以WordCount为例介绍scala开发流程(spark + scala)
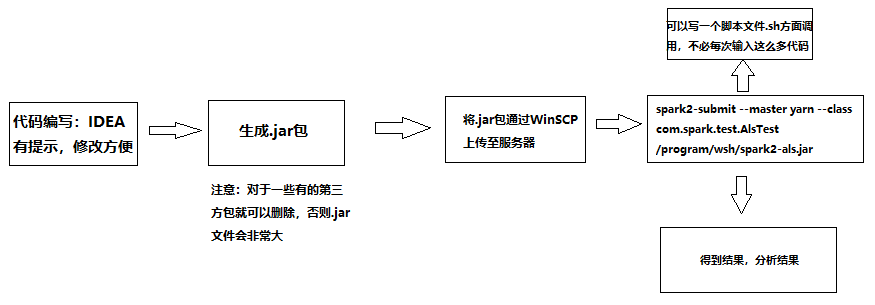
1、整体流程(这里不是wordcount例子,但整体流程相同)
2、对整体流程有整体了解后,接下来使用Maven创建scala工程,也可以使用sbt,具体区别请参考博文:https://blog.csdn.net/TXBSW/article/details/84070499,如果之前没有配置Maven请参考博文:https://blog.csdn.net/qq_32588349/article/details/51461182,https://blog.csdn.net/little_skeleton/article/details/80900244
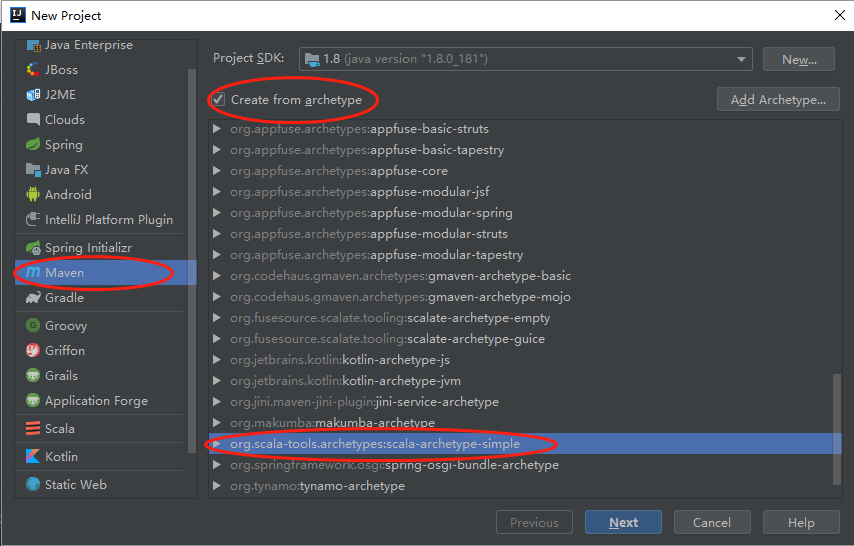
右侧勾选Create from archetype,点击下面的scala-archetype-simple选项,点击Next。如下图
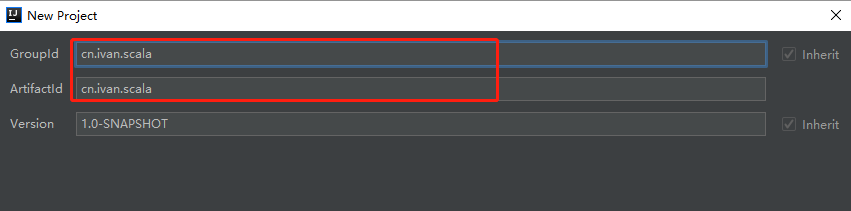
填写GroupId和ArtifactId选项,然后点击Next。如下图
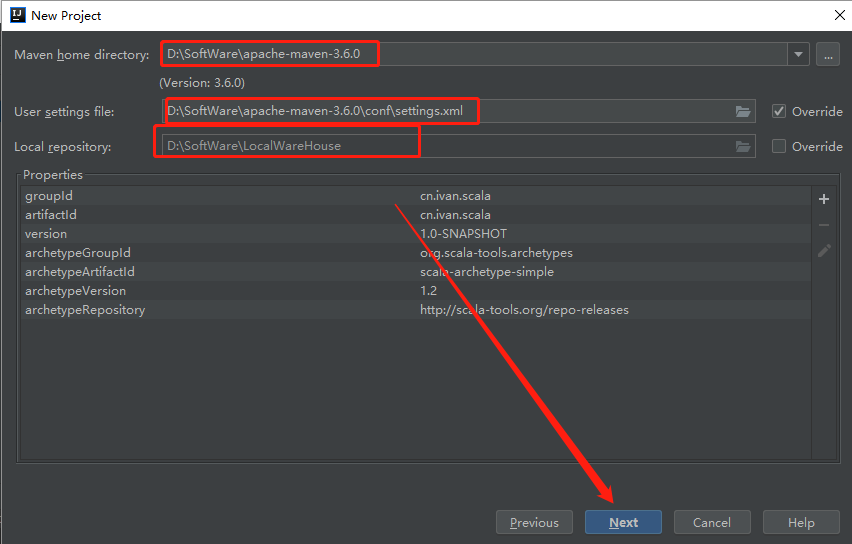
选择本地安装的maven目录和maven配置文件的路径,点击Next,如下图
最后,填写Project name,和刚刚GroupId一样就可以,然后点击Finish,完成工程创建。
3、工程创建成功后,接下来在pom.xml文件中加入spark环境所需要的一些依赖包,如下所示。这里要注意spark的版本一定要和scala的版本相对应,如果缺少什么包,在该文件下自行添加即可。
<properties> <maven.compiler.source>1.5</maven.compiler.source> <maven.compiler.target>1.5</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.12.7</scala.version> <spark.version>2.2.1</spark.version> <hadoop.version>2.7.3</hadoop.version> </properties> <!-- <repositories> <repository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </pluginRepository> </pluginRepositories> --> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> </dependencies
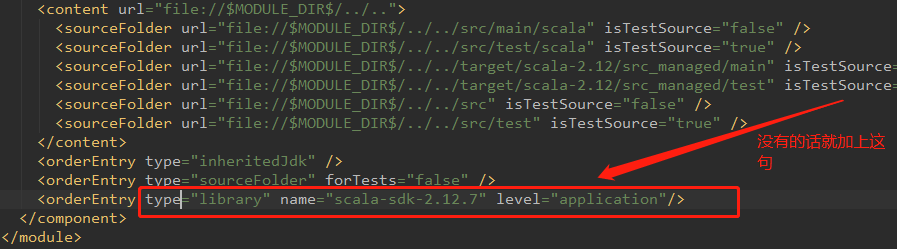
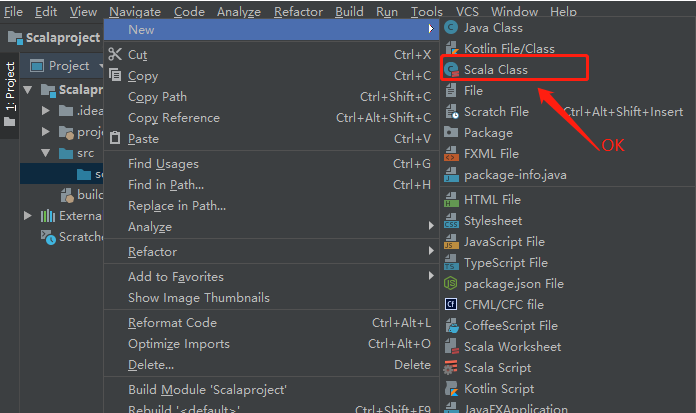
4、一切准备就绪,接下来进行程序的开发(以wordcount为例),当然在进行scala开发时,如果右键找不到scala.class,那么请进行如下设置。
package com.ivan
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//创建SparkConf()并且设置App的名称
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
//sc是SparkContext,他是spark程序执行的入口
val sc = new SparkContext(conf)
/**
* 带参数的任务,通过args(0)和args(1)进行参数设置
*/
//sc.textFile(args(0)).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile(args(1))
/**
* 直接进行处理
*/
val lines = sc.textFile("hdfs://10.77.20.23:8020/user/hadoop/word.txt")
// lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
/**
* 第二种处理写法
*/
val words = lines.flatMap(line => {
line.split(" ")
})
val pairWords = words.map(word => {
new Tuple2(word, 1)
})
/**
*
* reduceByKey 先分组,在给每个组的value进行聚合
*/
val result = pairWords.reduceByKey((v1, v2) => {
v1 + v2
})
result.foreach(tuple => {
println(tuple)
})
//停止sc,结束该任务
sc.stop()
}
}
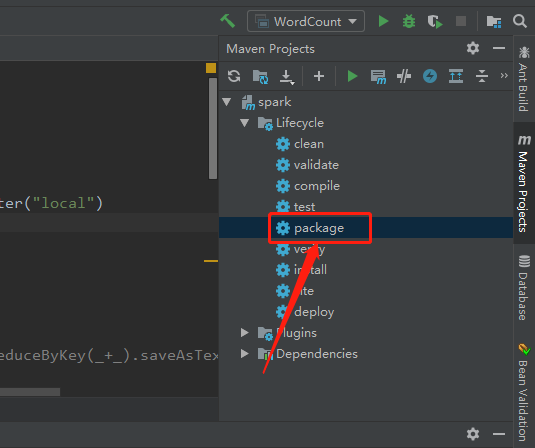
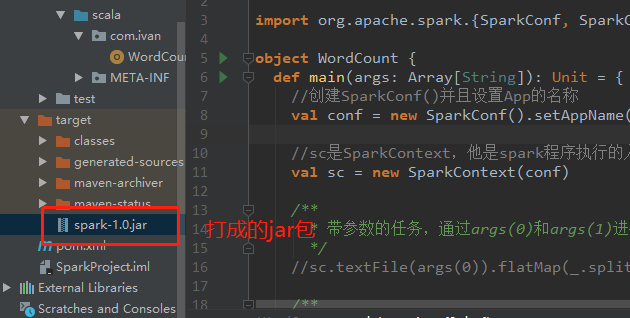
5、将程序打成jar包(过程如下,Maven方式),并利用winscp上传至服务器
6、向集群提交任务,并执行任务
./spark2-submit
--master spark://10.77.20.23:7077
--executor-memory 512mb
--total-executor-cores 4
--class com.ivan.WordCount /program/spark-1.0.jar
hdfs://10.77.20.23:9000/user/hadoop/
hdfs://10.77.20.23:9000/user/hadoop/output

 浙公网安备 33010602011771号
浙公网安备 33010602011771号