Redis源码解析-SDS
总结
-
要想理解 Redis 数据类型的设计,必须要先了解 redisObject。 Redis 的 key 是 String 类型,但 value 可以是很多类型(String/List/Hash/Set/ZSet等),所以 Redis 要想存储多种数据类型,就要设计一个通用的对象进行封装,这个对象就是 redisObject。
// server.h typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; int refcount; void *ptr; } robj;其中,最重要的 2 个字段:
-
type:面向用户的数据类型(String/List/Hash/Set/ZSet等)
-
encoding:每一种数据类型,可以对应不同的底层数据结构来实现(SDS/ziplist/intset/hashtable/skiplist等)
例如 String,可以用 embstr(嵌入式字符串,redisObject 和 SDS 一起分配内存),也可以用 rawstr(redisObject 和 SDS 分开存储)实现。
又或者,当用户写入的是一个「数字」时,底层会转成 long 来存储,节省内存。
同理,Hash/Set/ZSet 在数据量少时,采用 ziplist 存储,否则就转为 hashtable 来存。
所以,redisObject 的作用在于:
-
为多种数据类型提供统一的表示方式
-
同一种数据类型,底层可以对应不同实现,节省内存
-
支持对象共享和引用计数,共享对象存储一份,可多次使用,节省内存
redisObject 更像是连接「上层数据类型」和「底层数据结构」之间的桥梁。
-
-
关于 String 类型的实现,底层对应 3 种数据结构:
- embstr:小于 44 字节,嵌入式存储,redisObject 和 SDS 一起分配内存,只分配 1 次内存
- rawstr:大于 44 字节,redisObject 和 SDS 分开存储,需分配 2 次内存
- long:整数存储(小于 10000,使用共享对象池存储,但有个前提:Redis 没有设置淘汰策略,详见 object.c 的 tryObjectEncoding 函数)
-
ziplist 的特点:
- 连续内存存储:每个元素紧凑排列,内存利用率高
- 变长编码:存储数据时,采用变长编码(满足数据长度的前提下,尽可能少分配内存)
- 寻找元素需遍历:存放太多元素,性能会下降(适合少量数据存储)
- 级联更新:更新、删除元素,会引发级联更新(因为内存连续,前面数据膨胀/删除了,后面要跟着一起动)
List、Hash、Set、ZSet 底层都用到了 ziplist。
-
intset 的特点:
- Set 存储如果都是数字,采用 intset 存储
- 变长编码:数字范围不同,intset 会选择 int16/int32/int64 编码(intset.c 的 _intsetValueEncoding 函数)
- 有序:intset 在存储时是有序的,这意味着查找一个元素,可使用「二分查找」(intset.c 的 intsetSearch 函数)
- 编码升级/降级:添加、更新、删除元素,数据范围发生变化,会引发编码长度升级或降级
-
SDS 判断是否使用嵌入式字符串的条件是 44 字节,嵌入式字符串会把 redisObject 和 SDS 一起分配内存,那在存储时结构是这样的:
- redisObject:16 个字节
- SDS:sdshdr8(3 个字节)+ SDS 字符数组(N 字节 + \0 结束符 1 个字节)
Redis 规定嵌入式字符串最大以 64 字节存储,所以 N = 64 - 16(redisObject) - 3(sdshr8) - 1(\0), N = 44 字节。
背景
对于Redis来说,键值对中的键是字符串,值有时也是字符串。我们在Redis中写入一条用户信息,记录了用户姓名、性别、所在城市等,这些都是字符串,如下所示:
SET user:id:100{"name":"zhangsan","gender":"M","city":"beijing"}
在Redis的字符串结构需要满足以下条件
- 能支持丰富且高效的字符串操作,比如字符串追加、拷贝、比较、获取长度等;
- 能保存任意的二进制数据,比如图片等;
- 能尽可能地节省内存开销。
说到字符串会立即想到C语言中的char*字符数组,它可以通过string.h中定义的诸如字符串比较函数strcmp、字符串长度计算函数strlen、字符串追加函数strcat等来进行操作。
strcat源码如下:
char *strcat(char*dest,const char*src){
//将目标字符串复制给tmp变量
char *tmp=dest;
//用一个while循环遍历目标字符串,直到遇到“\0”跳出循环,指向目标字符串的末尾 while(*dest)
dest++;
//将源字符串中的每个字符逐一赋值到目标字符串中,直到遇到结束字符 while((*dest++=*Src++)!='\o')
return tmp;
}
综上,char*字符数组有以下不足
- 操作效率低:获取长度需遍历,O(N)复杂度
- 二进制不安全:无法存储包含 \0 的数据(\0代表字符串结束)
SDS
结构
简单动态字符串(Simple Dynamic String,SDS),它的结构如下:
SDS创建函数sdsnewlen
typedef char *sds; //sds是char*的别名
sds sdsnewlen(const void*init,size_t initlen){
void*sh; //指向SDS结构体的指针
sds s; //sds类型变量,即char*字符数组
...
sh=s_malloc(hdrLen+initlen+1); //新建SDs结构,并分配内存空间
...
s=(char*)sh+hdrLen;//sds类型变量指向SDS结构体中的buf数组,sh指向SD
...
if(initlen&&init)
memcpy(s,init,initlen); //将要传入的字符串拷贝给sds变量s s[initlen]='\0'; //变量s未尾增加\0,表示字符串结束
returns;
}
SDS字符串追加函数sdscatlen()
sds sdscatlen(sds s,const void*t,size_t len){
//获取目标字符串s的当前长度
size_t curlen=sdslen(s);
//根据要追加的长度Len和目标字符串s的现有长度,判断是否要增加新的空间 s=sdsMakeRoomFor(s,len);
if(s==NULL) return NULL;
//将源字符串t中1en长度的数据拷贝到目标字符串结尾
memcpy(s+curlen,t,len);
//设置目标字符串的最新长度:拷贝前长度curLen加上拷贝长度
sdssetlen(s,curlen+Len);
//拷贝后,在目标字符串结尾加上\0
s[curlen+1en]='\0';
returns;
}
SDS通过记录字符数组的使用长度和分配空间大小,避免了对字符串的遍历操作,降低了操作开销,进一步就可以帮助诸多字符串操作更加高效地完成,比如创建、追加、复制、比较等。
封装
SDS把目标字符串的空间检查和扩容封装在了sdsMakeRoomFor 函数中,并且在涉及字符串空间变化的操作中,如追加、复制等,会直接调用该函数。这一设计实现,就避免了开发人员因忘记给目标字符串扩容,而导致操作失败的情况。比如,在使用函数 strcpy(char *dest,const char *src)时,如果src的长度大于dest的长度,代码中也没有做检查的话,就会造成内存溢出。
紧凑型字符串结构
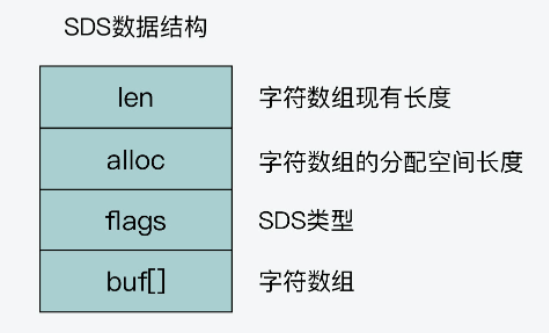
SDS结构中有一个元数据flags,表示的是SDS类型。事实上,SDS一共设计了5种类型,分别是sdshdr5(已经不再使用)、sdshdr8、sdshdr16、sdshdr32和sdshdr64。这5种类型的主要区别就在于,它们数据结构中的字符数组现有长度len和分配空间长度alloc,这两个元数据的数据类型不同。
sdshdr8:
struct__attribute__((__packed__))sdshdr8{
uint8_t len;/*字符数组现有长度*/
uint8_t alloc;/*字符数组的已分配空间,不包括结构体和\0结束字符*/
unsigned char flags;/*SDS类型*/
char buf[];/*字符数组*/
};
现有长度len和已分配空间alloc的数据类型都是uint8t。uint8t是8位无符号整型,会占用1字节的内存空间。当字符串类型是sdshdr8时,它能表示的字符数组长度(包括数组最后一位\0)不会超过256字节(2的8次方等于256)。而对于sdshdr16、sdshdr32、sdshdr64三种类型来说,它们的len和alloc 数据类型分别是uint16t、uint32t、uint64t即它们能表示的字符数组长度,分别不超过2的16次方、32次方和64次方。这两个元数据占用的内存空间在sdshdr16、sdshdr32、sdshdr64类型中,则分别是2字节、4字节和8字节。
SDS之设计不同的结构头(即不同类型),是为了能灵活保存不同大小的字符串,从而有效节省内存空间。因为在保存不同大小的字符串时,结构头占用的内存空间也不一样,这样一来,在保存小字符串时,结构头占用空间也比较少。
代码中的__attribute__((__packed__))的作用就是告诉编译器,在编译 sdshdr8结构时,不要使用内存对齐的方式,而是采用紧凑的方式分配内存。因为在默认情况下,编译器会按照内存对齐的方式,给变量分配内存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号