BiLSTM +CRF 原理介绍
-
数据格式
”O”表示非实体;”B”表示实体;”I”表示实体内
-
BiLSTM + CRF 模型
模型的结构:
- 句子𝑥中的每一个单元都代表着由character embedding或word embedding构成的向量。其中,character embedding是随机初始化的,word embedding是通过数据训练得到的。所有的 embeddings 在训练过程中都会调整到最优。
- 这些 embeddings 为BiLSTM-CRF模型的输入,输出的是句子𝑥中每个单元的标签。
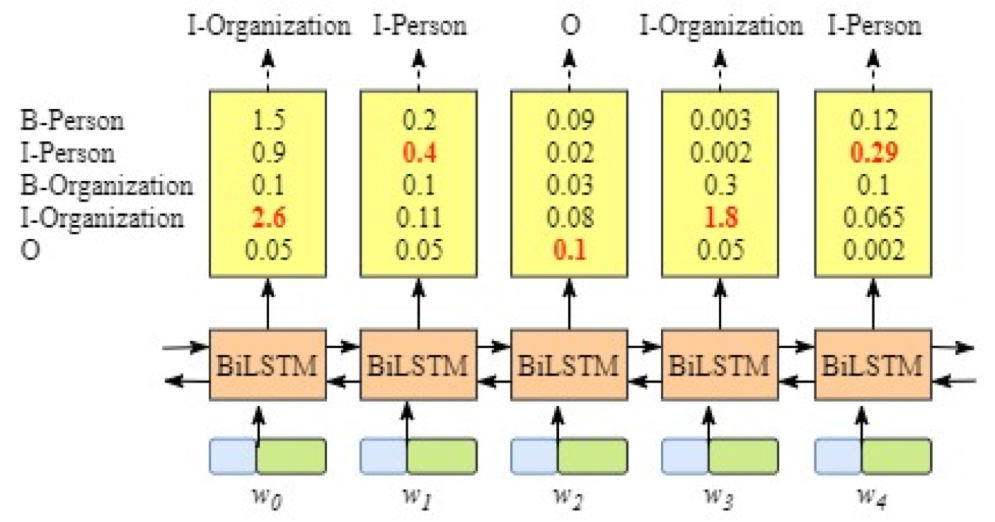
尽管一般不需要详细了解BiLSTM层的原理,但是为了更容易知道CRF层的运行原理,我们需要知道BiLSTM的输出层。这些分值将作为CRF的输入. 如下图所示, BiLSTM层的输出为每一个标签的预测分值,例如对于单元𝑤0,BiLSTM层输出的是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) 0.05 (O)
如下图(1)所示, “B-Person”有最高分值—— 1.5,因此我们可以挑选“B-Person”作为w0的预测标签. 同理,我们可以得到w1—“I-Person”,w2—“O” ,w3—“B-Organization”,w4—“O”. 由于BiLSTM的输出为单元的每一个标签分值,我们可以挑选分值最高的一个作为该单元的标签。虽然我们可以得到句子x中每个单元的正确标签,但是我们不能保证标签每次都是预测正确的(如下图2所示), 即所谓的标记偏置的问题。所以CRF的功能就是增加了一些约束规则,来大大降低预测错误的概率。
 (图1)
(图1)
(图2)
-
CRF的作用
CRF层可以为最后预测的标签添加一些约束来保证预测的标签是合法的。在训练数据训练过程中,这些约束可以通过CRF层自动学习到。
这些约束可以是:
- 句子中第一个词总是以标签“B-“ 或“O”开始,而不是“I-”
- 标签“B-label1 I-label2 I-label3 I-…”, label1, label2, label3应该属于同一类实体。例如,“B-Person I-Person” 是合法的序列, 但是“B-Person I-Organization” 是非法标签序列。
- 标签序列“O I-label” is 非法的.实体标签的首个标签应该是“B-“ ,而非“I-“, 换句话说,有效的标签序列应该是“O B-label”。
现在大家可能会有一个疑问标签的score怎么计算?
- 标签的Score
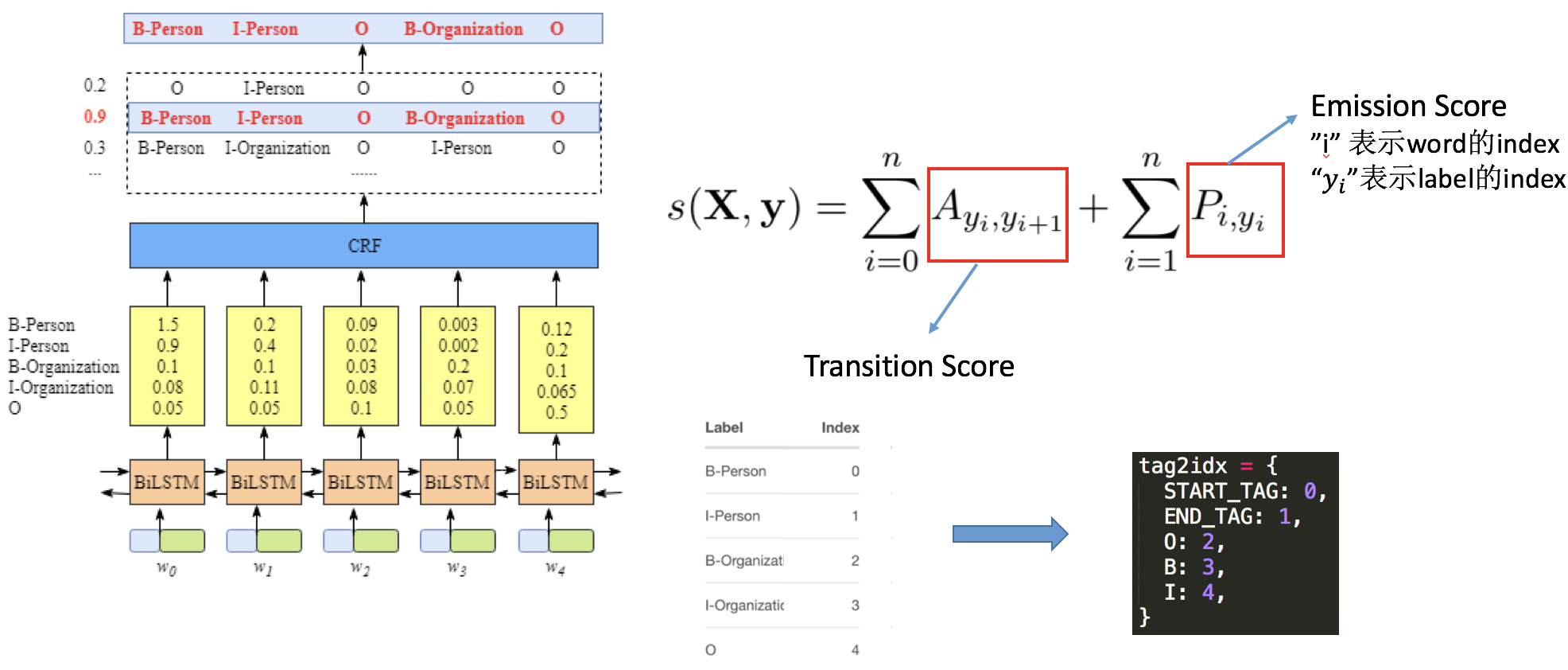
如下图所示, 确切的说,这个矩阵是 BiLSTM-CRF 模型的一个参数。在你训练模型之前,你可以随机地初始化矩阵中所有的 transition score。在之后的训练过程中,这些随机初始化的 score 将会被自动更新。换句话说,CRF 层可以自己学习到这些约束。我们并不需要手动创建这样一个矩阵。这些分数值会随着训练的迭代次数的增加,变得越来越 “合理”。
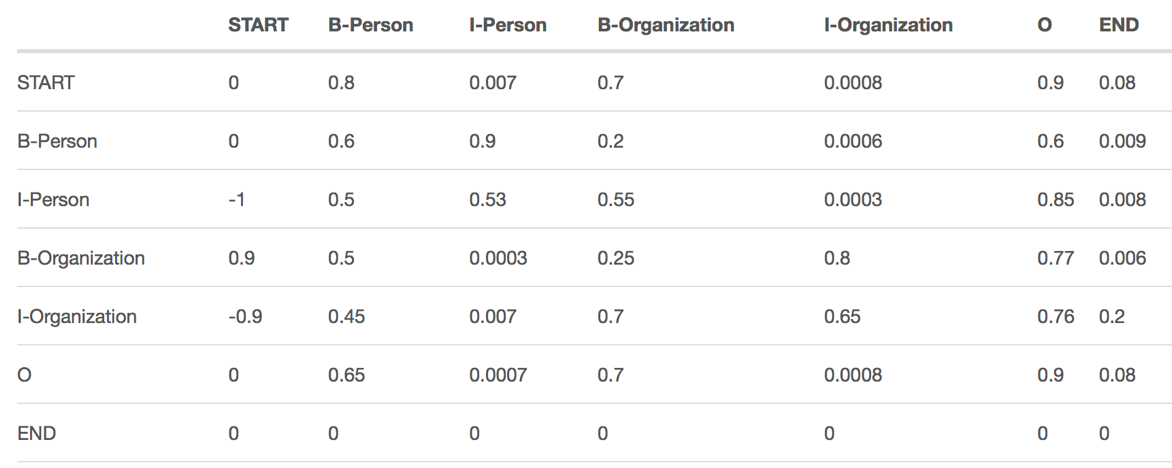
根据CRF的约束分析,我们可以知道:
- 句子中的第一个单词的标记应该是以“B-“ 或者 “O”开头, 并不会是 “I-”形式的标记。(“START” 到 “I-Person or I-Organization” 的转移值非常的小。)
- 在“B-label1 I-label2 I-label3 I-…”这样形式的标注序列中, label1, label2, label3 … 应该是同种实体的标签。比如,“B-Person I-Person” 是合理有效的标注序列,而 “B-Person I-Organization” 则不是。(“B-Organization” to “I-Person” 转移值为0.0003)
- 标签序列“O I-label” 是 非法的.实体标签的首个标签应该是“B-” ,而非“I-”(“START” to “I-Person”)
-
损失函数
CRF 的损失函数由真实转移路径值和所有可能转移路径值两部分组成。真实路径表示在所有可能转移路径中具有最高 score 的路径。比如, 我们也有一个由 5 个单词组成的句子,那么标签的可能转移路径有:
1.START B-Person B-Person B-Person B-Person B-Person END
2.START B-Person I-Person B-Person B-Person B-Person END
…
i.START B-Person I-Person O B-Organization O END
…
N.O O O O O O O
假定每一个可能的路径有一个分数值𝑃𝑖 , 那么对于所有 N 条可能的路径的总分数值为𝑃𝑡𝑜𝑡𝑎𝑙=𝑃1+𝑃2+𝑃3+…+𝑃𝑁=𝑒𝑆1+𝑒𝑆2+𝑒𝑆3+…+𝑒𝑆𝑁,e 是数学常量 e。
那么有Loss Function——>𝐿𝑜𝑠𝑠𝐹𝑢𝑛𝑐𝑡𝑖𝑜𝑛=𝑃𝑅𝑒𝑎𝑙𝑃𝑎𝑡ℎ/𝑃1+𝑃2+𝑃3+…+𝑃𝑁, 在训练阶段,BiLSTM-CRF模型的参数值将会一直不停的被更新,来提高真实路径的分数值所占的比重。
现在把损失函数变成log损失函数:

参考文献:
https://www.jianshu.com/p/566c6faace64
https://createmomo.github.io/2017/09/12/CRF_Layer_on_the_Top_of_BiLSTM_1/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号