k8s源码解析之kube-scheduler启动流程
kube-scheduler功能
kube-scheduler是kubernetes中的重要的一环,总的来说,它的功能就是:将一个未调度的pod,调度到合适的node节点上。
下面以创建一个Pod为例,简要介绍kube-scheduler在整个过程发挥的作用:
- 用户通过命令行创建Pod
- kube-apiserver经过对象校验、admission、quota等准入操作,写入etcd
- kube-apiserver将结果返回给用户
- kube-scheduler一直监听节点信息、Pod信息(监听spec.nodeName为空的pod),然后进行调度
- kubelet监听分配给自己的Pod,调用CRI接口进行Pod创建
- kubelet创建Pod后,更新Pod状态等信息,并向kube-apiserver上报
- kube-apiserver向etcd写入信息数据
kube-scheduler控制循环
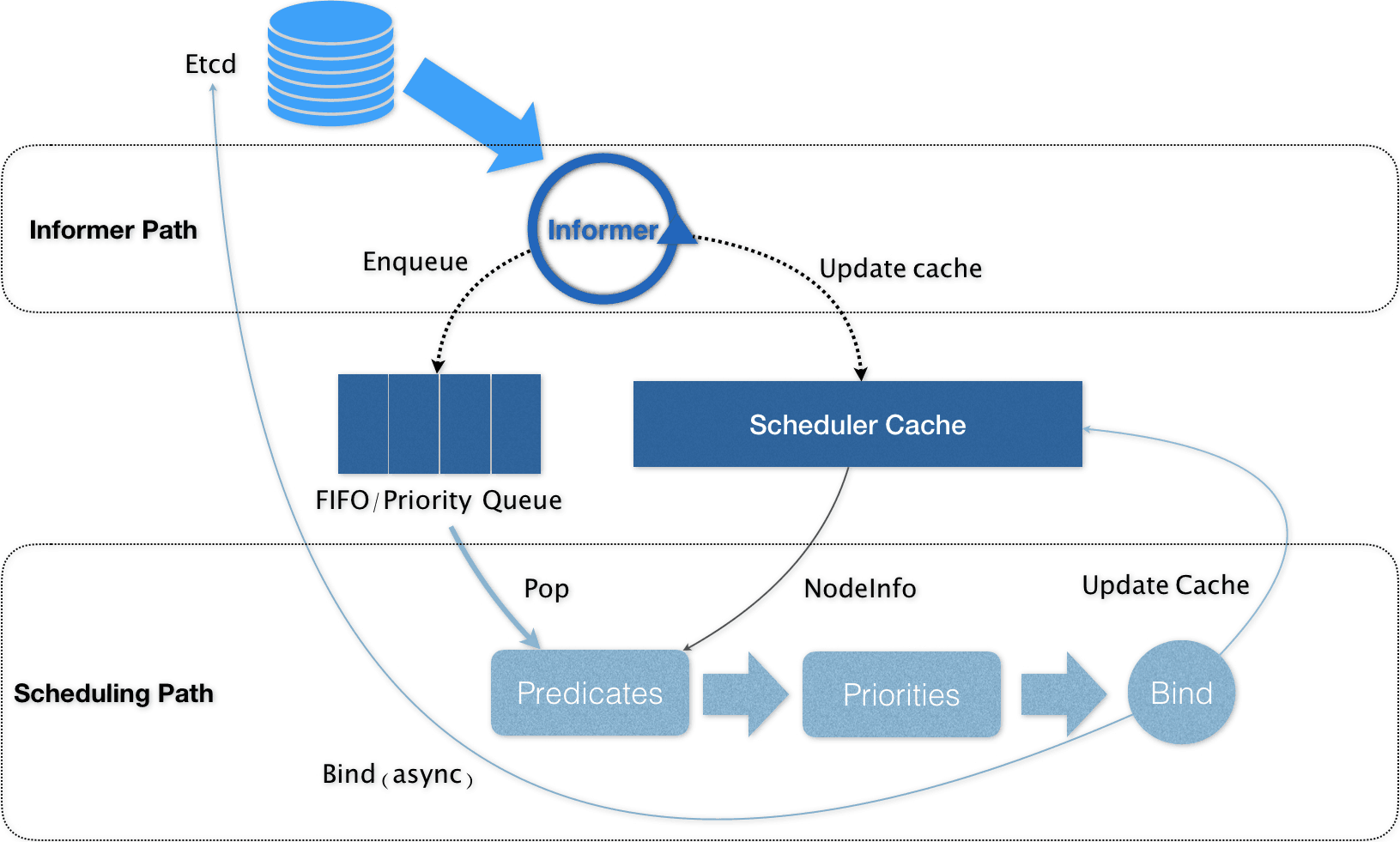
Informer Path
- 启动一系列 Informer,用来监听(Watch)Etcd 中 Pod、Node、Service 等与调度相关的 API 对象的变化
Scheduling Path
- 预选
- 优选
- BInd(异步)
kube-scheduler架构
Policy:
- 策略模块管理Scheduler的调度策略,我们可以通过命令行参数或配置文件的方式来指定这些策略。典型的策略配置有:加载哪些Plugin、Extender,在Predicates和Priorities的扩展点使用哪些插件等。
- 例如:当我们需要使用coscheduling时,我们需要在配置文集中pluginConfig字段指定添加coscheduling,并且在plugins的queueSort、preFilter、permit、reserve这些扩展点指定使用coscheduling。
Informer:
- 在服务启动时,调度器会注册多种Informer来监听集群资源的变化,典型的Informer有pod Informer和node Informer。
- 例如:当有新的pod 请求发送到apiserver中后,pod Informer会监听到该pod,并将其加入到active queue中以等待调度线程的调度
Schedule Cahe:
- Schedule Cache用于缓存Inform更新的资源信息和调度的结果信息,以便调度的时候可以进行快速的查询
- 例如:node informer每次发现有新的node加入到集群中时,都会将node写入到cache中以便调度线程在调度时能够选择新加入的node
Schedule Algorithm:
- 负责实现调度器的核心资源调度逻辑,整体上来讲分为三个阶段:Filter阶段选择符合Pod添加的Node,Score阶段对所有符合条件的Node进行打分,Bind阶段Pod分配给分数最高的Pod
本人阅读的kubernetes 1.21.13版本代码,kube-scheduler和其他组件一样,也是入口放在 cmd/kube-schduler 中,把实现放在 pkg/scheduler 中。
kube-scheduler的启动参数解析通过cobra来实现,因此也可以将kube-scheduler看成是一个基于cobra的CLI Application。
主函数scheduler.go
kube-scheduler的主函数位于cmd/kube-scheduler/scheduler.go
func main() {
// 设置全局随机数种子
rand.Seed(time.Now().UnixNano())
pflag.CommandLine.SetNormalizeFunc(cliflag.WordSepNormalizeFunc)
// 根据启动参数 初始化 kubelet,返回一个*cobra.Command
command := app.NewSchedulerCommand()
// 初始化日志控制器
logs.InitLogs()
defer logs.FlushLogs()
// 执行启动流程
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
NewSchedulerCommand()
通过 cobra 命令行定义 scheduler 的启动命令,实际调用的是cobra.Command.Run内的匿名函数,其中Run内又调用了runCommand方法
// NewSchedulerCommand creates a *cobra.Command object with default parameters and registryOptions
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
opts, err := options.NewOptions()
if err != nil {
klog.Fatalf("unable to initialize command options: %v", err)
}
cmd := &cobra.Command{
Use: "kube-scheduler",
Long: `The Kubernetes scheduler is a control plane process which assigns
Pods to Nodes. The scheduler determines which Nodes are valid placements for
each Pod in the scheduling queue according to constraints and available
resources. The scheduler then ranks each valid Node and binds the Pod to a
suitable Node. Multiple different schedulers may be used within a cluster;
kube-scheduler is the reference implementation.
See [scheduling](https://kubernetes.io/docs/concepts/scheduling-eviction/)
for more information about scheduling and the kube-scheduler component.`,
Run: func(cmd *cobra.Command, args []string) {
if err := runCommand(cmd, opts, registryOptions...); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
},
Args: func(cmd *cobra.Command, args []string) error {
for _, arg := range args {
if len(arg) > 0 {
return fmt.Errorf("%q does not take any arguments, got %q", cmd.CommandPath(), args)
}
}
return nil
},
}
fs := cmd.Flags()
namedFlagSets := opts.Flags()
verflag.AddFlags(namedFlagSets.FlagSet("global"))
globalflag.AddGlobalFlags(namedFlagSets.FlagSet("global"), cmd.Name())
for _, f := range namedFlagSets.FlagSets {
fs.AddFlagSet(f)
}
usageFmt := "Usage:\n %s\n"
cols, _, _ := term.TerminalSize(cmd.OutOrStdout())
cmd.SetUsageFunc(func(cmd *cobra.Command) error {
fmt.Fprintf(cmd.OutOrStderr(), usageFmt, cmd.UseLine())
cliflag.PrintSections(cmd.OutOrStderr(), namedFlagSets, cols)
return nil
})
cmd.SetHelpFunc(func(cmd *cobra.Command, args []string) {
fmt.Fprintf(cmd.OutOrStdout(), "%s\n\n"+usageFmt, cmd.Long, cmd.UseLine())
cliflag.PrintSections(cmd.OutOrStdout(), namedFlagSets, cols)
})
cmd.MarkFlagFilename("config", "yaml", "yml", "json")
return cmd
}
runCommand()
启动scheduler
// runCommand runs the scheduler.
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
verflag.PrintAndExitIfRequested()
cliflag.PrintFlags(cmd.Flags())
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
cc, sched, err := Setup(ctx, opts, registryOptions...)
if err != nil {
return err
}
return Run(ctx, cc, sched)
}
Setup()
会根据配置文件和启动参数来创建和初始化调度器的核心对象,这些对象会在调度线程中进行使用。创建的方式就是使用New()函数。初始化包括 informer, schedulerCache, schedulingQueue,和实例化 scheduler。
// Setup creates a completed config and a scheduler based on the command args and options
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
if errs := opts.Validate(); len(errs) > 0 {
return nil, nil, utilerrors.NewAggregate(errs)
}
// 初始化 client, EventBroadcaster,PodInformer,InformerFactory
// 并通过 scheduler config对象 回传
c, err := opts.Config()
if err != nil {
return nil, nil, err
}
// Get the completed config
cc := c.Complete()
outOfTreeRegistry := make(runtime.Registry)
for _, option := range outOfTreeRegistryOptions {
if err := option(outOfTreeRegistry); err != nil {
return nil, nil, err
}
}
recorderFactory := getRecorderFactory(&cc)
completedProfiles := make([]kubeschedulerconfig.KubeSchedulerProfile, 0)
// Create the scheduler.
sched, err := scheduler.New(cc.Client,
cc.InformerFactory,
recorderFactory,
ctx.Done(),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithAlgorithmSource(cc.ComponentConfig.AlgorithmSource),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
scheduler.WithParallelism(cc.ComponentConfig.Parallelism),
scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {
// Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging
completedProfiles = append(completedProfiles, profile)
}),
)
if err != nil {
return nil, nil, err
}
if err := options.LogOrWriteConfig(opts.WriteConfigTo, &cc.ComponentConfig, completedProfiles); err != nil {
return nil, nil, err
}
return &cc, sched, nil
}
opts.Config() 主要做了下面几件事:
- createClients 启动 clientset
- events.NewEventBroadcasterAdapter(eventClient) 启动 EventBroadcaster
- c.InformerFactory = informers.NewSharedInformerFactory(client, 0) 启动 informer
这几步基本所有的 kubernetes 的组件基本都是有的,保证组件跟 api-server 的通信。
Complete()方法
返回一个Config结构体
// Config has all the context to run a Scheduler
type Config struct {
// ComponentConfig is the scheduler server's configuration object.
ComponentConfig kubeschedulerconfig.KubeSchedulerConfiguration
// LoopbackClientConfig is a config for a privileged loopback connection
LoopbackClientConfig *restclient.Config
InsecureServing *apiserver.DeprecatedInsecureServingInfo // nil will disable serving on an insecure port
InsecureMetricsServing *apiserver.DeprecatedInsecureServingInfo // non-nil if metrics should be served independently
Authentication apiserver.AuthenticationInfo
Authorization apiserver.AuthorizationInfo
SecureServing *apiserver.SecureServingInfo
// Clientset.Interface内部封装了向apiServer所支持的所有apiVersion
// (apps/v1beta2,extensions/v1beta1...)之下的resource(pod/deployment/service...)发起查询请求的功能
Client clientset.Interface
InformerFactory informers.SharedInformerFactory
//lint:ignore SA1019 this deprecated field still needs to be used for now. It will be removed once the migration is done.
EventBroadcaster events.EventBroadcasterAdapter
// LeaderElection is optional.
LeaderElection *leaderelection.LeaderElectionConfig
}
scheduler.New()
创建scheduler,启动 scheduler 实例
// New returns a Scheduler
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
stopEverything := stopCh
if stopEverything == nil {
stopEverything = wait.NeverStop
}
options := defaultSchedulerOptions
for _, opt := range opts {
opt(&options)
}
// 初始化 schedulerCache
// 启动 scheduler 的缓存,主要是会启动pkg/scheduler/internal/cache/cache.go:cleanupAssumedPods
// 这个函数定期清理AssumedPods。
schedulerCache := internalcache.New(durationToExpireAssumedPod, stopEverything)
// 注册所有 intree 的 plugins
// 例如:注册interpodaffinity 的调度算法,
// 这种 plugin 的注册方式是通过 v1.15 开始引入的 scheduler framework 实现的
registry := frameworkplugins.NewInTreeRegistry()
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
// 初始化 snapshot,初始化一个 map 保存 node 信息,是用在 Algorithm.Schedule 的过程中的,主要是保留一份 cache 的备份
snapshot := internalcache.NewEmptySnapshot()
// 创建Scheduler构建所需要的对象(例如schedule cache)
configurator := &Configurator{
client: client,
recorderFactory: recorderFactory,
informerFactory: informerFactory,
schedulerCache: schedulerCache,
StopEverything: stopEverything,
percentageOfNodesToScore: options.percentageOfNodesToScore,
podInitialBackoffSeconds: options.podInitialBackoffSeconds,
podMaxBackoffSeconds: options.podMaxBackoffSeconds,
profiles: append([]schedulerapi.KubeSchedulerProfile(nil), options.profiles...),
registry: registry,
nodeInfoSnapshot: snapshot,
extenders: options.extenders,
frameworkCapturer: options.frameworkCapturer,
parallellism: options.parallelism,
}
metrics.Register()
// 通过上面 configurator 创建 scheduler(sched)
// 可以通过switch里的 policy 或者 provider 创建
var sched *Scheduler
source := options.schedulerAlgorithmSource
switch {
case source.Provider != nil:
// 根据注册算法的名称创建config
// Create the config from a named algorithm provider.
sc, err := configurator.createFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
sched = sc
case source.Policy != nil:
// 根据用户指定的策略源创建config
// Create the config from a named algorithm provider.
policy := &schedulerapi.Policy{}
switch {
case source.Policy.File != nil:
if err := initPolicyFromFile(source.Policy.File.Path, policy); err != nil {
return nil, err
}
case source.Policy.ConfigMap != nil:
if err := initPolicyFromConfigMap(client, source.Policy.ConfigMap, policy); err != nil {
return nil, err
}
}
// Set extenders on the configurator now that we've decoded the policy
// In this case, c.extenders should be nil since we're using a policy (and therefore not componentconfig,
// which would have set extenders in the above instantiation of Configurator from CC options)
configurator.extenders = policy.Extenders
sc, err := configurator.createFromConfig(*policy)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler from policy: %v", err)
}
sched = sc
default:
return nil, fmt.Errorf("unsupported algorithm source: %v", source)
}
// Additional tweaks to the config produced by the configurator.
sched.StopEverything = stopEverything
sched.client = client
// 为 scheduler 提供 eventHandler
// 为Node、Unschedule Pod、Schedule Pod、PersistentVolumeClaim等资源配置对应的Event处理函数
addAllEventHandlers(sched, informerFactory)
return sched, nil
}
createFromProvider()和createFromConfig()都调用了c.create()
c.create()使用一组注册的插件创建一个调度器
func (c *Configurator) create() (*Scheduler, error) {
var extenders []framework.Extender
var ignoredExtendedResources []string
if len(c.extenders) != 0 {
var ignorableExtenders []framework.Extender
for ii := range c.extenders {
klog.V(2).InfoS("Creating extender", "extender", c.extenders[ii])
extender, err := core.NewHTTPExtender(&c.extenders[ii])
if err != nil {
return nil, err
}
if !extender.IsIgnorable() {
extenders = append(extenders, extender)
} else {
ignorableExtenders = append(ignorableExtenders, extender)
}
for _, r := range c.extenders[ii].ManagedResources {
if r.IgnoredByScheduler {
ignoredExtendedResources = append(ignoredExtendedResources, r.Name)
}
}
}
// place ignorable extenders to the tail of extenders
extenders = append(extenders, ignorableExtenders...)
}
// If there are any extended resources found from the Extenders, append them to the pluginConfig for each profile.
// This should only have an effect on ComponentConfig v1beta1, where it is possible to configure Extenders and
// plugin args (and in which case the extender ignored resources take precedence).
// For earlier versions, using both policy and custom plugin config is disallowed, so this should be the only
// plugin config for this plugin.
if len(ignoredExtendedResources) > 0 {
for i := range c.profiles {
prof := &c.profiles[i]
pc := schedulerapi.PluginConfig{
Name: noderesources.FitName,
Args: &schedulerapi.NodeResourcesFitArgs{
IgnoredResources: ignoredExtendedResources,
},
}
prof.PluginConfig = append(prof.PluginConfig, pc)
}
}
// The nominator will be passed all the way to framework instantiation.
nominator := internalqueue.NewSafePodNominator(c.informerFactory.Core().V1().Pods().Lister())
// It's a "cluster event" -> "plugin names" map.
clusterEventMap := make(map[framework.ClusterEvent]sets.String)
// 初始化 profiles
profiles, err := profile.NewMap(c.profiles, c.registry, c.recorderFactory,
frameworkruntime.WithClientSet(c.client),
frameworkruntime.WithInformerFactory(c.informerFactory),
frameworkruntime.WithSnapshotSharedLister(c.nodeInfoSnapshot),
frameworkruntime.WithRunAllFilters(c.alwaysCheckAllPredicates),
frameworkruntime.WithPodNominator(nominator),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(c.frameworkCapturer)),
frameworkruntime.WithClusterEventMap(clusterEventMap),
frameworkruntime.WithParallelism(int(c.parallellism)),
frameworkruntime.WithExtenders(extenders),
)
if err != nil {
return nil, fmt.Errorf("initializing profiles: %v", err)
}
if len(profiles) == 0 {
return nil, errors.New("at least one profile is required")
}
// Profiles are required to have equivalent queue sort plugins.
// 初始化队列优先级函数
lessFn := profiles[c.profiles[0].SchedulerName].QueueSortFunc()
// 初始化调度队列,需要优先级函数,定义 backoffQ,UnScheduableQ 刷回 activeQ 的周期参数
podQueue := internalqueue.NewSchedulingQueue(
lessFn,
c.informerFactory,
internalqueue.WithPodInitialBackoffDuration(time.Duration(c.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(c.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodNominator(nominator),
internalqueue.WithClusterEventMap(clusterEventMap),
)
// Setup cache debugger.
debugger := cachedebugger.New(
c.informerFactory.Core().V1().Nodes().Lister(),
c.informerFactory.Core().V1().Pods().Lister(),
c.schedulerCache,
podQueue,
)
debugger.ListenForSignal(c.StopEverything)
// 初始化 Algorithm
algo := core.NewGenericScheduler(
c.schedulerCache,
c.nodeInfoSnapshot,
extenders,
c.percentageOfNodesToScore,
)
return &Scheduler{
SchedulerCache: c.schedulerCache,
Algorithm: algo,
Profiles: profiles,
NextPod: internalqueue.MakeNextPodFunc(podQueue),
Error: MakeDefaultErrorFunc(c.client, c.informerFactory.Core().V1().Pods().Lister(), podQueue, c.schedulerCache),
StopEverything: c.StopEverything,
SchedulingQueue: podQueue,
}, nil
}
addAllEventHandlers()为 scheduler 提供 eventHandler,它是一个用于在测试和调度器中添加EventHandlers的辅助函数
// addAllEventHandlers is a helper function used in tests and in Scheduler
// to add event handlers for various informers.
func addAllEventHandlers(
sched *Scheduler,
informerFactory informers.SharedInformerFactory,
) {
// scheduled pod cache activeQ下一个调度周期需要调度的对象
informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
// pod的pod.Spec.NodeName是不是为空
return assignedPod(t)
case cache.DeletedFinalStateUnknown:
if _, ok := t.Obj.(*v1.Pod); ok {
// The carried object may be stale, so we don't use it to check if
// it's assigned or not. Attempting to cleanup anyways.
return true
}
utilruntime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, sched))
return false
default:
utilruntime.HandleError(fmt.Errorf("unable to handle object in %T: %T", sched, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToCache,
UpdateFunc: sched.updatePodInCache,
DeleteFunc: sched.deletePodFromCache,
},
},
)
// unscheduled pod queue 用来存放调度失败的 Pod
informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
// pod的Spec.NodeName是不是为空
return !assignedPod(t) && responsibleForPod(t, sched.Profiles)
case cache.DeletedFinalStateUnknown:
if pod, ok := t.Obj.(*v1.Pod); ok {
// The carried object may be stale, so we don't use it to check if
// it's assigned or not.
return responsibleForPod(pod, sched.Profiles)
}
utilruntime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, sched))
return false
default:
utilruntime.HandleError(fmt.Errorf("unable to handle object in %T: %T", sched, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToSchedulingQueue,
UpdateFunc: sched.updatePodInSchedulingQueue,
DeleteFunc: sched.deletePodFromSchedulingQueue,
},
},
)
informerFactory.Core().V1().Nodes().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.addNodeToCache,
UpdateFunc: sched.updateNodeInCache,
DeleteFunc: sched.deleteNodeFromCache,
},
)
informerFactory.Storage().V1().CSINodes().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.onCSINodeAdd,
UpdateFunc: sched.onCSINodeUpdate,
},
)
// On add and update of PVs.
informerFactory.Core().V1().PersistentVolumes().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
// MaxPDVolumeCountPredicate: since it relies on the counts of PV.
AddFunc: sched.onPvAdd,
UpdateFunc: sched.onPvUpdate,
},
)
// This is for MaxPDVolumeCountPredicate: add/update PVC will affect counts of PV when it is bound.
informerFactory.Core().V1().PersistentVolumeClaims().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.onPvcAdd,
UpdateFunc: sched.onPvcUpdate,
},
)
// This is for ServiceAffinity: affected by the selector of the service is updated.
// Also, if new service is added, equivalence cache will also become invalid since
// existing pods may be "captured" by this service and change this predicate result.
informerFactory.Core().V1().Services().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.onServiceAdd,
UpdateFunc: sched.onServiceUpdate,
DeleteFunc: sched.onServiceDelete,
},
)
informerFactory.Storage().V1().StorageClasses().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.onStorageClassAdd,
},
)
}
Run()
基于给定的配置运行调度程序,主要用来启动调度线程来执行调度任务
// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
// To help debugging, immediately log version
klog.V(1).Infof("Starting Kubernetes Scheduler version %+v", version.Get())
// Configz registration.
// 注册configz
if cz, err := configz.New("componentconfig"); err == nil {
cz.Set(cc.ComponentConfig)
} else {
return fmt.Errorf("unable to register configz: %s", err)
}
// Prepare the event broadcaster.
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
// Setup healthz checks.
// 配置健康检查
var checks []healthz.HealthChecker
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
waitingForLeader := make(chan struct{})
isLeader := func() bool {
select {
case _, ok := <-waitingForLeader:
// if channel is closed, we are leading
return !ok
default:
// channel is open, we are waiting for a leader
return false
}
}
// Start up the healthz server.
// 启动健康检查服务,创建处理Health请求的handler
if cc.InsecureServing != nil {
separateMetrics := cc.InsecureMetricsServing != nil
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader, separateMetrics, checks...), nil, nil)
if err := cc.InsecureServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start healthz server: %v", err)
}
}
// 创建处理Metric请求的handler
if cc.InsecureMetricsServing != nil {
handler := buildHandlerChain(newMetricsHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader), nil, nil)
if err := cc.InsecureMetricsServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start metrics server: %v", err)
}
}
// 创建处理health请求的handler
if cc.SecureServing != nil {
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader, false, checks...), cc.Authentication.Authenticator, cc.Authorization.Authorizer)
// TODO: handle stoppedCh returned by c.SecureServing.Serve
if _, err := cc.SecureServing.Serve(handler, 0, ctx.Done()); err != nil {
// fail early for secure handlers, removing the old error loop from above
return fmt.Errorf("failed to start secure server: %v", err)
}
}
// Start all informers.
// 启动所有informer.注:对应的informer已经在Setup阶段完成设置,因此这里直接启动即可
cc.InformerFactory.Start(ctx.Done())
// Wait for all caches to sync before scheduling.
// 等待所有缓存同步完成后再进行调度
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// If leader election is enabled, runCommand via LeaderElector until done and exit.
// 选主逻辑
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
close(waitingForLeader)
sched.Run(ctx)
},
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// Leader election is disabled, so runCommand inline until done.
close(waitingForLeader)
// 启动后台调度线程
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
sched.Run()
sched.Run(ctx)开始监视和调度。它开始调度并阻塞,直到完成。其中的sched.scheduleOne是调度主逻辑
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
// 会启动两个定时goroutine
sched.SchedulingQueue.Run()
// 调度线程,会从activeQ中不断取出Pod进行调度
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}
SchedulingQueue.Run()
SchedulingQueue.Run()
// Run starts the goroutine to pump from podBackoffQ to activeQ
func (p *PriorityQueue) Run() {
// 每1 second执行一次,将backoffQ中的pod移动到active Q中
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
// 每30 seconde执行一次,将unscheduleQ中的pod移动到activeQ或backoffQ中(注:如果pod仍然在backoff time内则会被放到backoffQ中)
go wait.Until(p.flushUnschedulableQLeftover, 30*time.Second, p.stop)
}
sched.scheduleOne()
sched.scheduleOne是调度逻辑主线程,为了提升调度器的调度性能,bind阶段通过创建一个 Goroutine 来异步地向 APIServer 发起更新 Pod 的请求
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// 从activeQ中取出一个Pod进行调度
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
// 根据pod中的schedule name选择一个对应的framework来执行调度
// 【之前版本是 frameworkForPod】 会查看 pod 的 schedulername
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
klog.ErrorS(err, "Error occurred")
return
}
// pod是否跳过调度
// 情况一:pod正在被删除
// 情况二:pod在调度的过程中,被绑定到一个更新事件
if sched.skipPodSchedule(fwk, pod) {
return
}
klog.V(3).InfoS("Attempting to schedule pod", "pod", klog.KObj(pod))
// 尝试为pod找一个合适的节点
// Synchronously attempt to find a fit for the pod.
start := time.Now()
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
// 针对于当前的pod对所有node执行filter和score两部分逻辑,
// 并选出score分数最高的node作为pod的调度资源
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, fwk, state, pod)
if err != nil {
// Schedule() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
nominatedNode := ""
if fitError, ok := err.(*framework.FitError); ok {
if !fwk.HasPostFilterPlugins() {
klog.V(3).InfoS("No PostFilter plugins are registered, so no preemption will be performed")
} else {
// Run PostFilter plugins to try to make the pod schedulable in a future scheduling cycle.
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
if status.Code() == framework.Error {
klog.ErrorS(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
} else {
klog.V(5).InfoS("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
}
if status.IsSuccess() && result != nil {
nominatedNode = result.NominatedNodeName
}
}
// Pod did not fit anywhere, so it is counted as a failure. If preemption
// succeeds, the pod should get counted as a success the next time we try to
// schedule it. (hopefully)
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else if err == core.ErrNoNodesAvailable {
// No nodes available is counted as unschedulable rather than an error.
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else {
klog.ErrorS(err, "Error selecting node for pod", "pod", klog.KObj(pod))
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
}
sched.recordSchedulingFailure(fwk, podInfo, err, v1.PodReasonUnschedulable, nominatedNode)
return
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start))
// Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet.
// This allows us to keep scheduling without waiting on binding to occur.
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
// 将assume pod信息写入到SchedulerCache中
// assume modifies `assumedPod` by setting NodeName=scheduleResult.SuggestedHost
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
if err != nil {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// This is most probably result of a BUG in retrying logic.
// We report an error here so that pod scheduling can be retried.
// This relies on the fact that Error will check if the pod has been bound
// to a node and if so will not add it back to the unscheduled pods queue
// (otherwise this would cause an infinite loop).
sched.recordSchedulingFailure(fwk, assumedPodInfo, err, SchedulerError, "")
return
}
// Run the Reserve method of reserve plugins.
// 执行reserve plugin
if sts := fwk.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.SchedulerCache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
}
sched.recordSchedulingFailure(fwk, assumedPodInfo, sts.AsError(), SchedulerError, "")
return
}
// Run "permit" plugins.
// 执行permiet plugin
runPermitStatus := fwk.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if runPermitStatus.Code() != framework.Wait && !runPermitStatus.IsSuccess() {
var reason string
if runPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = SchedulerError
}
// One of the plugins returned status different than success or wait.
fwk.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.SchedulerCache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
}
sched.recordSchedulingFailure(fwk, assumedPodInfo, runPermitStatus.AsError(), reason, "")
return
}
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
// 为了提升调度器的调度性能,bind阶段通过创建一个 Goroutine 来异步地向 APIServer 发起更新 Pod 的请求
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Dec()
// 在上面的PermitPlugin阶段可能会使得pod处于waiting状态,此时则是等待waiting状态的结束
waitOnPermitStatus := fwk.WaitOnPermit(bindingCycleCtx, assumedPod)
if !waitOnPermitStatus.IsSuccess() {
var reason string
if waitOnPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = SchedulerError
}
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.SchedulerCache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
}
sched.recordSchedulingFailure(fwk, assumedPodInfo, waitOnPermitStatus.AsError(), reason, "")
return
}
// Run "prebind" plugins.
// 执行prebind plugin
preBindStatus := fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if !preBindStatus.IsSuccess() {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.SchedulerCache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
}
sched.recordSchedulingFailure(fwk, assumedPodInfo, preBindStatus.AsError(), SchedulerError, "")
return
}
// 执行bind逻辑,本质上是调用了Extender bind plugin和framework的bind plugin
err := sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)
if err != nil {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if err := sched.SchedulerCache.ForgetPod(assumedPod); err != nil {
klog.ErrorS(err, "scheduler cache ForgetPod failed")
}
sched.recordSchedulingFailure(fwk, assumedPodInfo, fmt.Errorf("binding rejected: %w", err), SchedulerError, "")
} else {
// Calculating nodeResourceString can be heavy. Avoid it if klog verbosity is below 2.
if klog.V(2).Enabled() {
klog.InfoS("Successfully bound pod to node", "pod", klog.KObj(pod), "node", scheduleResult.SuggestedHost, "evaluatedNodes", scheduleResult.EvaluatedNodes, "feasibleNodes", scheduleResult.FeasibleNodes)
}
metrics.PodScheduled(fwk.ProfileName(), metrics.SinceInSeconds(start))
metrics.PodSchedulingAttempts.Observe(float64(podInfo.Attempts))
metrics.PodSchedulingDuration.WithLabelValues(getAttemptsLabel(podInfo)).Observe(metrics.SinceInSeconds(podInfo.InitialAttemptTimestamp))
// Run "postbind" plugins.
fwk.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
}
}()
}
sched.Algorithm.Schedule()
sched.Algorithm.Schedule()针对于当前的pod对所有node执行filter和score两部分逻辑,并选出score分数最高的node作为pod的调度资源,返回调度结果
// Schedule tries to schedule the given pod to one of the nodes in the node list.
// If it succeeds, it will return the name of the node.
// If it fails, it will return a FitError error with reasons.
func (g *genericScheduler) Schedule(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
// 对scheduled cache执行一次snapshot,获取一次nodeInfo的快照,并以此次的snapshot中的node状态为基础执行filter和score逻辑
if err := g.snapshot(); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if g.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
// 预选
// 执行调度器的filter逻辑,一共分为5个步骤:
// 执行prefilter plugin
// 通过snapshot获取node list
// 如果当前pod为nominate pod,则直接返回nominate node
// 执行filter plugin
// 执行filter extender plguin
// 根据这些plguin找到适合pod的节点
feasibleNodes, diagnosis, err := g.findNodesThatFitPod(ctx, fwk, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
if len(feasibleNodes) == 0 {
return result, &framework.FitError{
Pod: pod,
NumAllNodes: g.nodeInfoSnapshot.NumNodes(),
Diagnosis: diagnosis,
}
}
// 如果只有一个 node 合适就不会进入优选环节,直接返回
// When only one node after predicate, just use it.
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap),
FeasibleNodes: 1,
}, nil
}
// 优选
// 执行score逻辑,一共分为了三个步骤:
// 1)执行pre score plugin;
// 2)执行score plugin;
// 3)执行extender score plugin
priorityList, err := g.prioritizeNodes(ctx, fwk, state, pod, feasibleNodes)
if err != nil {
return result, err
}
// 从所有node中选择score最高的返回
host, err := g.selectHost(priorityList)
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap),
FeasibleNodes: len(feasibleNodes),
}, err
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号