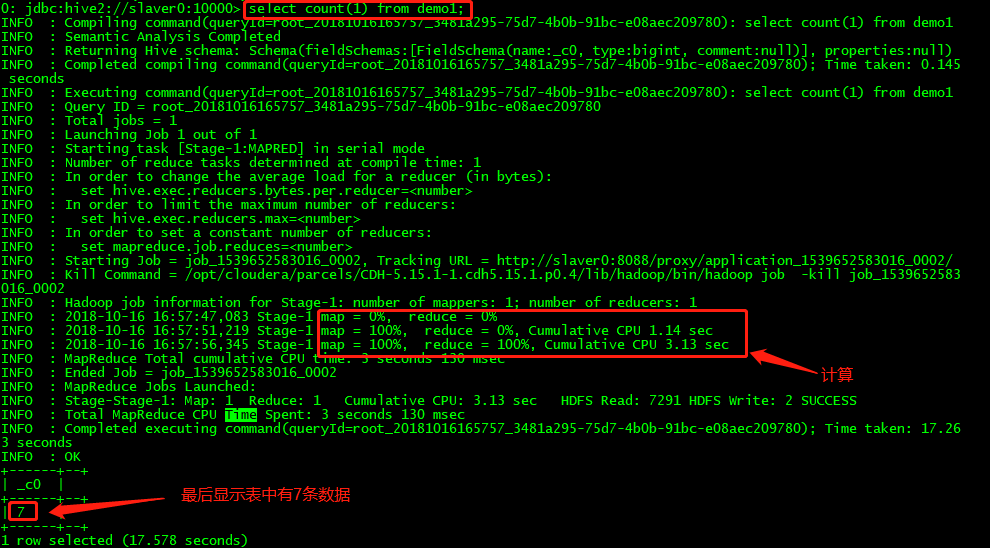
7、怎么覆盖数据库中的原有记录
首先,准备新的数据,这里我准备的数据文件的名字是bigdata10161
其次,执行如下语句进行Hive数据库中数据的更新操作
最后,查看是否更新成功!
load data local inpath '/root/bigdata10161' overwrite into table demo1;

8、怎么将新查询结果保存到新的Hive表中
> create table new_tb > as > select * from demo1;
hive --service hiveserver2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号